NeurIPS2022 | 训练缺少数据?你还有“零样本学习(zero-shot Learning)”(香槟分校)
来源: AINLPer微信公众号(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2022-10-09
引言
虽然单向预训练模型(如:GPT)和双向预训练模型(如Bert)在小样本学习任务中取得了不错的成绩,但是它们在零样本学习任务中的潜力并未充分挖掘,为此本文提出了用语言模型生成训练数据实现零样本学习。

关注 AINLPer公众号,最新干货第一时间送达
背景介绍
利用大量任务特定的训练数据对预训练的语言模型(PLMs)进行微调,在自然语言理解(NLU)任务中已经可以达到了人类水平。然而,这样一个有监督的微调范式与人类相比有很大的不同:人们不需要看很多特定任务的训练样本就可以给出很好的答案。最近,许多研究指出了PLMs在少样本情况下的学习能力:通过将任务描述转换为自然语言提示(prompt),并将其注入PLMs,基于提示(Prompt)的方法利用特定任务信息可以提高训练数据质量,并取得显著的效果。
然而,当基于提示的方法应用于零样本时,PLM 的预测准确度要低得多。例如,GPT-3 的零样本性能相对于它的少样本性能会大大降低,尤其是在自然语言推理(NLI)等具有挑战性的任务上。如果没有任何特定任务的样本,PLM 确实很难有效地解释以不同格式出现且在预训练数据中看不到的提示。为了让 PLMs 熟悉各种提示,以将零样本泛化到未知任务,最近的一项研究提出了指令调优,它在指令描述的大量不同任务上对 PLM 进行微调。尽管性能强劲,但它的成功是基于大量的跨任务注释数据集(例如,在许多非 NLI 任务上训练并转移到 NLI 任务)和巨大的模型规模(例如,数千亿个参数),在实际应用过程中会存在一定的困难。
针对以上问题,本文在没有任何特定任务或跨任务数据情况下,研究了 PLM 在 NLU 任务上的零样本学习。受近期 PLM 强大的文本生成能力的启发,提出了SuperGen,这是一种监督生成(Supervision Generation)方法,其中训练数据是通过单向 PLM(即生成器)创建的,在标签描述提示的指导下生成类条件文本。然后通过双向PLM(即分类器)对生成的文本进行微调,以执行相应的任务。两种 PLM 的大小都可以适中,以适合典型的研究硬件(例如,GPT-2大小的生成器和RoBERTaLarge大小的分类器)。借助生成器自动创建的监督,SuperGen 消除了对特定任务注释的需求,并为分类器 PLM 提供了比少样本场景更多的训练数据。 SuperGen 兼容任何 PLM 作为分类器和任何微调方法。
模型介绍
如下图所示:用于NLU任务的零样本学习的SuperGen概述。
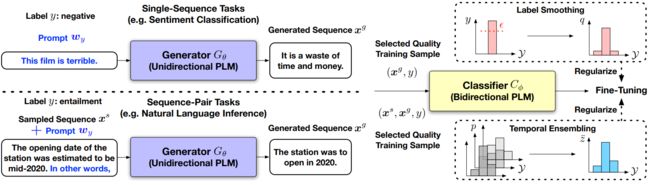
其中:
- 单向 PLM 用作生成器,用于创建由标签描述性提示引导的训练数据。
- 根据平均日志生成概率选择高质量的训练样本。
- 双向PLM在选定的训练集上以标签平滑和时间集成作为正则化进行微调,以执行分类任务
下图为中总结了用于单序列 NLU 任务的 SuperGen。解决序列对问题遵循相同的算法,只是需要预训练语料库D对第一个序列 x s x^s xs进行采样。

实验结果
下表中展示了SuperGen、其消融和比较方法的结果。总体而言,SuperGen 显着优于零样本提示,并取得了比所有少样本方法更好的总体结果。

本文还尝试混合不同提示组(混合)来生成的数据。 如下表所示。总体而言,不同提示下的模型性能非常接近,除了测试集非常小的RTE,可能导致更高的方差。

如下表所示,除了默认的 PLM 选择之外,还给出了使用 GPT-2XLarge(1.54B 参数)作为生成器和 RoBERTaLarge(356M 参数)作为分类器的结果。

下表给出了由不同标签的提示引导的生成文本的具体示例。生成的序列不仅是连贯的,而且与相应的标签有关。

论文&&源码
Paper:https://arxiv.org/pdf/2202.04538.pdf
Code:https://github.com/yumeng5/supergen
推荐阅读
[1] 一文了解EMNLP国际顶会 && 历年EMNLP论文下载 && 含EMNLP2022
[2]【历年NeurIPS论文下载】一文带你看懂NeurIPS国际顶会(内含NeurIPS2022)
[3]【微软研究院 && 含源码】相比黑盒模型,可解释模型同样可以获得理想的性能
[4]【IJCAI2022&&知识图谱】联邦环境下,基于元学习的图谱知识外推(阿里&浙大&含源码)
[5]【NLP论文分享&&语言表示】有望颠覆Transformer的图循环神经网络(GNN)
[6]【NeurIPS && 图谱问答】知识图谱(KG) Mutil-Hop推理的锥形嵌入方法(中科院–含源码)
[7]【NLP论文分享 && QA问答】动态关联GNN建立直接关联,优化multi-hop推理(含源码)
[8]【历年IJCAI论文下载 && 论文速递】无数据对抗蒸馏、垂直联合、预训练微调范式图神经网络(GNN)
[9]【NLP论文分享&&中文命名实体识别】如何构建一个优秀的Gazetteer/地名词典(浙大&含源码)