【极简笔记】VPGNet: Vanishing Point Guided Network for Lane and Road Marking Detection and Recognition
Abstract
- propose a unified end-to-end trainable multi-task network that jointly handles lane and road marking detection and recognition that is guided by a vanishing point under adverse weather conditions.提出统一的端到端可训练多任务网络,共同处理在恶劣天气条件下由消失点引导的车道和道路标记检测和识别。
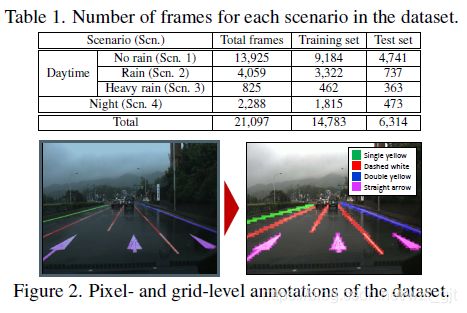
- To address this shortcoming(poor weather conditions), we build up a lane and road marking benchmark which consists of about 20,000 images with 17 lane and road marking classes under four different scenarios: no rain, rain, heavy rain, and night. 为了解决这个缺点,我们建立了一个车道和道路标记基准,包括大约20,000个图像,17个车道和道路标记类,在四种不同的情况下:没有下雨,下雨,大雨和夜晚。
- The resulting approach, VPGNet, can detect and classify lanes and road markings, and predict a vanishing point with a single forward pass. Experimental results show that our approach achieves high accuracy and robustness under various conditions in real-time (20 fps). 由此产生的方法VPGNet可以检测并分类车道和道路标记,并通过单个前向通道预测消失点。实验结果表明,我们的方法在各种条件下实时(20 fps)实现了高精度和鲁棒性。
Contributions
- We build up a lane and road marking detection and recognition benchmark dataset taken under various weather and illumination conditions. The dataset consists of about 20,000 images with 17 manually annotated lane and road markings classes. Vanishing point annotation is provided as well.
- We design a unified end-to-end trainable multi-task network that jointly handles lane and road marking detection and recognition that is guided by the vanishing point. We provide an extensive evaluation of our network on the created benchmark. The results show robustness under different weather conditions with realtime performance. Moreover, we suggest that the proposed vanishing point prediction task enables the network to detect lanes that are not explicitly seen.我们设计了一个统一的端到端可训练多任务网络,共同处理由消失点引导的车道和道路标记检测和识别。 我们在创建的基准测试中对我们的网络进行了广泛的评估。 结果表明在不同天气条件下具有实时性能的鲁棒性。 此外,我们建议所提出的消失点预测任务使网络能够检测未明确看到的通道。
数据集
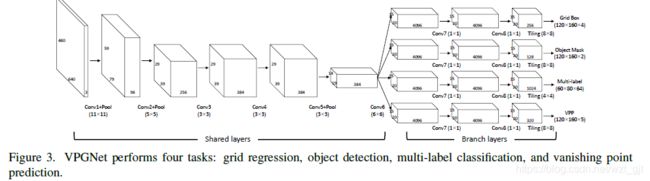
Network
1. Architecture
The network has four task modules and each task performs complementary cooperation: grid box regression, object detection, multi-label classification, and prediction of the vanishing point. This structure allows us to detect and classify the lane and road markings, and predict the vanishing region simultaneously in a single forward pass.网络有四个任务模块,每个任务执行互补合作:网格框回归,对象检测,多标签分类和消失点预测。 这种结构允许我们检测并分类车道和道路标记,并在单个前向通道中同时预测消失区域。
2. Vanishing Point Prediction Task
we have designed a Vanishing Point Prediction (VPP) task that guides robust lane and road marking detection similar to human vision. In this paper, “Vanishing Point (VP)” is defined as the nearest point on the horizon where lanes converge and disappear predictively around the farthest point of the visible lane .This VP can be used to provide a global geometric几何 context of a scene, which is important to infer the location of lanes and road markings.
We use a quadrant(象限) mask that divides the whole image into four sections. The intersection of these four sections is a VP. In this way, we can infer the VP using four quadrant sections which cover the structures of a global scene.To implement this, we define five channels for the output of the VPP task: one absence channel and four quadrant channels. Every pixel in the output image chooses to belong to one of the five channels. The absence channel is used to represent a pixel with no VP, while the four quadrant channels stand for one of the quadrant sections on the image. On the other hand, if the VP is hard to be identified (e.g. intersection roads, occlusions), every pixel will tend to be classified as the absence channel. In this case, the average confidence of the absence channel would be high
3. Training.
We noticed that during the training stage the VPP task became dependent on the lane detection task. The dependency between lanes and the VP implies a strong information correlation. In this case, the VP provides redundant冗余的 information to the network, leading to marginal lane detection improvement. In order to prevent this side effect, we train the network in two phases to tolerate the balance between the tasks.
In the first phase, we train only the VPP task.The training of this phase stops upon reaching convergence of the VP detection task. Although we train only the VPP task, due to the weight update of the mutually shared layers, losses of the other detection tasks are also decreased by about20%. This shows that lane and road marking detection and VPP tasks share some common characteristics in the feature representation layers.
In the second phase, we further train all the tasks using the initialized kernels from the first phase.
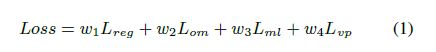
where Lreg is a grid regression L1 loss, Lom and Lml and Lvp are cross entropy losses in each branch of the network
Balance weight trick
First, w1∼w4 are set to be equal to 1, and the starting losses are observed. Then, we set the reciprocal of these initial loss values to the loss weight so that the losses are uniform. In the middle of the training, if the scale difference between losses becomes large, this process is repeated to balance the loss values. The second phase stops when the validation accuracy is converged.
Post-Processing
Lane :
- subsample local peaks from the region where the probability of lane channels from the multi-label task is high.
- selected points are projected to the birds-eye view by inverse perspective mapping (IPM) [3]. IPM is used to separate the sampled points near the VP. This is useful not only for the case of straight roads but also curved ones.
- cluster the points by our modified density-based clustering method.
- quadratic regressions of the lines from the obtained clusters utilizing the location of the VP. If the farthest sample point of each lane cluster is close to the VP, we include it in the cluster to estimate a polynomial model. This makes the lane results stable near the VP. The class type is assigned to each line segment from the multi-labeled output of the network.
Road marking:
- we extract grid cells from the grid regression task with high confidence for each class from the multi-label output.
- select corner points of each grid and merge them with the nearby grid cells iteratively. If no more neighboring grid cells belong to the same class, the merging is terminated.
ps:Some road markings such as crosswalks or safety zones that are difficult to define by a single box are localized by grid sampling without subsequent merging. 某些道路标记(如人行横道或安全区域)难以通过单个框定义,通过网格采样进行定位,无需后续合并。
Vanishing point

Results
1. Experimental Settings
At the first training phase, we initialize the network only by the VPP task. After the initialization, all four tasks are trained simultaneously. For every task, we use Stochastic Gradient Descent optimization with a momentum of 0.9 and a mini-batch size of 20. Since multiple tasks must converge proportionally, we tune the learning rate of each task.
We train three models of the network divided by task: 2-Task (revised [16]), 3-Task (revised [35]), and 4-Task (VPGNet). 2-Task network includes regression and binary classification tasks. 3-Task network includes 2-Task and a multi-label classification task. 4-Task network includes 3- Task and a VPP task, which is the VPGNet. Since the lane detection in [16] ( An empirical evaluation of deep learning on highway driving)is not fully reproducible, we modify the data layer to handle the grid mask and move one convolutional layer from shared layers to branch layers, as in the 3- and 4-Task networks. The 3-Task network is similar to [35](Traffic-sign detection and classification in the wild. In CVPR, 2016.笔记:https://segmentfault.com/a/1190000009438113), but we modify the data layer to handle the grid mask.
We test our models on NVIDIA GTX Titan X and achieve a speed of 20 Hz by using only a single forward pass. Specifically, the single forward pass takes about 30 ms and the post-processing takes about 20 ms or less.
2.Analysis of Multi Task Learning

As the results show, if we use more tasks, more neurons respond, especially around the boundaries of roadways.
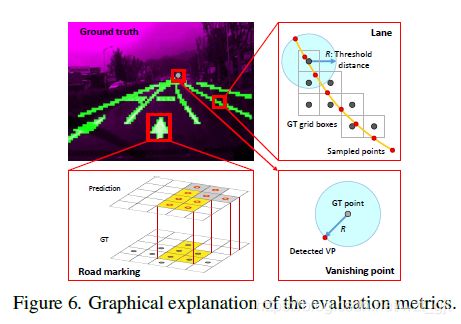
3. Evaluation Metrics
4. Lane Detection and Recognition
In order to see what happens if the VP does not exist, we conducted an additional test on images without the VP (e.g. intersection roads or occlusions). Table 4 shows the results of the experiment, demonstrating that the enhancement of feature representation through the VPP task helps to find lanes even when there is no VP.


5. Road Marking Detection and Recognition

6. Vanishing Point Prediction
