哈工大视听觉信号处理——听觉部分报告——一种智能家居命令词识别系统的设计
题 目 听觉部分
专 业 软件工程
学 号 120L0219XX
班 级 2037101
姓 名 李启明
报 告 日 期 2022.12.20
一、基频
(一)语音信号中的基频对人类感知和理解语音内容的影响
人在讲话时声带会对基音频率产生很大影响。一般来说基音频率低,代表声带牵拉的程度小;基音频率高,那就代表声带被牵拉的程度大,此时声带将变得比较长、薄且比较紧,声门的形状为细长。基音频率包含了许多和语音情感激活度有关联的有价值的信息 ,因此能够体现情感的变动。
(二)基于自相关函数的基频检测方法
(1)自相关函数
对于离散的语音信号x(n),它的自相关函数定义为:
R(k)=Σx(n)x(n-k),
如果信号x(n))具有周期性,那么它的自相关函数也具有周期性,而且周期与信号x(n)的周期性相同。自相关函数提供了一种获取周期信号周期的方法。在周期信号周期的整数倍上,它的自相关函数可以达到最大值,因此可以不考虑起始时间,而从自相关函数的第一个最大值的位置估计出信号的基音周期,这使自相关函数成为信号基音周期估计的一种工具。
(2)短时自相关函数
语音信号是非平稳的信号,所以对信号的处理都使用短时自相关函数。短时自相关函数是在信号的第N个样本点附近用短时窗截取一段信号,做自相关计算所得的结果
Rm(k)=Σx(n)x(n-k)
式中,n表示窗函数是从第n点开始加入。
(三)其它的语音基频检测方法概述
1.平行处理法
平行处理法是一种比较成功的音调检测的时域方法.语调信号通过略去与音调检测无关的信息而保留住信号的周期性的预处理后形成一系列脉冲,由平行的一些简单的检测器估计音调周期,在后处理器部分对这几个估值作逻辑组合,输出估计的正确周期。
2.倒谱法
倒谱法,是一种有效的频域方法,特别是对于无噪语音.倒谱法是基于声道的激励一调制模型,信号的倒谱是其功率的对数的傅里叶变换。
3.简化逆滤波法
简化逆滤波法,先降低语音信号采样率,抽取其模型参数,用这些参数对原信号进行逆滤波得出音源序列,最后求出该序列的峰值位置,从而求得音调周期。
(四)提取基频特征的平台或工具
下面罗列出一些常用提取音频特征的工具和使用平台。
| 名称 |
地址 |
适配语言 |
| Aubio |
https://aubio.org |
c/python |
| Essentia |
https://essentia.upf.edu |
c++/python |
| Librosa |
https://librosa.org |
python |
| Madmom |
http://madmom.readthedocs.org |
python |
| pyAudioAnalysis |
https://github.com/tyiannak/pyAudioAnalysis |
python |
| Vamp-plugins |
https://www.vamp-plugins.org |
c++/python |
| Yaafe |
http://yaafe.sourceforge.net |
python/matlab |
(五)需要用到基频特征的语音应用
情感计算相关的应用一般会着重使用基频特征作为模型的重要特征。参考一篇计算机研究应用的期刊——《基于基频特征的情感语音识别研究》[1]。本文从语音的基频特征出发,统计了不同情感下语音基频的变化规律,确定了基于基频的情感语音特征,最后用GMM进行建模和识别,对于语音情感识别作了初步探讨,取得了较好的效果。
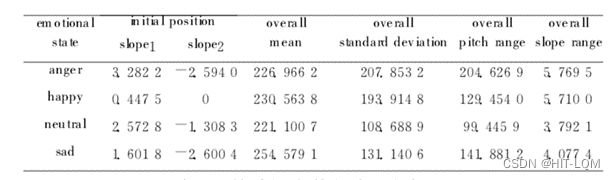
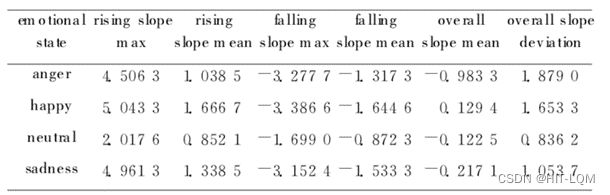
通过对大量的情感语句的基频进行观察分析,得到这样的结论:对于同一个句子,不同情感状态下的基频变化是不同的,基频的构造特征也是不同的。如图1所示,它们是同一个句子分别在四种情感状态下的基频曲线。本文选择整个句子基频的动态范围、均值、方差、最大值、最小值来作为基频的基本特征;基频斜率的最大值、最小值、均值作为基频的扩展特征。
综合观察分析的结果,选择基频的基本特征以及扩展特征,共12维的基频特征,如下所示:
a)基频的均值、方差、动态变化范围;
b)前端部分基频的上升和下降斜率;
c)整个句子基频的上升部分斜率的最大值、均值,下降部分斜率的最大值、均值;
d)整个句子基频斜率的动态范围、均值、方差
二、语音编码算法
(一)DPCM语音编码算法中的量化误差的来源
由于计算出来的差值需要被量化,量化过程中,可能会因为差值超出可以正确量化的范围,导致量化值精度不够,从而可能导致解压过程中计算出来的值与被压缩数据不同。这种量化过程中出现的误差就是量化误差。
(二)ADPCM和CELP编码中利用计算线性预测系数的方式上的差异
ADPCM(adaptive difference pulse code modulation)综合了 APCM 的自适应特性和DPCM 系统的差分特性,是一种性能比较好的波形编码。它的核心想法是:
①利用自适应的思想改变量化阶的大小,即使用小的量化阶(step-size)去编码小的差值,使用大的量化阶去编码大的差值。
②使用过去的样本值估算下一个输入样本的预测值,使实际样本值和预测值之间的差值总是最小。接收端的译码器使用与发送端相同的算法,利用传送来的信号来确定量化器和逆量化器中的阶的大小,并且用它来预测下一个接收信号的预测值。
中、低速率语音编码器的研究成果已经应用到了移动广播通信中。码激励线性预测编码是低速卒编码方式中最有效的方式之一。CELP 编码方式由Schroeder和Atal在1980s时提出。和中速率活音编码器相比,其可以产生更低速率的码字,它是波形编码和音源编码器的结合的产物,将两者的优点结合了起来。
CELP 对于窄带和中带语音编码系统(4~16kbps)说,是一种有效的闭环分析一和成编码方法。CELP 采取分物技术进行编码,帧长一般为 20~-30ms,每一语音帧再被分成 2~-5个子帧,在每个子帧内搜素最佳的码字矢量(简称码矢量)作为激励信号。
模拟话音信号(带宽为 300~-3400Hz)经8kHz采样后,首先进行线性预测(LP) 分析,去除语音的相关性,将语音信号表示为线性预测滤波器系数,并由此构成编译码器中的合成滤波器。CBLP 在LP 声码器的垫础上,引进一定的波形准则,采用了合成分析和感觉加权矢量量化技术,通过合成分析的搜索过程搜索到最佳矢量。码本中存储的每一个码矢量都可以代替LP余量逼近语音的长时周期性(基音 Pitch)结构:用一个固定的随机码本中的矢量来逼近语音的经过短时、长时预测后的余量信号作为可能的激励信号源。激励由两部分码本组成,分别模拟浊音和清音。CELP一般用一个自适应码本中的码矢量。
CELP 编码算法将预测误差看作纠错信号,将残余分成矢量,然后通过两个码本搜寻来找出最接近匹配的码矢量,乘以各自的最佳增益后相加,代替 LP 余量信号作为 CELP 激动信号源来纠正线性预测模型中的不精确度。
(三)语音信号产生模型不够精确的原因
为了用数字信号处理方法对语音信号进行处理,首先需要建立语音信号产生的数字模型,因此,我们必须在对人的发声器官和发声机理进行研究的基础上,才能建立精确的模型。但是,由于人类语音产生过程的复杂性和语音信息的丰富性以及多样性,迄今为止还没有找到一种能够精确描述语音产生过程和所有特征的理想模型。
作为接受语音信息的人耳听觉系统,其听觉机理也是很复杂的。听觉模型的精确建立对于语音识别和理解是非常重要的,但是,目前人们对听觉机理的了解比对发音机理的了解少得多。
因此,目前的语音信号产生模型不够精确。
(四)改进
线性语音产生模型的基本假设是:肺部气流在声道中以平面波的形式传递。但是,研究表明,声道中的语音信号并不总是以平面波的形式传播,气流在通过声道腔体的某些部分时存在湍流,因此在声道模型中,语音信号应该由平面波部分的线性部分和湍流区域部分的非线性部分共同组成。
三、一种能够有商用价值的命令词识别系统
(一)命令词识别系统应用需求与所需资源
1.命令词识别任务
对于智能家居而言,将语音控制技术规模化应用于智能家居或将成为未来市场发展的新趋势之一。本系统将针对生活中常见的一些家电控制指令进行语音识别。
2.词表
共十个命令词,分别为:开门、关门、开灯、关灯、开空调、关空调、开电视、关电视、烧水、蒸饭。
3.语料采集方法和规模
用Cool Edit软件录制音频进行采集,每个词录制五遍,其中一遍为模板,其它四遍用来测试。测试样例录制时适当变化音调和音量,以模拟特定说话人不同的发声情况。
(二)功能模块分解与实现算法
1.对语音信号提取mfcc特征,特征提取算法的基本流程。
① 预加重
预加重处理其实是将语音信号通过一个高通滤波器:H(z) = 1–uz-1。
式中的值介于0.9-1.0之间,我们通常取0.97。预加重的目的是提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱。同时,也是为了消除发生过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所抑制的高频部分,也为了突出高频的共振峰。
② 分帧
先将N个采样点集合成一个观测单位,称为帧。通常情况下N的值为256或512,涵盖的时间约为20~30ms左右。为了避免相邻两帧的变化过大,因此会让两相邻帧之间有一段重叠区域,此重叠区域包含了M个取样点,通常M的值约为N的1/2或1/3。通常语音识别所采用语音信号的采样频率为8KHz或16KHz,以8KHz来说,若帧长度为256个采样点,则对应的时间长度是256/8KHz =32ms。
③ 加窗(Hamming Window)
将每一帧乘以汉明窗,以增加帧左端和右端的连续性。假设分帧后的信号为S(n),n=0,1,…,N-1,N为帧的大小,那么乘上汉明窗后为S’(n) = S(n)×W(n),其中W(n)形式如下:
![]()
不同的a值会产生不同的汉明窗,一般情况下a取0.46。
④ 快速傅里叶变换
由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。所以在乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。并对语音信号的频谱取模平方得到语音信号的功率谱。设语音信号的DFT为:
![]()
式中x(n)为输入的语音信号,N表示傅里叶变换的点数。
⑤ 三角带通滤波器
将能量谱通过一组Mel尺度的三角形滤波器组,定义一个有M个滤波器的滤波器组(滤波器的个数和临界带的个数相近),采用的滤波器为三角滤波器,中心频率为。M通常取22-26。各f(m)之间的间隔随着m值的减小而缩小,随着m值的增大而增宽。
三角滤波器的频率响应定义为:
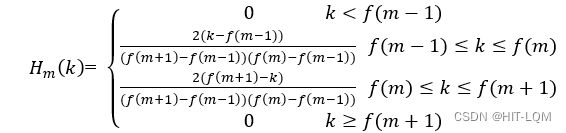
式中:
![]()
三角带通滤波器有两个主要目的:
对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。因此一段语音的音调或音高,是不会呈现在MFCC参数内,换句话说,以MFCC为特征的语音辨识系统,并不会受到输入语音的音调不同而有所影响。
此外,还可以降低运算量。
⑥ 计算每个滤波器组输出的对数能量为
![]()
⑦ 经离散余弦变换(DCT)得到MFCC系数
![]()
将对数能量带入离散余弦变换,求出L阶的Mel-scale Cepstrum参数。L阶指MFCC系数阶数,通常取12-16。这里M是三角滤波器个数。
⑧ 对数能量
此外,一帧的音量(即能量),也是语音的重要特征,而且非常容易计算。因此,通常再加上一帧的对数能量(定义:一帧内信号的平方和,再取以10为底的对数值,再乘以10)使得每一帧基本的语音特征就多了一维,包括一个对数能量和剩下的倒频谱参数。
注:若要加入其它语音特征以测试识别率,也可以在此阶段加入,这些常用的其它语音特征包含音高、过零率以及共振峰等。
⑨ 动态查分参数的提取(包括一阶差分和二阶差分)
标准的倒谱参数MFCC只反映了语音参数的静态特性,语音的动态特性可以用这些静态特征的差分谱来描述。实验证明:把动、静态特征结合起来才能有效提高系统的识别性能。差分参数的计算可以采用下面的公式:
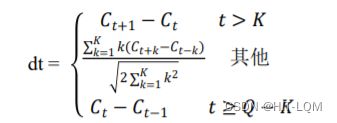
式中,dt表示第t个一阶差分;Ct表示第t个倒谱系数;Q表示倒谱系数的阶数;K表示一阶导数的时间差,可取1或2。将上式中结果再代入就可以得到二阶差分的参数。
总结:因此,MFCC的全部组成其实是由N维MFCC参数(N/3MFCC系数+N/3一阶差分参数+N/3二阶差分参数)和帧能量(此项可根据需求替换)组成。
由此可知,39维的MFCC参数即由13维MFCC系数、13维一阶差分参数和13维二阶差分参数组成。
2.mfcc特征提取的方法
① HTK工具包
配置好list_v1.scp文件后,运行“hcopy -A -D -T 1 -C tr_wav.cfg -S list_v1.scp”命令即可。
list_v1.scp文件配置部分截图如下。

读取.mfc文件的代码如下。
1. '''''读取.mfc二进制文件'''
2. def readmfcc(filename):
3. fid = open(filename, 'rb')
4. nframes,frate,nbytes,feakind = struct.unpack('>IIHH',fid.read(12))
5. '''''
6. nframes: number of frames 采样点数
7. frate: frame rate in 100 nano-seconds unit
8. nbytes: number of bytes per feature value
9. feakind: 9 is USER
10. '''
11. ndim = nbytes//4 # feature dimension(4 bytes per value) 39维度
12. mfcc0 = np.empty((nframes,ndim))
13. for i in range(nframes):
14. for j in range(ndim):
15. mf = fid.read(4)
16. c = struct.unpack('>f',mf)
17. mfcc0[i][j] = c[0]
18. fid.close()
19. return mfcc0
② python库
利用librosa库,提取mfcc特征,调用代码如下。
1. '''''利用librosa库,提取mfcc特征'''
2. def mfcc(filename):
3. y, sr = librosa.load(filename, sr=None) # Load a wav file
4. mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=39) # extract mfcc feature
5. return mfccs.transpose()
特征提取部分运行结果的截图
下面给出利用HTK工具包进行特征提取的部分截图。


特征文件内容的截图
下面给出利用HTK工具包进行特征提取的部分文件内容的截图。

3. DTW计算
(1) 开发工具
编程语言:python 3.6.4
编程工具:PyCharm 5.0.3、Anaconda3-5.1.0
操作系统:Windows 10 64-bit
(2) DTW算法
算法代码如下。
1. '''''
2. dtw算法
3. wavedata1: mfc文件1
4. wavedata2: mfc文件2
5. '''
6. def dtw(wavedata1, wavedata2):
7. # 初始化
8. len1 = len(wavedata1)
9. len2 = len(wavedata2)
10. D = np.empty((len1+1,len2+1)) # 记录代价
11. P = np.empty((len1+1,len2+1,2)) # 记录路径
12. D[0][0] = 0
13. P[0][0] = [0, 0]
14. for i in range(1,len1+1):
15. D[i][0] = sys.maxsize
16. for j in range(1,len2+1):
17. D[0][j] = sys.maxsize
18. # 计算
19. for i in range(1,len1+1):
20. for j in range(1,len2+1):
21. d = euclidean(wavedata1[i-1], wavedata2[j-1]) # 欧氏距离
22. a1 = 2*d + D[i-1][j-1]
23. a2 = d + D[i-1][j]
24. a3 = d + D[i][j-1]
25. minD = min(a1, a2, a3)
26. if minD == a1:
27. P[i][j] = [i-1, j-1]
28. elif minD == a2:
29. P[i][j] = [i-1, j]
30. else:
31. P[i][j] = [i, j-1]
32. D[i][j] = minD
33. # 回溯路径
34. w = 0
35. m = P[len1][len2]
36. while True:
37. pm = P[int(m[0])][int(m[1])]
38. if pm[0]+1 == m[0] and pm[1]+1 == m[0]:
39. w += 2
40. else:
41. w += 1
42. if pm[0] == 0 and pm[1] == 0:
43. break
44. m = pm
45. return D[len1][len2]/w
46.
47. '''''欧氏距离'''
48. def euclidean(a, b):
49. return np.sqrt(np.sum(np.square(a-b)))
4. 计算正确率
正确检出的语料文件的个数:
正确率= 100 %
说明如下:
① 利用HTK工具包进行39维mfcc特征提取时,正确率= 95 %
② 利用python中的librosa库进行mfcc特征提取时,不同维数的正确率差异较大,列表如下。

由表可知,当利用python中的librosa库进行mfcc特征提取时,提取15维mfcc特征较好,此时正确率为百分之百。
实现代码请见github
https://github.com/QimingLee/Auditory_signal_processing
参考文献
[1]基于基频特征的情感语音识别研究.
郭鹏娟1 蒋冬梅1 Hichem Sahli2 Werner Verhelst2
1. 西北工业大学计算机学院 2. 比利时布鲁塞尔自由大学电子与信息工程系