长期换衣行人重识别(Long-Term Clothes-Changing Person Reid)数据集汇总
长期换衣行人重识别任务中目前常用的数据集
- 总览
- 目前换衣数据集的主要问题
- 数据集换衣/总体情况集统计
- DeepChange(2021)
- LaST(2021)
- COCAS(2020)
- VC-Clothes(2020)
- LTCC(2020)
- PRCC(2019)
- Celebrities-reID(2019)
总览
在长期换衣行人重识别的任务当中,数据集的获取(尤其是对于学术环境下)是一个难点,主要的困难有以下几点:
- 采集大规模的数据集比较困难。
- 采集不同的衣服的数据集比较困难。
- 采集不同衣服不同角度的数据集比较困难。
目前也有一些数据集或多或少的能够解决相关的问题,在下面按照时间顺序进行一个总结,总结的具体内容会尽量简短的概括不同数据集的优缺点,以及相关的改进措施和未来的方向。
目前换衣数据集的主要问题
- 缺乏大规模的数据集(表现比较好的PRCC数据集也只有300+的id)
- 缺乏基于视频的数据集(可以提取步态特征,而步态我认为是最有力的特征),目前几乎全部的数据集都是基于单帧图片的。
- 大规模的数据集背景比较杂乱:例如LaST和Celeb-Reid,同时这两个数据集相互之间的cross-testing也比较好,但对于其他数据集的cross-testing比较差,因为他们俩采集过程比较相似(街拍和视频截图)。
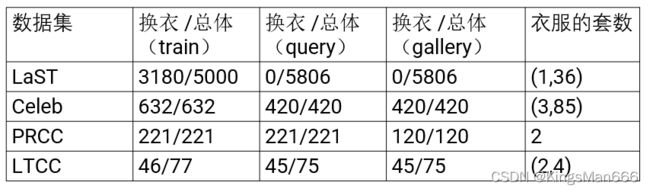
数据集换衣/总体情况集统计
目前为止,完全换衣情况的数据集有:Deep Change,PRCC和Celebrities-reID, 总体的纯换衣服的子集占数据集总数如下图所示:
表格中换衣/总体代表有多套衣服的id占总id的比例。
DeepChange(2021)
DeepChange是2021年5月份新提出的数据集,包括1121个行人的170000多张图片,有17个摄像头,时间跨度为2年。
优点:是大规模的数据集,季节跨度有12个月,也就说明了该数据集会包含同一个人穿着四季的衣服,另外,在一天之内也有跨度,包含了不同时刻的数据。同时也有一定的图像序列可以用于提取步态特征。
缺点:整体的分辨率较低(128*64),但与现实情况较为贴近。
链接:
Github:
DeepChange
数据集样例:

LaST(2021)
Large-scale Spatio-Temporal数据集是 2021 年新发布的数据集。它是从电影和电视剧中不同角色的截图中捕获的,包含 10862 个人物,超过 228000 张图像。
优点:由于数据源的特殊性,会有不同的环境条件和角度,为模型的泛化提供了很好的数据。同时,这是目前最大的换衣数据集。
缺点:与Celebrities-reID类似,它也存在背景杂乱,无法提取步态特征的问题。
链接:
Github
LaST
数据集样例:
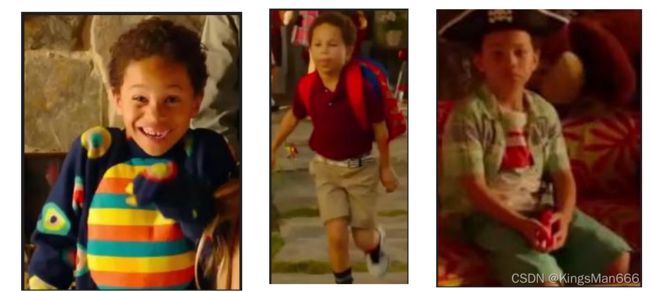
COCAS(2020)
COCAS是一个包含 5266 人的 62,382 张图片的大型数据集。
优点:所有数据均来自实拍,包括不同角度、灯光、室内或室外、遮挡等。每个人物有2-3套衣服,每套衣服有5-10张照片。
缺点:该数据集尚未开源。
链接:
COCAS
数据集样例:
VC-Clothes(2020)
VC-Clothes是来自游戏 GTA-V 的虚拟数据集,包括 512 个id和 19,060 张图像。它还有一个基于真实世界的测试数据集包括来自 28 个id的 4,324 张图像。
优点:数据集足够大,也是基于视频的数据集。
缺点:但是因为它来自游戏,所以里面的人物都是按照预先设定好的动作移动的,这说明这个数据集实际上并不适合提取步态等特征。步态信息应该是因人而异的,但是这样的话是无法采用步态来区别人的。
链接:
Github:
VC-Clothes
数据集样例:

LTCC(2020)
LTCC 包括152个人物的17138张图像,提供12个摄像头在不同光照条件下的安防摄像头图像。
优点:有助于增强模型对不同环境的适应能力,尤其是在不同的光照条件下和摄像头的低分辨率下。
缺点:数据量小,模型无法充分训练小规模数据。
链接:
Github
LTCC
数据集样例:

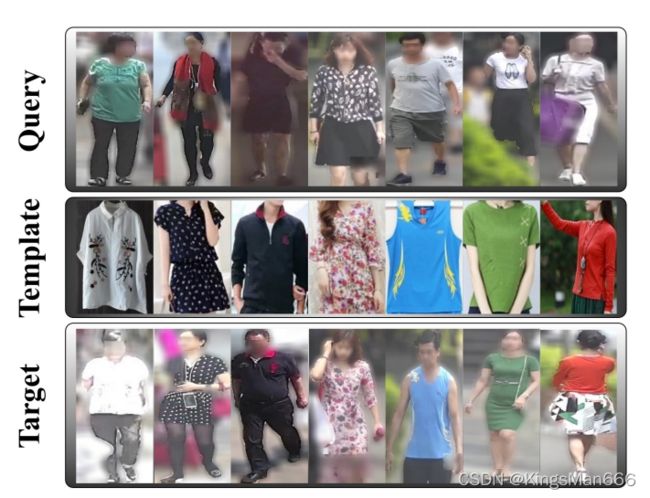
PRCC(2019)
PRCC包括来自221个人物的33698张图片,3个不同的角度,还提供人物的轮廓草图图像,方便提取人的轮廓信息。 需要注意的是,目前该领域大部分的研究(2019年之后的)都会用PRCC作为一个基准来测试模型的表现,因为它是一个严格的换衣数据集。
优点:PRCC的规模足够大,从不同的角度有严格的两套不同的衣服,因此也被广泛用于评估长期换衣行人重识别模型的表现。
缺点:它的数据是基于图像的而不是基于视频的,因此给提取步态等生物特征带来了困难。
链接:
Github
PRCC
数据集样例:

Celebrities-reID(2019)
Celebrities-reID 是最早专门针对长期换衣行人重识别任务问题提出的数据集之一。它来自名人的街拍照片,用这种方式来解决数据集比较难采的问题,包括590个人和10,842张照片。
优点:解决了换衣服数据集不够大的问题,并提供足够的训练和测试数据。
缺点:一般背景杂乱,分辨率高于安防摄像头。这些缺点会导致训练出的模型在self-testing的表现比较好,但在cross-testing的表现比较差。
链接:
Github
Celebrities-reID
数据集样例:
