【论文翻译笔记】A Systematic Evaluation of StaticAPI-Misuse Detectors
论文题目:A Systematic Evaluation of StaticAPI-Misuse Detectors
论文作者:Sven Amann, Hoan Anh Nguyen, Sarah Nadi, Tien N. Nguyen,and Mira Mezini
论文发表:IEEE TRANSACTIONS ON SOFTWARE ENGINEERING, VOL. 45, NO. 12, DECEMBER 2019
论文地址:https://arxiv.org/pdf/1712.00242.pdf
注意:
仅作本人参考笔记,机器翻译质量较低。
本翻译中的API滥用是指API误用,比较麻烦就没改。
Abstract
应用程序编程接口(API)通常具有使用规范,例如对调用顺序或调用条件的限制。API的滥用(即违反这些限制)可能导致软件崩溃,错误和漏洞。 尽管研究人员在过去的二十年中开发了许多API滥用检测器,但最近的研究表明API滥用仍很普遍。因此,我们需要了解现有检测器的功能和局限性,以提高技术水平。 在本文中,我们提出了首次定性和定量评估,该评估将静态API滥用检测器沿相同尺寸与原始作者进行了比较。 为了实现这一目标,我们在误用数据集MUBENCH的基础上,开发了API滥用分类器MUC和用于检测器比较的自动化基准MUBENCHPIPE。 我们的结果表明,现有检测器的功能差异很大,并且现有检测器尽管能够检测到误用,但精度和召回率极低。 系统的根本原因分析表明,最重要的是,检测器需要超越天真的假设,即与最常用用法的偏离即为API误用,并且需要获取其他用法示例来训练其模型。 我们提出了更强大的API误用检测器的可能方向。
Index Terms—API-misuse detection, survey, misuse classification, benchmark, MUBench
Introduction
应用程序编程接口(API)的不正确使用或API的不当使用均违反了API的(隐式)使用约束。 一个使用约束的示例,它希望在调用Iterator上的next()之前检查hasNext()是否返回真,以避免在运行时发生NoSuchElementException。 错误使用API是导致软件错误,崩溃和漏洞[1],[2],[3],[4],[5],[6],[7]的普遍原因。 尽管API使用限制的高质量文档可能会有所帮助,但至少以当前形式,通常不足以解决问题[8]。 例如,最近的一项实证研究表明,Android开发人员更喜欢非正式引用,例如Stack-Overflow,而不是正式的API文档,尽管前者提倡了许多不安全的API用法[9]。 我们也确认了这种非安全性API的趋势:修改基础集合后,不得使用Iterator的Iterator实例,否则会引发ConcurrentModificationException。 此约束及其违反的后果已得到详细记录。尽管如此,对有关ConcurrentModificationException的2,854个Stack-Overflow回答中前5%的回顾显示,其中有57%的人询问如何修复包含上述误用现象的某些代码[10]。
理想情况下,开发环境应帮助开发人员实现正确的用法以及发现和解决现有的滥用问题。 在本文中,我们将重点放在识别给定代码库中的误用的工具上,特别是那些自动推断API使用规范并通过静态代码分析来识别违规的工具。 我们将这些工具称为静态API滥用检测器。
现阶段已经进行了许多尝试来解决API滥用的问题。 现有的静态滥用检测器通常会滥用模式,即频繁发生的等效API使用,并将与这些模式有关的任何异常报告为潜在的滥用[1],[11],[12],[13],[ 14],[15],[16],[17],[18],[19],[20]。 这些方法的不同之处在于它们如何定义用法和频率,以及它们应用于识别模式和违规的技术。 尽管在API滥用检测方面进行了大量工作,但API滥用在实践中仍然存在,如最近的研究显示[9],[21]。 为了提高API滥用检测的最新水平,我们需要了解现有方法之间的比较方式,以及它们当前的局限性。 这将使研究人员可以通过增强其优势并克服其弱点来改进API滥用检测器。
在这项工作中,我们提出了API滥用分类(MUC)作为API滥用的分类法,并提出了评估静态API滥用检测器功能的框架。 为了创建这样的分类法,我们需要各种不同的API滥用示例。 在我们之前的工作中,我们描述了MUBENCH,这是一个90个API滥用的数据集,它是通过检查来自现有错误数据集的1200多个报告并进行开发人员调查而收集的[3]。 MUBENCH向我们提供了创建分类法所需的滥用示例。 为了涵盖API滥用的整个问题空间,在本文中,我们将通过研究API使用指南[8],[22]中的示例,为该数据集添加更多误用。 使用MUC,我们在质量上比较了12个现有的探测器,并确定了它们的缺点。 例如,我们发现只有很少的检测器能够检测到与条件或异常处理相关的误用。 我们与检测器的原始作者确认了这一评估。
上一步为我们提供了现有检测器的概念比较。 我们还希望通过经验来比较这些API滥用检测器的精度和调用率。 由于检测器使用的底层机制和表示形式不同,因此这是一项艰巨的任务。 为了进行这种经验比较,我们建立了MUBENCHPIPE,这是第一个对API滥用检测器进行基准测试的自动化管道。我们的自动基准测试利用了MUBENCH和我们在这项工作中收集到的误用,并在其上创建了一个基础结构来运行检测器并比较其结果。 我们基于29个实际项目和25个手工制作的示例执行了三个实验,以经验评估和比较四个最新探测器。 我们排除了其他八个检测器,因为两个检测器依赖于已终止的Google代码搜索[23],五个目标C / C ++代码和一个目标Dalvik Bytecode,而我们的基准测试包含Java滥用行为。 在实验P中,我们在每个项目的设置中测量检测器的精度,在检测器中,他们挖掘模式并检测来自MUBENCH的单个项目中的违规行为。 在实验RUB中,我们针对MUBENCH中已知的误用情况确定了探测器召回的上限。 通过为检测器提供精心设计的正确用法示例,使他们适应所需的模式,我们可以排除训练公式中数据不足的可能性。 最后,在实验R中,我们根据每个项目的设置,对MUBENCH数据集和检测器自己从ExperimentP确认的发现进行了测量。
我们的概念分析显示了API滥用的许多先前被忽略的方面,例如错误的异常处理和冗余调用。 我们的定量结果表明,如果为模式挖掘提供了正确的用法,则误用检测器能够检测到误用。 但是,它们的精度极低,并且在现实环境中会被召回。我们确定了误报的四个根本原因和误报的七个根本原因。 最重要的是,为了提高精度,检测器需要超越天真的假设,即偏离最频繁使用情况对应于误用,例如,通过建立概率模型来推理其各自上下文中的使用可能性。 为了提高召回率,检测人员需要获取可能来自不同来源的更多正确的用法示例,并考虑程序语义,例如API用法之间的类型层次结构和隐含依赖关系。 这些新颖的见解可以通过我们的自动基准测试来实现。 我们的经验结果代表了一个警钟,揭示了该领域工具和评估策略的严重实际限制。 最重要的是,检测器的召回率极低,通常无法评估。 此外,我们发现检测器在单个项目中的应用似乎没有给他们足够的数据来学习正确使用API的良好模型。
总而言之,本文对API滥用检测领域做出了以下贡献:
- API滥用的分类法MUC,提供了一个概念框架来比较API滥用检测器的功能。
- 对基于MUC的12个最新的误用检测器进行了调查和定性评估。
- 一个针对API滥用检测器的公开自动化基准测试管道MUBENCHPIPE,它有助于对滥用检测器进行系统且可重现的评估。
- 使用MUBENCHPIPE的对四个现有误用检测器的召回率和精度进行的经验比较。我们的工作是首次在概念和实际水平上比较不同的检测器,更重要的是,这是第一个测量检测器的召回率的方法,揭示了它们的不良性能。
- 对检测器精度低和召回率低的根本原因进行系统分析,以使研究人员采取行动。
我们的基准测试基础结构是公开可用的[24],我们的Web页面[10]提供了有关结果的完整详细信息。
2.BACKGROUND AND TERMINOLOGY
API的用法(简称用法)是使用给定的API完成某些任务的一段代码。 它是基本程序元素的组合,例如方法调用,异常处理或算术运算。 API使用中此类元素的组合受到约束,具体取决于API的性质。 我们称这种约束为使用约束。 例如,可能需要以特定的顺序调用两种方法,除法不能与零的除数一起使用,并且文件资源需要沿着所有执行路径释放。 当一种用法违反一个或多个此类约束时,我们称其为滥用,否则称为不正确的用法。
可以通过对源代码或二进制文件的静态分析以及通过动态分析(即运行时监视或运行时数据(例如跟踪或日志)的分析)来进行API滥用的检测。 在这两种情况下,检测都需要指定正确的API使用规范以发现违规情况,或者需要指定滥用以查找实例。 可以由专家手动制作这些规格,或者由算法自动推断。 自动规范推断(排序)可以再次例如基于代码样本或文档而静态地,以及例如基于跟踪或日志而动态地接近。
由于手动制定和维护规范的成本很高,因此在这项工作中,我们专注于自动检测器,我们称此类工具为API滥用检测器。 在文献中,我们找到了静态滥用检测器,它可以静态挖掘规范并通过静态分析检测滥用,例如[1],[13],[15];动态滥用检测器,它可以动态挖掘规格并通过动态分析来检测滥用,例如, [25],[26]; 混合滥用检测器,例如,将动态规范挖掘与静态检测结合在一起的方法[27]。 在这项工作中,我们专注于静态API滥用检测器。
静态API滥用检测通常是通过检测异常代码[1],[11],[12],[13],[14],[15],[16],[17],[18],[19], [20],[28]。 关键思想是错误违反了代码应遵守的约束,并且在足够多正确使用示例的情况下,此类违反会出现异常。 我们称这种在程序中经常出现的用法为pattern。 通过检测异常代码来识别错误的假设是,模式与正确的用法(规范)相对应,因此,与这些模式有关的异常是滥用。 这样的方法可以发现流行的库 [1],[11],[13],[15],[19],[28]在使用中的错误。
在我们以前的工作[3]中,我们通过查看21个现实项目的错误报告并就API滥用对开发人员进行了调查,收集了JavaAPI滥用的数据集。 我们称此数据集为MUBENCH。 它包含90个滥用,实际项目中的73个滥用和调查中的17个滥用(请参见表1,第1行)。 对于每个现实世界中的滥用,数据集都会标识该滥用在哪里的项目,包含该滥用的项目版本以及修复该滥用的提交。 对于其他滥用,MUBENCH提供了手工制作的滥用示例及其修复程序。

在我们以前的工作[3]中,我们通过查看21个现实项目的错误报告并就API滥用对开发人员进行了调查,收集了JavaAPI滥用的数据集。 我们称此数据集为MUBENCH。 它包含90个滥用,实际项目中的73个滥用和调查中的17个滥用(请参见表1,第1行)。 对于每个现实世界中的滥用,数据集都会标识该滥用在哪里的项目,包含该滥用的项目版本以及修复该滥用的提交。 对于其他滥用,MUBENCH提供了手工制作的滥用示例及其修复程序。
3.THE API-MISUSE CLASSIFICATION(MUC)
在本节中,我们介绍API滥用分类,这是我们针对API滥用的分类。 我们从MUBENCH数据集中的滥用示例中得出MUC。 在第4节中,我们使用MUC定性比较现有的API滥用检测器的功能。 在第7节中,我们使用MUC定义我们对探测器性能的期望。 在介绍分类本身之前,我们简要讨论现有的分类,以激发对MUC的需求。
3.1 Motivation for MUC
(1.)IEEE有一个用于对软件缺陷进行分类的标准[29],它是IBM ORTHOGONALDEFECTCLASSIFICATION(ODC)[30]的基础。 ODC使用缺陷类型作为对缺陷进行分类的方面之一。 缺陷类型由概念上的程序元素(例如函数,检查,赋值,文档或算法)和违规类型(即丢失或不正确)组成。 (2.)最近,贝勒等。 [31]提出了GENERAL DEFECT CLASSIFICATION(GCD),这是一种远程ODC后裔,专为比较自动化静态分析工具的功能而设计。这两种分类都涵盖了所有类型的软件缺陷的整个领域。 为了比较API滥用检测器的功能,我们需要对两者中的一个类别子集进行更细粒度的区分。
过去的工作介绍了API使用指令的实证研究和分类法[8],[22]。 这些指令中的许多指令可以被视为我们术语中的使用限制,因此,它们的违规行为被视为滥用。 但是,其他指令没有制定约束条件。 示例是明确允许将null作为参数传递的指令和指示实现行为的替代方法(可能具有不同的权衡)的指令。 因此,我们不能将使用指令的分类法直接转换为滥用的分类法。 相反,为了考虑可以被视为使用限制的方向,我们通过手工制作的违反它们的滥用示例来扩展MUBENCH [3],这是我们从研究中的示例中得出的。这给我们带来了10种额外的滥用,从而导致总计 用于MUC和实验的100种滥用(请参阅表1,第2行)。 为简单起见,我们随后将此扩展数据集称为MUBENCH。
3.2The Classification
我们使用扎根理论[32]的变体开发了MUC:遵循我们的API滥用概念,即一个或多个违反API使用规范,这项工作的第一作者研究了MUBENC中的所有滥用,提出了特征标签 直到每次滥用都被标记了至少一个标签。 随后,所有作者迭代地重新审视了标记的滥用,以统一语义上等效的标记和与组相关的标记,直到我们有了一致的分类法为止。 最后,我们有两个维度,它们的交集描述了MUBENCH中的所有违规:所涉及的API-使用元素的类型和违规的类型。因此,我们将违例定义为一对violation type和API-usage element。
API-usage element是出现在API用途中的程序元素。 MUBENCH中的误用涉及以下元素:method calls,conditions,iterations, 和exception handling.。 请注意,我们将基本运算符(例如算术运算符)视为方法。 对于条件,由于其独特的属性,我们进一步区分了空校验,值或状态条件,同步条件和上下文条件。
violation type描述了用法如何违反关于给定用法元素的给定用法约束。 在MUBENCH中,我们发现两种违规类型:missing和redunddant。 缺少类型的违例来自强制使用元素存在的约束。 它们通常会导致程序错误。 此类违规的一个示例是“缺少方法调用”。 违反冗余类型的约束来自强制使用元素不存在或声明使用元素不必要的约束。 请注意,在任何一种情况下,元素的重复都可能具有不良影响,例如错误或性能下降。 这种冗余违规的示例是“冗余方法调用”。
表2列出了MUC的总结。 单元格中的数字显示MUBENCH中有多少次滥用有相应的违法行为。 请注意,由于一次滥用可能会导致多次违规,因此表格中的各个单元格总计超过我们收集的100次滥用。 该表显示,最常见的冲突是缺少方法调用,空检查以及值或状态条件。 冗余调用和missing exception处理的频率较低,但仍然很普遍,尽管我们只有很少的其他违规示例。
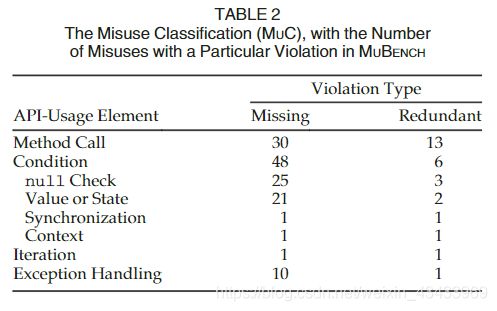
现在,我们讨论表2中所示的不同违规类别,其中按涉及的API使用元素分组。
3.2.1 Method Calls
方法调用是API使用的最重要元素,因为它们是客户端代码和API之间进行通信的主要方式。
一种违规类别是缺少方法调用,如果使用未调用API使用约束所强制的特定方法,则会发生这种情况。 例如,如果用法在向JFrame添加元素后未在JFrame上调用validate(),则更改变为可见是必需的。
另一种情况是冗余方法调用,如果usage调用受API usage约束限制的某个方法,则会发生这种情况。 例如,如果用法在当前正在迭代的列表上调用remove(),则在后续迭代中导致异常。
3.2.2 Conditions
客户代码通常需要确保与API进行有效通信的条件,以便遵守API的使用限制。 通常有其他方法可以确保此类条件。 例如,要确保一个集合不为空,可以检查isEmpty(),检查其size()或向其中添加一个元素。 请注意,特别是检查也是客户端代码根据程序输入改变用法的一种手段。
一种违规类别是缺少条件,如果使用不能确保API使用约束所规定的某些条件,则会发生这种情况。 一种情况是缺少空值检查,例如,一种用法是否无法确保接收者或呼叫的参数不为空。另一种情况是缺少值或状态条件,例如,一种用法是否无法确保使用一个键来访问Map之前,Map包含某个键 。 在多线程环境中,可能会发生缺少同步的情况,例如,如果使用情况在更新从多个线程访问的哈希映射之前未获得锁[22]。 最后,例如,如果用法未能确保在事件调度线程(EDT)上更新SWING中的GUI组件,则可能会发生缺少上下文条件的情况[8]。
另一种情况是冗余条件,其中条件阻止用法的必要部分(例如方法调用)沿某些执行路径执行,或者仅是冗余的。一种情况是冗余空检查,例如,如果用法仅在对相应对象调用了方法之后才检查空性。 另一种情况是冗余值或状态条件,例如,如果用法在保证包含元素的集合的情况下上加入isEmpty()。 在多线程环境中,可能会发生冗余同步条件,例如,如果使用情况请求它已经持有的锁,则可能导致死锁。 最后,冗余的上下文条件也可能发生,例如,如果在另一个线程上执行了JUNIT断言,则JUNIT框架无法捕获其断言。
3.2.3 Ieration
迭代是与API交互的另一种方法,特别是与集合和IO流一起使用。 它采用循环和递归方法的形式。 请注意,各个用法约束是关于(不是)重复使用(一部分),而不是控制执行的条件。
一个违规类别是缺少迭代,如果不对usage重复检查一部分使用情况后必须再次检查APIusage约束要求的情况,则会发生这种情况。 例如,Java文档规定,调用Object.wait()必须始终在循环中发生。 用法调用wait()暂停当前线程,直到接收到中断为止。 它这样做是为了等待直到某种条件成立,例如直到资源变得可用为止。 由于中断随时可能发生,因此恢复使用必须检查条件,如果不成立,则再次检查call wait()。 请注意,在条件变为真之前,这可能会发生任意次数。 因此,对条件仍然进行检查的用法违反了用法约束。
另一种情况是冗余迭代,如果重复使用的一部分,则可能会重复执行API使用约束任务一次或仅是冗余的,就会发生这种情况。 例如,可以在循环中重用aCipherinstance来加密值的集合,但是通过调用init()进行初始化必须恰好发生在一次,即循环之前。 请注意,如果在循环内调用了init(),则只对方法进行了一次调用(使用限制所要求的),但是将其包含在迭代中会引起冲突。
3.2.4 Exception Handling
异常是API将错误传达给客户端代码的一种方式。 不同错误的处理通常取决于特定的API。
一种违规类别是缺少异常处理,如果使用未按照API使用约束的规定采取措施从可能的错误中恢复,则会发生异常处理。 例如,在使用外部提供的加密密钥初始化aCipher时,应处理han-dleInvalidKeyException。 另一个例子是使用后也需要关闭的资源,如果有异常情况也是如此。 通常通过finallyblock来实现这种保证,但是也可以使用try-with-resources构造甚至在多个catchblock中进行相应的处理。
另一种情况是冗余异常处理,如果用法截获了不应明确捕获或处理的异常,则会发生这种情况。 例如,在应用程序中执行命令时,catchingThrowable可能会抑制cancellationException,从而阻止用户取消该命令。
4.CONCEPTUAL CLASSIFICATION OF EXISTING MISUSE DETECTORS
为了提高API滥用检测的技术水平,我们需要了解现有滥用检测器的功能和缺点。 为了识别检测器,我们从Robillard等人在自动API属性推断技术调查中列出的有关API滥用检测的出版物开始。 [33]。 根据ACM数字图书馆或IEEE Xplore数字图书馆,对于每个出版物,我们都将其视为相关作品的所有出版物以及引用它们的所有出版物进行了研究。 我们递归地重复此过程,直到没有发现新的检测器为止。
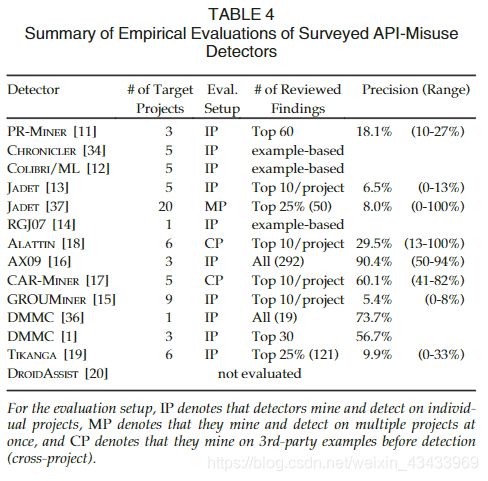
我们将MUC用于检测器的定性比较,即我们评估每个检测器相对于MUC的概念能力,以获得现有检测器的概念分类。 我们使用已发布的描述和每个检测器的结果来从概念上确定它们可以检测到哪些MUC类别。 为了降低主观性,我们与各自的作者确认了我们的能力评估和探测器的描述,但PR-MINER和COLIBRI / ML的作者没有对此做出回应。 表3总结了结果。 我们还描述了用于评估每个检测器的策略,并总结了表4中的策略。

PR-MINER是C的滥用检测器[11]。 它将sussus编码为在同一函数内调用的所有函数名的集合,然后使用频繁项集挖掘来查找最少支持15种用法的模式。这里的违规行为是模式的严格子集,发生频率至少是该模式的十倍。 为了修剪误报,PR-MINER应用过程间分析,即,对于每次发生的违规,它都会检查丢失的调用是否在被调用方法中发生。 此分析最多跟踪3个级别的呼叫路径。 所报告的违规行为由相应模式的支持进行排序。PR-MINER检测到缺少的方法调用。 PR-MINER作者的评估将检测器分别应用于三个目标项目,从而发现了违反项目特定模式的情况。 作者回顾了所有项目中报告的前60名违规行为,发现了18.1%的真实阳性(单个项目中分别为26.7%,10.0和14.3%)。
CHRONICLER是C的滥用检测器[34]。 它从过程间控制流图中挖掘频繁的呼叫优先关系。 如果关系在所有执行路径中至少占80%,则认为该关系是频繁的。 这种关系不成立的路径被报告为冲突。CHRONICLER检测到缺少的方法调用。 由于循环只展开一次,因此无法检测到缺少的迭代。 CHRONICLER的作者进行的评估将检测器应用于五个项目,从而发现了违反项目特定模式的行为。 作者将已识别的协议与一个API的已记录协议进行了比较,并讨论了一些通过其工具发现的实际错误的示例。
COLIBRI / ML是C的另一种滥用检测器[12]。 它使用形式概念分析[35]重新实现PR-MINER,以加强该方法的理论基础。 因此,其功能与PR-MINER的功能相同。 COLIBRI / ML的作者进行的评估将检测器应用于五个目标项目,从而发现了违反项目特定模式的情况。 尽管在论文中预先提出了一些检测到的违规行为,但没有报告有关检测器发现质量的统计数据。
JADET是Java的滥用检测器[13]。 它使用COLIBRI / ML [12],但它不仅编码方法名称,还编码方法调用顺序和用法中的接收者。 它建立一个有向图,其节点表示对给定对象的方法调用,其边缘表示控制流。 从该图可以得出每个呼叫顺序关系的一对呼叫。 这些对的集合构成了Min-ing的输入,Min-min的最小支持为20,标识了模式(即,对的集合)。违反可能会丢失所侵犯模式的最多2个属性,并且至少需要发生一次 次数比模式少。 检测到的违规将按u s = v进行排序,从而说明违规模式的支持情况,针对该模式违规的次数以及该模式的唯一性因素。 JADET检测到丢失的方法调用。 JADET的作者将检测器应用于五个目标项目,从而发现了违反项目特定模式的情况,它可能会将缺失的循环检测为从循环头中的方法调用到其自身的缺失的调用顺序关系。作者审查了每个项目报告的前十大违规情况,发现真正的正面肯定率为6.5%(单个项目的正确率分别为0、0、7.7、10.5和13.3%)。 其他调查结果分为代码气味(6.5)或提示1(35.0%)。
后来的研究[37]使用最小模式支持200,一次将JADET应用于6,097个项目(多项目设置)。 作者回顾了来自20个项目的随机样本中前25%的发现,共50个发现,发现8%的真实阳性。 其他发现被归类为代码气味(14.0%)。
RGJ07是C的滥用检测器[14]。 它将用法编码为每个变量的属性集。 属性是与文字,函数调用中的参数位置以及赋值的比较。 对于每个调用,它都会为调用的参数创建一组属性集。 它针对特定功能的所有组,应用序列挖掘来学习控制流属性的公共序列,并使用频繁项挖掘来识别所有其他属性类型的所有公共集,随后识别出违反公共属性序列和集的情况。 RGJ07旨在检测丢失的情况。 从它编码的属性中,它可以检测缺少的空检查和缺少的值或状态条件。 由于模式包含对参数的先前调用,因此如果各个调用与模式中的另一个调用共享参数,它也可能检测到未调用。 RGJ07作者的评估将检测器应用于单个项目,从而发现了违反项目特定模式的行为。 作者讨论了使用其方法检测到的实际错误的几个示例,但没有报告检测性能的统计信息。
ALATTIN是Java [18]的滥用检测器,它是用于条件检查的专用替代模式。 对于每个目标方法,它都会查询代码搜索引擎GOOGLECODESEARCH以查找示例用法。 从每个示例中,提取出一组关于接收器的条件检查和条件检查的规则,参数以及m的返回值,例如“ booleancheck onreturnofIterator.hasNextbeforeIterator.next”。 然后,对这些规则应用频繁项目集挖掘,以最少40%的支持率获得模式。 对于每个这样的模式,它都提取不遵守该模式的所有组的子集,并对该子集重复挖掘以获得频率不低于20%的不频繁模式。 最终,它通过析取结合了同一方法的所有频繁和不频繁模式。 如果拥有init的规则集不是任何替代模式的超集,则分析的方法将产生冲突。 违规由相应模式的支持进行排名。 因此,ALATTIN会检测到缺失的null检验以及缺失的值或状态条件,这些条件由检验确保并且不涉及文字。 它还可能检测到检查中丢失的方法调用。 ALATTIN的作者进行的评估将检测器应用于六个项目。 由于它向代码搜索引擎查询用法示例,因此它可以检测到跨项目模式的违反情况。 作者手动审查了每个项目中前十大模式的所有违规情况,总共发现了532个结果,并确认29.5%的人发现缺失情况检查(单个项目分别为12.5、26.2、28.1、32.7、52.6和100% )。考虑到频繁使用替代模式,平均可将误报率降低15.2%,将准确性提高到33.3%。 考虑到频繁使用和不频繁使用的替代方法,平均误报率平均降低了28.1%,导致准确率达到了37.8%,但又引入了1.5%的误报率,因为多次发生的误用被误认为是不常见的模式。
AX09是用于C [16]的滥用检测器,专门用于检测错误的错误处理,通过返回(并检查)错误代码来实现。 它区分正常路径,即从主要功能的开始到结束的执行路径,以及错误路径,即从主要功能的开始到错误处理块中的退货声明的路径。 AX09使用下推模型检查来生成诸如方法调用序列之类的路径,并将频繁子序列挖掘应用于发现模式,最低支持80%(但至少使用5次)。 然后,它使用下推模型检查来验证对这些模式的遵守情况并识别出各自的违规行为。 最后,它通过跟踪变量值并排除不可能发生的错误情况来过滤误报。 它可以检测错误处理函数中缺少的错误处理以及方法调用。 由于它可以通过一组预定义的检查来识别错误处理块,因此在缺少错误处理块的情况下,它还可以检测到缺少空检查和值或状态条件的缺失.AX09作者的评估将检测器分别应用于三个项目,从而发现了违规情况 项目特定模式。 作者手动审查了所有292个发现,并确认90.4%的真实阳性(单个项目分别为50.0、90.3和93.5%)。
CAR-MINER是C ++和Java的滥用检测器[17],也专门用于检测错误的错误处理。 对于给定代码语料库中的每个分析方法,它都会查询代码搜索引擎GOOGLECODESEARCH以查找示例用法。 从示例中,它构建了一个异常流图(EFG),即带有额外边缘的控制流图,以实现出色的流程。 它从EFG生成正常的呼叫序列,这些序列导致当前分析的呼叫和例外呼叫序列,这些序列沿着异常边缘从呼叫中引出。 随后,它挖掘正常序列和异常序列之间的关联规则,最小支持为40%。 为了检测违规,CAR-MINER提取目标方法调用的常规调用序列和异常调用序列。 然后,它使用学习的关联规则来确定预期的例外处理,如果实际序列不包括违规,则报告违规。 CAR-MINER检测错误处理函数之间缺少的异常处理以及方法调用。 CAR-MINER的作者进行的评估将检测器应用于五个项目。 由于它向代码搜索引擎查询用法示例,因此它可以检测到跨项目模式的违反情况。 作者手动检查了每个项目违反前十名关联规则的所有行为,总共264项违规行为,并确认60.1%的人识别错误处理错误(单个项目中为41.1%,54.5%,68.2%,68.4%和82.3%)。 其他发现被归类为提示(3.0%)。
GROUMINER是Java的滥用检测器[15]。 它为每个目标方法创建基于图形的对象使用表示(GROUM)。GROUM是有向无环图,其节点表示方法调用,分支和循环,并且其边缘编码控制和数据流。 GROUMINER在此类图的集合上进行频繁子图挖掘,以检测最小支持为6的重复使用模式。当子模式的所有出现中至少有90%可以扩展到更大的模式时,但是有些不能,则有瑟拉瑞纳可伸长的出现 被视为违法行为。 请注意,此类违规始终恰好是一个无节点而不是一个模式。 模式和违规的检测同时发生。 违规行为按其稀有程度排序,即模式的支持程度高于违规的支持程度。 GROUMINER检测丢失的方法调用。 它还可以检测丢失的条件并以缺少分支或循环节点的粒度进行循环。 但是,它不能考虑实际情况。 GROU-MINER作者的评估将检测器分别应用于9个项目,从而发现了违反项目特定模式的情况。 作者审查了每个项目中排名前10位的违规行为,共得出184个发现,并发现了5.4%的真实肯定(单个项目的3倍0%,5倍6.7%和一次7.8%)。 其他发现被分类为code smells(7.6%)或提示(6.0%)。
DMMC是Java [36]的滥用检测器,专门用于调用方法。 该检测基于类型用法,即在给定方法中在给定接收器类型上调用的方法集。 如果两种用法的预期集完全匹配,则两种用法完全相似;如果其中一种包含正好一种附加方法,则它们几乎相似。 该检测基于这样的假设:违规应仅具有很少的完全相似的用法,但有许多几乎相似的用法。用法x被违规的可能性以范围分数¼1jEðxÞj=ðjEðxÞjþjAðXÞjÞ表示,其中EðxÞ是一组与x和Aðxexactly完全相似的用法。 几乎相似的 如果用法的陌生度得分高于0.97,则认为该用法为违规。 DMMC仅通过一个缺失的方法调用来检测滥用情况.DMMC的作者进行评估,将检测器应用于单个项目,从而发现了特定于项目的违规行为。作者手动审查了所有奇怪度得分均高于97%的发现,总计 19个发现,并确认73.7%为真实肯定。 后来的研究[1]将DMMC分别应用于三个项目,从而发现了针对一组预定义API的特定于项目的违规行为。 作者报告说,他们手动检查了大约30个发现,并确认了17个(56:7%)是肯定的。其他被归类为使用过的API中的错误的变通办法。
TIKANGA是在JADET上构建的Java [19]滥用检测器。 它将简单的调用顺序属性扩展到有关对象用法的generalComputation树逻辑公式。 具体来说,它使用需要进行特定调用的公式,需要顺序进行两次调用的for-mulae以及需要特定调用才能发生的公式。 它使用模型检查来确定所有这些公式,并且在代码库中的最小支持为20。 在违规用法中,对当前公式集与缺失公式集之间的关联的置信度[38],对违规进行排序。 然后,它应用形式概念分析[35]来同时获取模式和违规。 TIKANGA的功能与JADET相同。 TIKANGA的作者进行的评估将检测器分别应用于六个项目,发现违反了特定于项目的模式。作者手动审查了每个项目中前25%的调查结果,总共有121个发现,并确认了9.9%的真实阳性(单个项目的0、0、8.3、20.0、21.4和33.3%)。 其他发现被归类为代码气味(29.8%)。
DROIDASSIST是Dalvik字节码(AndroidJava)[20]的检测器。 它从源代码生成方法调用序列,并从中学习隐马尔可夫模型,以计算特定调用序列的可能性。 如果可能性太小,则将序列视为违规。 然后,DROIDASSIST探索序列的不同修改(添加,替换和删除呼叫),以找到稍微修改的,更有可能的序列。 这使它可以检测丢失和冗余的方法调用,甚至可以为它们提出解决方案。 DROIDASSIST的作者在相应的论文中未对此机制进行评估。
摘要:所有检测器均使用代码(摘要)作为训练和验证输入。 有些要求使用编译格式的代码,例如Java字节码,而另一些则直接使用源代码。 检测器通常将用法编码为集合,序列或图形。 对于同时编码用法元素,顺序和数据流关系,图形表示似乎很有希望。 除DROIDASSISTandDMMC以外,检测器根据其用法表示通过频繁项集/子序列/子图挖掘来挖掘模式。 为了检测违规,他们挖掘了很少见到的模式的不可扩展部分。这意味着它们无法检测到冗余元素,因为此类元素的使用绝不是任何模式的一部分。 DROIDASSIST例外,它可能不太可能找到冗余呼叫。
表3总结了检测器针对MUC的功能。 总体而言,我们发现检测器仅涵盖所有API滥用类别的一小部分。 尽管所有检测器都可以在某种程度上识别丢失的方法调用,但只有四个检测器可以识别丢失的空检查和丢失的值或状态条件,只有三个可以识别丢失的迭代,只有两个可以识别丢失的异常处理。 没有一个探测器针对所有这些类别。
现有的检测器同时使用绝对最小支持阈值和相对最小支持阈值来识别模式。 再次例外的是DROIDASSIST和DMMC,它们使用概率方法。 由于许多检测器会产生大量的误报,因此它们使用各种排名策略。 其中大多数主要依靠模式支持,但也使用了一些不同的概念,例如稀疏性,陌生性或信念。在任何出版物中都未报告对不同排名策略的比较。
表4总结了调查报告的实证评估,如其原始论文所报道。 多数评估将检测器分别应用于项目。 在这种情况下,检测人员将学习特定于项目的模式并识别相应的违规行为。 项目数量从1到20不等(平均5.3;中位数5)。 具体的项目样本都是截然不同的,甚至大部分都是不相交的。
为了评估检测性能,大多数作者回顾了他们的检测器的前X个发现,其中X是固定数字或百分比。 然后,他们要么呈现真实阳性的正相关性,要么测量检测器的精度。许多评估还提出了其他发现类别,例如代码气味,以将误报与其他对开发人员仍然有价值的非滥用发现区分开。 一个发现何时属于哪个类别(如果提供)的定义,即使出版物使用相同的标签(例如“bug”或“code smells”),也会有所不同。没有评估会考虑各个检测器的召回率。
总体而言,看来专注于特定违规(例如错误处理或缺少方法调用)的检测器具有更高的精度。 但是,仅基于检测器报告的经验结果对检测器进行比较是不可靠的,因为目标项目,审查样本量以及评估检测器发现的标准在研究之间存在差异。
5. EXPERIMENTAL SETUP
在第4节中,我们从概念上比较了检测器的功能。 在本节中,我们描述了经验性的比较其功能的实验设置。 我们设计了三个实验,以测量探测器的精度和召回率。 我们以MUBENCH真实数据集为基础建立这些实验。 这使我们能够比较相同目标项目上的所有检测器,并就相同的已知滥用进行比较。
主题检测器。在本研究中,我们重点研究Java API的滥用检测器,因为MUBENCH包含Java-API滥用的示例。 我们的调查确定了七个此类检测器。 我们联系了各自的作者,并得到了所有人的答复。 但是,我们了解到我们无法运行CAR-MINER和ALATTIN,因为它们都依赖于GOOGLECODESEARCH,该服务不再可用[23]。我们排除了DROIDASSIST,因为其实现仅支持Dalvik Bytecode,2而MUBENCH中的示例是通用Java项目, 编译为Java字节码。这给我们留下了四个检测器JADET,GROUMINER,TIKANGA和DMMC。
滥用数据集:我们使用第2节中所述的MUBENCH查找评估的目标。 尽管GROUMINER使用源代码,但JADET,TIKANGA和DMMC需要Java字节码作为输入。 因此,我们只能在具有源代码和字节码的项目版本上进行比较。 由于字节码不适用于数据集中的大多数项目版本,因此我们通过添加必要的构建文件并修复任何依赖关系问题来自行编译它们。 我们排除了无法修复的26个项目版本(占47%)的编译错误。 最后,我们有29个可编译的项目版本和25个手工制作的示例,总共有64个误用。 请注意,某些项目版本包含多种误用。 表1中的最后三行描述了我们在各个实验中使用的该数据集的子集。 我们发布了数据集[24]供其他人在将来的研究中使用。
5.1 Experiment P
我们设计实验P来评估探测器的精度。
动机。过去的研究表明,开发人员很少使用会产生许多误报的分析工具[39],[40],[41]。 因此,为了在实践中采用检测器,需要高精度。
设置。为了测量精度,我们遵循文献中最常见的实验设置(请参见表4)。首先,我们在各个项目版本上运行检测器。 在这种情况下,他们挖掘模式并在每个项目的基础上检测违规情况。 其次,我们根据各个探测器的排名策略来手动验证每个版本上每个探测器的前20个发现。 我们限制了发现的数量,因为开发人员似乎只会考虑固定数量的发现,而不是所有可能非常多的发现。 因此,检测器最重要发现的精确度对于采用工具至关重要。 另外,我们希望限制审查每个项目版本上多个检测器的发现的工作量。
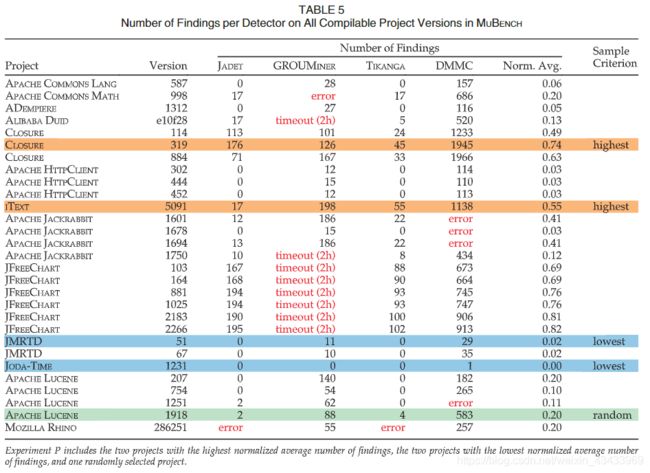
数据集:由于无法手动检查所有项目版本上所有检测器的发现,因此我们对五个项目版本进行了采样。 为了确保公平选择项目,我们首先在所有项目版本上运行所有检测器。 出于实际原因,我们在两个小时后使每个探测器在单独的projectversion上超时。 表5中汇总了运行统计信息。
JADET和TIKANG在一个项目版本上失败,而DMMC在四个项目版本上失败,因为字节码包含检测器各自的字节码工具包不支持的结构。 GROUMINER在八个项目版本上超时,在另一个版本上产生错误。 我们排除使检测器发生故障的所有项目版本。
对于其余的15个版本,我们观察到发现的总数与各个检测器相关。 表6显示,除了JADET和GROUMINER(r¼0:49)以外,所有其他检测器对的成对相关(Pearson’sr)均为强(0:75)或中等(0:5)。 这意味着,在任何给定的项目版本中,所有检测器都报告相对较大的发现结果。 我们假设调查结果的总数可能与检测者准确识别给定项目版本中的滥用情况有关。 因此,我们根据所有检测器上发现的平均归一化数量对项目版本进行采样。 我们通过所有项目版本上该检测器的最大发现数量来归一化每个探测器在所有项目版本中的发现数量。 我们对所有检测器的平均归一化数量最高的两个项目(CLOSURE [42] v319和ITEXT [43] v5091)进行采样,对所有检测器的平均归一化数量最低的两个项目(JMRTD [44] v51和JODA-TIME[45] v1231)进行采样 。 此外,我们从其余项目中随机选择一个项目版本(APACHELUCENE [46] v1918),以涵盖中间立场。 **请注意,我们从每个不同的项目中最多选择一个版本,**因为同一项目的不同版本可能共享很多代码,因此检测器可能会对它们执行类似的操作。 表1的第3行汇总了该实验P的数据集。
指标。我们计算探测器的精度,即,真实阳性数与发现数之间的比率。
审查过程:两位作者独立审查了样本项目版本的前20个发现,并将其标记为是否滥用。 为了确定这一点,他们考虑了源代码中的逻辑和文档,API的文档及其实现(如果可公开获得)。审核后,将讨论审核者之间的任何分歧,直到达成共识为止。我们报告科恩的Kawcppa得分,以衡量审核者的同意程度。 请注意,我们遵循宽松的审核流程。 例如,假设用法在调用Iterator.next()之前缺少检查 if(Iterator.hasNext())。 如果检测器发现缺少hasNext(),我们将发现标记为命中,尽管这并未明确指出应通过检查hasNext()的返回值来保护调用tonext()。 这是根据我们的直觉,即这样的发现仍可能为开发人员提供有关该问题的宝贵提示。
5.2 Experiment RUB

我们设计了实验RUB,以评估目标探测器的探测能力,即在假设他们始终挖掘所需模式的前提下,测量其召回率的上限。
动机。我们认为,对于开发人员来说,了解哪些滥用特定工具的可能是很重要的,以便确定该工具是否适合其使用情况,以及他们是否必须采取其他措施。 此外,对于研究人员来说,了解现有探测器可能会识别出哪种类型的滥用也很重要,以便指导未来的工作。 因此,我们在提供足够多正确用法的情况下测量探测器的召回率,使他们能够挖掘所需的pattern。
数据集:在本实验中,我们使用MUBENCH数据集中的所有可编译项目版本以及各自已知的误用以及手工制作的误用示例。 表1的第4行汇总了该实验RUB的数据集。
设置:请记住,我们所有的主题检测器都会挖掘模式,即频繁重复出现的API使用情况,并假定它们与正确的使用情况相对应。 他们使用这些模式来识别滥用。 进一步回想一下,每个检测器对用法和模式及其自身的挖掘和检测策略都有不同的表示。 如果检测器未能识别出特定的误用,则可能是由于(1)检测器的固有局限性,例如,因为它不能代表诸如条件之类的使用要素,或者(2)缺少相应正确用法的示例 模式挖掘,即训练数据的限制。 在实验RUB中,我们将重点放在(1)上,即,将(2)排除在等式之外,并评估检测器识别误用的一般能力。 为此,我们为检测器提供了足够多的正确用法示例,这些示例与所讨论的滥用相对应。这保证了它们可以挖掘各自的模式。 如果检测器无法在此设置中识别出误用,我们知道问题出在检测器本身上。
我们使用MUBENCH中记录的修复提交为数据集中的每个滥用手动创建正确的用法。对于每个滥用,我们在修复提交之后将方法的整个代码与滥用一起使用,并删除所有与数据无关或不依赖控件的代码 涉及滥用的物品。 我们将精心设计的正确用法的代码存储在我们的数据集中.
在实验中,我们针对数据集中每个已知的误用操作对每个检测器运行一次。 在每次运行中,我们为检测器提供包含已知误用的文件以及相应制作的正确用法的50份副本。 我们确保检测器将每个副本视为不同的用法。 我们将检测器配置为在最小支持50的情况下挖掘模式,从而确保仅从精心设计的使用方法中的代码中挖掘模式。 我们选择50作为阈值,因为它足够高以确保没有检测器会从文件中的代码中挖掘出带有误用的模式。
指标。我们为每个探测器计算两个数字。 第一个是其概念召回上限,它是数据集中与其表3中的功能匹配的已知误用的一部分。请注意,概念召回上限是离线计算的,无需运行任何实验。 第二个是检测器的经验召回上限,这是检测器实际上从数据集中所有已知的滥用中发现的滥用百分比。 理想探测器的经验召回上限应等于其概念召回上限。 否则,其实际能力与概念能力不匹配。 在这种情况下,我们调查了这种不匹配的根本原因。请注意,我们使用“上限”一词,因为这两种召回率均无法反映检测器在某个环境中的召回率,而无法保证正确使用挖掘的次数。
审查过程:为了评估结果,我们审查了所有潜在的命中点,即每个检测器的发现,这些发现将相同的文件和方法中的违规行为标识为已知的滥用,两位作者独立审查每个此类潜在的命中点,以确定它是否确实识别了已知的滥用之一。 如果至少一个潜在的命中现象标识了误用,我们将其视为命中。 审阅后,将讨论审阅者之间的任何分歧,直到达成共识为止。 我们报告科恩的Kappa得分是对评论者同意程度的衡量。 我们遵循与实验P相同的lenientreview过程。
5.3 Experiment R
我们设计实验R来评估探测器的召回率。
动机。尽管实验RUB为我们提供了滥用检测器召回的上限,但我们也想评估我们的实际召回率,如果我们自己没有为他们提供正确的用法。 由于缺乏真实的数据集,因此在我们调查的任何滥用检测论文中都没有尝试过这种实验。
数据集:作为此实验的基本事实,我们使用了MUBENCH中真实项目中的所有已知滥用以及实验P中任何检测器识别出的真阳性结果。这意味着实验R不仅可以评估对MUBENCH滥用的回忆。 ,但实际上也会相互交叉验证检测器的功能。 由于没有相应的检测器从中挖掘模式的代码,因此我们从该实验中排除了手工制作的滥用示例。 表1第5行汇总了我们用于实验R的数据集。
设置:我们分别在所有项目版本上运行所有检测器,即我们使用与针对实验P相同的每个项目设置。
指标:我们计算检测器的召回率,即实际命中次数超过数据集中已知问题的次数。
审核流程。我们以与实验RUB相同的流程审核所有潜在匹配。 这使检测人员可以回想起MUBENCH大量已知的误用。
6.MUBENCHPIPE
为了系统地评估和比较API滥用检测器,我们建立了MUBENCHPIPE,这是API滥用检测器的基准测试管道。 MUBENCHPIPE可自动执行第5节中介绍的大部分实验设置,并有助于进行本研究。 它还可以在将来为比较添加新的检测器,并使用不同的或扩展的数据集进行基准测试。 我们发布了管道[24]以供将来研究。
6.1 Automation
遵循BUGBENCH [47]和BEGBUNCH [48]等C程序的自动错误检测基准的想法,我们使用评估管道简化了我们误用数据集上多个检测器的基准测试。 MUBENCHPIPE使我们的许多评估步骤自动化,例如目标项目的检索和编译,运行检测器以及收集其发现。 MUBENCHPIPE提供了一个命令行界面来控制这些步骤。 随后,我们描述了为便于评估而实施的管道步骤。
Checkout.MUBENCHPIPE使用来自MUBENCH的记录的提交ID来获取相应项目版本的源代码。 它支持SVN和Git存储库,源存档(zip),以及MUBENCH随附的手工制作示例的特殊处理.
编译。对于每个项目版本,MUBENCHPIPE首先将整个项目源代码,包含已知滥用的单个文件以及为实验RUB设计的正确用法分别复制到一个单独的文件夹中。 然后,它使用数据集中的相应构建配置将所有Java源代码编译为Bytecode。 编译后,它将整个项目字节码,包含已知滥用的单个文件的字节码以及各自精心制作的正确用法的字节码复制到单独的文件夹中。 这样,我们可以分别为检测器提供每个部分的源代码或字节码。
检测:对于每个检测器,我们还构建了runner,以为所有检测器提供统一的命令行界面。 对于每个项目版本,MUBENCHPIPE都将调用带有各自源代码和字节码的路径的检测器。
将使用各自出版物中报告的最佳配置来调用所有检测器。 除了添加一些访问器方法以允许我们获取检测器的输出外,所有检测器的实现均保持不变。
验证。为了帮助对结果进行人工审查,MUBENCHPIPE自动将实验结果发布到审查网站[10]。 对于每次发现的检测器,网站都会显示发现的源代码以及检测器提供的任何元数据,例如违反的模式,违反的属性和检测器的置信度。
对于实验RUB和R,MUBENCHPIPE通过根据文件名和方法名将发现结果与已知的误用进行匹配,自动过滤潜在的匹配。 在审阅网站上,viewer看到了已知滥用的描述及其修复方法,以及需要审阅的一组潜在命中内容。 对于实验P,MUBENCHPIPE显示了查看站点上检测器的所有发现。
评论网站允许评论者保存对每个发现的评估和评论。 在自动计算实验统计信息(例如精度,召回率和科恩的Kappa得分)之前,它还可以确保每个发现至少有两次评论。
6.2 Reproduction, Replication, and Extension
MUBENCHPIPE带有Docker映像,该映像允许跨平台运行可重复的实验,而无需确保正确的环境设置。 它的评论网站带有第二个Docker映像,允许独立提供它。 此外,它基于PHP和MySQL,因此可以将其托管在任何现成的Web空间中。 审查网站即使在研究人员在不同地点工作时也可促进独立审查,同时使用身份验证确保审查完整性。该网站还可以直接用作发布审查结果和实验统计数据的工具。 MUBENCHPIPE为滥用示例定义了简单的数据模式,以简化MUBENCH的扩展。 它还提供了一个方便的Java接口作为Maven依赖项,以允许插入其他检测器以进行基准评估。有关如何使用或扩展MUBENCHPIPE的更多详细信息,请参见我们的项目网站[24]。
7.RESULTS
现在我们讨论在实验中比较JADET,GROU-MINER,TIKANGA和DMMC的结果。 所有审阅数据都可以在我们的页面[10]上找到。
7.1 Experiment P
表7显示了我们的精密度结果,其依据是我们对五个样本项目中每个检测器的前20个发现进行了回顾。 第二列显示了检查结果的总数,所有检测器中共有230个结果。 请注意,对于某些项目,所有检测器报告的结果少于20个。 第三列显示在解决分歧后已确认的滥用情况,第四列显示相对于已审查发现的准确性。 第五列显示了人工审核的Kappa评分,其余列显示了误报的根本原因的频率,我们发现所有检测器的精度都非常低,TIKANGA的最佳精度仅为11.4%。 JADET和DMMC紧随其后,精确度分别为10.3%和9.9%。 GROUMINER仅报告前20个发现中的假阳性。
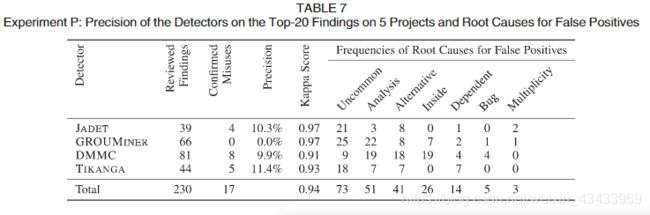

Kappa得分表明审稿人的认可度很高,这表明所有检测器产生的假阳性大多是明确的。 TIKANGA的得分略低,因为它报告了一次确认的滥用两次,其中一位观众首先认为是实际点击,而另一位观众则没有。 DMMC的分数也较低,因为我们最初不同意它标识的inIteratorusages中的一些违规行为,这些行为不检查hasNext(),而是底层集合的大小。
7.1.1 True Positives
在我们审查的230个报告发现中,我们确认了17个真正的误用。 DMMC报告未选中hasNext()的迭代器API的8次误用。 JADET报告了4个在访问集合之前没有检查其大小的误用。同样,对于集合,TIKANGA报告了4个缺失hasNext()误用,以及1个误用的缺失大小检查。 TIKANGA和JADET都报告了一种情况,TIKANGA和DMMC都报告了另一种情况。 此外,JADET报告同一个误用两次。 这就留下了14个独特的误用,所有这些都不同于MUBENCH中已知的误用。 有趣的是,所有这些误用都是缺失值或状态条件,对于这些条件,检测器只报告对应该在各自的缺失检查中使用的方法的缺失调用。 在我们宽松的审查过程中,我们接受这些调查结果。

7.1.2 False Positives
为了确定提高滥用检测器准确性的机会,我们系统地调查了他们报告的误报的根本原因。 在下文中,我们将讨论按其绝对频率顺序在所有检测器中汇总的这些根本原因。
1.不常见但正确的用法。特殊用法可能会违反检测器从频繁使用中学习的模式,而不会违反实际的API使用限制。 检测器无法区分不经常使用和无效使用。 例如,DMMC和JADE获悉MapEntry的方法getKey()和getValue()通常在代码中一起出现。如果缺少对这两个方法的调用,或者如果调用JADET,则它们以不同顺序出现,它们都报告违规。 但是,API不需要始终调用两个getter方法,更不用说按特定顺序调用了。 在我们分析的所有报告违规情况中,如果getter方法中的丢失或以不同顺序调用,则检测器会错误地报告42个缺少的方法调用。 另一个例子是JADET和TIKANGA了解通常在循环中调用诸如List.add()和Map.put()之类的方法,并报告循环外针对预期调用的五个缺失的迭代,这完全符合API。 诸如多层模式[49]或ALATTIN的替代模式[18]之类的方法可能有助于缓解此问题。 还要注意,我们实验中的四个检测器都使用绝对频率阈值,而我们在第4节中调查的某些检测器也使用了相对阈值。 未来的工作应该研究这两种选择之间的比较。

2.不精确分析。检测器使用静态分析来确定属于特定用法的事实。 这些分析的不精确性会导致误报。 例如,检测器错误地报告了代码中五个缺失的元素,这些元素对同一对象使用了多个别名,而在代码中又有17个带有嵌套控制语句。 在这两种情况下,分析都无法捕获属于相同用法的所有呼叫。 GROUMINER报告了两个丢失的方法调用,因为它无法解析链式方法调用的接收器类型,例如 for m()in o.getX().m(),通常仅靠源代码是不可能的。 因此,GROUMINER无法匹配模式和用法之间的调用。 另一个例子是,由于对流畅的API(例如StringBuilder)的链接调用,检测器报告了八次方法丢失的调用,在这种分析中,检测器无法确定所有调用实际上发生在同一对象上。JADET,GROUMINER和DMMC一起报告了9个丢失的调用,这些调用在相同类的辅助方法中或通过包装对象(例如aBuffer-edStream)传递地发生。 DMMC报告一个丢失的调用,该调用位于匿名类实例的封闭方法中,并且对由调用者按合同关闭的参数进行amissingclose()调用。 此外,GROUMINER报告由断言辅助方法检查的四个缺失条件。 PR-MINER [11]提出的一种过程间检测策略可以减轻这个问题。

3.替代模式。检测器通常会学习一个模式,然后将替代用法的实例报告为违规。我们将替代用法定义为使用API的不同功能正确方式,以实现相同或不同的功能。 注意,多种选择可能足够频繁地发生以引起图案。 例如,JADET,TIKANGA和DMMC了解到,在calltonext()之前,应该始终有一个对onanIterator的hasNext()调用。 因此,他们报告了16种违规用法,它们在通过Iterator仅获取第一个元素之前,先检查基础集合的isEmpty()或size()。 DMMC报告了另一个违规,因为在访问列表之前使用了Empty()而不是size()。 另一个示例是JADET,TIKANGA和DMMC通过调用add()一次得知集合被填充一个元素,并报告了10种缺少的用法(例如通过构造函数或usingaddAll()使用)来填充集合的用法不同的情况。 GROUMINER报告使用替代控制语句的四种用法,例如,用for代替while。
这种根本原因的一种特殊情况是获取类型实例的替代方法。 例如,GROUMINER错误地报告了两个丢失的构造函数调用,其中实例不是通过模式中的构造函数调用创建的,而是从方法调用返回的。 JADET和DMMC每个报告对象缺少构造函数调用,在这种情况下,实例不是创建的,而是作为参数传递的。 虽然处理替代模式是一个未解决的问题,但某些工具(如ALATTIN)已经提出了可能的解决方案[18]。

4.跨方法用法。存储在字段中的对象经常在该字段的声明类的多种方法中使用。 然后,各个方法内的各个API使用可能会偏离使用模式,而不会造成实际的滥用。 图1显示了这种情况的示例,其中使用Iterator类型的两个字段in和out来实现NeighborIterator类。 当不产生更多元素时(第12行),第14行中对next()的调用将在不事先检查是否有更多元素的情况下发生。尽管这似乎是对封装方法内部的Iterator API的滥用,但这是对封装类内部的正确用法,因为NeighborIterator本身实现了Iterator,并因此继承了其使用约束。 正确调用NeighborIterator的用法需要在调用其next()方法(第11行)之前检查其hassNext()方法(第6行),以确保在调用next()时没有更多的元素。 DMMC和GROUMINER报告了此类字段的此类用法的十六次违规。

这种根本原因的一种特殊情况是,当类在其实现中使用其自己的API的一部分时。 例如,当aCollection在其addAll()方法的实现中调用其自己的add()方法时。 DMMC和GROUMINER报告了四个此类违规行为。 这特别有趣,因为这些实际上是API的自用,而检测器则以客户端使用为目标。 由于任何代码库都可能包含此类自用,因此检测人员应考虑这一点。

5.从属对象状态。当两个对象的状态相互依赖时,用法有时会检查一个对象的状态,并隐式得出关于另一个对象状态的结论。 检测器不考虑这种相互依赖性。 例如,当两个集合并行维护时,即始终具有相同的大小,在访问其中一个之前检查其中一个的大小就足够了。 在这种用法中,检测器错误地报告了14个丢失的尺寸检查。 在其中的10种情况下,以相同的方法构造集合可确保大小相等。 在其余四个案例中,在同一类别的其他位置进行保险。 我们认为这是一种危险的做法,因为如果集合之间的依赖关系发生变化,则很容易错过一些依赖它的代码。 因此,警告开发人员可能是有道理的。 但是,由于当前用法是正确的,因此我们将这些情况视为误报。

6.调用多重性。检测器无法处理可能经常被任意调用的方法。 GROUMINER和JADE都学习了一种模式,其中StringBuilderis的append()方法被调用了两次,并错误地报告了三个缺失的方法调用,而该方法仅被调用了一次。

7.错误。一些发现可能是由检测器实现中的错误引起的。 DMMC报告了四次违规,缺少一组空缺的方法。 当所有可能丢失的方法都不符合DMMC的流行标准时,将产生这些空集。 DMMC应该在报告之前过滤掉这些空置的发现。 GROUMINER报告了实际上在所有各个用法中出现的一个缺失,因为它的图形映射与一种用法中的相应ifnode与所有其他用法中的对应节点不匹配。
7.2 Experiment RUB
我们运行所有检测器,以查看MUBENCH的64种已知滥用中的哪些能在给定各自正确的模式挖掘用法时检测到。 表8显示了每个检测器的结果。 解决分歧后,第二列和第三列显示潜在的点击数和实际的点击数。 第四列和第五列分别显示了检测器的经验召回上限和概念召回上限。 第六列显示手动审核的Kappa分数。 其余各栏显示了导致表3中探测器的概念能力与其在本实验中的实际发现之间出现分歧的根本原因的频率。
我们发现GROUMINER迄今为止具有最佳召回率上限,并且在实验RUB中也表现出最佳召回率,这表明GROUMINER的图形表示是捕捉正确用法和模式之间差异的不错选择。 但是,GROUMINER在概念上的召回上限与经验上的召回上限之间的差距相当明显。 实际上,表8显示了所有四个检测器在实践中均远未达到其概念召回上限。
通常,我们观察到实际发现和概念能力之间的两种差异:意外的假阴性,即滥用检测器应该能够检测到的错误,以及意外的点击,即滥用检测器应该无法检测到的错误,但是 点击了。 我们调查了每种差异的根本原因,以找出可改进检测器的可行方法。

Kappa评分表明审稿人的同意程度很高,尽管比实验P中的要低。由于我们只审阅了潜在的点击率,即与已知的误用方法相同的发现,因此许多潜在的点击率与已知的误用有关。 因此,对于特定的潜在打击实际上是否能识别出特定的误用,我们存在一些分歧。 我们总共有18个这样的分歧(JADET:4; GROUMINER:6; DMMC:5; TIKANGA:3),这导致我们对第5.2节中所述的宽大审查流程进行了模拟。 其中有八种。我们观察到,JADET的Kappa得分比其他探测器低。 由于分歧的绝对数量是可比较的,并且JADETh的潜在匹配数相对较少,即,少量决策作为Kappa分数的基础,因此我们将较低的分数归因于机会。
7.2.1 Unexpected False Negatives(判断为正常其实是误用)
1.不精确的表示形式。当前的使用形式表示形式不足以捕捉到所有区分误用和正确用法所必需的细节。 例如,DMMC和GROUMINER仅按名称编码方法,因此,当用法调用相应方法的重载版本时,它们无法检测到丢失的方法调用。 例如,假设模式需要调用getBytes(String),但目标用法则调用getBytes()。 理想的滥用检测器仍会报告违规,因为未调用具有正确参数的预期方法。 但是,由于在这两个检测器中仅将方法名称用于比较,因此不会检测到这种冲突。 另一个示例是,要使用Cipher实例进行解密,它必须处于解密模式。 通过将Cipher.DECRYPT传递给Cipher的init()方法,可以确保此状态条件。 检测器中没有一个捕获这种确保条件成立的方式,因为它们未在其表示中对方法调用参数进行编码。

2.不精确的模式匹配。检测器无法关联模式和用法。 通常,检测器通过其常见事实将模式和使用情况联系起来。 如果没有或只有很少的常见事实,检测器不会报告违规。 例如,JADET的事实是一对方法调用。在偶然地在Jpack的pack()方法之后调用JFrame的setPreferredSize()方法的情况下,JADET用对
3.不精确的分析。检测器依靠静态分析来提取其使用表示。 这些分析中的不精确性可能会混淆模式和用法之间的关系,例如GROUMINER无法检测到一个丢失的空校验,因为它无法确定链式调用的接收方类型,例如form()in o .getX().m(),而这通常是不可能的 仅源代码。 而且,由于它忽略了数据流依赖性,因此它无法检测到另外四个缺失的空检查。 图3示出了这种情况。

除了null检查外,GROUMINER还错过了缺失中从get()调用到remove()调用的数据流,这使模式和用法因多个事实而有所不同。 但是,GROUMINER仅在差异是单个事实的情况下才报告违规。 TIKANG拒绝在一种情况下以正确用法进行的呼叫,而在另一种情况下无法从正确用法中捕获两个呼叫之间的呼叫顺序。 我们假设原因是其分析的局限性,但最终无法验证这一点,因为该工具的开发人员无法确认实施细节。

4. Bug.DMMC如果模式包含的调用少于用法,则跳过用法和模式的比较,以提高性能。 例如,来自Apache HTTPCLIENT的AuthState模式需要三个调用,其中误用场景会丢失一个调用。但是,如果这种滥用有一个不在模式中的附加可选调用,则DMMC会跳过此模式和目标之间的比较 包含3个调用。 这在我们的实验中导致了两个意外的假阴性。
7.2.2 Unexpected Hits
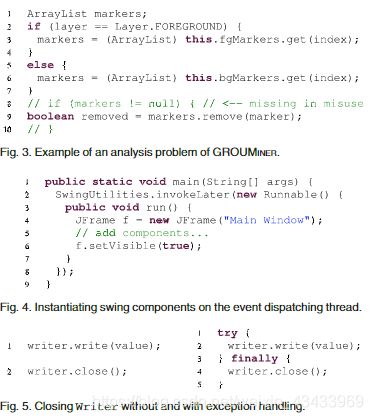
1.宽松的审查程序:除了两个案例外,所有意外命中的原因都是我们对实验使用的宽松的审查程序(参见第5.2节)。 在大多数情况下,检测器报告指示缺少条件检查的缺少调用。 唯一的另一种情况是,在需要在事件分派线程上运行某些SWING代码的情况下,GROUMINER检测到丢失的上下文条件。通过将代码包装到Runnable的匿名实例中来实现对EDT的委托,如图4所示。GROUMINER认为run()中的代码是封闭方法代码的一部分。 因此,它通过在JFrame实例化之前报告Runnable的丢失实例来建议滥用。


2.捕获异常处理。在其余两种情况下,JADET和TIKANGA正确地报告缺少的异常处理。 例如,图5(左)显示了一个滥用,其中write()引发异常时未调用close()。右侧显示了相应的正确用法。TIKANGA和JADET都表示正确的用法有两个事实:{(write,close);(write:EXC; close)},在正常执行和发生异常的情况下,对close()进行有效编码后调用afterwrite()。 在滥用中,他们找到了第二个事实。 在相应的出版物中没有提到这种实现的能力。
7.3 Experiment R
在实验R中,我们运行所有检测器以评估其召回率,而没有明确为它们提供正确的用法。 除了MUBENCH的64种误用之外,我们还从实验P中添加了14种新的误用,并排除了25种手工制作的示例,这些示例没有可从中挖掘模式的项目代码。 这给实验R留下了53次误用(表1第5行)。
表9显示了结果,图6显示了召回情况。JADET仅发现了在实验P中已经发现的三种滥用情况。GROUMINER找不到任何滥用情况。 TIKANGA发现了在实验P中已经发现的五种滥用,一种是在实验P中DMMC识别出的滥用,另一种是在实验P中JADETidenti-fied的滥用。 实验P,并且滥用了实验P中报告的JADET和TIKANG。
DMMC在实验R中显示出最好的召回率。这表明,在关注缺少的方法调用时,其相对简单的检测策略效果很好。 但是,在实验R提供的实际设置中,所有检测器的呼出率都很低。 通过分析其不良性能的根本原因,我们确定了探测器设计和评估设置的两个普遍问题。
1.排名不佳。实验R显示,检测器识别出的其他滥用行为超出了我们在实验P中考虑的前20个发现。不幸的是,他们将滥用行为的排名非常低。 例如,DMMC的两个MUBENCHmisuses排名分别为309和613。这远远超出了我们可以合理预期用户进行评估的发现数量。 我们实验中的四个检测器都使用不同的排名策略,但是我们在第4节的调查中没有一个检测器在同一检测器上比较不同的策略。

2.缺乏使用示例。实验RUB和实验R在检测器性能上的巨大差异表明,原因是目标项目中缺少正确的使用示例。 一种可能是此类示例的数量小于检测器对模式挖掘的最小支持,在这种情况下,我们可以简单地降低这些阈值。 但是,由于开采模式通常变得不那么可靠,这也可能会增加误报的数量,这强调了有效过滤误报(O1)和改善排名(O14)的需要。 另一种可能性是项目中不存在或仅存在很少的此类示例。 对于滥用检测器的评估设置,这将是一个普遍的问题。 为了解决这个问题,我们需要使用示例的其他来源来消除其模式。 Gruska等。 [37]通过在一个有6,000个项目的多项目环境中应用JADET展示了一种可能的方法,但是没有衡量召回率。 其他软件工程推荐系统,例如代码完成引擎[50],是跨项目工作的,也就是说,他们从大量项目中学习,以为其他项目提供建议。 滥用检测器CAR-MINER [17]和ALATTIN [18]通过代码搜索引擎专门搜索目标项目中使用的API的使用示例,从而实现了一种替代方法。 与此相关的是,其他研究领域建议代码搜索引擎在开源项目[51],[52]或StackOverflow [53]中查找使用示例。

Kappa评分表明实验R中的评论者意见基本完美。这是因为检测器几乎完全发现了其中一个在实验P中也已发现的滥用行为,即我们之前已经同意的滥用行为。DMMC是个例外,我们最初不同意它在14种潜在命中问题之一中对原始MUBENCH数据集的误用。
7.4 User Experience
现在,我们报告使用主题滥用检测器的用户的经验。 我们的观察结果基于我们在检查实验中检测器的发现时获得的经验。
DMMC仅报告当前和缺少的方法调用,以及第一个当前调用的源行号。我们发现此输出通常易于理解。 行号特别有助于在大型方法中定位使用情况。GROUMINER报告模式和使用情况图,这更难理解。 但是,我们发现图形表示形式捕获的源代码的结构特性有助于解释。 JADETandTIKANG报告其各自表示形式的当前和缺少的事实。 我们发现通常很难将事实相互关联,尤其是在存在多个相同API的情况下。 这可能部分是由于我们查看的文本表示。 尽管没有一种检测器实现旨在将其发现提供给最终用户,但仍然值得关注的是,解释发现的挑战似乎与源代码和用法表示之间的距离相关.
我们还发现基于字节码的检测器可能会报告编译器引入的代码中的发现。 例如,编译器将foreach循环转换为Iteratorusages。 TIKANGA在这种用法中报告丢失的呼叫,即,它在Iterator不出现在源代码中的方法中报告onIterator的丢失的呼叫。 这个发现起初使我们感到困惑。 尽管可以采取其他步骤来帮助用户将这些发现映射回源代码,但是基于源的检测器不会遇到此问题。
我们宽松的审查过程显示,丢失的方法调用通常表示缺少的条件(O2和O13)。虽然这样的发现不能报告整个问题,但我们发现推断它们的含义相对容易。 相反,当GROUMINER覆盖缺失的条件时,它只报告一个丢失的节点。 虽然这些发现更明确地指出了支票遗漏的问题,但我们觉得实际上很难采取行动,因为它们没有给出应该检查什么的信息。 这表明检测器识别违规行为的能力与向用户解释该违规行为的能力之间存在差距。
最重要的是,我们认为探测器的精度可能是其在实践中的适用性的最大威胁。 作为约翰逊等人以前的研究。 [41]表明,大量误报是采用代码分析工具的主要障碍。 检测器的召回率低使此问题变得更糟。 即使开发人员花时间审查所有报告的警告,他们仍可能会遗漏绝大多数误用。
7.5 Call to Action
我们发现,如果提供了正确的用法以与(实验RUB)进行比较,则误用检测器实际上能够检测出MUBENCH中相当一部分的误用。
但是,即使检测器也能够在现实环境中发现一些误用(实验P和实验R),它们的精度(O1)和召回率(O15)却极低。 我们确定了假阴性的四个根本原因,假阳性的七个根本原因以及检测器设计及其通常评估方式的两个一般性问题。 这使我们对如何提高API滥用检测的最新水平提出了几点看法。 因此,我们呼吁研究人员采取行动:
- 首先,我们需要对API用法进行精确定义,并考虑用法属性,例如用法位置(O6)和调用多重性(O8)。
- 我们需要这样一种用法的表示形式,以捕获所有区分正确用法和误用所必需的代码细节( O10)和更精确的分析以识别代码中的用法(O4和O12)。
- 我们需要使用项目外部资源(例如大型项目集或代码搜索引擎(O15))来检索足够多的用法示例的检测器。
- 我们需要的检测器必须超出天真的假设,即偏离最频繁使用对应于滥用(O3),但要考虑程序语义,例如类型层次结构(O11)和对象之间的隐式依赖关系(O7)。 我们假设概率模型可能是解决此问题的一种方法。
- 我们需要在存在违规情况下(O9和O11)正确匹配模式和用法的策略,
- 我们需要在同一API(O5)上正确处理替代模式的策略。
- 我们需要良好的排名策略,以减少评审结果的成本(O14)。
为了实现所有这些,我们需要可重复和可复制的研究,以使系统评估和分析替代方法和策略成为可能。 我们发布了MUBENCHand MUBENCHPIPE [24],作为此类工作的基础,并呼吁研究人员使用该基础结构并对此做出贡献,以提高API滥用检测的最新水平。
8.THREATS TO VALIDITY
构建有效性。任何检测器的性能都取决于其配置。 由于审核发现的工作量很大,因此我们无法为每个检测器尝试不同的配置。 但是,为了给每个检测器一个公平的机会,我们使用了各自出版物中报告的最佳配置。
我们的研究集中于静态误用检测器。 基于动态分析的方法可能会表现不同,并且具有独特的优点和缺点。 为了对MUBENCH中的项目版本进行动态分析,我们必须确保相应的代码是可执行的(除了编译时依赖关系之外,还需要足够的运行时环境),并提供执行示例输入。 目前尚不清楚如何做到这一点,从而可以对静态技术和动态技术进行公平的比较,而不必诉诸于将苹果与橙子进行比较。 在这项工作中,我们仅关注静态方法。
我们的实验重点是检测Java代码中的滥用情况的检测器。 因此,结果可能无法推广到其他语言的检测器。 我们决定专注于检测器的这一子集,因为我们在调查中确定的大多数方法都针对Java。为了包括针对其他语言的检测器,我们将不得不将它们迁移到Java或为相应的语言建立其他数据集,这两者都不在本文的范围之内。
内部有效性。审查检测器的发现是由三位作者完成的,并且不是盲目的(即,不知道我们正在审查发现器的检测器)。 我们无法进行盲目审查,因为每种方法都具有无法匿名使用和使用的违规表示。 此外,该工作的两名作者是GROUMINER的原始作者。 我们尽力客观地进行了审查。 为避免产生偏见,至少有两名审阅者独立查看每个发现。 在GROUMINER的调查结果中,至少有一位审稿人没有参与原始工作。
虽然我们确实要求原始作者确认我们对其工具的概念能力的评估,但并未要求他们确认我们实验的经验结果。 我们估计,包括解决分歧的讨论在内,每位审稿人平均需要2分钟的时间来验证检测器是否识别出了实验RUB和R中的已知滥用之一,并需要5分钟来验证检测器的发现是否标识出了实验P中的实际滥用,其中 我们需要了解相应的代码,检查文档,有时还需要研究可传递方法。 每个审稿人的审阅时间为24.8小时,JADET为4小时,GROUMINER为7.2小时,TIKANGA为4.7小时,DMMC为8.9小时。 我们认为期望原作者花这么多时间来验证我们的评估是不合理的。 但是,我们确实发布了所有审查数据[10],以使他们和其他人可以重新审视我们的决定。
外部有效性。MUC中可能存在一些遗漏的违规类别。 MUBENCH数据集可能还没有足够的所有违规示例。 这可能会影响检测器的比较。 但是,现有的MUBENCH数据集基于来自最新状态数据集的1200多个报告以及开发人员的输入[3]和有关API使用指令的两次实证研究的结果。 我们对现有探测器功能的调查还包括12个探测器。 这使得我们不太可能错过普遍流行的类别。
我们的数据集可能无法代表现实世界中所有可能的API滥用,特别是因为我们只能编译55个项目版本中的29个(52%),并且不得不从我们的实验中排除其他版本中的滥用。 从项目的源代码管理历史中编译项目的任意版本是一项艰巨的任务。 我们投资了一位作者的两个星期的工作,以及一个学生另外三个月的工作,以尽可能地包含许多项目版本。 仍然,失去我们无法编译相应项目版本的示例可能会使我们的实验结果产生偏差。
理想情况下,我们的实验应包括来自大量项目的成千上万个误用项,并且在每个单独的项目版本中都可以使用,以使我们对结果的可推广性更有信心。 但是,目前尚无此类数据集。 我们花了几个月的时间来收集和准备MUBENCH的当前状态,以迈向大型基准测试的第一步。 现在我们已经有了基础架构,可以使用来自不同来源的滥用示例来扩展MUBENCH。
我们发布了MUBENCHPIPE和MUBENCH [24],并鼓励其他人扩展数据集并重复我们的实验,同时使用其他探测器和探测器配置。
9. CONCLUSIONS
API滥用检测器通过警告开发人员代码中可能存在的滥用行为,帮助开发人员编写更好的软件。尽管存在许多此类检测器,但仍未尝试系统地研究API滥用的类型并相应地设计检测器。 在本文中,我们通过基于100个误用的数据集创建MUC来解决此差距。 通过评估12个现有探测器相对于MUC的概念能力,我们从质量上确定了缺点。 Wethen开发了一个自动基准测试管道MUBENCH-PIPE,以根据经验评估四个现有检测器。 我们的结果表明,误用检测器在明确提供正确的用法以从中进行挖掘时,实际上能够检测出误用。 但是,它们的精度极低,并且在实际的应用程序设置中会被召回。 我们确定了误报的四个根本原因,误报的七个根本原因以及检测器的设计和常用的评估设置两个普遍的问题。 这些使我们对如何在将来的工作中提高API滥用检测的最新水平提出了几点看法。 我们发布了所有工具和数据集[24],以鼓励其他研究人员沿着这条道路加入我们。