AI模型工业部署:综述【常用的部署框架:TensorRT、Libtorch】【常见提速方法:模型结构、剪枝、蒸馏、量化训练、稀疏化】【常见部署流程:onnx2trt】【常见服务部署搭配】
作为深度学习算法工程师,训练模型和部署模型是最基本的要求,每天都在重复着这个工作,但偶尔静下心来想一想,还是有很多事情需要做的:
- 模型的结构,因为上线业务需要,更趋向于稳定有经验的,而不是探索一些新的结构
- 模型的加速仍然不够,还没有压榨完GPU的全部潜力
一、AI部署
AI部署的基本步骤:
- 训练一个模型,也可以是拿一个别人训练好的模型
- 针对不同平台对生成的模型进行转换,也就是俗称的parse、convert,即前端解释器
- 针对转化后的模型进行优化,这一步很重要,涉及到很多优化的步骤
- 在特定的平台(嵌入端或者服务端)成功运行已经转化好的模型
- 在模型可以运行的基础上,保证模型的速度、精度和稳定性
就这样,虽然看起来没什么,但需要的知识和经验还是很多的。
对于硬件公司来说,需要将深度学习算法部署到性能低到离谱的开发板上,因为成本能省就省。
在算法层面优化模型是一方面,但更重要的是从底层优化这个模型,这就涉及到部署落地方面的各个知识(手写汇编算子加速、算子融合等等);
对于软件公司来说,我们往往需要将算法运行到服务器上,当然服务器可以是布满2080TI的高性能CPU机器,但是如果QPS请求足够高的话,需要的服务器数量也是相当之大的。
这个要紧关头,如果我们的模型运行的足够快,可以省机器又可以腾一些buffer上新模型岂不很爽,这个时候也就需要优化模型了,其实优化手段也都差不多,只不过平台从arm等嵌入式端变为gpu等桌面端了。
作为AI算法部署工程师,你要做的就是将训练好的模型部署到线上,根据任务需求,速度提升2-10倍不等,还需要保证模型的稳定性。
算法部署落地这个方向是比较踏实务实的方向,相比设计模型提出新算法,对于咱们这种并不天赋异禀来说,只要肯付出,收获是肯定有的(不像设计模型,那些巧妙的结果设计不出来就是设计不出来你气不气)。
其实算法部署也算是开发了,不仅需要和训练好的模型打交道,有时候也会干一些粗活累活(也就是dirty work),自己用C++、cuda写算子(预处理、op、后处理等等)去实现一些独特的算子。也需要经常调bug、联合编译、动态静态库混搭等等。
算法部署最常用的语言是啥,当然是C++了。如果想搞深度学习AI部署这块,C++是逃离不了的。
所以,学好C++很重要,起码能看懂各种关于部署精巧设计的框架(再列一遍:Caffe、libtorch、ncnn、mnn、tvm、OpenVino、TensorRT,不完全统计,我就列过我用过的)。当然并行计算编程语言也可以学一个,针对不同的平台而不同,可以先学学CUDA,资料更多一些,熟悉熟悉并行计算的原理,对以后学习其他并行语言都有帮助。
系统的知识嘛,还在整理[1],还是建议实际中用到啥再看啥,或者有项目在push你,这样学习的更快一些。
可以选择上手的项目:
- 好用的开源推理框架:Caffe、NCNN、MNN、TVM、OpenVino
- 好用的半开源推理框架:TensorRT
- 好用的开源服务器框架:triton-inference-server
- 基础知识:计算机原理、编译原理等
二、常用的部署框架
这里介绍一些部署常用到的框架,毕竟对于某些任务来说,自己造轮子不如用别人造好的轮子。
并且大部分大厂的轮子都有很多我们可以学习的地方,因为开源我们也可以和其他开发者一同讨论相关问题;同样,虽然开源,但用于生产环境也几乎没有问题,我们也可以根据自身需求进行魔改。
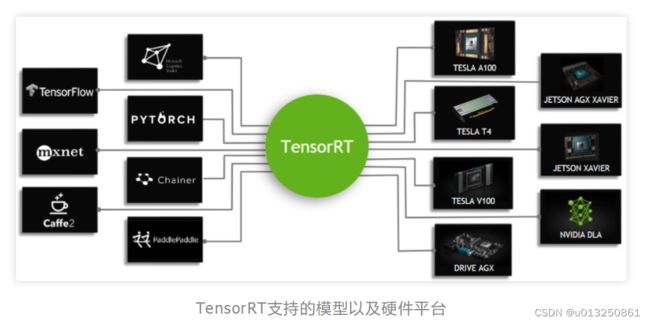
1、TensorRT
TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个C++推理框架。我们利用Pytorch、TF或者其他框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行我们这个模型,从而提升这个模型在英伟达GPU上运行的速度。速度提升的比例是比较可观的。
在GPU服务器上部署的话,TensorRT是首选!
2、Libtorch (torchscript)
libtorch是Pytorch的C++版,有着前端API和与Pytorch一样的自动求导功能,可以用于训练或者推理。
Pytorch训练出来的模型经过torch.jit.trace或者torch.jit.scrpit可以导出为.pt格式,随后可以通过libtorch中的API加载然后运行,因为libtorch是纯C++实现的,因此libtorch可以集成在各种生产环境中,也就实现了部署(不过libtorch有一个不能忽视但影响不是很大的缺点[4],限于篇幅暂时不详说)。
libtorch是从1.0版本开始正式支持的,如今是1.9版本。从1.0版本我就开始用了,1.9版本也在用,总的来说,绝大部分API和之前变化基本不大,ABI稳定性保持的不错!
libtorch适合Pytorch模型快速C++部署的场景,libtorch相比于pytorch的python端其实快不了多少(大部分时候会提速,小部分情况会减速)。在老潘的使用场景中,一般都是结合TensorRT来部署,TensorRT负责简单卷积层等操作部分,libtorch复杂后处理等细小复杂op部分。
基本的入门教程:
-
利用Pytorch的C++前端(libtorch)读取预训练权重并进行预测
-
Pytorch的C++端(libtorch)在Windows中的使用
官方资料以及API:
-
USING THE PYTORCH C++ FRONTEND[5]
-
PYTORCH C++ API[6]
libtorch的官方资料比较匮乏,建议多搜搜github或者Pytorch官方issue,要善于寻找。
一些libtorch使用规范:
- Load tensor from file in C++ [7]
3、Caffe
Caffe有多经典就不必说了,闲着无聊的时候看看Caffe源码也是受益匪浅。我感觉Caffe是前些年工业界使用最多的框架(还有一个与其媲美的就是darknet,C实现)没有之一,纯C++实现非常方便部署于各种环境。
适合入门,整体构架并不是很复杂。当然光看代码是不行的,直接拿项目来练手、跑起来是最好的。
第一次使用可以先配配环境,要亲手来体验体验。
至于项目,建议拿SSD来练手!官方的SSD就是拿Caffe实现的,改写了一些Caffe的层和组件,我们可以尝试用SSD训练自己的数据集,然后部署推理一下,这样才有意思!
4、OpenVINO
在英特尔CPU端(也就是我们常用的x86处理器)部署首选它!开源且速度很快,文档也很丰富,更新很频繁,代码风格也不错,很值得学习。
在我这边CPU端场景不是很多,毕竟相比于服务器来说,CPU场景下,很多用户的硬件型号各异,不是很好兼容。另外神经网络CPU端使用场景在我这边不是很多,所以搞得不是很多。
5、NCNN/MNN/TNN/TVM
有移动端部署需求的,即模型需要运行在手机或者嵌入式设备上的需求可以考虑这些框架。这里只列举了一部分,还有很多其他优秀的框架没有列出来…是不是不好选?
- NCNN[8]
- MNN[9]
- TNN[10]
- TVM[11]
- Tengine[12]
个人认为性价比比较高的是NCNN[13],易用性比较高,很容易上手,用了会让你感觉没有那么卷。而且相对于其他框架来说,NCNN的设计比较直观明了,与Caffe和OpenCV有很多相似之处,使用起来也很简单。可以比较快速地编译链接和集成到我们的项目中。
三、AI部署中的提速方法
上到模型层面,下到底层硬件层面,其实能做的有很多。如果我们将各种方法都用一遍(大力出奇迹),最终模型提升10倍多真的不是梦!有哪些能做的呢?
- 模型结构
- 剪枝
- 蒸馏
- 稀疏化训练
- 量化训练
- 算子融合、计算图优化、底层优化
1、模型结构
模型结构当然就是探索更快更强的网络结构,就比如ResNet相比比VGG,在精度提升的同时也提升了模型的推理速度。又比如CenterNet相比YOLOv3,把anchor去掉的同时也提升了精度和速度。
模型层面的探索需要有大量的实验支撑,以及,脑子,我脑子不够,就不参与啦。喜欢白嫖,能白嫖最新的结构最好啦,不过不是所有最新结构都能用上,还是那句话,部署友好最好。
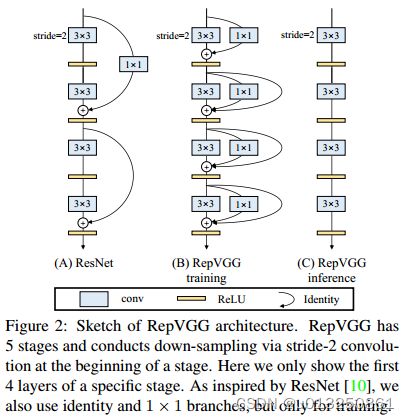
哦,还有提一点,最近发现另一种改变模型结构的思路,结构重参化。还是蛮有搞头的,这个方向与落地部署关系密切,最终的目的都是提升模型速度的同时不降低模型的精度。
之前有个比较火的RepVgg[15]——Making VGG-style ConvNets Great Again就是用了这个想法,是工业届一个非常solid的工作。部分思想与很多深度学习推理框架的算子融合有异曲同工之处。
2、剪枝
剪枝很早就想尝试了,奈何一直没有时间啊啊啊。
我理解的剪枝,就是在大模型的基础上,对模型通道或者模型结构进行有目的地修剪,剪掉对模型推理贡献不是很重要的地方。经过剪枝,大模型可以剪成小模型的样子,但是精度几乎不变或者下降很少,最起码要高于小模型直接训练的精度。
积攒了一些比较优秀的开源剪枝代码,还咩有时间细看:
yolov3-channel-and-layer-pruning[16]
YOLOv3-model-pruning[17]
centernet_prune[18]
ResRep[19]
3、蒸馏
我理解的蒸馏就是大网络教小网络,之后小网络会有接近大网络的精度,同时也有小网络的速度。
再具体点,两个网络分别可以称之为老师网络和学生网络,老师网络通常比较大(ResNet50),学生网络通常比较小(ResNet18)。训练好的老师网络利用soft label去教学生网络,可使小网络达到接近大网络的精度。
印象中蒸馏的作用不仅于此,还可以做一些更实用的东西,之前比较火的centerX[20],将蒸馏用出了花,感兴趣的可以试试。
4、稀疏化
稀疏化就是随机将Tensor的部分元素置为0,类似于我们常见的dropout,附带正则化作用的同时也减少了模型的容量,从而加快了模型的推理速度。
稀疏化操作其实很简单,Pytorch官方已经有支持,我们只需要写几行代码就可以:
5、量化训练(模型训练中量化)
这里指的量化训练是在INT8精度的基础上对模型进行量化。简称QTA(Quantization Aware Training)。
量化后的模型在特定CPU或者GPU上相比FP32、FP16有更高的速度和吞吐,也是部署提速方法之一。
PS:FP16量化一般都是直接转换模型权重从FP32->FP16,不需要校准或者finetune。
量化训练是在模型训练中量化的,与PTQ(训练后量化)不同,这种量化方式对模型的精度影响不大,量化后的模型速度基本与量化前的相同(另一种量化方式PTQ,TensorRT或者NCNN中使用交叉熵进行校准量化的方式,在一些结构中会对模型的精度造成比较大的影响)。
四、常见部署流程
假设我们的模型是使用Pytorch训练的,部署的平台是英伟达的GPU服务器。
训练好的模型通过以下几种方式转换:
- Pytorch->ONNX->trt onnx2trt
- Pytorch->trt torch2trt
- Pytorch->torchscipt->trt trtorch
五、常见的服务部署搭配
triton server + TensorRT/libtorch
flask + Pytorch
Tensorflow Server
参考资料:
一文详解AI模型部署及工业落地方式