机器学习算法-支持向量机SVM案例Rain in Australia预测明天是否下雨
案例分析流程
- 一、获取数据
- 二、解读数据
- 三、数据探索
-
- 1.导入相关包
- 2.导入数据和查看数据
- 3.随机抽样
- 4.探索变量
- 5.将样本特征和标签分开
- 6.切分训练集和测试集
- 四、数据清洗
-
- 1.将特征进行分类整理
-
- 建立分类型变量列表
- 建立连续型变量列表
- 2.去重
- 3.异常值处理
- 4.缺失值处理
- 5.对变量进行编码
- 6.处理量纲不统一
- 五、模型创建和评估
一、获取数据
本案例中所用的数据集为Kaggle提供的澳大利亚气象局十年的气象数据,共142193条数据。本文采用SVM、随机森林进行预测,仅供学习交流。
二、解读数据
数据大小:12.9M,142193条数据;
数据格式:csv
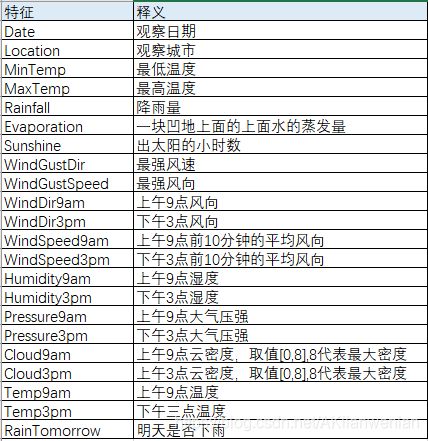
数据特征:总共有23个特征,下图为各特征的中文释义。其中RainTomorrow为目标变量Y,Cloud9am和Cloud3pm是有9个取值范围的,这样的特征有程度的数据,建议用分类型变量进行分析,不建议以连续型变量进行哑变量转换。
三、数据探索
1.导入相关包
# 导入基本包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt #画图包
%matplotlib inline
import seaborn as sns #画图包
plt.style.use('seaborn')
import warnings
warnings.filterwarnings('ignore') #警告过滤器,跳过警告
2.导入数据和查看数据
# 导入数据
weather = pd.read_csv('weather.csv',index_col=0) #读取csv文件'weather.csv'
pd.set_option('max_columns',100) #显示所有行
weather.head() #查看数据前5行
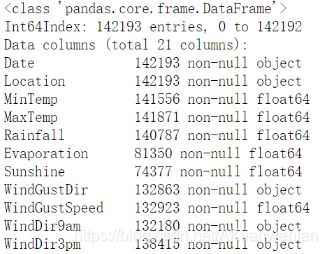
weather.info() #查看数据长相,有多少个特征,有多少条数据,特征的数据类型
查看目标变量的分布
weather.RainTomorrow.value_counts()
3.随机抽样
我们可以先随机抽取10000条数据进行分析建模
# 随机抽取,random_state是随机数种子,为0代表不能重复,1代表可以重复
df = weather.sample(n=10000,random_state=0)
df.index = range(df.shape[0]) #抽取的数据需要重建索引
4.探索变量
df.info()
df.describe().T #观察四分位数,再通过T转置一下,可以比较完整看到各特征的数据分布情况
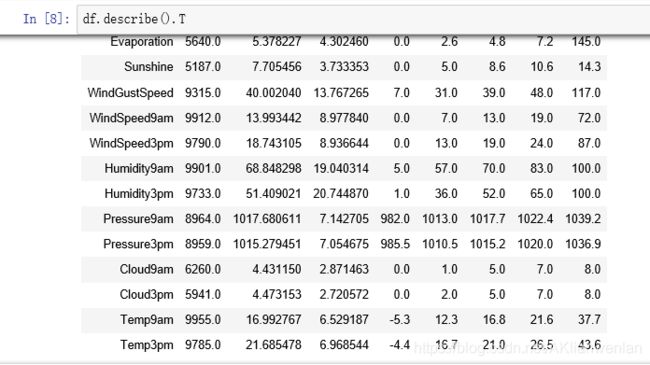
从上述两个数据基本情况可以看出,Cloud9am和Cloud3pm虽然为浮点型数据,但数据取值只有8个,可能为分类型变量。我们来查看一下是否为分类变量?
df.Cloud9am.unique()
df.Cioud3am.unique()

通过查看唯一值,确定Cloud9am和Cloud3pm为分类变量。
5.将样本特征和标签分开
X = df.iloc[:,:-1] #X取所有行中的第一列到倒数第二列
Y = df.iloc[:,-1] #Y取所有行中的最后一列
6.切分训练集和测试集
from sklearn.model_selection import train_test_split
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,Y,test_size = 0.3,random_state = 100)
print(Xtrain.shape,Ytrain.shape,Xtest.shape,Ytest.shape)
切分完训练集和测试集后记得要重置各部分数据的索引
for i in [Xtrain,Xtest,Ytrain,Ytest]:
i.index = range(i.shape[0])
四、数据清洗
1.将特征进行分类整理
建立分类型变量列表
categ_var = Xtrain.columns[Xtrain.dtypes=='object'].tolist() #将数据类型为object的列写到一个列表里,定义为categ_var(分类变量)
categ_var.extend(['Cloud9am','Cloud3pm']) #将上面分析出的Cloud9am和Cloud3pm加到分类变量列表
建立连续型变量列表
#用一个for循环,将数据类型不属于categ_var的列提取出来
cont_var = []
for i in Xtrain.columns:
if i not in categ_var:
cont_var.append(i)
cont_var
2.去重
X.drop_duplicates()
查看如果有10000行数据,说明无重复值,不用去重。
3.异常值处理
定义异常值:大于3倍标准差的数据定义为异常值。
deltrain = [] #需要删除的训练集数据中的异常值
for i in col:
bool_=np.abs((Xtrain.loc[:,i]-Xtrain.loc[:,i].mean())/Xtrain.loc[:,i].std())>3
ind=Xtrain[bool_].index
deltrain.extend(list(ind))
deltrain = list(set(delxtrain)) #将需删除的异常值装在一个列表里
deltest=[] #需要删除的测试集数据中的异常值
for i in col:
bool_=np.abs((Xtest.loc[:,i]-Xtest.loc[:,i].mean())/Xtest.loc[:,i].std())>3
ind=Xtest[bool_].index
deltest.extend(list(ind))
deltest = list(set(deltest)) ##将需删除的异常值装在一个列表里
删除异常值
Xtrain = Xtrain.drop(index=deltrain,axis=0)
Ytrain = Ytrain.drop(index=deltrain,axis=0)
Xtest = Xtest.drop(index=deltest,axis=0)
Ytest = Ytest.drop(index=deltest,axis=0)
删除完数据记得要检查一下数据,如果没问题,再恢复一下索引。
print(Xtrain.shape,Ytrain.shape,Xtest.shape,Ytest.shape) #检查行数
for i in [Xtrain,Xtest,Ytrain,Ytest]: # 恢复索引
i.index = range(i.shape[0])
Xtrain.index
4.缺失值处理
1、用众数来填补分类变量缺失值
#第一步:整理需要用众数填充的列(缺失值占比大于0的分类变量)
categ_mode=Xtrain[categ_var].isnull().mean()[Xtrain[categ_var].isnull().mean()>0].index.tolist()
categ_mode
#第二步:导包,使用众数来填补
from sklearn.impute import SimpleImputer
si=SimpleImputer(missing_values=np.nan,strategy="most_frequent")
si.fit(Xtrain.loc[:,categ_mode])
Xtrain.loc[:,categ_mode]=si.transform(Xtrain.loc[:,categ_mode])
Xtest.loc[:,categ_mode]=si.transform(Xtest.loc[:,categ_mode])
Xtrain.info()
2、均值的方法来填补连续变量(可以尝试用随机森林填补法来填写)
```python
si=SimpleImputer(missing_values=np.nan,strategy="mean")
si.fit(Xtrain.loc[:,cont_var])
Xtrain.loc[:,cont_var]=si.transform(Xtrain.loc[:,cont_var])
Xtest.loc[:,cont_var]=si.transform(Xtest.loc[:,cont_var])
5.对变量进行编码
from sklearn.preprocessing import OrdinalEncoder
Xtrain=Xtrain_copy.copy()
Xtest = Xtest_copy.copy()
# 在categ_var中移除Month,Month不需要编码
categ_var.remove('Month')
oe = OrdinalEncoder()
oe = oe.fit(Xtrain.loc[:,categ_var])
Xtrain.loc[:,categ_var] = oe.transform(Xtrain.loc[:,categ_var])
for i in range(len(categ_var)):
indexs = list(oe.categories_[i])
Xtest[categ_var[i]] = Xtest[categ_var[i]].map(lambda x:indexs.index(x) if x in indexs else -1)
#备份数据
Xtrain_copy = Xtrain.copy()
Xtest_copy = Xtest.copy()
# 复原categ_var表
categ_var.append("Month")
6.处理量纲不统一
对分类型变量进行量纲统一
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss = ss.fit(Xtrain.loc[:,cont_var])
Xtrain.loc[:,cont_var] = ss.transform(Xtrain.loc[:,cont_var])
Xtest.loc[:,cont_var] = ss.transform(Xtest.loc[:,cont_var])
# 备份数据
Xtrain = Xtrain.copy()
Xtest = Xtest.copy()
Ytrain = Ytrain.copy()
Ytest = Ytest.copy()
五、模型创建和评估
from time import time
import datetime
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import roc_auc_score,recall_score
#检查标签是否一致
print(Ytrain.shape,Ytest.shape)
for kernel in ['linear','poly','rbf','sigmoid']:
times = time()
clf = SVC(kernel = kernel,
gamma = 'auto',
degree = 1).fit(Xtrain,Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest,result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
print("%s's testing accuracy is %f,recall is %f,auc is %f"%(kernel,score,recall,auc))
print(datetime.datetime.fromtimestamp(time() - times).strftime('%M:%S:%f'))
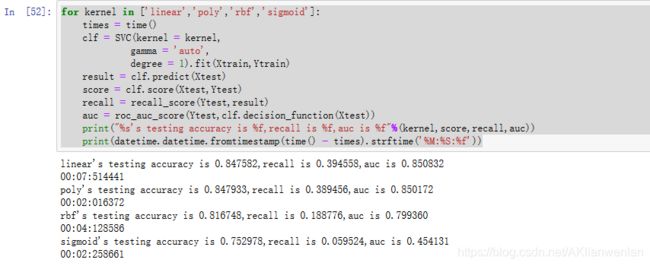 看输出结果得出,通过模型输出结果可以看出accuracy和auc分数还可以,但是recall分数较低。
看输出结果得出,通过模型输出结果可以看出accuracy和auc分数还可以,但是recall分数较低。
在四种核函数中,线性核函数表现最好。