【踩坑记录】OpenPrompt工具包如何使用?
家人们,泪目啊!整整弄了好几个小时,终于是跑起来了,跑起来了啊家人们,一起看看我踩过了哪些坑吧。关于Prompt的介绍可以看博主的另外两篇文章:
简明扼要:红到发紫的prompt是什么?【上】
详细介绍:红到发紫的Prompt是什么?【下】
目录
- 介绍
- 安装
- 运行
- 小demo
- cannot import name 'load_dataset'
- 下载数据集
- demo详解
- 第一步:确定NLP任务
- 第二步:确定预训练语言模型
- 第三步:定义模板
- 第四步:答案映射
- 第五步:构造PromptModel
- 第六步:构造PromptDataLoader
- 第七步:零样本预测

介绍
OpemPromt是一个清华大学提出的专门针对第四范式开发的工具。PromptModel和PromptDataset是用来与pytorch兼容的两个数据结构。PLMs与Tokenizer支持调用和管理各种各样的预处理语言模型。Template是Prompt的特色,该工具提供了很多可供选择的模板。Dataset支持跨不同NLP任务数据集的使用。
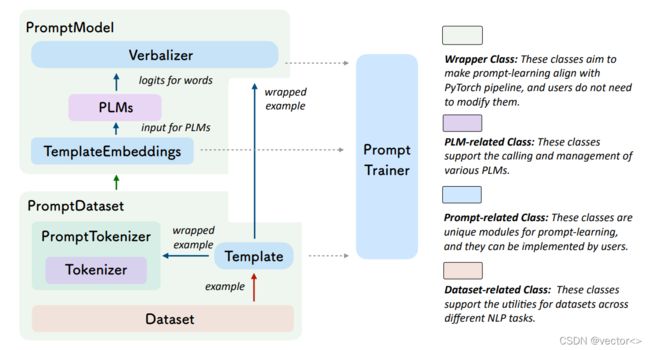
总而言之:OpenPrompt 提供一套完整的 Prompt Learning Pipeline,而其中每个 class 都继承了 torch 的类或者 huggingface 的类来实现,完美兼容最流行的深度学习框架和最流行的预训练模型框架,在代码风格和 pipeline 设计上也是完美贴合 huggingface 框架,让研究者可以以最少的学习成本上手和修改。
读者可以通过下面的参考资料和文献详细了解这个工具,本篇文章仅重点记录如何使用这个工具。
- 链接:https://github.com/thunlp/OpenPrompt
- 论文https://arxiv.org/abs/2111.01998
- 官方文档:https://thunlp.github.io/OpenPrompt/
安装
官方提供了两种安装方式,博主使用的是git方式
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
python setup.py install
此处有一个小坑,上面这三行命令是官方文档中的教程,相比于git中的readme中少了一行
pip install -r requirements.txt
requirements.txt里面记录的是一部分需要安装的工具包,刚开始我只是扫了一眼,发现有很多我已经安装过的包(比如torch,tansformers等),所以抱着偷懒的心态没有执行这一条命令,导致后面不停地找补(频繁报错:no module),建议有条件的读者直接依次运行下面四行命令安装:
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py install
运行
小demo
下载好之后可以打开tutorial文件夹中的脚本进行学习,不过,对我这种小白来说,还是不愿意直接看太长的例子,所以打算从官方文档中的sample入手。根目录下新建一个py文件
# step1:
import torch
from openprompt.data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative",
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample(
guid = 0,
text_a = "Albert Einstein was one of the greatest intellects of his time.",
),
InputExample(
guid = 1,
text_a = "The film was badly made.",
),
]
# step 2
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("bert", "bert-base-cased")
#step3
from openprompt.prompts import ManualTemplate
promptTemplate = ManualTemplate(
text = '{"placeholder":"text_a"} It was {"mask"}',
tokenizer = tokenizer,
)
#step4
from openprompt.prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer(
classes = classes,
label_words = {
"negative": ["bad"],
"positive": ["good", "wonderful", "great"],
},
tokenizer = tokenizer,
)
#step 5
from openprompt import PromptForClassification
promptModel = PromptForClassification(
template = promptTemplate,
plm = plm,
verbalizer = promptVerbalizer,
)
#step 6
from openprompt import PromptDataLoader
data_loader = PromptDataLoader(
dataset=dataset,
tokenizer=tokenizer,
template=promptTemplate,
tokenizer_wrapper_class=WrapperClass,
)
# step 7
# making zero-shot inference using pretrained MLM with prompt
promptModel.eval()
with torch.no_grad():
for batch in data_loader:
logits = promptModel(batch)
preds = torch.argmax(logits, dim=-1)
print(classes[preds])
# predictions would be 1, 0 for classes 'positive', 'negative'
右键运行这个脚本,有可能此时还是会报错,根据提示,缺什么就pip install什么(由于前一步的偷懒,我感觉我至少pip了十几次)。直到控制台成功预测出标签,说明上面的demo运行成功。

cannot import name ‘load_dataset’
我想重点记录一下这个报错,提醒自己不要偷懒。根据控制台的提示可以发现,这是由于某些脚本中某一句import报红导致的错误:
from datasets import load_dataset
看到这个datasets,我理所当然地认为是在OpenPrompt\datasets这个文件夹下引入load_dataset,尝试了很多办法,完全没找到datasets中有任何py脚本,因为这个问题浪费了很多时间,后来才发现,requirements.txt中有提示需要安装datasets这个包,这就说明上述import的是需要安装的外部包,并不是项目里面现存的包,只是作者取了相同的名字而已。只需要pip一下就完事儿了。
pip install datasets
下载数据集
datasets文件夹中有各种sh文件,里面存储的是下载实验数据的shell脚本,根据需要,读者可以选择自己想要的数据集进行下载。因为我的电脑是windows,在pycharm中执行这些脚本会更加方便。参考这篇博客:https://blog.csdn.net/weixin_43897187/article/details/118406368
解决了直接用pycharm运行shell的问题。设置完成之后,我的shell path是这样的:

如果不记得自己的git安装目录在哪里,在cmd中输出 where git 既可以看到了(保姆级别的教程了有没有!)
继续尝试运行shell脚本,可能会报错:wget:command not found

参考这篇博客:https://blog.csdn.net/u013810234/article/details/104408009完美解决。运行shell脚本就可以看到数据集已经被下载下来了。
demo详解
既然已经可以跑通了,那么我们一起来看一下官方给的小小demo都有哪些值得学习的地方吧~
第一步:确定NLP任务
确定NLP任务也就是需要确定输出标签以及数据集。这里的输出标签指的是下游任务的输出,也就是y。本例只有两个类别,表示情感正向的positive,和情感负向的negative。
# 第一步:确定NLP任务(简单起见以情感分析作为例子)
import torch
from openprompt.data_utils import InputExample
# 1. 确定类别:也就是确定数据标签,本例只有两个类别,表示情感正向的positive,和情感负向的negative
classes = [
"negative",
"positive"
]
# 2.确定数据集:为了简单起见,这里只有两个例子text_a是数据的输入文本,一些其他数据集可能在一个例子中有多个输入句子
dataset = [
InputExample(
guid = 0,
text_a = "Albert Einstein was one of the greatest intellects of his time.",
),
InputExample(
guid = 1,
text_a = "The film was badly made.",
),
InputExample(
guid = 2,
text_a = "That is wonderful.",
),
]
这个小demo没有从外部加载数据集,这是简单构造了一个测试句子。对于一个正常的流程,需要从外部加载训练测试集和测试集。
第二步:确定预训练语言模型
这里加载的是一个训练好的bert语言模型,这也是为什么上一步只有测试数据没有训练数据的原因。
# 第二步:定义预训练语言模型(PLMs)作为主干。
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("bert", "bert-base-cased") # 这里选择的预训练语言模型是bert
第三步:定义模板
这一块对应就是模板工程中的问题了,本例采用的格式是 [x],It was [Z],x对应代码中的text_a,应填入输入语句。Z对于mask,是LM的预测结果。
# 第三步:定义模板。
from openprompt.prompts import ManualTemplate
promptTemplate = ManualTemplate(
text = '{"placeholder":"text_a"} It was {"mask"}',
tokenizer = tokenizer,
)
第四步:答案映射
这一块对应的是答案工程,在这个例子中把消极类投射到单词bad,把积极类投射到单词good, wonderful, great。
# 第四步:定义Verbalizer是另一个重要的
# Verbalizer将原始标签投射到一组lable单词中。在这个例子中把消极类投射到单词bad,把积极类投射到单词good, wonderful, great
from openprompt.prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer(
classes = classes,
label_words = {
"negative": ["bad"],
"positive": ["good", "wonderful", "great"],
},
tokenizer = tokenizer,
)
第五步:构造PromptModel
promptModel有三个对象,分别是:PLM,Prompt,Verbalizer,分别对应Prompt研究重点中的这三个部分:

# 第五步:将它们合并到PromptModel中
# 给定任务,现在我们有一个PLM、一个模板和一个Verbalizer,我们将它们合并到PromptModel中。
# 请注意,尽管示例简单地组合了三个模块,但实际上可以在它们之间定义一些复杂的交互。
from openprompt import PromptForClassification
promptModel = PromptForClassification(
template = promptTemplate,
plm = plm,
verbalizer = promptVerbalizer,
)
第六步:构造PromptDataLoader
与数据加载和数据处理有关
# 第六步:定义DataLoader
# PromptDataLoader基本上是pytorch Dataloader的prompt版本,它还包括一个Tokenizer、一个Template和一个TokenizerWrapper。
from openprompt import PromptDataLoader
data_loader = PromptDataLoader(
dataset=dataset,
tokenizer=tokenizer,
template=promptTemplate,
tokenizer_wrapper_class=WrapperClass,
)
第七步:零样本预测
在上述过程中,没有用任何训练数据对Bert进行调整,就实现了零样本的情感分类。只需要将Model处理为PromptModel,DataLoader处理为PromptDataLoader就可以向基于Pytorch的其他机器学习一样完成训练和测试。
# 第七步:训练和预测:完成了!我们可以像Pytorch中的其他过程一样进行训练和推理。
# making zero-shot inference using pretrained MLM(masked language model) with prompt
promptModel.eval()
with torch.no_grad():
for batch in data_loader:
logits = promptModel(batch)
preds = torch.argmax(logits, dim=-1)
print(classes[preds])
# predictions would be 1, 0 for classes 'positive', 'negative'