【姿态估计文章阅读】Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation
 一、这是毫无疑问的大佬们的文章,2014年出就发布了第一版本,代码:https://github.com/max-andr/joint-cnn-mrf
一、这是毫无疑问的大佬们的文章,2014年出就发布了第一版本,代码:https://github.com/max-andr/joint-cnn-mrf
二、文章的核心思想
1、利用CNN做姿态估计,采用heatmap的方式来回归出关键点
2、利用人体关键点之间的结构关系,结合马尔科夫随机场的思想来优化预测结果,主要针对于网络预测的false postive。
三、这是早期的deep learning应用到姿态估计文章,所以有比较大篇幅网络模型设计,但是这部分的设计过程依然非常值得学习和思考,每一步都有讲究,不是说说的那种,是理论结合实际出发提出的改进。
先来看看模型迭代的过程:



1号模型:想要采用滑动窗口的方式,结合上多尺度(pyramid),这里的LCN是local contrast normalized,这种拉普拉斯金字塔可以让卷积核non-overlapping spectral content,从而降低网络的redundancy(字打不出来了)。这种over-lapping的滑动窗口方式可以保留更多的内容,同时拥有“平移不变性”。
2号模型:解决了1号模型利用滑动窗口计算上会比较慢的缺点,因为巨大的redundant 卷积,而且同时期的一些研究工作证明了2号模型这种方式可以产生有效的dense feature map。
3号模型:结合了1、2模型,3号模型的下半部分的步长直接等于1/2的原始大小,其他部分比较好理解,着重看“Interleaved”这部分,其实和另一个idea很像“pixel shuffle”,注意上面的每个颜色块对应到前面的4个部分(1,1),(1,2),(2,1),(2,2),这样可以提高空间上的精度吧。
4号模型:依然是取代了滑动窗口,同时利用upscale把feature map大小提上来(对比与3号模型,在两个分支的feature 融合之前)3号模型利用了类似“pixel shuffle”的方式来upscale,4号模型应该是直接上采样,比如双线性插值(这里具体用的什么方式,有人知道的话告诉我下)。
大致的模型构建过程,在这里就结束了。
四、第二大核心内容“Higher-Level Spatial-Model”
这里作者,通过验证集发现,网络预测heatmap存在着很多的false positive,而且姿态是不正确的(anatomically incorrect),这里就是说,检测器只是在检测一个图中相似的目标,没有理解人的姿态这个核心思想,不懂什么是姿态。但是并不能说,CNN在回归的过程中没有参考“相关的关键点之间的联系”,因为网络的复杂结构,在拟合过程中很可能存在着比较弱的关联性体现,对这部分的学习也比较弱,毕竟我们的label对于每个人都是一对点,没有给出关联性的体现。
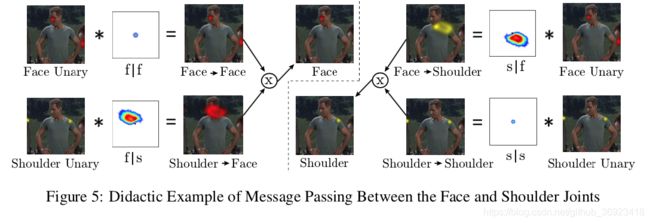
我们也不难发现,头部预测的peak出现在heatmap中的时候,其实肩部也会在附近。但是目前CNN可能对这部分没有那么好的直接进行学习,所以建立了“spatial model”进行优化,对于那部分false positive 进行移除。
we start by connecting every body part to itself and to every other body part in a pair-wise fashion in the spatial model to create a fully connected graph.也就是说,构建的是全联接的图,同时每个点还有个自链接。
那么CNN直接回归出heatmap,可以看成一堆的先验概率,以及条件概率(因为CNN预测的时候是一次性“同时”预测出n个关键点的概率,因此可以当成是条件概率,也就是在B出现的条件下A出现的概率)
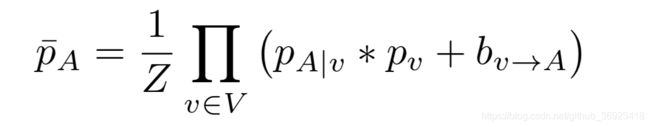
上面这个公式是最终的概率。文章说了,对于FLIC这个数据集是来自于好莱坞的所以很多是正面的镜头,而且是站立的,因此能够得到比较稳定的结构信息,空间概率推测信息,比如头的左下部会出现右肩。但是对于LSP这个数据集变化较大,因此这个模型的效果也会相应被减弱。![]()
在实际应用中作者把大Z去掉了,有以下几个原因:1、我们只关注heatmap上的极大值点,或者最大值点,这一个点,在预测过程中heatmap我们只是希望能够更加接近标准正态分布就行了;2、反向传播的时候这个Z只会相当于在这部分的梯度上乘了一个系数而已;3、每个人并不是一定是完整的,所以也是无法规范化的。下面是改进后的公式(虽然不再是标准的马尔可夫随机场了,但是依然对于适合用于空间限制的编码):
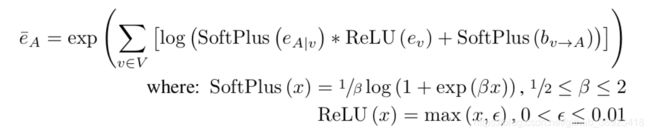 the addition in log space means that the partial derivative of the loss function with respect to the convolution output is not dependent on the output of any other stages。这里很多取巧的地方避免的训练和回传时候的梯度问题,保证空间连续可导,防止出现0之类。而且整个计算过程可以很方便的嵌入到深度学习框架中:
the addition in log space means that the partial derivative of the loss function with respect to the convolution output is not dependent on the output of any other stages。这里很多取巧的地方避免的训练和回传时候的梯度问题,保证空间连续可导,防止出现0之类。而且整个计算过程可以很方便的嵌入到深度学习框架中:
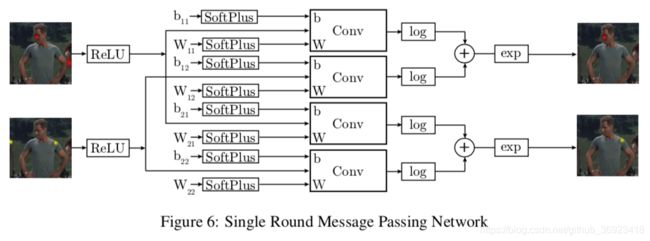
这张图也回答了我们,条件概率(e A|v),background 概率(b v->A)这两部分是来自于网络学习的,一开始看的时候以为是通过统计得到的,后来发现这些全部都是通过网络自己学习得到的。这里卷积核也是非常大的,需要能够去覆盖“最大的两个关键点之间的距离”,因此对于90x60的输出,卷积核达到了128x128,这样能覆盖64个像素之内的关键点偏移,比如手腕到手肘(这里卷积核为什么是偶数,我也不知道,当然是需要padding的,而且要用FFT的方式进行卷积计算,初始化也比较特别,The convolution weights are initialized using the empirical histogram of joint displacements created from the training examples.)。
六、训练
先单独训练(单独训练,先训练回归模型,然后再基于回归模型训练空间模型),然后一起再微调。 Unified training of both models (after independent pre-training) adds an additional 4-5% detection rate for large radii thresholds.

从这张图,可以发现,空间模型,在eval的时候,阈值越小(要求离groundtruth越近)时,效果不明显,这也和文章一开始预料的一样,这个方法不是用来提升“本身以及比较好的那部分结果的”,而是用于纠正那部分“错的比较明显的那部分”。