实录 | 旷视研究院详解COCO2017人体姿态估计冠军论文(PPT+视频)
主讲人:王志成 | 旷视研究院研究员
屈鑫 整理编辑
量子位 出品 | 公众号 QbitAI
12月13日晚,量子位·吃瓜社联合Face++论文解读系列第二期开讲,本期中旷视(Megvii)研究院解读了近期发表的人体姿态估计论文:Cascaded Pyramid Network for Multi-Person Pose Estimation。
基于这篇论文所提出的算法,Megvii(Face++)队在COCO2017人体姿态估计竞赛上获得了历史最好成绩,相对 2016年人体姿态估计的最好成绩提高了19%。
本期主讲人为旷视研究院研究员王志成,同时也是COCO 2017 Detection竞赛队owner、论文共同一作,在比赛中主要负责整体方案的确定,模型设计、训练调优的工作。
量子位应读者要求,将精彩内容整理如下:
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1.7647058823529411" data-w="480" data-src="http://v.qq.com/iframe/player.html?vid=v0520v2marp&width=670&height=376.875&auto=0" style="display: block; width: 670px !important; height: 376.875px !important;" width="670" height="376.875" data-vh="376.875" data-vw="670" src="http://v.qq.com/iframe/player.html?vid=v0520v2marp&width=670&height=376.875&auto=0"/>
△ 直播回放视频
本期主要讲的是人体姿态估计算法,主要内容如下:
1 Top-down Pipeline
2 Network Design
A. Motivation: How human locate keypoints?
B. Our Network Architecture
3 Techniques & Experiments
4 Conclusion
下一期将会由黎泽明为大家讲解Light-Head R-CNN,欢迎12月20日晚19:30来观看直播。
Top-down Pipeline

现在我们做Pose Estimation主要有两种Pipeline,这次比赛使用的是Top-down Pipeline:先用detector检测出图象中的人,再把每一个人的图像抠图,抠出来的单人的图过single person Pose Estimation Network(即单人姿态估计网络),最后把所有的单人估计出来的姿态,整合到原图中,得到最终结果。
先讲一些网络设计过程中的细节。
我们在这次比赛方法的Motivation跟paper中写的稍微有一点出入,因为在写paper的时候补充了一些实验,并对整体架构做了一定的重新梳理。
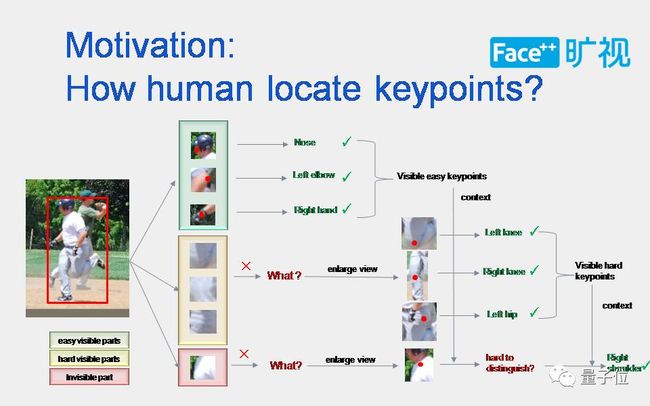
我们最初的Motivation是来源于对人怎么去看人体关节点这个问题的思考。在分析的这个问题的时候,我们会发现在人看人的关节点的时候,会下意识地先看人体裸露在外面的关节点。比如说鼻子,从这张图上来看裸露在外面的关节点,它会有相对固定的形状和纹理,所以这类关节点可能是一些Visible easy keypoints,人其实是会更倾向于先去看到这些关节点。但是在初级的阶段,有些关节点是相对难于被识别的,比如被衣服遮挡的关节点。
那么人是怎么样去看比较难的关节点呢?人可能会无意识地放大或者利用可见点的上下文信息来推断其他点的信息。有些点是隐藏的,不仅是被衣服遮挡,识别这一类关节点会更难,需要利用更多的上下文信息。
从人理解关节点的过程,我们受到了很大的启发,但是怎么样做才可以把看keypoint这个过程体现在卷积神经网络里呢。我们很难人为定义哪些关节点是可见容易关节点,哪些是被遮挡的关节点,哪些是隐藏的关节点。
为了解决这个问题,我们退而求其次,把人体的关节点,大致分类两类:简单的部分和难的部分。用不同的方案去解决简单点和难点,先解决容易点,再解决难点。在解决难关节点部分时,提供更多的上下文信息,更大的可感受野。
Network Design

介绍一下提出的网络结构。
首先,宏观地讲解一下网络的概括。
从人看关节点的过程获得启发,然后将这一启发运用到卷积神经网络里,先解决简单部分再解决难的部分。这是一个两阶段网络:全局网络和精炼网络。全局网络,主要是解好一些容易点;精炼网络,主要是定向解决更难的一些点。具体的实施方法用到了在线难关节点挖掘的算法。
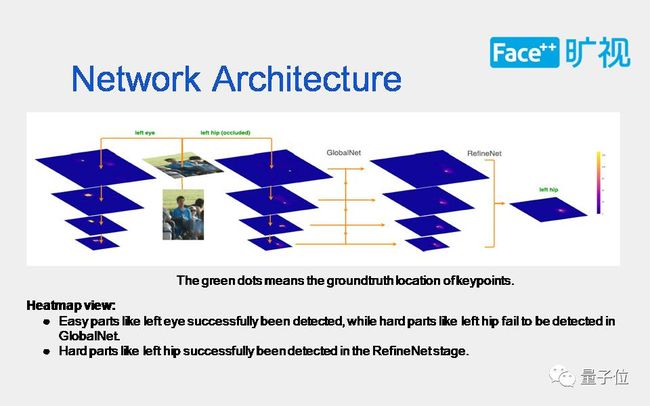
这张图上,热力图可以体现出我们的网络设计原理,图上的绿点是关节点对应的ground truth。从图中左边的部分可以看出左眼作为相对容易的关节点,在前阶段的全局网络就可以解的很好。而右边的左臀部,作为相对较难的遮挡点,需要在后面的精炼网络里面才能识别出来。
再介绍一些网络设计和实验上的细节。
Top-down的框架是先检测人,人抠出来之后,再去做姿态估计。所以有必要对person detection(行人监测器)做一定的分析。首先解释一下非最大值抑制。现在有两种主流的方式:软非最大值抑制(Soft NMS)和硬非最大值抑制(Hard NMS),软非最大值抑制是对所有的候选框去做重新的估分,对比较差的框保留但会抑制分数。硬非最大值抑制就是将IOU超过阈值之后的分数比较差的那些框过滤掉。所以两种方式最终实现的结果是Hard NMS保留的框比较少,而Soft NMS对框的分数做了一个修改,保留了较高的召回率(recall)。
我们在paper中有做过一组实验来比较这两种策略对keypoint准确率有什么影响。这张表就是反映了实验的结果。
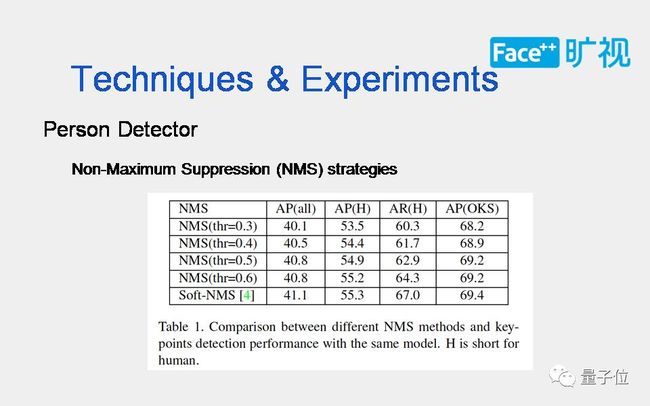
从这张表中可以看出,使用Hard NMS的实验比使用Soft NMS的实验差,这张表中实验的其他配置都是相同的。 Hard NMS的不同阈值也会有所影响,阈值越高,keypoint精度越高。
COCO评测的时候,每个ground truth会匹配分数排序前20个的候选检测人,Soft NMS 在recall上会比较占优势,所以对应的Keypoint AP一般来说也会比较高。同时Soft NMS对分数抑制后,会反映在keypoints最终得分数上(keypoints 最终分数 = 检测框分数 * keypoints 平均分数),而该分数是用来排序评测,会从另外一个角度提高Keypoint AP。
Detection Performance
我们用的检测框来自于我们detection team,而旷视研究院detection这一次也是拿了COCO的第一名,分数很高。所以在这里我们有必要分析下detection AP对Keypoint AP有多大影响。

我们有关detection的这组实验室从detectionAP 36.3开始到52.1。52.1是今年冠军的水平,36.3目前属于一般水平,44.1属于是平均水平。我们在36.3的detection mAP上是68.8,41.1的是69.4,44.3的是69.7,也就是说到后来在detection mAP有明显提升的情况下,在keypoint mAP上基本没有提升。
所以我们可以得出一个结论,detetion mAP的提升在一定范围之内会对Keypoint 的AP产生积极影响,但超过这个范围后,影响是微乎其微的。这里与detection的检测目标与keypoint检测的目标不同有关系。

介绍下我们网络。

Online Hard Keypoints Mining,从这张图可以看出我们是怎么去做Hard Keypoints Mining的。COCO有17个点,我们输出17个heatmap,把每个heatmap计算loss之后再回传。Online Hard Keypoints Mining是相当于把每一个headmap计算之后,按照关节点为粒度做平均,把17个loss排序,把最难的那一部分的keypoints回传,剩下的简单的一部分,不回传loss或者是把loss置为0。
在比赛中也主要就是用了类似策略。简单分析一下:如果是17个点,在二分之一的位置回传loss比较好。

右边这个表说明了普通的L2 loss和Online Hard Keypoints Mining的loss各有什么区别。最后可以看出前面用普通的L2 loss,后面用Online Hard Keypoints Mining的loss会更科学点。
因为前面其实是在宏观上对所有关节点做预测,后面的loss是把前面没有解完或者不好的关节点用作学习。这种情况下他们就各有分工,也会解得比较好。
下面讲一讲设计RefineNet。

我们首先看是只采用全局网络的网络结构,AP是66.6。后面的是在全局网络输出特征上进行直接concat,把不同层的的信息整合起来去预测后面的keypoint的话会有一定的提升,提升单位有两个点左右。
下面的是,在concat之前会加一个bottleneck,增加难度的同时增加了复杂度,该配置下网络有69.2的AP,按照我们前面介绍的网络结构会在更小FLOPs下有0.2个点的提升。
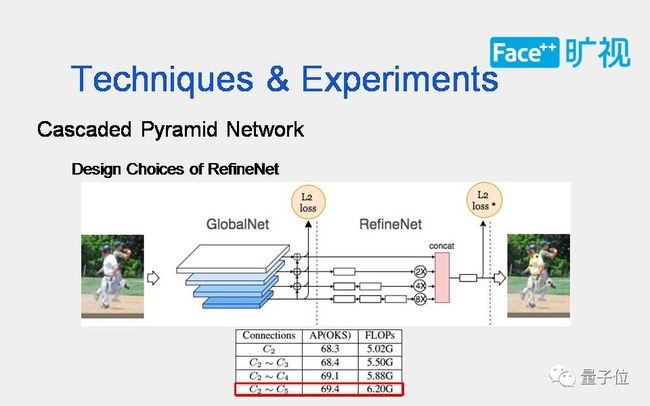
我们从只采用c2的特征输出开始分析,直到取到c2~c5。从c2开始,c2只提取了一个层的特征,然后从c2到C3, c2到c4, c2到c5。从实验结果来看,取c2到c5的网络结构效果最好。
接下来说一下Pre-processing方面的细节,Pre-processing这块从比赛到之后的一些实验获得了一个结论:图片尺寸越大AP越高。
怎么样设计图片尺寸?如果你把256:256的图片往大放,一般来说就不会涨点。方形的图片再往大放的话,对应的batch_size会缩小,图片很大,每个interation学习的图片就会变少, AP会降低。在这种情况下,我们发现把图片的尺寸设置成256x192类似的比例。既能满足图片的尺寸,又能满足batch_size的要求,而能实现这一要求的原因主要是人的形状一般是长形的而不是方形的,用方形的尺寸会增加计算量而不提高精度。
我们在Pre-processing中大概抠出来人之后做一个padding,padding到与256x192相同比例的尺寸,然后再resize到256x192尺寸。
小技巧

Crop augmentation
先crop,后padding再resize,这样输入图片会保持长宽比。我们做过类似的实验,抠图直接resize到输入尺寸,这样图片会损失长宽比,结果会差一点。然后,我们会先做加入Random scales,把框进行随机扩大或者缩小。
Rotation
目前主流的处理方式rotate负30度到正30度,这次我们用的是负45度到正45度。这个Rotation一般来说会有提升但是不会很大,主要是用在一些比较极端的情况下,比如人是斜着的。
在后面做实验的时候,发现了另外一种思路:直接把人旋转,检测出人的头,或某个部位之后,按照一定的角度把人转正。
Large Batch
Large Batch在 keypoints上也是有用的,大概能提到0.4到0.3的点的AP。
模型融合
我们提交结果的时候做过模型融合,使我们在minival上大概能提升到1到1.5个点。
COCO比赛的结果

在COCO test-dev数据里,我们有两个网络,一个是单模型结果,一个是有模型融合结果。单模型的结果也基本比test-challenge中后几位都要高,而且我们没有用更多的数据。

后面是说我们自己的minival数据集。minival数据集上是74.5,在test dev上是73,test challenge是72.1。
这是一个图片的结果的展示。从结果上可以看出视觉效果还不错,下面放一个视频中的人体关节点检测例子。这个视频是基于单帧做预测的结果,没有采用帧间平滑。
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1.7647058823529411" data-w="480" data-src="http://v.qq.com/iframe/player.html?vid=s05217u6x34&width=670&height=376.875&auto=0" style="display: block; width: 670px !important; height: 376.875px !important;" width="670" height="376.875" data-vh="376.875" data-vw="670" src="http://v.qq.com/iframe/player.html?vid=s05217u6x34&width=670&height=376.875&auto=0"/>
总结

两个阶段的网络很重要,不同的阶段识别的keypoints不一样,easy point和hard point分开。
Intermediate supervision很重要。
Large batch,在keypoint上也是有用的。
一则招人硬广:
希望加入旷视科技一起登上CV巅峰的同学可以投简历至:[email protected],长期招聘算法实习生。实习优秀者,更有直接跳过面试阶段,入职megvii研究院的机会。
Q&A
在视频中进行Keypoint检测怎么加入tracking?能否用keypoint检测做行人检测和行人多目标跟踪?
我们现在也在做tracking,具体一些细节现在还不能透露,因为后面也会准备一个paper。能否用keypoint检测做行人检测和行人多目标跟踪这个的话,其实在做行人检测上,可以用keypoint的检测结果做post filter滤掉行人检测的FP。Bottom Up的方法可以用紧框去做行人检测,最好与现有检测框架共同去检测行人,行人多目标跟踪的话,现在有很多方法是用人体关节点作为特征来比对跟踪目标,keypoint的作用主要在用于提供特征。
Softnms阈值是怎么确定的?
我们是用默认的阈值,因为我们这一块主要focus在keypoint上,detection大概也是只是用了一下,没有去更多的去挖掘。
请问判断easy point和hard point的依据是什么?
我们没办法去定义什么是easy point,什么是hard point,正是因为这样,所以我们就做了一个Online Hard Keypoints Mining。在线将那些loss值比较高的关节点作为难关节点来学习。
Code有开源的计划吗?
有的,不过我们的code是旷视自研深度学习框架Meg Brain上实现的,要迁移到开源框架(如tensorflow)需要一个过程,还有开源时间也跟我们的工作安排有关。
人体姿态检测的应用场景主要有哪些?
我觉得随着技术的不断成熟,人体姿态检测的应用场景会越来越多,比如:步态分析、行为分析、零售等场景。
Train的batch是多少?
我们训练的时候根据输入图像的尺寸不同,batch_size在20到64之间。
相关学习资源
以上就是此次旷视研究院王志成带来分享的全部内容,在量子位公众号(QbitAI)界面回复“171219”可获得完整版PPT以及视频回放链接。
第一期回顾:旷视研究院解读COCO2017物体检测算法夺冠论文
P.S. 12月20日(周三)晚19:30,旷视研究院研究员、COCO竞赛队主力队员、论文一作黎泽明,将带来吃瓜社第三期:解读Light-Head R-CNN,一起讨论如何在物体检测中平衡精确度和速度,欢迎报名~
— 完 —
活动报名
加入社群
量子位AI社群12群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot4入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot4,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态