机器视觉库之detectron2安装及使用详解
机器视觉库之detectron2安装及使用详解
本文转自:https://blog.csdn.net/qq_18560985/article/details/124539628
文章目录
- 前言
- 一、Detectron2的安装
- 二、简单的运行案例
-
- 1.利用已有的模型进行各种测试
- 2.训练自己的模型
- 总结
前言
detectron2是Facebook的一个机器视觉相关的库,建立在Detectron和maskrcnn-benchmark基础之上,可以进行目标检测、语义分割、全景分割,以及人体体姿骨干的识别。这个项目在GitHub上已经有超过了20k的星星。
一、Detectron2的安装
在Detectron2的官网上已经给出了Linux平台的安装方法。在这里介绍另外一个常用的平台即windows上的安装方法。
- 首先,需要保证你的电脑上有3.6版本以上的python环境以及c++相关的生成工具。
- 其次,如果你的电脑正好配有Nivdia的显卡,且支持cuda。你可以在Nvidia的官网上下载最新的pytorch对应的cudatoolkit版本和cudatoolkit对应的cudnn,在下载cudnn的时候可能需要你注册成为Nvidia的会员(免费)并填写一个意向问卷。如果没有相应的显卡,可以直接下载cpu版的pytorch
- 然后,你需要保证你的python环境有一下的这些包,pillow、Cython、opencv-python、numpy、matplotlib,并按照pytorch官网的提示安装pytorch
- 最后你需要在Detectron2克隆下完整的代码,并解压,在Detectron2-main(从GitHub上克隆下来的项目)的目录下执行同样的命令即
pip install -e.在执行命令的时候请务必保证你所在的目录有setup.py,如果你的电脑没有右键在终端打开,可以在cmd下找到项目的目录运行同样的命令。
二、简单的运行案例
1.利用已有的模型进行各种测试
首先,不管是训练模型还是预测模型都需要有数据集,在这里作者要介绍的便是大名鼎鼎的coco数据集(Common Objects in Context) 它由世界各大商业巨头如谷歌、微软、脸书 赞助的。cocodataset包含常见类别80类,大约330K的图片(超200K以标注)。coco数据集每年都在更新,在这里我们以val2017数据集为例做预测。
小提示: 如果你感觉在coco数据集的官网下载速度较慢的话可以复制下载链接放到百度云的新建下载中进行中转加速下载。第一次运行以下代码建议在非自带ide中或者直接双击py文件运行。
#detectron2相关的库
import detectron2
import cv2
from detectron2 import model_zoo #前人训好的模型
from detectron2.engine import DefaultPredictor #默认预测器
from detectron2.config import get_cfg #配置函数
from detectron2.utils.visualizer import Visualizer #可视化检测出来的框框函数
from detectron2.data import MetadataCatalog #detectron2对数据集预留的标签
from matplotlib import pyplot as plt #画画函数
cfg=get_cfg()
#cfg.MODEL.DEVICE='cpu' #如果你的电脑没有Nvidia的显卡或者你下载的是cpu版本的pytorch就将注释打开
im=cv2.imread("val2017\\000000009590.jpg") #放入图片的地址
#plt.figure(figsize=(20,10))
#plt.imshow(im[:,:,::-1])
#plt.show()
进行目标检测
##物件辨识
cfg.merge_from_file(model_zoo.get_config_file("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml")) #设定参数档/迁移
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST=0.7 #阈值
cfg.MODEL.WEIGHTS=model_zoo.get_checkpoint_url("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml") #真正参数档
predictor=DefaultPredictor(cfg)
outputs=predictor(im)
print(outputs['instances'].pred_classes)
print(outputs['instances'].pred_boxes) #方框标记值
all_things=MetadataCatalog.get(cfg.DATASETS.TRAIN[0]).thing_classes #中继资料/标记值
preds=[all_things[x] for x in outputs['instances'].pred_classes]
v=Visualizer(im[:,:,::-1],MetadataCatalog.get(cfg.DATASETS.TRAIN[0]),scale=1.2)
v=v.draw_instance_predictions(outputs['instances'].to("cpu"))
plt.figure(figsize=(20,10))
plt.imshow(v.get_image())
plt.show()
效果图:

进行语义分割
##语义分割
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST=0.5
cfg.MODEL.WEIGHTS=model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
predictor=DefaultPredictor(cfg)
outputs=predictor(im)
v=Visualizer(im[:,:,::-1],MetadataCatalog.get(cfg.DATASETS.TRAIN[0]),scale=1.2)
v=v.draw_instance_predictions(outputs['instances'].to("cpu"))
plt.figure(figsize=(20,10))
plt.imshow(v.get_image())
plt.show()
效果图:

进行体姿骨干检测
##体姿骨干
cfg.merge_from_file(model_zoo.get_config_file("COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST=0.7
cfg.MODEL.WEIGHTS=model_zoo.get_checkpoint_url("COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml")
predictor=DefaultPredictor(cfg)
outputs=predictor(im)
v=Visualizer(im[:,:,::-1],MetadataCatalog.get(cfg.DATASETS.TRAIN[0]),scale=1.2)
v=v.draw_instance_predictions(outputs['instances'].to("cpu"))
plt.figure(figsize=(20,10))
plt.imshow(v.get_image())
plt.show()
效果图:
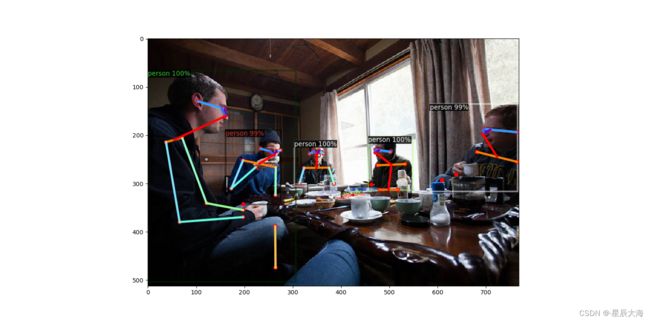
进行全景分割
##全景分割
cfg.merge_from_file(model_zoo.get_config_file("COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST=0.7
cfg.MODEL.WEIGHTS=model_zoo.get_checkpoint_url("COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml")
predictor=DefaultPredictor(cfg)
outputs=predictor(im)
v=Visualizer(im[:,:,::-1],MetadataCatalog.get(cfg.DATASETS.TRAIN[0]),scale=1.2)
v=v.draw_instance_predictions(outputs['instances'].to("cpu"))
plt.figure(figsize=(20,10))
plt.imshow(v.get_image())
plt.show()
效果图:
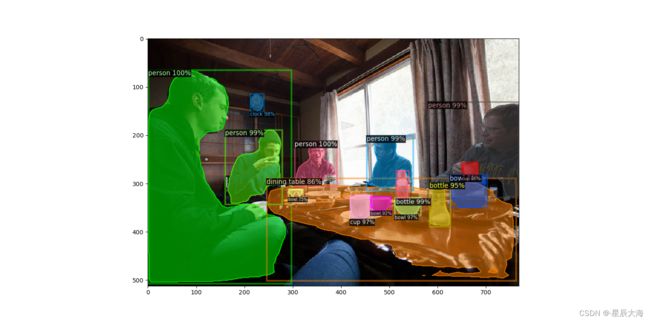
2.训练自己的模型
要想训练自己的模型,那就得有自己的数据集或者从某些地方下载下来的数据集,在这里我们使用coco数据集的气球数据集,免去了自己标记的繁琐行为,当然你也可以自己标记,在这里作者推荐使用labelme来实现图像的标记,在其项目地址有具体的安装方式,当然如果你的平台是windows,也可以直接下载可执行的exe文件 。
在detectron2的官方文档中详细介绍了如何注册自己的数据集,包含文件路径、标记值、框的高度和宽度、框的样式、图片的id、类别的id、是否只包含单独一个类的标记等,另外的一个Metadata可注册也可不注册,如果不注册则标签视为默认的0,1,2,3,…,detectron2给出了标准的字典(dicts),你需要对相应的json文件进行一定的处理使之符合detectron2的标准。具体的标准形式长什么样子,可以尝试使用labelme标记一个图片并查看其生成的json文件。
在这个案例中笔者用balloon数据集来尝试进行物体识别。数据集采用balloon数据集 。
加载必要的库:
import numpy as np
import json
import cv2
import os
import random
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog #注册Metadata
from detectron2.data import DatasetCatalog #注册资料集
from detectron2.engine import DefaultTrainer
from detectron2.structures import BoxMode #标记方式
from matplotlib import pyplot as plt
将数据集中已经标好的json文件做成符合detectron2的字典格式:
def get_balloon_dicts(img_dir):
json_file=os.path.join(img_dir,'via_region_data.json')
with open(json_file) as f:
imgs_anns=json.load(f)
dataset_dicts=[]
for idx,v in enumerate(imgs_anns.values()):
record={} #标准字典档
filename=os.path.join(img_dir,v['filename'])
height,width=cv2.imread(filename).shape[:2] #获取尺寸
record['file_name']=filename
record['image_id']=idx
record['height']=height
record['width']=width
annos=v['regions'] #范围
objs=[]
for _,anno in annos.items():
assert not anno['region_attributes']
anno=anno['shape_attributes']
px=anno['all_points_x']
py=anno['all_points_y']
poly=[(x+0.5,y+0.5) for x,y in zip(px,py)] #标记框框
poly=[p for x in poly for p in x]
obj={
'bbox':[np.min(px),np.min(py),np.max(px),np.max(py)], #左上角坐标和右下角坐标
'bbox_mode':BoxMode.XYXY_ABS,
'segmentation':[poly],
'category_id':0, #类别id
'iscrowd':0 #标注对象是否发生堆叠
}
objs.append(obj)
record['annotations']=objs
dataset_dicts.append(record)
return dataset_dicts
注册数据集:
for d in ['train','val']: #注册数据集
DatasetCatalog.register('balloon_'+d,lambda d=d: get_balloon_dicts('./balloon/'+d))
MetadataCatalog.get('balloon_'+d).set(thing_classes=['balloon'])
配置并开始训练&测试:
cfg=get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml")) #预设档,参数
cfg.DATASETS.TRAIN=('balloon_train',) #训练集
cfg.DATASETS.TEST=('balloon_val',) #测试集
cfg.DATALOADER.NUM_WORKERS=0 #执行序,0是cpu
cfg.SOLVER.IMS_PER_BATCH=1 #每批次改变的大小
cfg.SOLVER.BASE_LR=0.01 #学习率
cfg.SOLVER.MAX_ITER=100 #最大迭代次数
cfg.MODEL.WEIGHTS=model_zoo.get_checkpoint_url("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml") #迁移基础
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE=128 #default:512 批次大小
cfg.MODEL.ROI_HEADS.NUM_CLASSES=1 #一类
cfg.MODEL.DEVICE='cpu' #注释掉此项,系统默认使用NVidia的显卡
cfg.OUTPUT_DIR = 'D:/temp_model'
os.makedirs(cfg.OUTPUT_DIR,exist_ok=True)
trainer=DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()
cfg.MODEL.WEIGHTS=os.path.join(cfg.OUTPUT_DIR,'model_final.pth')
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST=0.7
predictor=DefaultPredictor(cfg)
val_dicts=DatasetCatalog.get('balloon_val')
balloon_metadata=MetadataCatalog.get('balloon_val')
s1,s2=0,0
for d in val_dicts:
im=cv2.imread(d['file_name'])
outputs=predictor(im)
s1+=len(outputs['instances'].get("pred_classes"))
with open('./balloon/val/via_region_data.json') as f:
im_js=json.load(f)
for i in im_js.keys():
s2+=len(im_js[i]['regions'])
print(s1/s2)
由于笔者的电脑显卡不够所以用cpu来跑:
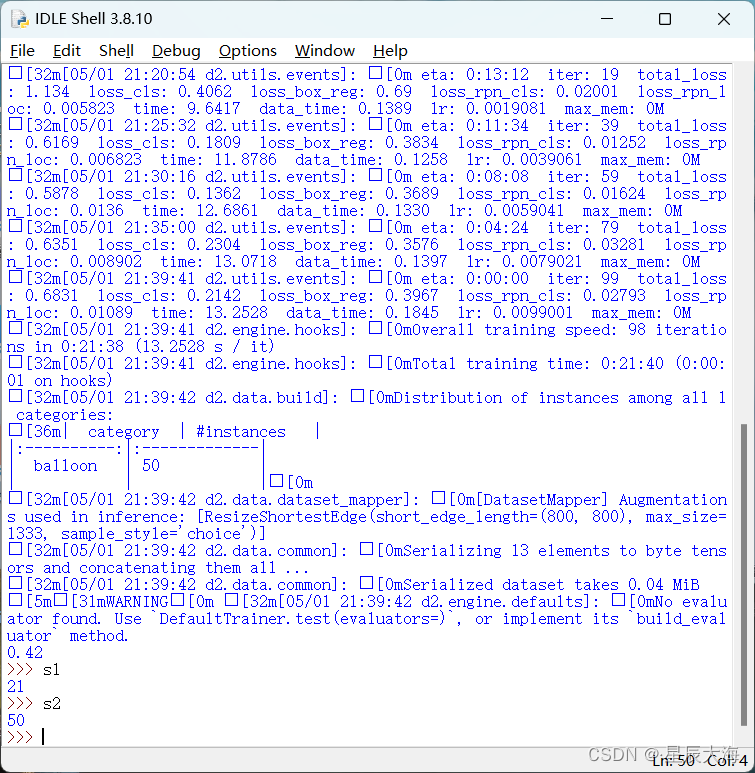
由于最大迭代次数只有100,所以在50个标注的气球框里只找出了21个气球,准确率高达42%…,不过这个准确率也可能大于1,很多时候同一个气球可能会被标上好几个框,特别是多个气球重合的情况下。
随机测试3张图看一下效果:
for d in random.sample(val_dicts,3):
im=cv2.imread(d['file_name'])
outputs=predictor(im)
v=Visualizer(im[:,:,::-1],metadata=balloon_metadata,scale=0.8)
v=v.draw_instance_predictions(outputs['instances'].to('cpu'))
plt.figure(figsize=(20,10))
plt.imshow(v.get_image()[::,::-1])
plt.show()


总结
detectron2是目前非常流行的一个目标检测的库,虽然当下有很多库都在宣称其效果已经超过了detectron,但是这不影响detectron的受欢迎程度。高强度的“炼丹”需要强大的“丹炉”,建议大家在训练数据集的时候最好使用配有独立显卡的计算机,如果条件不允许也可以使用Google的Colab或者百度的AI studio来完成你的训练和测试。
本篇参考:https://www.youtube.com/channel/UC_TZfmL1ob6M5yEL00NZu1A