传统的图片检索技术的发展-传统经典方法篇
传统的图片检索技术的发展
作者:manyi-guanyonglai
今天我们来介绍一下图片检索技术,图片检索就是拿一张待识别图片,去从海量的图片库中找到和待识别图片最相近的图片。这种操作在以前依靠图片名搜图的时代是难以想象的,直到出现了CBIR(Content-based image retrieval)技术,依靠图片的内容去搜图。比较常见的图搜平台有百度、谷歌、拍立淘等,有些图搜技术已经能达到非常不错的效果。接下来我们做个测试,给出一个柯基宝宝的图片,分别用三家搜索引擎进行搜索:

图1 原图

图2 百度搜索结果


图3 谷歌搜索结果
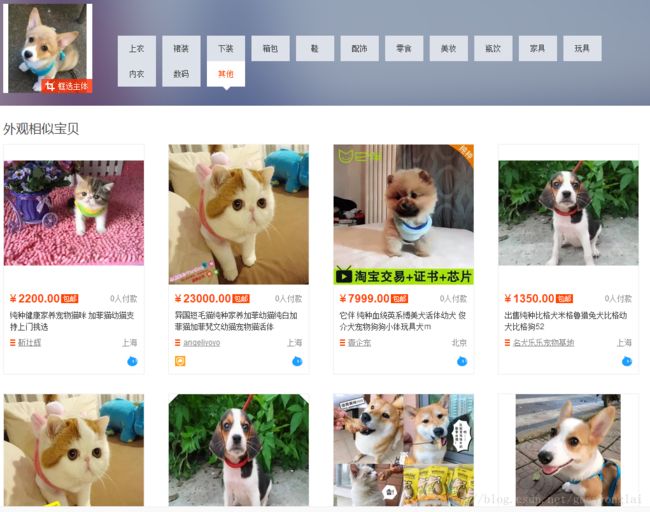
图4 拍立淘搜索结果
早期的图片检索技术都是基于文本的,需要按照图片的名称去搜索对应的图片,而这样有个很明显的缺陷就是:大量的图片需要人为事先去命名,这个工作量太大了。随后渐渐出现了基于内容的图片检索技术,较早出现的有哈希算法LSH(Locality-Sensitive Hashing),随后图搜这一块逐渐丰富,从BOF -> SPM -> ScSPm ->LLC 使传统的图搜技术逐渐成熟。下面我们就来巴拉一下传统图搜技术的前世今生。
一、LSH
LSH(Locality-Sensitive Hashing)[1]较为官方的理解为:将原始数据空间中的两个相邻数据点通过相同的映射后,这两个数据点在新的数据空间中仍然相邻的概率很大,而不相邻的数据点被映射到同一个桶的概率很小。也就是说,如果我们对原始数据进行一些hash映射后,我们希望原先相邻的两个数据能够被hash到相同的桶内,具有相同的桶号。因此,LSH算法使用的关键是针对某一种相似度计算方法,找到一个具有以上描述特性的hash函数,使得经过它们的哈希映射变换后,原始空间中相邻的数据落入相同的桶内,那么我们在该数据集合中进行近邻查找就变得容易,只需要将查询数据进行哈希映射得到其桶号,然后取出该桶号对应桶内的所有数据,再进行线性匹配即可查找到与查询数据相邻的数据。
上面的叙述太过理论化,那么hash算法具体怎么应用到图搜技术中呢?参照nash_同学我们列举了三种不同的hash算法:
(一)、平均哈希算法(aHash)
此算法是基于比较灰度图每个像素与平均值来实现的,最适用于缩略图搜索。
步骤:
1.缩放图片:为了保留结构去掉细节,去除大小、横纵比的差异,把图片统一缩放到8*8,共64个像素。
2.转化为灰度图:把缩放后的图片转化为256阶的灰度图
3.计算平均值: 计算进行灰度处理后图片的所有像素点的平均值
4.比较像素灰度值:遍历64个像素,如果大于平均值记录为1,否则为0.
5.得到信息指纹:组合64个bit位,顺序随意保持一致性即可。
6.对比指纹:计算两幅图片的汉明距离,汉明距离越大则说明图片越不一致,反之,汉明距离越小则说明图片越相似,当距离为0时,说明完全相同。(通常认为距离>10 就是两张完全不同的图片)
(二)、感知哈希算法(pHash)
平均哈希算法过于严格,不够精确,更适合搜索缩略图,为了获得更精确的结果可以选择感知哈希算法,它采用的是DCT(离散余弦变换)来降低频率的方法
步骤:
1.缩小图片:32 * 32是一个较好的大小,这样方便DCT计算
2.转化为灰度图:把缩放后的图片转化为256阶的灰度图
3.计算DCT:DCT把图片分离成分率的集合
4.缩小DCT:DCT是32*32,保留左上角的8*8,这些代表的图片的最低频率
5.计算平均值:计算缩小DCT后的所有像素点的平均值
6.进一步减小DCT:大于平均值记录为1,反之记录为0
7.得到信息指纹:同平均哈希算法
8.对比指纹:同平均哈希算法
(三)、差异哈希算法( dHash)
相比pHash,dHash的速度要快的多,相比aHash,dHash在效率几乎相同的情况下的效果要更好,它是基于渐变实现的。
步骤:
1.缩小图片:收缩到9*8的大小,共72个像素点
2.转化为灰度图:把缩放后的图片转化为256阶的灰度图
3.计算差异值:dHash算法工作在相邻像素之间,这样每行9个像素之间产生了8个不同的差异,一共8行,则产生了64个差异值
4.获得指纹:如果左边像素的灰度值比右边高,则记录为1,否则为0
5.对比指纹:同平均哈希算法
二、BOW-> BOF
BOW(Bag of Words) 模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些不同类别词汇的集合,而文本中的每个词汇都是独立的。简单说就是将每篇文档都看成一个袋子,这个袋子里面装的是各种类别的词汇,我们按照类别把整篇文档的词汇归为不同的类,比如这些词汇的类可以是枪、银行、船、人、桌子等,然后依据每个类别中词汇出现的频率来判断整篇文档所描述的大致内容。比如一篇文档中枪、银行这两类词汇出现的概率比较高,我们就可以判断这篇文档和武装押运有关,或者是关于土匪抢银行的,兄台们可自行发挥自己的脑洞。
类比到图像就是BOF(Bag of Features)了,以上所述的“袋子”就相当于是一副完整的图像,而“词汇”则相当于图像的局部特征(如SIFT、SURF),先用这些局部特征来训练出图像的聚类中心,训练聚类中心的过程即相当于按照类别把文档的词汇归为不同的类。在图片检索的时候,对图片的每一个局部特征用近邻查找法找到距离它最近的聚类中心,并把此聚类中心上局部特征的数目加一,依次遍历每一个局部特征后就把一副图片映射到一个聚类中心上,即图片的量化。最后以这些聚类中心为横坐标,以每个聚类中心的局部特征个数为纵坐标可以得到一个直方图,该直方图表示的向量就是一副图片映射到聚类中心的BOF向量。图片检索的时候只要依次比较图像的BOF向量即可找到最相似的图片。
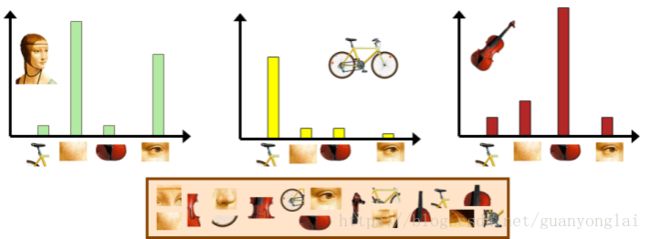
图5 基于单词包模型的图片特征示意图
三、指数权重VLAD
VLAD[2]相对于BOW的差别就是,BOW是把局部特征的个数累加到聚类中心上,而VLAD是把局部特征相对于聚类中心的偏差(有正负)累加到聚类中心上,而且是对最相邻的k个[3]聚类中心都进行累加(k一般设为4左右),这样能很大程度地提高特征量化的准确度,而且还能减少聚类中心的数目以提高量化速度。在累加每一个局部特征的偏差时,实际上累加的不是一个数,而是一个局部特征向量,比如用SIFT特征时累加的就是一个128维的向量,这样最终VLAD向量的维度就是128*聚类中心个数。如果聚类中心个数是256,最终的VLAD向量就是32768维。用这么大的向量去表征一副图片,显然会显得冗余,所以我们对直接累加的VLAD向量还要进行PCA降维,作者在使用VLAD向量的时候把它降到了512维,识别速率有了质的提升而识别率却基本维持不变。
因为PCA降维矩阵是按照特征值从大到小排列的,所以经过PCA降维处理后特征向量的前几个数据所占的比重会比较大,要远大于平均值,如图6所示。这样对特征的提取会造成较大干扰,因为若是前几个数据出现了差错,其引起的数据波动也往往比较大,在比较特征向量相似度时就容易产生较大误差,所以理想情况是使特征向量中前几个过大的数据按一定比例缩小,而使后面变化不大的数据尽量保持不变。
通过观察特征向量直方图可以发现它在二维坐标上的分布类似于指数函数,如图3a)所示为指数函数,所以考虑用图3b)所示的指数函数作为权重和特征向量的每一个数据相乘。

图6 PCA降维后的VLAD向量


a)指数函数 b)指数函数
图7 指数函数
但是在权重和数据相乘的时候还会有一个问题:当x取值很接近0的时候权重值g(x)也很接近0,当权重过小时会抹掉特征向量的前几个数据,这样会造成特征向量的部分数据无效,在度量特征向量相似度时反而会增大误差,所以在取离散g(x)值作权重的时候不能从0开始取值而应当有一个初始值。
将图6的特征向量和离散权重相乘可得到新的特征向量直方图,如图8所示,可见特征向量的前几个较大的数据被削减,而后续数据基本维持不变。

图8 指数权重VLAD
针对权重VLAD的提升效果,我们用6类图片做了识别率的对比:
表1 VLAD与权重VLAD的识别率对比
|
|
微软大楼 |
常青树 |
自行车 |
杯子 |
餐巾纸 |
吉他 |
| 原VLAD |
68.32% |
62.64% |
94.79% |
84.52% |
68.94% |
21.50% |
| 权重VLAD |
99% |
72.53% |
100% |
91.67% |
90.91% |
31.78% |
但是用VLAD向量做图片检索也存在很多缺点:首先,作为传统的图像识别方法,它需要手动提取特征,再加上Kmeans聚类时间长,会使得算法很繁琐;其次在向量量化的过程中会损失特征的精度,模板图片的设计也显得很粗糙,而且整个过程没有设计反馈系统,系统无法自动升级,迁移性很差。
四、FV
FV(Fisher Vector)是一种类似于BOW词袋模型的一种编码方式,如提取图像的SIFT特征,通过矢量量化(K-Means聚类),构建视觉词典(码本),FV采用混合高斯模型(GMM)构建码本,但是FV不只是存储视觉词典的在一幅图像中出现的频率,并且FV还统计视觉词典与局部特征的差异。可见FV和VLAD的差别就是FV用GMM构建码本,而VLAD用K-Means构建码本。
FV其实就是对于高斯分布的变量求偏导!也就是对权重、均值、标准差求偏导得到的结果,其本质上是用似然函数的梯度向量来表达一幅图像,这个梯度向量的物理意义就是数据拟合中对参数调优的过程,下面我们来说一下GMM。
事实上,GMM和K-means很像,不过GMM是学习出一些概率密度函数来(所以GMM除了用在clustering上之外,还经常被用于density estimation ),简单地说,K-means 的结果是每个数据点被分配到其中某一个 cluster 了,而 GMM 则给出这些数据点被分配到每个cluster的概率,从而也可以通过设置概率阈值把数据点分配到多个cluster,又称作 soft assignment 。
但是GMM有个缺点就是计算量很大,GMM 每一次迭代的计算量比 K-means 要大许多,所以有一个更流行的做法是先用 K-means (已经迭代并取最优值了)得到一个粗略的结果,然后将其cluster作为初值传入GMM函数,再用 GMM 进行细致迭代
五、SPM
由于BOW模型完全缺失了空间位置信息,会使特征的精度降低很多,而SPM[4]就在BOW的基础上加了一个空间位置信息,也相当于在BOW的基础上加了一个多尺度,盗用一下论文的图:
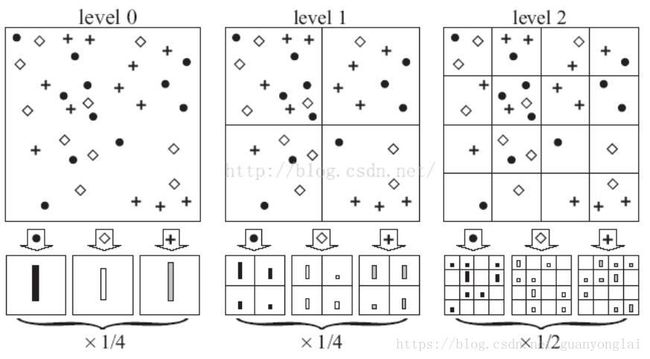
图9 SPM三个尺度示意图
上图中的点、菱形和十字架分别代表不同的局部特征。左边相当于原图,中间把原图分成了四小块,右边把原图分成了16小块,各图的小块大小是不一样的,所以能体现出多尺度信息,而各小块的位置体现出空间信息。然后对每一个小块单独进行聚类和量化,即相当于在多个尺度上进行BOW操作:
![]()
K是维度信息,比如单通道图像只有行和列两个维度,那么K就是2。L是尺度的个数,和代表点集中的点,当L=0时,上式就退化为BOW了。在识别的时候我们把L=0、1、2三个尺度的图片总共21个小块的特征串接起来,1+4+16=21。
关于图像的稀疏编码
对于二维数据,我们还可以用图像压缩来说明。类似于将图像的每个像素点当作一个数据,跑一下 K-means 聚类,假设将图像聚为k类,就会得到每类的质心centroids,共k个,然后用这些质心的像素值来代替对应的类里的所有点的像素值。这样就起到压缩的目的了,因为只需要编码k个像素值(和图像每个像素点的对这k个值得索引)就可以表示整张图像了。当然,这会存在失真,失真的程度跟k的大小有关。最偏激的就是原图像每个像素就是一个类,那就没有失真了,当然这也没有了压缩。
(一)、VQ(vector quantization)
首先我们来巴拉一下VQ,其实VQ就是上面提到的BOW特征量化,只不过VQ常常被用来稀疏SPM特征:

上式中,Xi表示第i个局部特征(如SIFT特征),B为聚类中心,Ci表示第i个局部特征特征所对应聚类中心的编码系数。Card (Ci)=1表示每个Xi只用一个B来表示,即Ci只有一个非零分量,其余分量全为零。虽然VQ方法得到的编码系数足够稀疏,但由于它把局部特征只量化到一个聚类中心上,没有考虑特征的多层语义信息,导致很大的编码误差。
(二)、SC(Sparse coding)
为了减少向量量化的信息损失,在基于SPM模型的稀疏编码中提出ScSPM,通过使用B的L2范数松弛约束条件,ScSPM[5-7]的目标函数为:

上式取消了中Ci >= 0的约束条件,因此每个特征可以用多个聚类中心进行表示。
(三)、LLC(locality-constrained linear coding)
在ScSPM之后是LLC[8],LLC对ScSPM的改进,在于引入了局部约束,其实也就是上文提到的VLAD向量,LLC是把特征量化到附近的多个聚类中心,所以才有局部约束这种提法。盗用一下Jinjun Wang 论文里的图直观说明VQ、ScSPM和LLC三者的区别:
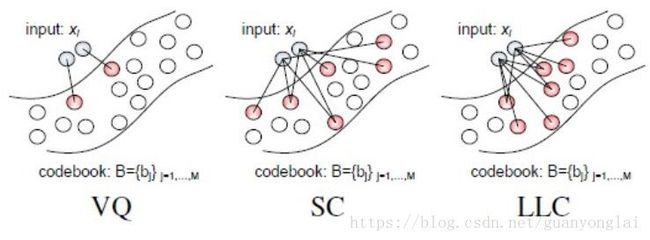
图10 VQ、SC、LLC对比
上述列举的只是传统的图片搜索方法,而目前主流的CBIR系统都是结合深度学习去做的,深度学习相对于传统方法是一个质的提升。
参考文献
[1]李大湘, 吴倩, 李娜. 融合LBP特征与LSH索引的鞋印图像检索[J]. 警察技术, 2016(3):47-49.
[2]Kim T E, Kim M H. Improving the search accuracy of the VLAD through weighted aggregation of local descriptors [J]. Journal of Visual Communication & Image Representation, 2015, 31(C):237-252.
[3]Kim M. Dual soft assignment clustering algorithm for human action video clustering[J]. Computer Vision & Image Understanding, 2017, 155:106-112.
[4]Yang J, Yu K, Gong Y, et al. Linear spatial pyramid matching using sparse coding for image classification[J]. 2009:1794-1801.
[5]Sch?lkopf B, Platt J, Hofmann T. Efficient sparse coding algorithms[J]. Proc of Nips, 2007, 19:801-808.
[6]王瑞霞. 基于稀疏编码的图像检索技术及其应用研究[D]. 西北工业大学, 2016.
[7]林中正. 图像稀疏表示方法及其在图像检索领域的应用研究[D]. 华东理工大学, 2013.
[8] Wang J, Yang J, Yu K, et al. Locality-constrained Linear Coding for image classification[C]// Computer Vision and Pattern Recognition. IEEE, 2010:3360-3367.