kaggle @房价预测 XGBoosts 机器学习

1.导入各种包
import tensorflow as tf
from tensorflow.keras import Sequential,layers
import keras
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm
from scipy import stats
import sys2.加载数据集,数据集可在kaggle平台下载。
##训练集
train_data=pd.read_csv('train.csv')
##测试集
test_data=pd.read_csv('test.csv')3.查看数据集内容和形状,训练集形状为(1460,81),测试集形状为(1459,80),测试集比训练集少了一列'SalePrice',也就是要预测的部分。
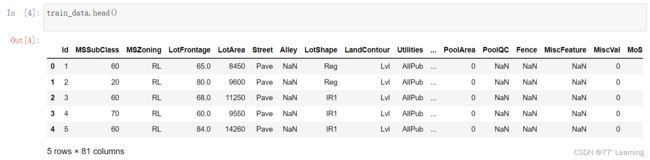

4.查看自变量和因变量的相关性
#查看自变量与因变量的相关性
fig = plt.figure(figsize=(14,8))
abs(train_data.corr()['SalePrice']).sort_values(ascending=False).plot.bar()
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)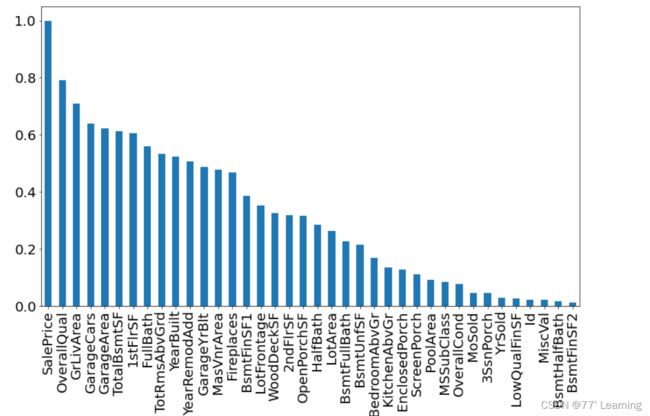
可以看到各种自变量与因变量相关性程度。'OverallQual'相关性最高。
5.对数据进行清洗,去掉一些异常值。这里只选择一部分自变量,实际操作中应该选择全部自变量,这里做了省略。
#异常值处理
figure=plt.figure()
sns.pairplot(x_vars=['OverallQual','GrLivArea','YearBuilt','TotalBsmtSF','1stFlrSF'],
y_vars=['SalePrice'],data=train_data,dropna=True)
plt.show()
可以看到,以上5张图片中有一些点是异常的。 比如'GrLivArea', 'TotalBsmtSF'最右边的点。需要对其进行删除。
#删除异常值
train_data = train_data.drop(train_data[(train_data['OverallQual']<5) &
(train_data['SalePrice']>200000)].index)
train_data = train_data.drop(train_data[(train_data['GrLivArea']>4000) &
(train_data['SalePrice']<300000)].index)
train_data = train_data.drop(train_data[(train_data['YearBuilt']<1900) &
(train_data['SalePrice']>400000)].index)
train_data = train_data.drop(train_data[(train_data['TotalBsmtSF']>6000) &
(train_data['SalePrice']<200000)].index)以下为删除异常值后的图像,这里做了省略。
6.开始构建训练集、测试集
#去掉Id和SalePrice,将训练集和测试集的79个特征按样本连接
all_features=pd.concat((train_data.iloc[:,1:-1],test_data.iloc[:,1:]))
#观察数据的缺失情况
nan_index=((all_features.isnull().sum()/len(all_features))).sort_values(ascending=False)#34个缺失值
nan_index
这里显示了数据集中数据缺失的程度,可以看到PoolQC数据缺失最严重。接下来处理这些缺失值。
#将列表中数值型的数据索引出来
numeric_features=all_features.dtypes[all_features.dtypes!='object'].index
#对数据进行标准化
all_features[numeric_features]=all_features[numeric_features].apply(
lambda x:(x-x.mean())/(x.std()))
#标准化后,每个数值特征的均值变为0,可以直接用0来替换缺失值
all_features[numeric_features]=all_features[numeric_features].fillna(0)将数据集中数值型的缺失数据填补为0
文字性数据转化为指示特征,比如特征MSZoning有两个不同的离散值RL和RM,那么这一步处理会去掉MSZoning特征,添加MSZoning_RL和MSZoning_RM两个新特征,其值为0或1。
#离散数值转成指示特征
#get_dummies是将拥有不同值的变量转换为0/1数值
#比如,特征MSZoning里面有两个不同的离散值RL和RM
#那么这一步将去掉MSZoning特征,并新加两个特征MSZoning_RL和MSZoning_RM,其值为0或者1.
#如果一个样本在原来MSZoning里的值为RL,那么MSZoning_RL=1且MSZoning_RM=0.
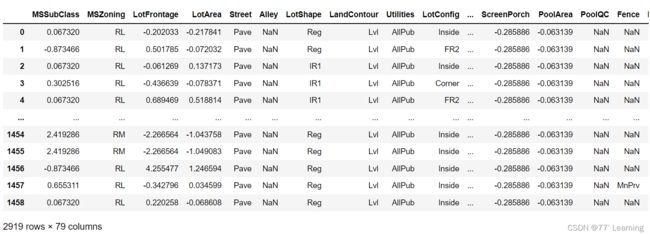
all_features=pd.get_dummies(all_features,dummy_na=True)#通过转换将特征数从79增加到了330
all_features 
可以看到特征已经变成330个。做一个对比,在前面,SaleType只有一列,变换后变成了多列数值型特征。左图为变换前,右图为变换后。


7.构建模型,划分训练集、测试集
from sklearn.model_selection import train_test_split
n_train=train_data.shape[0]
train_data1=all_features[:n_train]
test_data1=all_features[n_train:]
train_target=train_data['SalePrice']
x_train,x_test,y_train,y_test=train_test_split(train_data1,train_target,test_size=0.2)
test_data1.shape这里使用XGBoost进行训练.XGBoost原理可以参看xgboost入门与实战(原理篇)_我曾经被山河大海跨过的博客-CSDN博客_xgboost
xgboost 算法原理_大号小白兔的博客-CSDN博客_xgboost算法
from xgboost import XGBRegressor
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
scaler=scaler.fit(x_train)
x_train_scaled=scaler.transform(x_train)
x_test_scaled=scaler.transform(test_data1)
reg=XGBRegressor(n_estimators=1000,eta=0.05).fit(x_train_scaled,y_train)
print(reg.score(x_train_scaled,y_train))
pres=reg.predict(x_test_scaled)
train_target['SalePrice']=pres
a=pd.DataFrame()
a['Id']=range(1461,2920)
a['SalePrice']=pres
a.to_csv('predict.csv',index=False)
训练集准确率:

kaggle得分:

使用lightGBM:
#lightGBM
from lightgbm.sklearn import LGBMRegressor
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
scaler=scaler.fit(x_train)
x_train_scaled=scaler.transform(x_train)
x_test_scaled=scaler.transform(test_data1)
#定义lightGBM模型
clf=LGBMRegressor(n_estimators=1000,learning_rate=0.1)
#在训练集上训练
clf.fit(x_train_scaled,y_train)
clf.fit(x_train,y_train).score(x_train_scaled,y_train)训练集正确率:0.9999635 ,测试集正确率:0.865220
