猫狗识别与分类
猫狗识别与分类
文章目录
- 猫狗识别与分类
-
- 一、前言
- 二、环境配置
- 三、源码以及数据集
- 四、基础猫狗识别程序如下
-
- 1、train.py
-
- train.py程序结构:
- 2、detect.py
-
- detect.py程序结构:
- 五、配置环境过程
-
- 1、打开Anaconda Prompt
-
- a、创建一个叫MNIST4的环境
- b、创建成功后激活环境并下载keras包:
- c、下载matplotlib包
- d、下载tensorflow包
- e、下载SciPy包
- 2、打开Pycharm配置
- 六、运行基础程序
-
- 1、运行train程序
-
- a、将开头的程序copy进pycharm的程序中
- b、运行结果:
- 1、运行detect程序
-
- a、将开头的detect程序进pycharm的程序中
- b、运行结果
- 七、基于DenseNet神经网络构架的猫狗识别训练程序
-
- 1、在之前的基础上导入sklearn包
- 2、将程序copy到pycharm
-
- train.py程序结构
- 3、运行结果
一、前言
在实现猫狗识别的时候,我看到csdn上检索的猫狗识别有一些博客比较繁杂,可是作为正式进入AL世界的Hello world,这是不合理的,代码本来就不复杂。
繁杂的操作和图片有点让人生畏,所以我决定有必要重写一下程序、记录一下过程。
下面是一些国内的pip源,有需要可自取
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
二、环境配置
软件:ANACONDA3+Pycharm2019
keras>=2.7;
tensorflow>=2.7
注:一定关掉科学上网
三、源码以及数据集
链接:https://pan.baidu.com/s/1Q4kQ9el-uIiRCx7RS-FQmw
提取码:eorn
四、基础猫狗识别程序如下
1、train.py
基于卷积池化构架的猫狗识别训练程序
train.py程序结构:
- 第一步:导入包
- 第二步:指定一些超参数
- 第三步:准备训练集和验证集
- 第四步:建立神经网络模型
- 第五步:训练模型
- 第六步:根据训练过程中的信息绘制图表
#第一步:导入包
import numpy as np
import os,random,shutil
np.random.seed(7)
#第二步:指定一些超参数
FOLDER=".\\dataset_default"
train_data_dir=os.path.join(FOLDER,'train') #训练集路径
val_data_dir=os.path.join(FOLDER,'validate')#验证集路径
train_samples_num=4916 # 训练集的图片个数
val_samples_num=1439 #验证集的图片个数
IMG_W,IMG_H,IMG_CH=150,150,3 # 输入模型的图片大小
batch_size=32 #每一次输入神经网络图片个数
epochs=20 # 训练轮数
class_num=2 # 训练的类别,如果是多类别将这个修改,在按照猫狗数据集的形式,建立文件夹即可
#第三步:准备训练集,keras有很多Generator可以直接处理图片的加载,增强等操作,封装的非常好
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator( # 单张图片的处理方式,train时一般都会进行图片增强
rescale=1. / 255, # 图片像素值为0-255,此处都乘以1/255,调整到0-1之间
rotation_range=40, # 旋转范围
width_shift_range=0.2, # 水平平移范围
height_shift_range=0.2, # 垂直平移范围
shear_range=0.2, # 剪切变换的程度
zoom_range=0.2, # 剪切变换的程度
horizontal_flip=True, # 水平翻转
fill_mode='nearest'
)
train_generator = train_datagen.flow_from_directory(# 从文件夹中产生数据流
train_data_dir, # 训练集图片的文件夹
target_size=(IMG_W, IMG_H), #调整后每张图片的大小,这样是模型输入的大小
batch_size=batch_size, #每一次数据生成器生成图片数据
color_mode='rgb', #图片为RGB三通道
class_mode='categorical') # 此处是多分类问题,故而mode是categorical
#准备验证集
val_datagen = ImageDataGenerator(rescale=1. / 255) # 只需要和trainset同样的scale即可,不需增强
val_generator = val_datagen.flow_from_directory(
val_data_dir,
target_size=(IMG_W, IMG_H), #同训练集
batch_size=batch_size,
color_mode='rgb',
class_mode='categorical')
# 第四步:建立Keras模型:模型的建立主要包括模型的搭建,模型的配置
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
#建立神经网络模型的函数
def build_model(input_shape):
# 模型的搭建:此处构建三个CNN层+2个全连接层的结构
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=input_shape)) #第一个卷积层,参数从左到右分别为卷积核输出空间的维度,卷积核大小,输入大小
model.add(Activation("relu")) #激活函数
model.add(MaxPooling2D(pool_size=(2, 2))) #插入池化层 卷积池化1
model.add(Conv2D(32, (3, 3)))
model.add(Activation("relu")) #卷积池化2
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten()) #全连接层
model.add(Dense(64)) #64个神经元
model.add(Activation("relu")) #激活函数
model.add(Dropout(0.5)) # Dropout防止过拟合
model.add(Dense(class_num)) #神经元数为2,这里要和要识别的种类一致
model.add(Activation("softmax")) # 用softmax做激活函数输出猫狗两个类别的概率,
# 神经网络结构建好,之后执行模型的编译 ,必须有这步
from tensorflow import optimizers
model.compile(
loss="categorical_crossentropy", # 定义模型的loss func,optimizer,
optimizer='adam', # 使用默认的lr=0.001
metrics=["accuracy"],
) # 主要优化accuracy
return model # 返回构建好的模型
#利用刚刚写好的函数,生成一个神经网络模型
model=build_model(input_shape=(IMG_W,IMG_H,IMG_CH)) # 输入的图片维度
# 第五步:模型的训练
history_ft = model.fit(train_generator, #从训练集中获取数据流也就是图片,输入神经网络进行训练
steps_per_epoch=train_samples_num // batch_size, #每一轮训练的轮数
epochs=epochs, #每一轮训练的轮数
validation_data=val_generator, #从验证集中获取验证集,数据流也也就是图片输入神经网络进行训练
validation_steps=val_samples_num // batch_size #验证集轮数
)
# history_ft保存有训练过程的信息
model.save("./model.h5") #保存模型
print(history_ft.history.keys()) #输出模型训练过程中,关键参数名也就是accuracy,val_accuracy,loss,val_loss,下面画图需要这些参数
# 第六步:根据训练过程中的信息绘制图片
import matplotlib.pyplot as plt
acc = history_ft.history['accuracy'] #变量 acc=训练过程中的acc
val_acc = history_ft.history['val_accuracy']
loss = history_ft.history['loss']
val_loss = history_ft.history['val_loss']
#上面那些acc,val_acc,loss,val_loss变量,参数必须包含在history_ft.history.keys()中
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc') #点
plt.plot(epochs, val_acc, 'b', label='validate acc') #线
plt.title('Training and validation acc') #图的标题
plt.legend()
plt.show() #画这个图
plt.plot(epochs, loss, 'bo', label='Training loss') #点
plt.plot(epochs, val_loss, 'b', label='validate Loss') #线
plt.title('Training and validation loss')
plt.legend()
plt.show() #同上
2、detect.py
detect.py程序结构:
- 第一步:导入库以及定义一些参数
- 第二步:定义一个函数,从测试文件夹内读取任意一张图片
- 第三步:定义一个预测函数
- 第四步:载入模型并预测
# 第一步:导入库以及定义一些参数
import os, random
from matplotlib.pyplot import imshow
import numpy as np
import matplotlib.pyplot as plt
IMG_W,IMG_H,IMG_CH=150,150,3 #设置图片的大小,这个大小要和神经网络的第一层输入有关
# 第二步:定义一个函数,从测试文件夹内读取任意一张图片。
def read_random_image():
folder=r"./Imgs/" #修改成你的数据集地址
file_path = folder + random.choice(os.listdir(folder)) #随机获取文件内图片的地址
pil_im = Image.open(file_path, 'r') #打开这个图片
return pil_im #返回
# 第三步:定义一个预测函数
# 用训练好的模型来预测新样本
from PIL import Image
from keras.preprocessing import image
def predict(model, img, target_size):
name = ["猫", "狗"]
if img.size != target_size: #如果图片的大小不是目标大小则修改
img = img.resize(target_size)
x = image.img_to_array(img) #将图片转换成二维数组准备输入模型
x *= 1. / 255 #归一化,矩阵*1/255.0,相当于将像素值转换到0~1
x = np.expand_dims(x, axis=0) #调整图片维度为零
preds = model.predict(x) #执行模型自带的预测函数,参数为x
imshow(np.asarray(img)) #输出图片,提高可视度
print(preds) #打印预测结果
for i in range(2):
if preds[0][i]>0.5: #打印超过0.5概率的类别名字
print(name[i])
break
#第四步:载入模型并预测
# 载入训练保存的模型
from keras.models import load_model
model_path = './model.h5' #模型地址
model = load_model(model_path)
print("下面将抽五张图并预测如下:")
for i in range(5):
print("该图片的猫狗概率如下:")
predict(model,read_random_image(),(IMG_W,IMG_H)) #预测函数
plt.show()
# 评估函数下面运行后可以评估模型的平均准确率,损失函数
'''
test_datagen = ImageDataGenerator(rescale=1. / 255) # 只需要和trainset同样的scale即可,不需增强
test_data_dir="./data_oppo/train"
val_generator = test_datagen.flow_from_directory(
test_data_dir,
target_size=(IMG_W, IMG_H),
batch_size=32,
color_mode='rgb',
class_mode='categorical')
test_loss,test_acc=model.evaluate(val_generator)
print("test_acc={} test_loss={}".format(test_acc,test_loss))
'''
以下是跑通这个程序的过程。如果清楚这些步骤的过程可以略过下面
五、配置环境过程
1、打开Anaconda Prompt
a、创建一个叫MNIST4的环境
conda create -n MNIST4 python=3.8
注:记得python=3.8,大了就下载不了tensorflow包了
注:名字不重要,你之后想起什么名字都可以
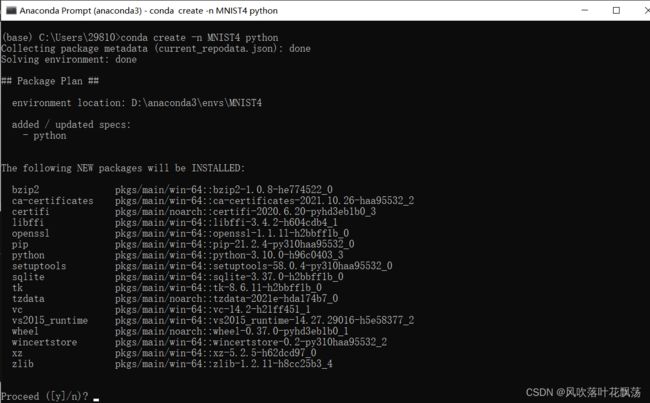
b、创建成功后激活环境并下载keras包:
conda activate MNIST4
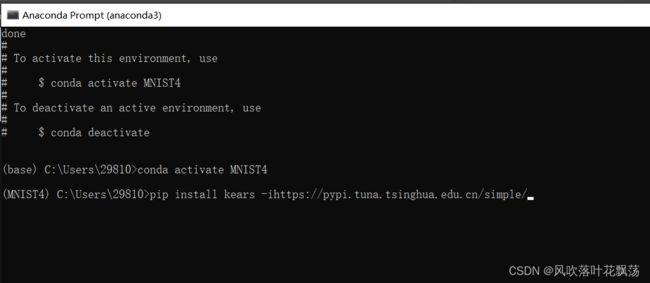
为了提高下载速度,在国内清华源中下载keras包
pip install keras -i https://pypi.tuna.tsinghua.edu.cn/simple/

c、下载matplotlib包
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple/
d、下载tensorflow包
pip install tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple/
e、下载SciPy包
pip install SciPy -i https://pypi.tuna.tsinghua.edu.cn/simple/
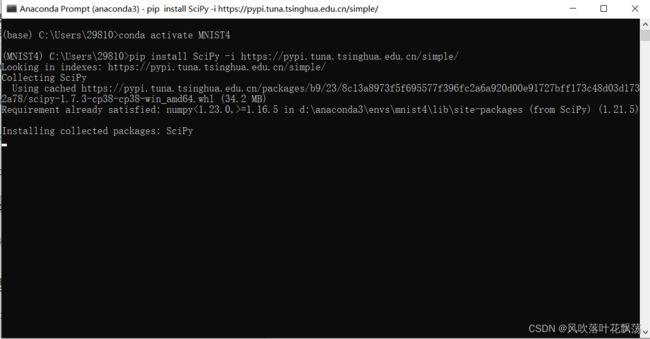
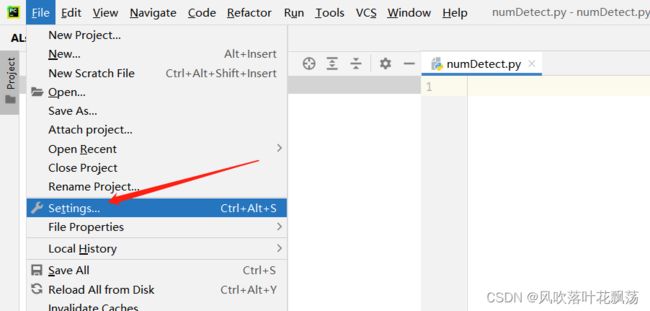
2、打开Pycharm配置
配置代码运行环境
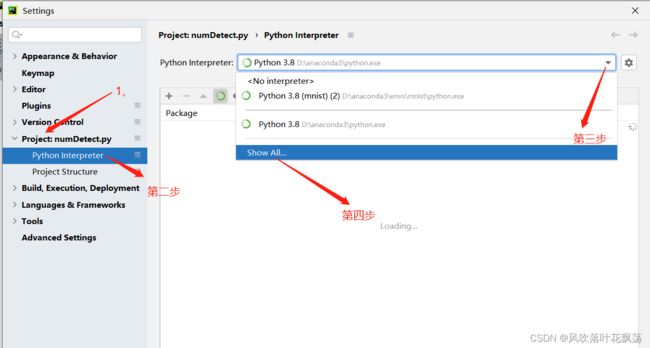
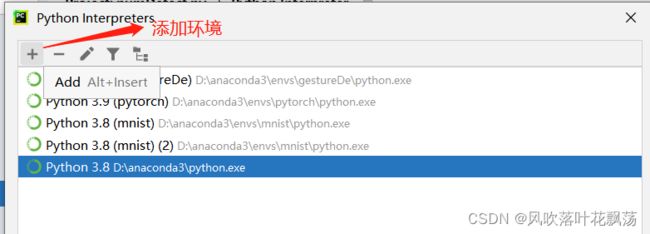
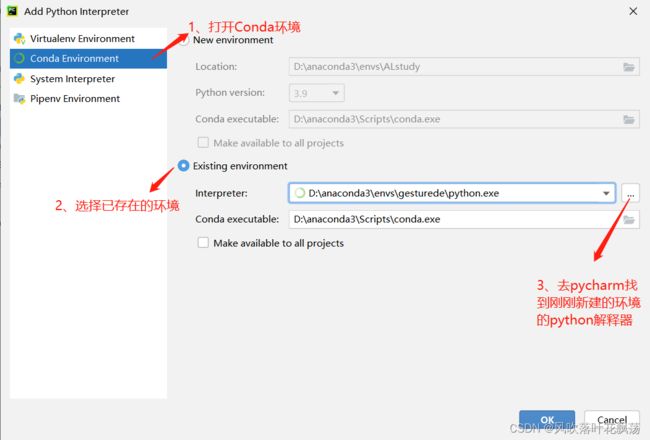
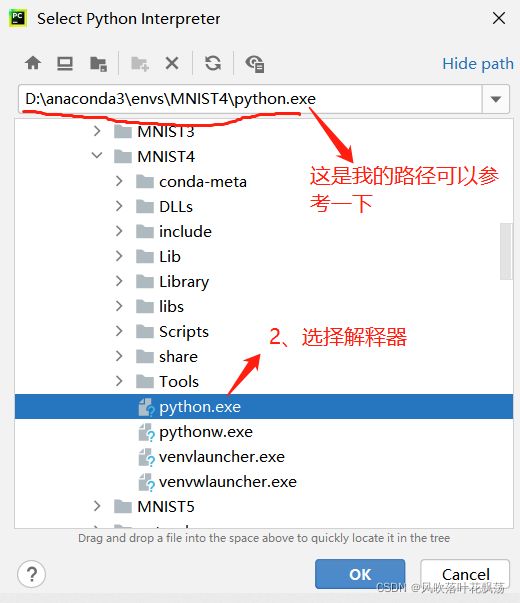
注:这里刷新出来的时候比较长,需要等等
之后一路点击确认下去
六、运行基础程序
这个程序是最基础的程序,有训练模型,部署模型的能力,数据集6000简单训练20轮,验证集精度大概有0.7的精度,
当然这只是用来玩的基础版本,一定要理解,之后的VGG–>Res–>DenseNet–>EffectionNet
也都只是时间问题了。
1、运行train程序
a、将开头的程序copy进pycharm的程序中
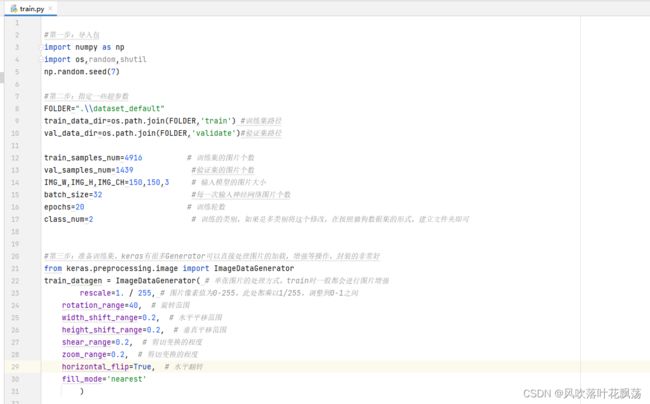
b、运行结果:
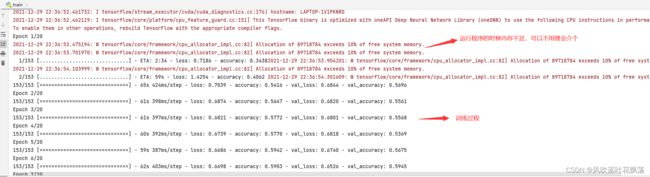
这样就训练成功了。
训练数据画图如下:
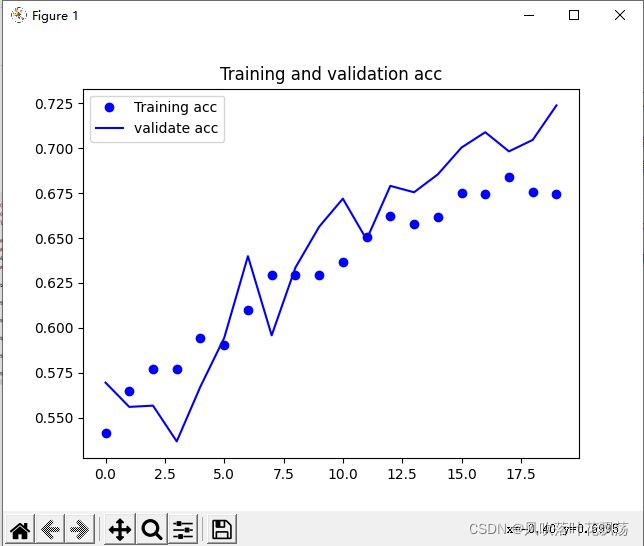
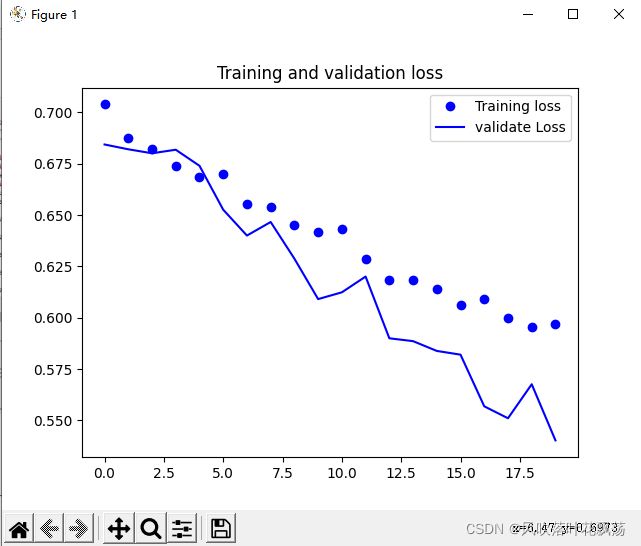
1、运行detect程序
a、将开头的detect程序进pycharm的程序中
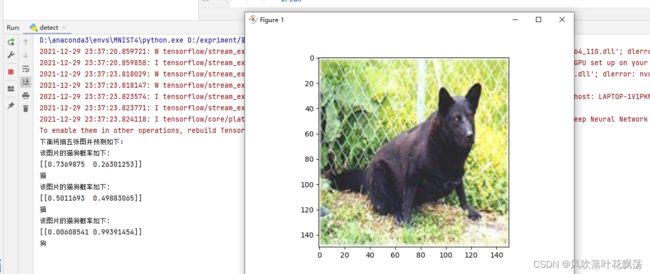
b、运行结果
七、基于DenseNet神经网络构架的猫狗识别训练程序
DenseNet神经网络架构是2017年比较活的架构
到2020年虽然干不过谷歌的EffectionNet不过在很多方面已经很优秀了
所以特意举这个例子
数据集:6000
验证集精度大概在0.97左右。
1、在之前的基础上导入sklearn包
pip install sklearn -i https://pypi.tuna.tsinghua.edu.cn/simple/
2、将程序copy到pycharm
train.py程序结构
- 第一步:导入相应的库和指定超参数
- 第二步:学习率修改函数
- 第三步:准备训练集
- 第四步:建立Keras模型:模型的建立主要包括模型的搭建,模型的编译
- 第五步:回调函数
- 第六步:模型的训练
- 第七步:绘制训练过程图像
from idlelib import history
#第一步:导入相应的库和指定超参数
from tensorflow.keras.callbacks import ReduceLROnPlateau,ModelCheckpoint
import tensorflow as tf
import os
#1指定超参数:
FOLDER=".\\dataset_default"#数据集前缀
train_data_dir=os.path.join(FOLDER,'train') #训练数据集的地址,里面应该有cats,dogs二个文件夹
val_data_dir=os.path.join(FOLDER,'validate') #验证数据集的地址,里面应该有cats,dogs二个文件夹
train_samples_num=4916 # train set中全部照片数
val_samples_num=1439 # validata set中全部照片数
IMG_W,IMG_H,IMG_CH=150,150,3 # 单张图片的大小
batch_size=32 #每次压入内存的图片个数
epochs=10 # 训练次数
class_num=2 # 此处有3个类别
# 创建保存模型的文件夹
if not os.path.exists("save_weights"):
os.makedirs("save_weights")
# 第二步:学习率修改函数,在model编译过程将调用
def lr_schedule(epoch):
"""Learning Rate Schedule
Learning rate is scheduled to be reduced after 80, 120, 160, 180 epochs.
Called automatically every epoch as part of callbacks during training.
# Arguments
epoch (int): The number of epochs
# Returns
lr (float32): learning rate
"""
lr = 1e-4
if epoch > 40:
lr *= 0.5e-3
elif epoch > 30:
lr *= 0.5
elif epoch > 20:
lr *= 0.5
elif epoch > 10:
lr *= 0.5
print('Learning rate: ', lr)
return lr
# 第三步:准备训练集,keras有很多Generator可以直接处理图片的加载,增强等操作,封装的非常好
from keras.preprocessing.image import ImageDataGenerator
'''
在深度学习中,一般要求样本的数量要充足,样本数量越多,训练出来的模型效果越好,模型的泛化能力越强。但是实际中,样本数量不足或者样本质量不够好,这就要对样本做数据增强,来提高样本质量。
关于数据增强的作用总结如下:
1,增加训练的数据量,提高模型的泛化能力
2,增加噪声数据,提升模型的鲁棒性
讲解数据增强的文章:#https://zhuanlan.zhihu.com/p/41679153
'''
train_datagen = ImageDataGenerator(rescale=1.0 / 255,
rotation_range=40, # 旋转范围
width_shift_range=0.2, # 水平平移范围
height_shift_range=0.2, # 垂直平移范围
shear_range=0.2, # 剪切变换的程度
zoom_range=0.2, # 剪切变换的程度
horizontal_flip=True, # 水平翻转
fill_mode='nearest')
'''
ImageDataGenerator类的简单介绍
(1)图片生成器,负责生成一个批次一个批次的图片,以生成器的形式给模型训练;
(2)对每一个批次的训练图片,适时地进行数据增强处理(data augmentation);
'''
train_generator = train_datagen.flow_from_directory( # 从文件夹中产生数据流
train_data_dir, # 训练集图片的文件夹
target_size=(IMG_W, IMG_H), # 调整后每张图片的大小
batch_size=batch_size, #每轮输入的图片个数
shuffle=True, #打乱标签
color_mode='rgb', #输入rgb
class_mode='categorical') #此处是多分类问题,故而mode是categorical
# 同样的方式准备测试集
val_datagen = ImageDataGenerator(rescale=1.0 / 255)
# 只需要和trainset同样的scale即可,无需增强# 只需要和trainset同样的scale即可,不需增强
val_generator = val_datagen.flow_from_directory(
val_data_dir,
target_size=(IMG_W, IMG_H),
batch_size=batch_size,
shuffle=False, #不打乱标签
color_mode='rgb',
class_mode='categorical')
# 第四步:建立Keras模型:模型的建立主要包括模型的搭建,模型的配置
from keras.models import Sequential
from keras.initializers import TruncatedNormal
#上一行TruncatedNormal可能会报错,这是由于版本的原因,忽视即可
def build_model(input_shape):
# unit1
covn_base = tf.keras.applications.DenseNet121(weights='imagenet', include_top=False, input_shape=(150, 150, 3))
covn_base.trainable = True
# 冻结前面的层,训练最后5层
for layers in covn_base.layers[:-5]:
layers.trainable = False
# 构建模型
model = tf.keras.Sequential()
model.add(covn_base)
model.add(tf.keras.layers.GlobalAveragePooling2D()) # 加入全局平均池化层
model.add(tf.keras.layers.Dense(512, activation='relu')) # 添加全连接层
model.add(tf.keras.layers.Dropout(rate=0.5)) # 添加Dropout层,防止过拟合
model.add(tf.keras.layers.Dense(2, activation='softmax')) # 添加输出层(2分类)
model.summary() # 打印每层参数信息
# 编译模型
model.compile(optimizer=tf.optimizers.RMSprop(lr_schedule(0)), # 使用adam优化器,学习率为0.0001
loss='binary_crossentropy', # 交叉熵损失函数
metrics=["accuracy"]) # 评价函数
return model
#利用构建后的函数构建模型
model=build_model(input_shape=(IMG_W,IMG_H,IMG_CH)) # 输入的图片维度并获取模型
# 第五步:回调函数
#回调函数1:学习率衰减
reduce_lr = ReduceLROnPlateau(
monitor='val_loss', #需要监视的值
factor=0.1, #学习率衰减为原来的1/10
patience=2, #当patience个epoch过去而模型性能不提升时,学习率减少的动作会被触发
mode='auto', #当监测值为val_acc时,模式应为max,当监测值为val_loss时,模式应为min,在auto模式下,评价准则由被监测值的名字自动推断
verbose=1 #如果为True,则为每次更新输出一条消息,默认值:False
)
#回调函数2:保存最优模型
checkpoint = ModelCheckpoint(
filepath='./save_weights/myDenseNet121.h5', #保存模型的路径
monitor='val_accuracy', #需要监视的值
save_weights_only=False, #若设置为True,则只保存模型权重,否则将保存整个模型(包括模型结构,配置信息等)
save_best_only=True, #当设置为True时,监测值有改进时才会保存当前的模型
mode='auto', #当监测值为val_acc时,模式应为max,当监测值为val_loss时,模式应为min,在auto模式下,评价准则由被监测值的名字自动推断
period=1 #CheckPoint之间的间隔的epoch数
)
# 第六步:模型的训练
history_ft = model.fit(train_generator, # 数据流
steps_per_epoch=train_samples_num // batch_size,
epochs=epochs,
validation_data=val_generator, #验证集数据流
validation_steps=val_samples_num // batch_size,
callbacks=[checkpoint, reduce_lr] #回调函数
)
model.save("./model2.h5") #保存程序为./model2.h5
print(history_ft.history.keys()) # 打印history_ft有哪些参数
#第七步:绘制训练过程图像
import matplotlib.pyplot as plt
acc = history_ft.history['accuracy']
val_acc = history_ft.history['val_accuracy']
loss = history_ft.history['loss']
val_loss = history_ft.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc') #点
plt.plot(epochs, val_acc, 'b', label='validate acc') #线
plt.title('Training and validation acc')
plt.legend()
plt.show()
plt.plot(epochs, loss, 'bo', label='Training loss') #点
plt.plot(epochs, val_loss, 'b', label='validate Loss') #线
plt.title('Training and validation loss')
plt.legend()
plt.show()
3、运行结果
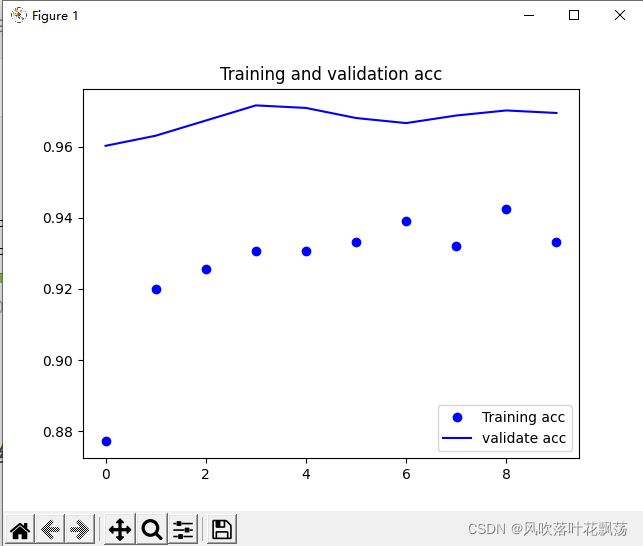
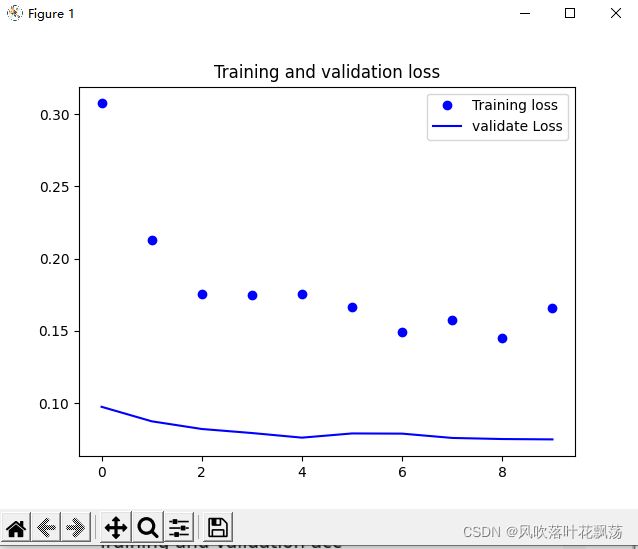
可以看到算比较理想,验证集精度0.97。毕竟数据集那么小,才6000张图片。
kaggle正式比赛时候训练的模型数据集可是25000张图片
至于为什么验证集精度比训练集精度高可以看这篇博客:https://blog.csdn.net/qq_51116518/article/details/122227731