第一个大规模中文视频多模态相似度数据集
前言
现如今短视频的消费爆发式增长,比如大家熟知的相关的平台有抖音、快手、B站、爱奇艺、腾讯视频等等。作为技术人员来看的话其中视频的语义理解是至关重要的,比如在推荐场景的视频去重、相似度召回、排序和多样性打散等场景都有重要的作用。笔者之前也介绍过相关的多模态算法综述,感兴趣的小伙伴可以看看:
多模态预训练模型综述 - 知乎
今天给大家介绍一份相关的中文数据集,其不仅仅是第一份中文的视频多模态相似性数据集,而且规模之大,提供了很多metadata信息包括标题、ASR、tag、类别等等如下,相信可以满足大家的各类需求。其是腾讯qq浏览器团队贡献的Tencent-MVSE数据集,已发表了paper提供了baaseline并且举行了相关的比赛。
论文地址:
https://openaccess.thecvf.com/content/CVPR2022/papers/Zeng_Tencent-MVSE_A_Large-Scale_Benchmark_Dataset_for_Multi-Modal_Video_Similarity_Evaluation_CVPR_2022_paper.pdfopenaccess.thecvf.com/content/CVPR2022/papers/Zeng_Tencent-MVSE_A_Large-Scale_Benchmark_Dataset_for_Multi-Modal_Video_Similarity_Evaluation_CVPR_2022_paper.pdf
比赛地址:
QQ浏览器2021AI算法大赛
Introduction
视频的相似度其实是多维的,如下:

对于第一个例子(第一行)来说,它们显然是相似的,都是在踢足球,视频本身画面就很相似;对于第二个例子,画面虽然不是很相似,但是文本是相似的,都是德云社;对于第三个例子画面和文本都不相似,但是都其实在说吃鸡这个游戏。可以看到事实上相似性是多模态的,在考虑视频是否相似的时候,应该综合考虑多个模态,这也是Tencent-MVSE提出的目的。
Tencent-MVSE Dataset
整个数据集包括pointwise和pairwise两部分,前者是为了大家更好的进行无监督的预训练,后者就是有标注的相似性数据集。
(1)Data Collection
数据的收集是来源于腾讯看点(看点-年轻人都在用的精品社区),看点上每天有数十万PGC(专业生产的)的短视频,作者只收集PGC视频,因为它们的质量要好一点,具体的是先抓取100万视频,然后选取其中时长小于60s的短视频组成pointwise数据集,然后再抓取200万视频作为pairwise的原始数据。
每一个视频都提供了丰富的信息,包括中文标题、ASR 文本(视频语音转化成文本)、视频frame 特征、人工标注的tag以及视频所属的category(垂类)。其中标题是视频作者自己起的,ASR 文本是使用腾讯云ASR API(语音识别 简介-API 中心-腾讯云)得到的,由于版权,视频最后只提供视频的id。
(2)Data Annotation
标注这里首先说tag和category,这里首先是建立了categories和tags词典,然后使用知识图谱以及最后经过人确认得到的,最终得到328种categories和64903种tags,每一个视频一个category以及一个或多个tags。一些case如下:

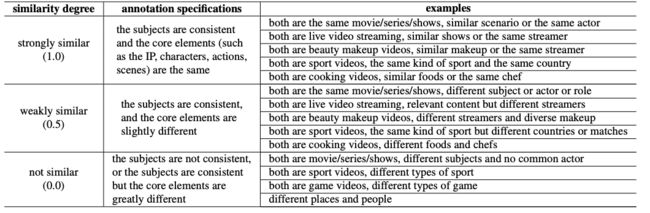
相似度的score标注其实对于标注人员是非常难把握的,尤其是多模态是多维度的,于是为了减轻标注人员的负担,这里采取了设置问题的方式来进行如下,最后相似被分成三个等级即强相似、弱相似和不相似,对应的量化分别是1、0.5和0。对于每一个视频是取所有标注人员的结果平均值作为最终标注结果。在现实中,由于大部分视频是不相似的,所以直接随机生成后续标注的话最后可能会导致了长尾问题,为了使得最终的类别尽可能的均衡,作者这里是训练了三个模型去生产pair后续给标注人员标注(其实目的就是为了去掉大部分无效的标注即不相似)。
具体就是这三个模型都是用tag作为监督信号训练的,只不过输入是不一样的,分别是:video、title以及video+title。然后随机在200万里面抽取视频作为query用上面三个模型去检索,作者这里观察了下召回的top50、50-100和100-200里面,其中100-200里面很少有相似的(往后的那就更小相似了,验证了长尾问题),然后每个视频根据上述三个top段就可以检索出9个视频(每个模型三个,一共三个模型),然后给标注人员标注,最后一共得到135705个pair视频,具体的标注是采用的十折进行的,对于标注方差过大的会认为是不准的过滤点(方差大于0.25过滤,比如5个标注是1,5个标注是0.5)
(3)Data Statistic
作者将标注的数据分成pairwise、test-dev和test-std三份,其中pairwise包含63613个视频和67854对视频,用以train;test-dev包含31514个视频和27161对视频,用以validation;test-std包含43027个视频和40726对视频,用以evaluation;其中test-dev和test-std相同的视频有10581个;而pairwise的视频都没有在test数据集出现过。
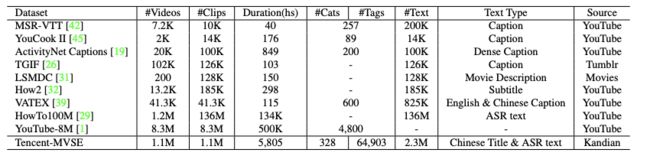
下表显示了categories、score和时长的分布,一共提供了328个categories和64903个tags,而这328个categories又其实是从29个超级大类里面细化出来的,这里同时提供了一些和其他数据集的对比

(4)Data Pre-processing
对于视频帧的预处理,首先是使用1 FPS进行抽帧,至于提取特征这里使用了三种模型:ResNet-50、EfficientNet-B3和CLIP,其抽取特征的能力是逐渐增加的。
Baselines
数据集就介绍的差不多啦,作者最后还给出了自己的baseline,框架(MMT:multi-modality Transformer)如下:
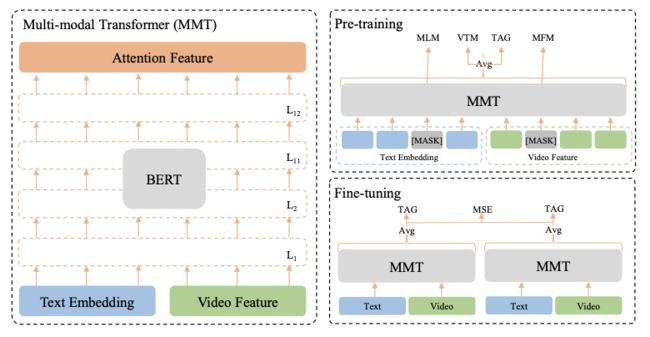
(1)Model Architecture
模型框架很简单,这里就是把文本的embedding和视频的embedding(用一层MLP将其转化为和文本embedding维度相同)进行拼接,然后送到多层transformer即可。
(2)Pre-training
作者这里利用pointwise数据进行预训练,设计了三种预训练任务分别是MLM(language modeling)、VTM(video text matching)、MFM(masked frame modeling)和TAG(Tag Classification)。
其中MLM大家都很熟悉,就是沿用bert的策略;VTM就是视频文本匹配任务,具体的是对于一个视频其本身对应的文本作为positive样本,然后随机抽取其他视频的文本作为negative样本(具体的是在同一个batch内进行的),最后进行二分类;对于MFM就是随机MASK一帧视频然后使用NCE Loss(自己本身原始特征作为正样本,其他帧的原始特征作为负样本)进行监督训练;至于TAG就是对tag和category分类。
Experiments
这里贴几个比较重要的实验结果
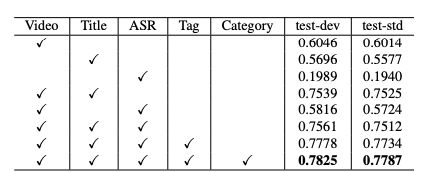
可以看到各个模态都是有用的,不过其中ASR的作用比较少,video和Title是比较重要的模态维度。
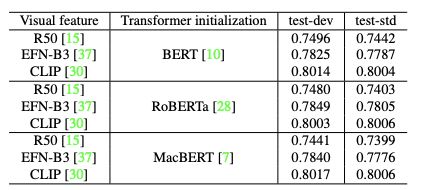
这里的backbone有bert、Roberta、macbert,但是其实差别没那么大,但是video特征提取的模型这里CLIP是最强的。
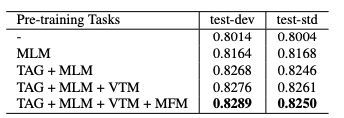
四个预训练任务的消融实验,可以看出都是有一些作用的。
其他更详细的细节如果大家感兴趣可以去看原paper~
总结
(1)这一份数据集还是挺宝贵的,相信可以为从事多模态的研究者带来一定的帮助
(2)算法这里其实设计的空间还挺大的,毕竟模态比较多,这里大家也可以看看文章开头给的其对应的比赛,应该是已经结束了,大家可以找找冠亚军等的实现方法
关注
欢迎关注,下期再见啦~
欢迎关注笔者微信公众号:

github:
Mryangkaitong · GitHubhttps://github.com/Mryangkaitong
知乎:
小小梦想 - 知乎