python数据分析及可视化
某大型超市的年销售数据信息如下所示:
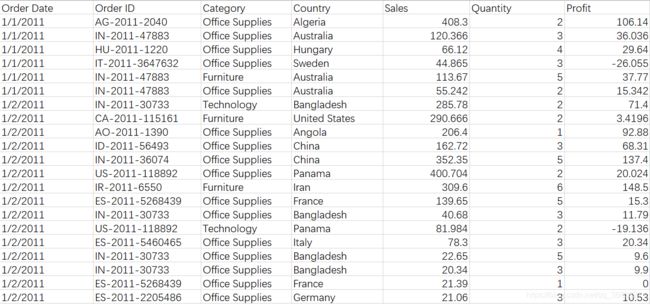
从左往右的相应字段分别为:订单日期、订单编号、商品门类、采购地区、销售额、数量以及利润。
首先导入所需要的库,并读取表格:
import pandas as pd
from pyecharts import Map
import matplotlib.pyplot as plt
df = pd.read_csv("superstore_dataset.csv")
之后查看字段对应的数据类型:
df.dtypes
--------------------------
Order Date object
Order ID object
Category object
Country object
Sales float64
Quantity int64
Profit float64
我们发现Order Date订单日期是object类型,所以需要将其转化为datetime类型,并且变量的命名不符合python的命名规则,需要将两个字符串之间的空格替换成下划线:
df["Order Date"] = pd.to_datetime(df["Order Date"])
df.rename(columns=lambda x: x.replace(' ', '_'), inplace=True)
查看数据有无缺失值,对含有缺失值的记录进行计数:
df.isnull().sum()
-------------------------
Order_Date 0
Order_ID 0
Category 0
Country 0
Sales 0
Quantity 0
Profit 0
month 0
显然,各个字段均无缺失值。
1.采购地区数据视图:
通过构建字典对采购国家和该国家在一年中的订单数额进行统计:
country_dict = {}
for country in df["Country"]:
if country not in country_dict.keys():
country_dict[country] = 0
country_dict[country] += 1
利用pyecharts中的Map,可视化全球订单所在的国家:
country = list(country_dict.keys())
order_quantity = list(country_dict.values())
map = Map("全球订单所在国家", width=1200, height=500)
map.add("订单数额", country, order_quantity, visual_range=[1, 900], maptype="world", is_visualmap=True,\
visual_text_color='#333', is_map_symbol_show=True)
map.show_config()
map.render(path="全球订单地图.html")
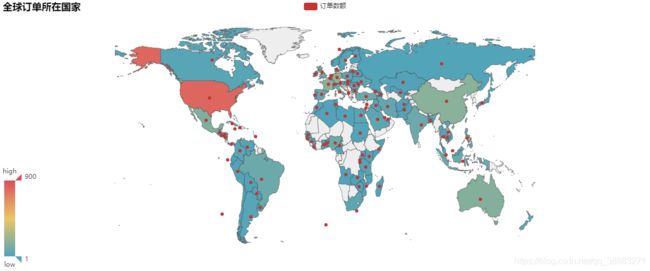
从上图中我们发现,美国是该超市商品的最大采购国家,其次是中国和澳大利亚以及欧洲绝大部分国家。
2.统计2011年该超市每月的销售总额、销量和利润:
先从"Order_Date"中拆分出月份,并且单独作为一列,字段名"month":
df["month"] = df["Order_Date"].values.astype('datetime64[M]')
再将现在的df按照月份进行分组,每一组中都是相同月份的订单日期、销售额、销量、利润和月份,再将每一组中的销售额、销量和利润求和,得到每个月的总销售额、总销量和总利润。
sales_data = df[["Order_Date", "Sales", "Quantity", "Profit", "month"]]
sales_month = sales_data.groupby(["month"]).sum()
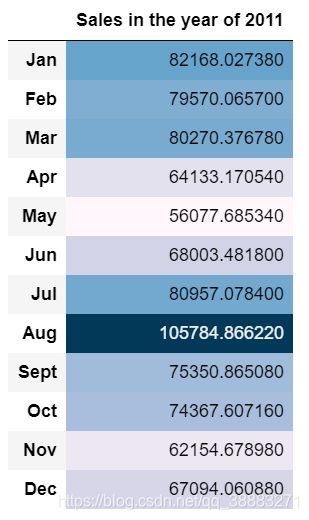
month_2011 = sales_month.loc[slice(None), :].reset_index()
sales = month_2011["Sales"]
sales = pd.DataFrame(sales)
sales.columns = ["Sales in the year of 2011"]
sales.index = ["Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sept", "Oct", "Nov", "Dec"]
sales.style.background_gradient()
reset_index()是将DataFrame结构的数据重新还原索引,包括每列的字段和每行的字段。
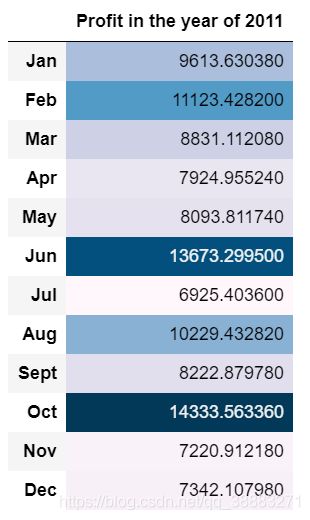
profit = month_2011["Profit"]
profit = pd.DataFrame(profit)
profit.columns = ["Profit in the year of 2011"]
profit.index = ["Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sept", "Oct", "Nov", "Dec"]
profit.style.background_gradient()
quantity = month_2011["Quantity"]
quantity = pd.DataFrame(quantity)
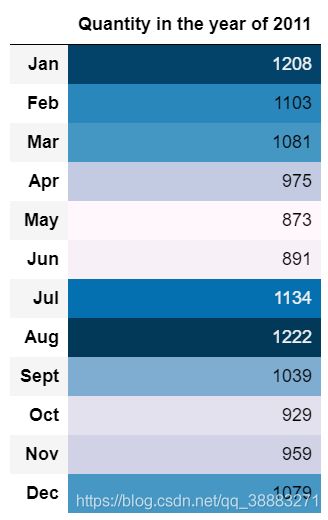
quantity.columns = ["Quantity in the year of 2011"]
quantity.index = ["Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sept", "Oct", "Nov", "Dec"]
quantity.style.background_gradient()
3.产品门类统计:
对产品门类Category进行统计,发现产品门类只有三个,即office supplies(办公用品),furniture(家居用品),technology(技术性机器设备)
order_category = {}
for c in df["Category"]:
if c not in order_category.keys():
order_category[c] = 0
order_category[c] += 1
category = list(order_category.keys())
category_quantity = list(order_category.values())
plt.bar(range(len(category)), category_quantity, width=0.08, tick_label=category, color='lightseagreen')
plt.show()
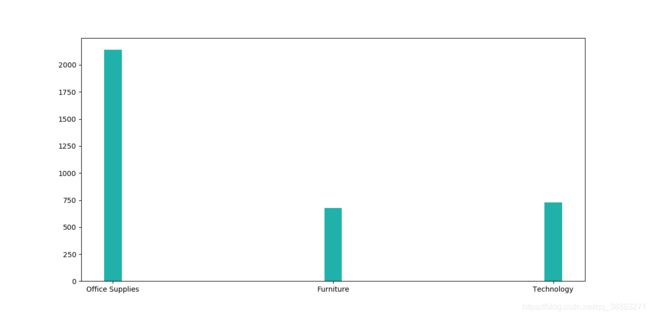
通过图表发现办公用品需求量最大,家居用品和机器设备基本持平.
我们可以统计出办公用品全球采购的国家,并进行可视化:
country_dict = {}
for country, category in zip(df["Country"], df["Category"]):
if category == "Office Supplies":
if country not in country_dict.keys():
country_dict[country] = 0
country_dict[country] += 1
else:
pass
country = list(country_dict.keys())
order_quantity = list(country_dict.values())
map = Map("全球办公用品采购国家", width=1200, height=500)
map.add("采购数额", country, order_quantity, visual_range=[1, 500], maptype="world", is_visualmap=True,\
visual_text_color='#333', is_map_symbol_show=True)
map.show_config()
map.render(path="全球办公用品采购地图.html")
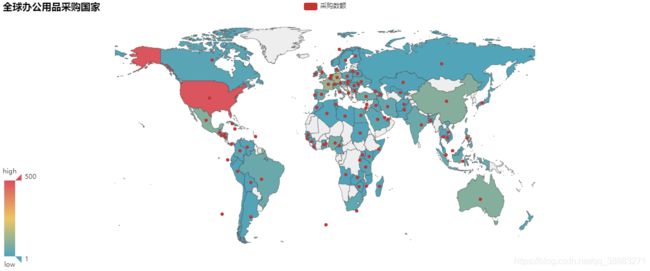
从图中可以看出办公用品采购国家大多来自美国,其次是中国,澳大利亚,墨西哥以及欧洲国家.