Python分类模型实战(KNN、逻辑回归、决策树、SVM)调优调参,评估模型——综合项目
目录
一、技术原理
逻辑回归
k近邻法(k-nearest neighbor,k-NN)
决策树
SVM(Support Vector Machine)
模型评估
二、数据探索与处理
2.1读取贷款违约数据集,在系统中可视化展示部分数据集
2.2对违约情况进行饼图可视化,查看其占比情况
2.3对数据中的年龄情况进行可视化分析
2.4对数据中的工龄情况进行可视化分析
2.5对收入可视化分析
2.6对各负债情况进行可视化查看
2.7根据皮尔森系数,得到与违约相关性较高的特征如下表所示
2.8进一步探查负债率、信用卡负债、工龄这3类与违约的关系
2.8.1负债率与违约关系
2.8.2信用卡负债与违约关系
2.8.3工龄与违约关系
三、模型构建
①选取负债率,信用卡负债为X
②x选取负债率、工龄(与上同理)
③x选信用卡负债、工龄(与上同理)
四、模型的基本训练
4.1决策树、SVM、逻辑回归、KNN模型的基本训练,并展示模型函数;
4.2测试集中基本模型的评估,并展示评估结果;
4.3模型的调优调参,寻找最优模型,并列表对比参数的变化过程及对应结果;
①决策树的调优调参
②SVM支持向量机的调优调参
③逻辑回归的调优调参
通过自动化调优调参得到最优参数如下:
④KNN的调优调参
五、实验结果及讨论
①KNN模型图
②逻辑回归模型图
③SVM模型图
④决策树模型图
各模型的优缺点汇总:
决策树
KNN算法
支持向量机(SVM)
逻辑回归
csv数据资源
一、技术原理
逻辑回归
面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏。
k近邻法(k-nearest neighbor,k-NN)
一种基本的分类和回归方法,是监督学习方法里的一种常用方法。k近邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例类别,通过多数表决等方式进行预测。
决策树
一种基于树结构来进行决策的分类算法,我们希望从给定的训练数据集学得一个模型(即决策树),用该模型对新样本分类。决策树可以非常直观展现分类的过程和结果,一旦模型构建成功,对新样本的分类效率也相当高。
SVM(Support Vector Machine)
中文名为支持向量机,是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。
模型评估
可以根据混淆矩阵。得到其Accuracy准确率以及F1 score是精确率和召回率的调和平均值,F1的结果当精确率接近0,或者召回率接近0时,都会得到一个很低的F值。当精确率为1,召回率也为1时,F值为1。因此F值可以用来为我们选择一个较好的临界值。
二、数据探索与处理
2.1读取贷款违约数据集,在系统中可视化展示部分数据集
通过pd.read_csv()读取数据集

dataset = pd.read_csv('../doc/bankloan.csv')
dataset.isnull().sum()#查看缺失值情况
dataset=dataset.dropna(axis=0, how='all')#去除行为空值
dataset2=dataset.dropna(axis=1,how="all")#去除列为空值
dataset3 = dataset2.drop_duplicates()
print(dataset3.shape)
dataset3.sample(5)#随机抽取5列进行展示进行缺失值处理,重复值删除之后数据的大小为(700,9)
describe()查看数据情况

2.2对违约情况进行饼图可视化,查看其占比情况


weiyue=dataset3.groupby('违约').size()
series = pd.Series([weiyue[0],weiyue[1]], index=["未违约", "违约"], name="违约情况")
series.plot.pie(figsize=(6, 6),autopct="%.2f",fontsize=20,labels=["未违约", "违约"],colors=["r", "g"])由图可知,本次贷款违数据集中,占了超过4分之3的客户是未违约客户,违约客户占了4分之1,需要进一步分析其违约情况与其具体关系
2.3对数据中的年龄情况进行可视化分析

groupby_birthyear = dataset3.groupby('年龄').size()
groupby_birthyear=pd.DataFrame(groupby_birthyear)
groupby_birthyear.columns=['年龄']
groupby_birthyear.plot.bar(figsize=(12, 6),title = '年龄分布情况',color='b')从图可知大多数客户的年龄集中在24-41之间
2.4对数据中的工龄情况进行可视化分析
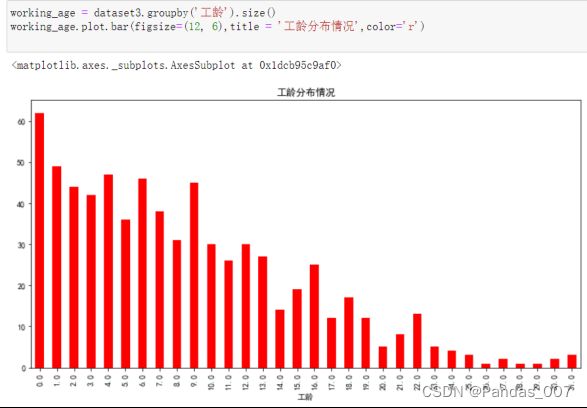
working_age = dataset3.groupby('工龄').size()
working_age.plot.bar(figsize=(12, 6),title = '工龄分布情况',color='r')
从图可知,大多数客户的工龄集中在13年以下,说明长期客户很不够多
2.5对收入可视化分析

由箱型图可以明显的观察到,大多数客户的收入集中在20-50w之间,有极少数大于100w的收入。
2.6对各负债情况进行可视化查看

2.7根据皮尔森系数,得到与违约相关性较高的特征如下表所示
绘制热力图进行展示

由图可知,负债率、信用卡负债、工龄这3类均达到了0.20以上的相关性。
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
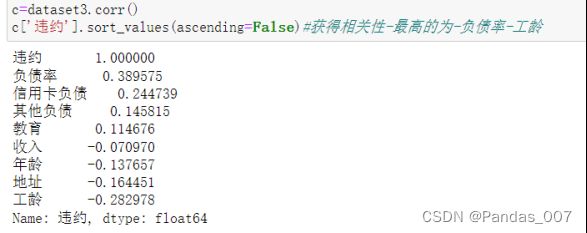
c=dataset3.corr()
c['违约'].sort_values(ascending=False)#获得相关性-最高的为-负债率-工龄
fig, ax = plt.subplots(figsize=(6, 6),facecolor='w')
import seaborn as sns
# 指定颜色带的色系
sns.heatmap(c,annot=True, vmax=1, square=True, cmap="Blues", fmt='.2g')
plt.title('相关性热力图')
plt.show()2.8进一步探查负债率、信用卡负债、工龄这3类与违约的关系
2.8.1负债率与违约关系

2.8.2信用卡负债与违约关系

2.8.3工龄与违约关系

最后选择以下三种方式行数据集的列名构建进行探究
| 自变量X的取值 |
Y值 |
| 负债率,信用卡负债 |
违约 |
| 负债率、工龄 |
违约 |
| 信用卡负债、工龄 |
违约 |
三、模型构建
①选取负债率,信用卡负债为X
X=dataset3.loc[:,['负债率','信用卡负债']].values
y=dataset3.loc[:,'违约'].values

得到以下的图

以下是这块的代码
X=dataset3.loc[:,['负债率','信用卡负债']].values
y=dataset3.loc[:,'违约'].values
size=np.arange(0.1,1,0.1)
scorelist=[[],[],[],[]]
from sklearn.model_selection import train_test_split
for i in range(0,9):
train_X, test_X, train_y, test_y = train_test_split(X ,
y,
train_size=size[i],
random_state=76)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
train_X = sc.fit_transform(train_X)
test_X = sc.transform(test_X)
#逻辑回归
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit( train_X , train_y )
scorelist[0].append(model.score(test_X , test_y ))
#决策树
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(train_X, train_y)
scorelist[1].append(model.score(test_X,test_y))
#支持向量机Support Vector Machines
from sklearn.svm import SVC
model = SVC()
model.fit( train_X , train_y )
scorelist[2].append(model.score(test_X , test_y ))
#KNN最邻近算法 K-nearest neighbors
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit( train_X , train_y )
scorelist[3].append(model.score(test_X , test_y ))
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
color_list = ('red', 'blue', 'lightgreen', 'cornflowerblue')
for i in range(0,4):
plt.plot(size,scorelist[i],color=color_list[i])
plt.legend(['逻辑回归', '决策树','SVM支持向量机', 'KNN最邻近算法'])
plt.xlabel('训练集占比')
plt.ylabel('准确率')
plt.title('不同的模型随着训练集占比变化曲线')
plt.show()②x选取负债率、工龄(与上同理)

③x选信用卡负债、工龄(与上同理)

综合上述三个图可知第③种划分中,逻辑回归模型的准确率最高
四、模型的基本训练
4.1决策树、SVM、逻辑回归、KNN模型的基本训练,并展示模型函数;
①决策树的基本训练
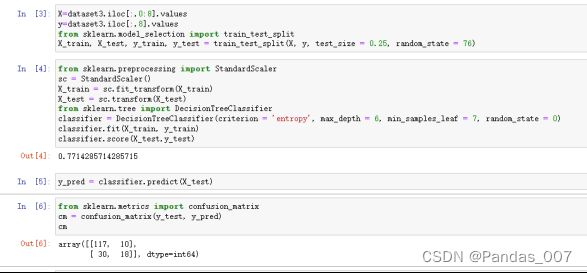
②SVM的基本训练

③逻辑回归的基本训练

④KNN模型的基本训练

4.2测试集中基本模型的评估,并展示评估结果;
①决策树模基本型评估

决策树模型:accuracy精确度为0.70
score得分为0.70
②SVM基本模型评估

SVM模型:accuracy精确度为0.78
score得分为0.77
③逻辑回归基本模型评估

逻辑回归模型:accuracy精确度为0.79
score得分为0.79
④KNN基本模型评估

KNN模型:accuracy精确度为0.75
score得分为0.74
4.3模型的调优调参,寻找最优模型,并列表对比参数的变化过程及对应结果;
①决策树的调优调参
max_depth(决策树的最大深度),默认值为None。如果模型样本数量多,特征也多时,推荐限制这个最大深度,具体取值取决于数据的分布。常用的可以取值10-100之间,常用来解决过拟合。
4.3.1当max_depth为自变量,其他参数不变时score的变化情况如图所示:
参数变化情况:
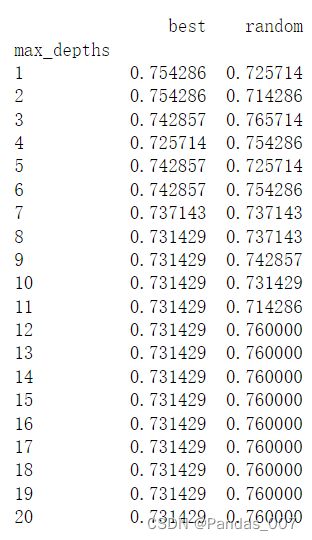
4.3.2当min_samples_leaf和splitter为自变量时,
spliiter参数为’best’和’random’的情况:
参数变化情况列表:
4.3.3当max_depth和max_features为自变量时,max_features为
‘auto’,’log2’,’sqrt’的情况:
详细信息如下:

4.3.4当min_samples_leaf和max_features为自变量时,max_features为‘auto’,’log2’,’sqrt’的情况:

详细信息如下:

4.3.5最后通过循环,遍历所有可变的参数,进行自动调参得到最高score和accuracy
通过循环设置多个变量,如图所示

from sklearn.tree import DecisionTreeClassifier
best_score=0.0
best_criterion = 'entropy'
best_max_depth=0
best_min_samples_leaf=0
best_splitter='best'
best_max_features=''
#best_size=-1
best_state=-1
best_accuracy=-1
best_all_a_s=-1
from sklearn.model_selection import train_test_split
#for p in range(25,50):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 76)
for j in range(5,20): #dep的值
for m in [2,3,5,10]:#sam的值
for n in ['best','random']: #im的值
for k in ['auto','log2','sqrt']:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
classifier = DecisionTreeClassifier(criterion = 'entropy', max_depth=j,max_features=k,
min_samples_leaf=m,splitter=n,random_state=0)
classifier.fit(X_train, y_train)
score=classifier.score(X_test,y_test)
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
from sklearn.metrics import classification_report
report = classification_report(y_test, y_pred)
d=report.replace(" ","").split("\n")
d2=d[5][8:]
d2=float(d2)#得到准确度 accuracy
all=d2+score#获得score和accuracy的最高分
if best_all_a_s依次遍历循环最终得到最高的score和accuracy的得分如下:
best_score=0.80
best_accuracy=0.79
最高分其对应的最好参数如下:
| max_depth |
min_samples_leaf |
splitter |
max_features |
random_state |
| 6 |
10 |
‘best |
‘auto’ |
0 |
②SVM支持向量机的调优调参
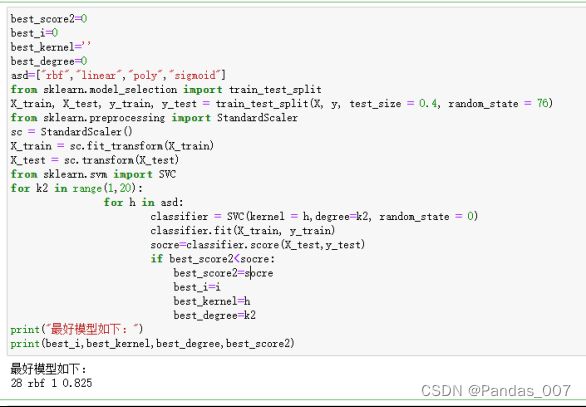
best_score2=0
best_i=0
best_kernel=''
best_degree=0
asd=["rbf","linear","poly","sigmoid"]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 76)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
from sklearn.svm import SVC
for k2 in range(1,20):
for h in asd:
classifier = SVC(kernel = h,degree=k2, random_state = 0)
classifier.fit(X_train, y_train)
socre=classifier.score(X_test,y_test)
if best_score2| degree |
kernel |
| 1 |
‘rbf’ |
③逻辑回归的调优调参

best_penalty=''
best_C=0
best_solver=''
best_score=0
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 76)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
for u in range(1,101):
for j in ['l1','l2']:
for k2 in ['liblinear','lbfgs','newton-cg','sag']:
try:
u2=u*0.01
from sklearn.linear_model import LogisticRegression
classifer=LogisticRegression(C=u2,penalty=j,solver=k2)
classifer=classifer.fit(X_train,y_train)
score=classifer.score(X_test,y_test)
if best_score通过自动化调优调参得到最优参数如下:
| C2 |
penalty |
solver |
| 0.09 |
‘l2’ |
‘liblinear’ |
④KNN的调优调参

from sklearn.neighbors import KNeighborsClassifier
best_score=0.0
best_k=-1
best_weight='uniform'
best_p=0
best_test=-1
best_state=-1
best_all_a_s=0
best_accuracy=0
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 76)
for i in ['uniform','distance']:
for j in range(1,21): #k的值
for k in range(1,10): #p的值
classifier = KNeighborsClassifier(n_neighbors = j, weights = i, p = k,metric = 'minkowski')
classifier.fit(X_train, y_train)
score=classifier.score(X_test,y_test)
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
from sklearn.metrics import classification_report
report = classification_report(y_test, y_pred)
d=report.replace(" ","").split("\n")
d2=d[5][8:]
d2=float(d2)#得到准确度 accuracy
all=d2+score#获得score和accuracy的最高分
if best_all_a_s通过自动化调优调参得到最优参数如下:
| n_neighbors |
weights |
p |
| 8 |
‘uniform’ |
1 |
综上所述决策树模型的调优调参后的效果最好,精确度达到了0.8

五、实验结果及讨论
①KNN模型图

②逻辑回归模型图

③SVM模型图
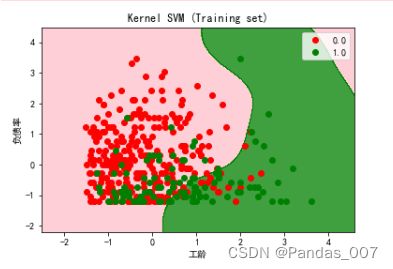
④决策树模型图

from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('pink', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Kernel SVM (Training set)')
plt.xlabel('工龄')
plt.ylabel('负债率')
plt.legend()
plt.show()由上图可知,逻辑回归的图形明显要好于其他模型的预测
各模型的优缺点汇总:
决策树
优点:
一、 决策树易于理解和解释.人们在通过解释后都有能力去理解决策树所表达的意义。
二、 对于决策树,数据的准备往往是简单或者是不必要的.其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性。
三、 能够同时处理数据型和常规型属性。其他的技术往往要求数据属性的单一。
缺点:
一、 对于那些各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。
二、 决策树处理缺失数据时的困难。
三、 过度拟合问题的出现。
四、 忽略数据集中属性之间的相关性。
KNN算法
优点:
一、 简单、有效。
二、 重新训练的代价较低(类别体系的变化和训练集的变化,在Web环境和电子商务应用中是很常见的)。
三、 计算时间和空间线性于训练集的规模(在一些场合不算太大)
缺点:
- KNN算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多
支持向量机(SVM)
优点
一、 可以解决小样本情况下的机器学习问题。
二、 可以提高泛化性能。
三、 可以解决高维问题。
缺点
一、 对缺失数据敏感。
逻辑回归
优点:
一、预测结果是界于0和1之间的概率;
二、可以适用于连续性和类别性自变量;
三、容易使用和解释;
缺点:
对模型中自变量多重共线性较为敏感,例如两个高度相关自变量同时放入模型,可能导致较弱的一个自变量回归符号不符合预期,符号被扭转。需要利用因子分析或者变量聚类分析等手段来选择代表性的自变量,以减少候选变量之间的相关性;
csv数据资源
Python分类模型实战(KNN、逻辑回归、决策树、SVM)调优调参,评估模型-综合项目csv资源数据-Python文档类资源-CSDN下载