isodata算法确定k均值聚类的k值
http://baike.baidu.com/view/3167773.htm
http://www.cnblogs.com/huadongw/p/4101422.html
(1) 选择某些初始值。可选不同的参数指标,也可在迭代过程中人为修改,以将N个模式样本按指标分配到各个聚类中心中去。
(2) 计算各类中诸样本的距离指标函数。
(3)~(5)按给定的要求,将前一次获得的聚类集进行分裂和合并处理((4)为分裂处理,(5)为合并处理),从而获得新的聚类中心。
(6) 重新进行迭代运算,计算各项指标,判断聚类结果是否符合要求。经过多次迭代后,若结果收敛,则运算结束。
3. ISODATA算法流程图:
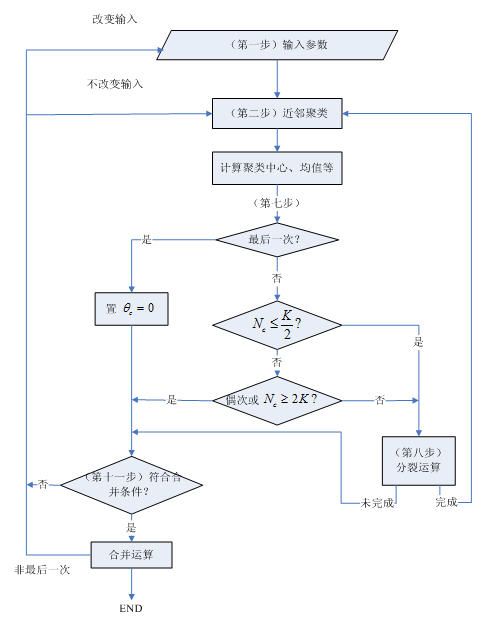
4.ISODATA算法
第一步:输入 N 个模式样本 {xi,i=1,2,…,N}
预选 Nc 个初始聚类中心 {z1,z2,…zNc} ,它可以不等于所要求的聚类中心的数目,其初始位置可以从样本中任意选取。
预选: K = 预期的聚类中心数目;
θN = 每一聚类域中最少的样本数目,若少于此数即不作为一个独立的聚类;
θS = 一个聚类域中样本距离分布的标准差;
θc = 两个聚类中心间的最小距离,若小于此数,两个聚类需进行合并;
L = 在一次迭代运算中可以合并的聚类中心的最多对数;
I = 迭代运算的次数。
第二步:将 N 个模式样本分给最近的聚类 Sj ,假若 Dj=min{∥x−zi∥,i=1,2,⋯Nc}
,即 ||x−zj|| 的距离最小,则 x∈Sj 。
第三步:如果 Sj 中的样本数目Sj<θN,则取消该样本子集,此时Nc减去1。
(以上各步对应基本步骤(1))
第四步:修正各聚类中心
第五步:计算各聚类域Sj中模式样本与各聚类中心间的平均距离
第六步:计算全部模式样本和其对应聚类中心的总平均距离
(以上各步对应基本步骤(2))
第七步:判别分裂、合并及迭代运算
- 若迭代运算次数已达到I次,即最后一次迭代,则置θc =0,转至第十一步。
- 若 Nc≤K2
,即聚类中心的数目小于或等于规定值的一半,则转至第八步,对已有聚类进行分裂处理。 - 若迭代运算的次数是偶数次,或 Nc≥2K
,不进行分裂处理,转至第十一步;否则(即既不是偶数次迭代,又不满足 Nc≥2K ),转至第八步,进行分裂处理。
(以上对应基本步骤(3))
第八步:计算每个聚类中样本距离的标准差向量
其中向量的各个分量为
式中,i = 1, 2, …, n为样本特征向量的维数,j = 1, 2, …, Nc为聚类数,Nj为Sj中的样本个数。
第九步:求每一标准差向量{σj, j = 1, 2, …, Nc}中的最大分量,以{σjmax, j = 1, 2, …, Nc}代表。
第十步:在任一最大分量集{σjmax, j = 1, 2, …, Nc}中,若有σjmax>θS ,同时又满足如下两个条件之一:
- D¯j>D¯ 和Nj > 2(θN + 1),即Sj中样本总数超过规定值一倍以上,
- Nc≤K2
则将zj 分裂为两个新的聚类中心和,且Nc加1。 中对应于σjmax的分量加上kσjmax,其中;中对应于σjmax的分量减去kσjmax。
如果本步骤完成了分裂运算,则转至第二步,否则继续。
(以上对应基本步骤(4)进行分裂处理)
第十一步:计算全部聚类中心的距离
第十二步:比较Dij 与θc 的值,将Dij <θc 的值按最小距离次序递增排列,即
式中 Di1j1<Di2j2<…<DiLjL 。
第十三步:将距离为 Dikjk 的两个聚类中心 Zik 和 Zjk 合并,得新的中心为:
式中,被合并的两个聚类中心向量分别以其聚类域内的样本数加权,使 Z∗k 为真正的平均向量。
(以上对应基本步骤(5)进行合并处理)
第十四步:如果是最后一次迭代运算(即第I次),则算法结束;否则,若需要操作者改变输入参数,转至第一步;若输入参数不变,转至第二步。
在本步运算中,迭代运算的次数每次应加1。
[算法结束]
5.例子:试用ISODATA算法对如下模式分布进行聚类分析:
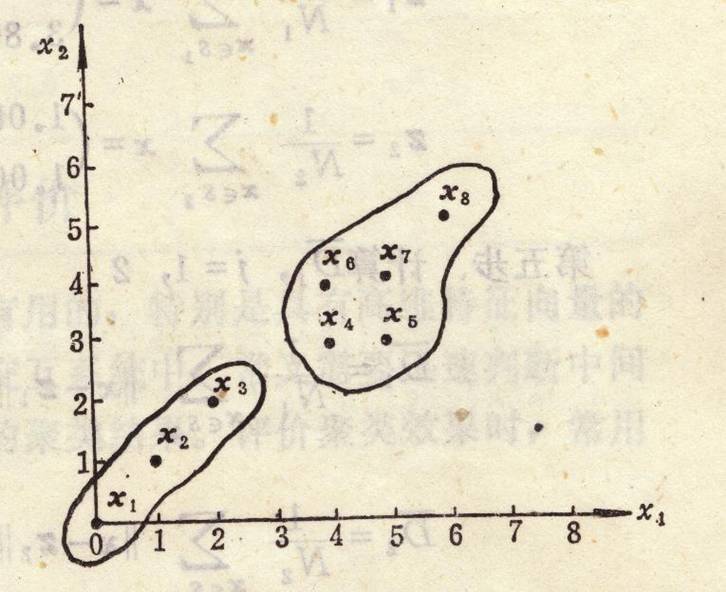
我们可以知道,N=10,n=2。假设取初始值 Nc=1 ,z1=x1=(0 0)T,则运算步骤如下:
(1) 设置控制参数
取K=3,θN=1,θS=1,θc=4,L=1,I=4
(2) 按最小距离原则将模式集(xi)中每个模式分到某一类中。
由于此时只有一个聚类中心,因此S1={x1, x2, …, x10},N1=10
(3) 因N1>θN ,无子集可抛
(4) 修改聚类中心
(5) 计算模式样本与聚类中心间的平均距离 D¯1
(6) 计算全部模式样本和其对应聚类中心的总平均距离
(7) 因不是最后一次迭代,且 Nc<K/2 ,进入(8)
(8) 计算S1中的标准差向量
(9) σ1max 中的最大分量是2.5219,因此 σ1max=2.5219 。
(10)因 σ1max>θs 且 Nc<K2 ,可将z1分裂成两个新的聚 类。设 rj=0.5σ1max≈1.261 .则
为方便起见,将 z+1 和 z−1 表示为z1和z2,Nc加1 , Nc=2 .
(11) 重新进行分类
| 样本点 |
特征值 |
到z1的距离 |
到z2的距离 |
聚类结果 |
|
| X1 |
0 |
0 |
6.3893 |
4.6537 |
S2 |
| X2 |
3 |
8 |
3.0737 |
5.5347 |
S1 |
| X3 |
2 |
2 |
3.6027 |
1.975 |
S2 |
| X4 |
1 |
1 |
4.9902 |
3.2831 |
S2 |
| X5 |
5 |
3 |
2.3362 |
1.1927 |
S2 |
| X6 |
4 |
8 |
2.9407 |
5.4619 |
S1 |
| X7 |
6 |
3 |
2.9424 |
2.15 |
S2 |
| X8 |
5 |
4 |
1.5283 |
1.8288 |
S1 |
| X9 |
6 |
4 |
2.3528 |
2.5582 |
S1 |
| X10 |
7 |
5 |
3.1006 |
3.9581 |
S1 |
(12) 因N1>θN 且N2>θN,无子集可抛。
(13) 修改聚类中心
(14) 计算模式样本与聚类中心间的平均距离 D¯j,j=1,2
(15) 计算全部模式样本和其对应聚类中心的总平均距离 D¯
(16) 因是偶数次迭代,所以进行合并
(17) 计算聚类对之间的距离
(18) 比较 D12 与θc , D12 >θc,所以聚类中心不发生合并
(19) 没有达到所需的聚类数,所以继续进行,重新分类
| 样本点 |
特征值 |
到z1的距离 |
到z2的距离 |
聚类结果 |
|
| X1 |
0 |
0 |
7.6577 |
3.3287 |
S2 |
| X2 |
3 |
8 |
2.9732 |
6.2032 |
S1 |
| X3 |
2 |
2 |
4.8415 |
0.82462 |
S2 |
| X4 |
1 |
1 |
6.2482 |
1.9698 |
S2 |
| X5 |
5 |
3 |
2.8 |
2.506 |
S2 |
| X6 |
4 |
8 |
2.4166 |
6.3151 |
S1 |
| X7 |
6 |
3 |
2.9732 |
3.4176 |
S1 |
| X8 |
5 |
4 |
1.8 |
3.1113 |
S1 |
| X9 |
6 |
4 |
2.0591 |
3.8833 |
S1 |
| X10 |
7 |
5 |
2.1541 |
5.2802 |
S1 |
(20) 因N1>θN 且N2>θN,无子集可抛。
(21) 修改聚类中心
(22) 计算模式样本与聚类中心间的平均距离, D¯1,j=1,2
(23) 计算全部模式样本和其对应聚类中心的总平均距离 D¯
(24) 此次是奇数次迭代,并且 Nc>K2 ,所以进行分裂操作
(25) 计算 S1={x2,x6,x7,x8,x9,x10}
和 S21={x1,x3,x4,x5}
的标准差
(26) σ1max=1.972,σ2max=1.8708
(27)此时, σ1max=1.972>θs,N1=6>2(θN+1)=4 且 D¯1>D¯ ,所以满足分裂的条件,将S1进行分裂。
设 \rj=0.5σ1max≈0.986 ,则
为方便起见,将 Z+1 和Z_^-表示为 Z11 和 Z12 , Nc 加1, Nc=3 .
(28)重新进行分类
| 样本点 |
特征值 |
到的距离 |
到的距离 |
到的距离 |
聚类结果 |
|
| X1 |
0 |
0 |
8.1626 |
6.7523 |
2.5 |
S2 |
| X2 |
3 |
8 |
2.7421 |
4.247 |
6.5765 |
S11 |
| X3 |
2 |
2 |
5.3558 |
3.9418 |
0.5 |
S2 |
| X4 |
1 |
1 |
6.7569 |
5.3447 |
1.118 |
S2 |
| X5 |
5 |
3 |
3.3235 |
1.3576 |
3.3541 |
S12 |
| X6 |
4 |
8 |
2.046 |
3.8345 |
6.8007 |
S11 |
| X7 |
6 |
3 |
3.4223 |
1.5842 |
4.272 |
S12 |
| X8 |
5 |
4 |
2.3253 |
0.38524 |
3.9051 |
S12 |
| X9 |
6 |
4 |
2.4645 |
0.90278 |
4.717 |
S12 |
| X10 |
7 |
5 |
2.2587 |
1.946 |
6.1033 |
S12 |
(29) 因N11>θN 且N12>θN且N2>θN,无子集可抛
(30) 修改聚类中心
(31) 计算模式样本与聚类中心间的平均距离 D¯j
(32) 计算全部模式样本和其对应聚类中心的总平均距离 D¯
(33) 因是偶数次迭代,所以进行合并
(34) 计算聚类对之间的距离
|
|
Z11 | Z12 | Z13 |
| Z11 | 0 |
4.7885 |
7.433 |
| Z12 | 4.7885 |
0 |
5.557 |
| Z2 | 7.433 |
5.557 |
0 |
所以
故没有可以合并的类
(35) 最后一次迭代,算法结束。
最终的聚类结果是
该资料整理于国科大《模式识别》讲稿和作业。