简易RISC软核CPU设计
1,简介
该工程已开源至GitHub,请自行点击查看
FPGA设计中在IP核的提供方式上,通常将其分为软核、固核和硬核这3类。软核(Soft IP Core) : 软核在EDA 设计领域指的是综合之前的寄存器传输级(RTL) 模型;通常遍是指以HDL代码(Verilog,VHDL…)为形式的可综合源代码;固核(Firm IP Core) :固核在EDA 设计领域指的是带有平面规划信息的网表;硬核 (Hard IP Core) :硬核在EDA 设计领域指经过验证的设计版图。软核只经过功能仿真,需要经过综合以及布局布线才能使用。其优点是灵活性高、可移植性强,允许用户自配置。软核处理器是指利用HDL语言描述的处理器功能代码,用于实现处理器的所需要的各种功能。

通常的处理器架构由以下部分组成。指令寄存器、累加器、算术逻辑运算单元、数据控制器、状态控制器、程序计数器、地址多路器等基本部件。是用于实现根据特定指令集生成的汇编代码的硬件运行环境。本文在介绍risc-v 指令集的相关基本概念后,通过一个简易的risc-v 处理器设计,来说明处理器工作时的各种细节。
2,CPU的工作流程
常见的CPU内部有5级流水线组成。cpu的工作大致分为以下几个步骤;
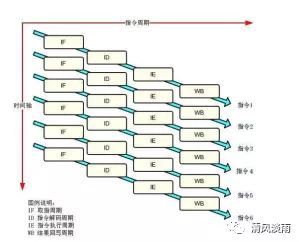
1:取指。该阶段从内存中读取指令,PC(程序计数器)制定指令的地址。
2:译码。该阶段将从内存读取的指令翻译为各种操作。并从寄存器中取出操作数。
3:执行。该阶段算数逻辑单元执行指令表示的操作。
4:访存。该阶段将结果数据写入到内存中。
5:写回。将结果写会到寄存器文件中。
(1)取指令(IF)
CPU在取指令阶段(IF阶段)时,先向一级指令缓存要指令,要到指令后我们将程序计数器(PC)自增1(1表示移动一条指令的宽度,如果数据单位是32位,那么就自增1,如果数据单位是8位1字节,那么就自增4)。这样我们在下次取指令的时候就能取到下一条指令了。同时如果你实现了分支预测,那么在这里则需要做另外的处理。
(2)解码(ID)
注意到我们有这些指令对:add和addi,addu和addui,or和ori等,这些指令对的功能是一样的,只是取操作数的方式不一样,如果我们能用某种方式统一这些指令对,那么我们在实现这些指令的执行将会变得更简单,因为对于同一类的指令我们能做同一个操作。解码器就是做这个事情的。
CPU在解码阶段(ID阶段)时还需要根据解码器得到的操作数寄存器的编号,从相应的寄存器中取出ALU所需要的操作数,因此我们也将寄存器归到解码阶段中。
(3)执行(EX)
执行阶段(EX阶段)是我们调用ALU进行真正的计算过程。由于乘法和除法的速度比较慢,如果1个周期能完成加法的计算,那么乘法和除法就需要超过1个周期的时间,也就是说乘法器和除法器在多周期CPU里是多周期的。同时,所有的浮点运算也都是多周期的,比如浮点加是4个周期(另外在浮点运算单元中同样存在流水线,把浮点加法分成4个阶段计算)。
同时对于syscall指令,我们也要在执行阶段完成操作。
因此执行阶段CPU一共会有以下执行模块,分别是ALU、整数的乘除运算单元、浮点运算单元(内部仍存在流水线,而且加减法和乘除法可以并行执行)和其他的一些处理电路。
【ALU】
ALU在执行阶段将会按照给定的ALU的微指令,对两个操作数进行运算(无论是加减运算、位运算、比较运算以及跳转指令需要的比较运算),并得到结果输出(输出包括运算结果、是否跳转等信息)。对于内存操作的指令,我们也需要ALU计算出我们要读取的内存的真实地址(因为指令规范中给定的是某个寄存器的偏移,或者当前指令的偏移)。
(4)内存读写(MEM)
对于lb、lbu、lh、lhu、lw、sb、sbu、sh、shu、sw等内存操作的指令,这个阶段将被启用。这个阶段将会与一级的数据缓存交互。
(5)寄存器写(WB)
这个阶段(WB阶段)有结果的指令将会把数据存到对应的寄存器里。
在CPU的工作流程中,首先读取PC(程序计数器)指向的地址的指令,送入到译码模块,译码器对opcode指令进行译码,经过译码之后得到指令需要的操作数寄存器索引,可以使用此索引从通用寄存器组(Register File,Regfile)中将操作数读出。指令译码之后所需要进行的计算类型都已得知,并且已经从通用寄存器组中读取出了所需的操作数,那么接下来便进行指令执行。指令执行是指对指令进行真正运算的过程。譬如,如果指令是一条加法运算指令,则对操作数进行加法操作;如果是减法运算指令,则进行减法操作。
3,RISC-V指令集介绍
下图显示了六种基本指令格式,分别是:用于寄存器-寄存器操作的 R 类型指令,用于短立即数和访存 load 操作的 I 型指令,用于访存 store 操作的 S 型指令,用于条件跳转操作的 B 类型指令,用于长立即数的 U 型指令和用于无条件跳转的 J 型指令。

首先,指令只有六种格式,并且所有的指令都是 32 位长,这简化了指令解码。第二,RISC-V 指令提供三个寄存器操作数(rs1,rs2,rd),而不是像 x86-32 一样,让源操作数和目的操作数共享一个字段。当一个操作天然就需要有三个不同的操作数,但是 ISA 只提供了两个操作数时,编译器或者汇编程序程序员就需要多使用一条 move(搬运)指令,来保存目的寄存器的值。第三,在 RISC-V 中对于所有指令,要读写的寄存器的标识符总是在同一位置,意味着在解码指令之前,就可以先开始访问寄存器。第四,这些格式的立即数字段总是符号扩展,符号位总是在指令中最高位。这意味着可能成为关键路径的立即数符号扩展,可以在指令解码之前进行。

RV32I 带有指令布局,操作码,格式类型和名称的操作码映射。
4,设计总览
在本设计中,为了简化设计,降低设计的复杂度,并没有采用多级流 水线形式来设计,而是采用了状态机的方法。取指,译码, 执行,访问,写回分别在几个周期内完成,等 完成该指令的操作后,在读取下一个指令。整个 RISC_CPU 设计方案组成框图应该包含以下内容:
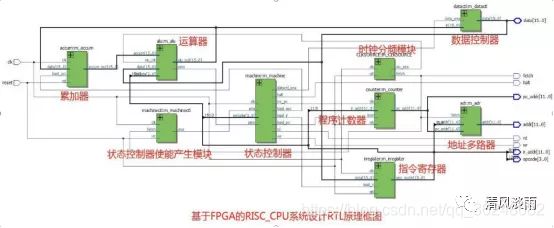
从上述架构图可以看出,RICS_CPU 结构比较复杂,但是它的基本部件并不复杂,整个方案设计可以从它的 8 个基本组成部分来考虑:
时钟发生器
指令寄存器
累加器
算术逻辑运算单元
数据控制器
状态控制器
程序计数器
地址多路器
4.1 时钟发生器
该模块的设计主要是利用外部时钟信号 clk 来产生一系列时钟信号,并且可以送到 CPU 的其它各个部件中。其中,fetch 是控制信号,clk 的 6 分频信号。当 fetch 高电平时,使 clk 能触发 cpu 控制器开始执行一条指令;同时 fetch 信号还将控制地址多路器输出指令地址和数据地址。clk 信号还用作指令寄存器,累加器,状态控制器的时钟信号。
 图 2 时钟发生器原理图
图 2 时钟发生器原理图
4.2 指令寄存器
指令寄存器的触发信号时 clk,在 clk 的正沿触发下,寄存器将数据总线送来的指令存入 16 位的寄存器中,但并不是每个 clk 的上升沿都寄存数据总线的数据,因为数据总线上有时传输指令,有时传输数据。什么时候寄存,什么时候不寄存由 CPU 状态控制器的 load_ir 信号控制。load_ir 信号通过 load_ir 口输入到指令寄存器,复位后,指令寄存器被清为零。
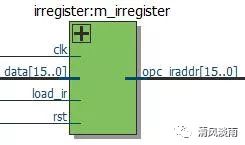 图 3 指令寄存器原理图
图 3 指令寄存器原理图
4.3 累加器
累加器用于存放当前的结果,它也是双目运算中的一个数据来源。复位后, 累加器的值是零。当累加器通过 load_acc 信号时,在 clk 时钟跳变沿时就受到来自于数据总线的数据。
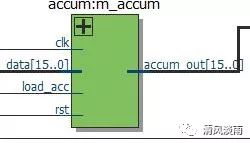 图 4 累加器原理图
图 4 累加器原理图
4.4 算术运算器
算术逻辑运算单元,它根据输入的 16 种不同的操作码分别进行加减乘,与或非等基本操作运算,利用这几种基本运算可以实现很多种其它运算以及逻辑判断等操作。
 图 5 算术运算器原理图
图 5 算术运算器原理图
4.5 数据控制器
数据控制器,其作用是控制累加器的数据输出,由于数据总线是各种操作时传送数据的公共通道,不同情况下传送不同的内容。有时要传输指令,有时要传送 RAM 区或接口的数据。累加器的数据只有在需要往 RAM 区域或端口写时才允许输出,否则应呈现高阻态,以允许其它部件使用数据总线。所以任何部件往总线上输出数据时,都需要一控制信号。而此控制信号的启停则由 cpu 状态控制器输出各信号控制决定。数据控制器何时输出累加器的数据则由状态控制器输出的控制信号 data_ena 决定。
 图 6 数据控制器原理图
图 6 数据控制器原理图
4.6 地址多路器
地址多路器,它用于选择输出的地址是 PC 地址还是数据/端口地址。每个指令周期的前 3 个时钟周期用于从 ROM 中读取指令,输出的应是 PC 地址,后 3 个时钟周期用于 RAM 或端口的读写,该地址有指令给出。地址的选择输出信号由时钟信号的 6 分频 fetch 提供。
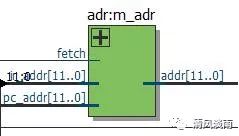 图 7 地址多路器原理图
图 7 地址多路器原理图
4.7 程序计数器
它用于提供指令地址,以便读取指令。指令按地址顺序存放在存储器中。有两种途径可形成指令地址;其一是顺序执行的情况,其二是遇到要改变顺序执行程序的情况,例如执行 JMP 指令后,需要形成新的地址。
 图 8 程序计数器原理图
图 8 程序计数器原理图
4.8 状态控制器
状态机控制器接收复位信号 reset,当 reset 有效时,通过信号 ena 使其为零, 输入到状态机中,以停止状态机的工作。状态机是 cpu 的控制核心,用于产生一系列的控制信号,启动或停止某些部件。cpu 何时进行指令来读写I/O 端口及RAM 区等操作,都是由状态机来控制的。状态机的当前状态,由变量 state 记录,state 的值就是当前这个指令周期中已过的时钟数。
指令周期是有 6 个时钟周期组成,每个时钟周期都要完成固定的操作,即:
-
第 0 个时钟,cpu 状态控制器的输出 rd,data_ctl 和 load_ir 为高电平,inc_pc从 0 变为 1 故 pc 加 1,ROM 送来的指令代码寄存在指令寄存器中。
-
第 1 个时钟空操作
-
第 2 个时钟。若操作符为 HLT,则输出信号 HLT 为高。如果操作符不为HLT,除了 PC 增 1 外,其他各控制线输出为零。
-
第 3 个时钟,若操作符为 AND,ADD,XOR,LDA,NOT,MUL,SUB , OR, RL, RR, POP, PUSH,读取相应地址的数据;若为 STO,输出累加器数据。
-
第 4 个时钟,若操作符为 AND,ADD 等算术运算,算术运算器就进行相应的运算;若操作符为 LDA,就把数据通过算术运算符送给累加器;若为SKZ,先判断累加器的值是否为 0,如果为 0,PC 加 1,否则保持原值;若为 JMP,锁存目标地址;若为 STO,将数据写入地址处。
-
第 5 个时钟空操作
5,仿真结果

图 10 RISC_CPU 顶层系统级仿真及部分信号说明

图 11 RISC_CPU 复位及内部寄存器初始值仿真
仿真结果说明:RISC_CPU 的复位和启动操作是通过 reset 引脚的信号触发执行。当 reset 信号一进入高电平,RISC_CPU 就会结束先行操作,并且只要 reset 停留在高电平状态,cpu 就维持在复位状态。在复位状态,cpu 各个内部寄存器都被设有初值,全部为零。数据总线为高阻态,地址总线为 000H,所有控制信号均为无效状态,reset 回到低电平后,接着到来的第一个 fetch 上升沿奖启动RISC_CPU 开始工作,从 ROM 的 000 处开始读取指令并执行相应操作,波形见图 11。

图 12 RISC_CPU 时钟分频模块仿真-6 分频

图 13 CPU 总线写操作—RISC_CPU 写入数据时序仿真

图 14 RISC_CPU 读取数据时序仿真
仿真结果说明:每个指令周期的前 0~2 个时钟周期用于读指令;第 2.5 个周期处,存储器或端口地址就输入到地址总线上;第 3~5 个时钟周期,读信号 rd有效,数据送到数据总线上,以便累加器锁存,或参与算术,逻辑运算。

图 15 RISC_CPU 指令寄存器模块仿真

图 16 RISC_CPU 运算器模块仿真