【论文阅读】APANet: Adaptive Prototypes Alignment Network for Few-Shot Semantic Segmentation

论文地址:https://arxiv.org/abs/2111.12263
论文代码:-
本文目录
文章目录
-
- 本文目录
- 1.前言
-
- 1.1深度学习与数据量
- 1.2语义分割
- 1.3元学习
- 1.4小样本分割
- 1.5小样本分割目前存在的问题
- 2.APANet概述
-
- 2.1提出问题
- 2.2解决方案
- 2.3文章贡献
- 2.4网络结构
- 2.5参数名词解释
- 2.6公式介绍
- 2.7效果展示
- 总结
-
- 留一个疑问:
1.前言
1.1深度学习与数据量
如今,深度学习技术在计算机视觉领域取得很大的发展。随着Imagenet、coco、pascal voc等大型数据集的提出,深度学习几乎和大量的有标注的人工数据集绑定在一起。海量的数据集使得网络具有可以不断加深的前提,网络模型的能力也不断提升,深度学习在图像分类,目标检测和图像分割领域都获得了突破。但同时大型数据集也制约了深度学习的发展,个人总结主要有以下两点原因:
1.数据集或带标注的数据集难以获取
在工业生产中或某些场合下,目标图像出现的次数很少,比如缺陷件的图像不容易采集,同时对于目标检测和语义分割任务而言,需要人工对图像矩形或像素进行密集型标注,这种工作周期长,且金钱代价大。
2.深度学习偏向于可见类,具有严重的过拟合现象
如今的深度学习网络动则几十层,上百层或者更深,模型参数量很大,需要庞大的数据集才可以train的动,但是大多数场景下,数据集本身会存在类别不平衡的情况,或者突然有一个新类需要加入训练,而其数据量很小,产生过拟合现象,导致初期的训练效果就会很不理想,需要不断采集加图训练,这样模型的迭代会很慢。
总之就是数据量不够的问题,data augmentation数据增广是一个不错的方法,但是一般的数据增广不一定对模型的性能有所改善,甚至起到负作用,有些研究者使用强大的数据增广来提升模型的泛化能力,但是我觉得在数据集缺少的情况下,他的作用是极其有限的。简单说"可以提升精度,但不一定work"
在介绍本次阅读的文献之前,我先介绍一下相关的知识背景,以后的文章不再叙述。
1.2语义分割
以经典的FCN网络为例,主要结构是采用全卷积的网络结构,先通过编码器对图像进行编码,就是下采样和特征提取,此时获取到的是高维的语义信息,然后通过解码器对特征图进行上采样,一般上采样的原图大小,之后通过激活函数对图像的每一个像素进行分类,通过精细的像素级人工标签,计算交叉熵损失后,得到分割结果,后续分割网络也都采用这种先编码再解码的结构。
1.3元学习
元学习meta learning 他与传统深度学习喂数据和答案的训练方式不同,元学习采用情景训练的学习方式,通过在查询集与支持集之间的对比,让模型自主的学会区分它们的能力,让模型学会学习。具体的元学习的内容比较难懂,具体可以看这篇博文http://t.csdn.cn/Azurt
我们只需要了解它是从有限的support set里面学知识,然后在query set预测的时候就是test set里面直接将这些知识用于判断那些是需要的图片或像素。

(这图也是在一篇c帖找到的,三玖yyds)
1.4小样本分割
小样本语义以分割为目标,在一幅查询图像中对新的类进行像素级分类,条件是只有少量的注释支持图像。OSLSM这篇文章第一次提出了这种方案,大致方案就是通过共享的特征提取器提取支持集和查询集的特征,然后使用再将特征送入元学习器中,进行判断,通过支持集的注释图像获得目标特征,然后在查询图像中分割新类。

1.5小样本分割目前存在的问题
- 小样本分割总是偏向于基类,分割的新类容易把基类分割进去(Learning What Not to Segment: A New Perspective on Few-Shot Segmentation提及)
- 小样本分割元学习器不稳定,容易受到支持集与查询集样本空间不一致带来的影响(Learning What Not to Segment: A New Perspective on Few-Shot Segmentation提及)
- 小样本分割分割一般只能分割支持集里面包含的novel类对于之前分割的类不能有效分割,需要推广到GFSS,即Generalized Few-shot Semantic Segmentation
2.APANet概述
2.1提出问题
APANET认为训练过程中正负样本的划分冲突会影响小样本分割精度的问题,原文中:

将前景原型与查询特征进行特征比较,并在训练时将查询图像中的整个背景特征作为负样本。 这将导致FSS的一个问题,因为测试集中的一些新类对象可能出现在训练图像中,但在训练过程中被视为背景。
通过原文的中Fig 2可以具体解释:

众所周知,小样本分割训练过程中,会将图片划分成支持集和查询集,在训练过程中支持集往往给出所需指定novel样本图像极其mask,对于其他可能的样本都会视作背景。如上图所示,四张图中的novel样本分别是:汽车,火车,长颈鹿。而图像上其他的区域都是背景,其中包含了轮船,人类,斑马和巴士。在这次训练过程不会出现歧义的问题,这些背景样本对象会在测试过程中出现在前景中,成为新的novel样本,这会给模型带来严重的歧义。

我们很容易发现一些类,如船、人、斑马和巴士,出现在这些训练图像的背景中,而它们实际上可以是新的类,需要在测试阶段识别为前景。 这种训练和测试阶段之间的冲突会带来系统偏差,从而限制小样本学习模型的泛化性能。
综合前面阅读的论文总结的问题,再结合这个问题还是有点让我意外的,总感觉这个问题的提出与小样本分割的原始含义相互冲突。我的理解是小样本学习的元学习是去学会学习,而不是学习固定的基类的是什么样子,小样本分割中应该完全利用support set中给出的原型直接用于query set分割即可,而这篇文章的这种说法意思现在的小样本分割和之前的语义分割类似,模型会记住什么是前景,什么是背景,然后由于正负样本的划分冲突从而影响分割精度,所以不是一种理想的元学习范式。
后续发现文章还提出了一个问题:

如上所述,特定于类的分支将查询图像中的背景特征从前景原型中移开,并鼓励查询图像中的前景特征靠近前景原型。 因此,这种学习机制在训练时容易强迫模型记住基类集cBase以外的对象作为背景,限制了模型的泛化能力。
可见由于训练方式的限制,导致模型偏向于基类特征
2.2解决方案


我们解决这个问题的基石是在训练阶段开发类特定和类不可知的原型,从而构建完整的特征对用于比较,如图所示 1(d). 对于特定类的原型,该模型以查询中的前景特征为正样本,以背景特征为负样本。 相反,对于每个类不可知的原型,查询中对应的背景特征被视为正样本,而前景特征被视为负样本。 请注意,背景被定义为那些注释对象(前景)之外的任何区域。 通过这种方式,我们可以减轻先前在训练集中记住NovelClass对象作为背景的偏见。 具体来说,利用支持特征映射和掩码注释生成类特定的原型; 并根据查询图像的背景特征自适应生成类不可知原型。 不同于以前的方法[2]、[8]、[12]从支持图像生成类无关原型,我们只从查询特征中提取这些原型,以确保这些原型与查询图像的背景特征之间的语义相似性。 最后,不仅对特定于类的原型和查询特征进行了特征比较,还对不依赖于类的原型和查询特征进行了特征比较。
文章中的特定于类指的是支持集的给出的类
2.3文章贡献
- 提出了一种新的小样本语义分割学习范式。 它不仅学习特定于类的原型和查询特性(在特定于类的分支中)之间的特性比较,还学习不同类的原型和查询特性(在不同类的分支中)之间的特性比较。 据我们所知,我们是第一个提出这种互补特征学习方式,以帮助产生一个无偏见的分割模型在FEW SHOT设置。
- 提出了一个简单而有效的不可知类分支,包括类不可知原型生成和特征对齐。 在实践中,该分支能够自适应地从查询图像的背景中生成多个类不可知的原型,并以自我对比的方式学习特征对齐。
- 我们在PASCAL-5i和COCO-20i数据集上获得了新的最先进的结果,在推断阶段没有额外的参数和计算成本。 我们还广泛展示了本文方法的效力。
2.4网络结构
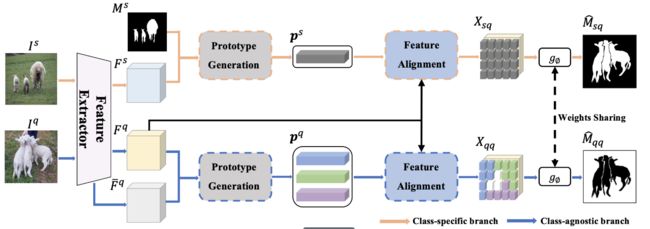
2.5参数名词解释
由于支持集和查询集的前景是已知的,称之为特定于类,而查询集的背景类是不可知的,称之为不可知类

S:支持集 I: 支持集图像 M:支持集掩膜
Q:同上

查询集预测的掩膜
P,F分别表示原型和特征图
以one-shot为例,训练过程可简化为
input:

goal:

θf为超参数,θl为网络可学习 参数
学习一个条件概率质量函数p,来有效分割Iq获得质量好的与mq接近的分割图像
2.6公式介绍
- MAP掩膜平均池化,通过将特征图与掩膜图像计算得到支持集的原型ps

- 将支持集原型reshape之后再与查询集特征进行拼接
![]()
- 使用卷积模板g对融合后的特征进行编码

以下介绍原文中不可知类的原型生成方法公式:
-
查询特征背景分组
文章认为支持集和查询集里面的前景大致相同,特征类似,但是背景缺没有什么必然联系,于是直接利用查询集特征来估计背景原型。这里没有直接通过MAP来获取背景原型,因为文章认为背景中包含的类是复杂的,其中可能包含多个class,所以通过公式4对背景特征进行分类,其中用到了传统的kmeans聚类的方法

-
不同类别的背景簇更新
文章通过聚类之后,会将背景分成k个不同的掩膜,但这些掩膜会包含前景掩膜(聚类的效果不好),所以需要进行删除重叠的部分。见公式6:


第三行为聚类结果
- 将聚类结果再和查询集特征进行MAP计算

以下介绍原文中Feature Alignment for Complete Comparison(用于完全比较的特征对齐: )小节,也就是文章的第二个贡献:利用特定类和不可知类的分支,进行特征对齐。
-
利用查询集直接生成不可知类的映射

-
再用卷积对Xqq进行编码
其中θl和等式3中一样,共享


我们开发了类特定的和类不可知的原型,从而构造了完整的特征对(即XSQ和XQQ),以缓解小样本语义分割中有偏见的分类问题。
这里我的理解是利用一个共享权重的g来对由特定类也就是可知的前景原型来分割得到的结果图和不可知类也就是背景原型来分割得到的结果图,保证这两张图都获得很好的效果(准确且互斥),使这个g也可以很好的分割背景类,以保证这个g不偏向于基类,保证了模型的泛化性
- 损失函数
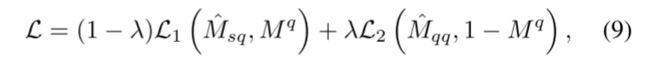
一方面需要保证通过特定类的前景原型与查询集特征进行比较来分割查询集前景得到的Msq与标注图像Mq相近,一方面需要保证通过通过查询集聚类得到的不可知类的背景原型与查询集特征进行比较分割得到背景图像Mqq与取反的标注图像(1-Mq)相近。两者都利用交叉熵函数。
如果其中的Lambda 对于0,那么不可知类将不会发生作用
2.7效果展示

总结
感觉这篇文章跟Learning What Not to Segment: A New Perspective on Few-Shot Segmentation还是有点像的,论文提出的问题也有点类似,都认为传统的fss方法偏向于base class导致模型分割精度差,两篇文章都有分割背景类的步骤,APANET在查询分支上通过聚类得到背景类原型,再对背景进行分割。而Learning What Not to Segment则s设计了一个base learner直接将背景类分割出来。从阅读感觉上来说APANET读起来更加难理解,但是仔细阅读之后,感觉里面提及的关于FSS的知识点更加详细,特别是在讲述查询集与支持集中的背景前景的相互关系。是之前没有了解的。
留一个疑问:
其中APANET一开始提出的前背景正负样本的冲突问题总感觉怪怪的,我感觉baseline中这种不同类以前景或背景交互出现,这样才能保证模型的泛化性,才能保证不偏向于基类吧,但是baseline效果为啥差呢,后续再继续研究相关文献,看看能不能理解。