OneHot数据Embedding的方法
OneHot数据Embedding
之前看的一些推荐模型都是将数据oneHot然后在通过Dense层或者Embedding层将数据稠密化,但一直不太理解具体如何实现。
注意:接下来讲的,不是直接将oneHot转为Embedding,而是将转为oneHot前的原始数据跨过oneHot直接Embedding
oneHot数据主要是将所有的特征值作为列,然后含有该特征值设为1。
eg. [a,b,c,d]四个特征,含有a,c,oneHot表示为[1,0,1,0]
对于我们一般构造的数据,都是这样的:
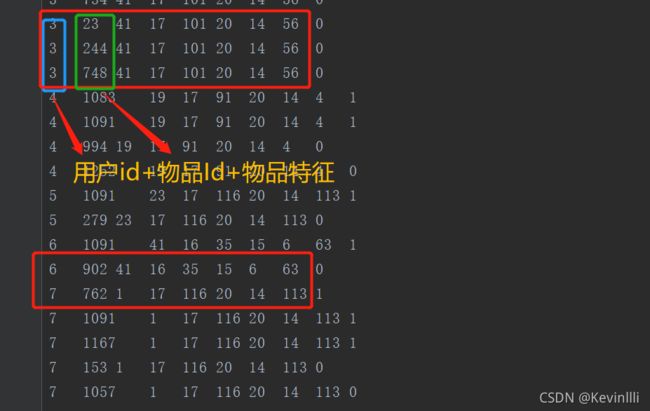
原始的数据中,所有的都是脱敏数值化。
论文中进行oneHot的目的是为了得到唯一值,然后在根据这个唯一值进行Embedding。
根据上面这个思路,我们可以直接用脱敏的数据来表示,将所有的特征值设置唯一的index形式
eg1.
# 统计的数量
用户个数 物品个数 A特征个数 B特征个数
10 20 30 40
-------------------------------
这里面存在每一种值的个数为:
用户个数+物品个数+A特征个数+B特征个数=10+20+30+40=100
按eg1的说法,我们就有100个唯一的值
但我们在输入模型的时候,数据格式是这样的:
[用户index 物品index A特征index B特征index]
a = [4, 6, 16, 31]
or
b = [6, 11, 26, 4]
要方便在上面修改,我们可以先构建一个记录的矩阵offsets
这样可以记录第一个特征的范围,第二个特征的范围,以此往后加,这样就不重复,实现唯一的效果
offsets=[0, 10, 10+20, 10+20+30]
=[0, 10, 30, 60]
现在来唯一化a和b
a + offsets = [4+0, 6+10, 16+30, 31+60]=[4, 16, 46, 91]
b + offsets = [6+0, 11+10, 26+30, 4+60]=[6, 21, 56, 64]
- pytorch代码实现:
'''
field_dims输入格式为[用户index 物品index A特征index B特征index]
例如上面提到的a和b
'''
def __init__(self, field_dims, embed_dim):
super().__init__()
self.embedding = torch.nn.Embedding(sum(field_dims), embed_dim)
'''
(0, *np.cumsum(field_dims)[:-1]得到的是
(0, 用户index, 用户index+物品index, 用户index+物品index+A特征index)
例如上面提到的
offsets=[0, 10, 10+20, 10+20+30]=[0, 10, 30, 60]
'''
self.offsets = np.array((0, *np.cumsum(field_dims)[:-1]), dtype=np.long)
torch.nn.init.xavier_uniform_(self.embedding.weight.data)
def forward(self, x):
'''
new_tensor()可以将原张量中的数据复制到目标张量(数据不共享),同时提供了更细致的属性控制
'''
x = x + x.new_tensor(self.offsets).unsqueeze(0)
return self.embedding(x)