EasyPR中文车牌识别系统开发
EasyPR中文车牌识别系统开发,我主要介绍如何使用开源的EasyPR中文车牌识别系统,我会介绍训练机器学习 SVM 支持向量机和 ANN 人工神经网络模型在车牌识别的应用,并公开训练数据。
目录:
一、Linux平台下EasyPR环境搭建
二、ARM平台下EasyPR环境搭建
三、训练机器学习 SVM 车牌监测算法模型和 ANN 字符识别神经网络模型
四、如何提高字符识别准确率?
五、使用OpenMP多核运算,提高运行速度
EasyPR中文车牌识别系统包括两个部分,但实际上为了更好进行模块化开发,EasyPR被划分成了六个模块,其中每个模块的准确率与速度都影响着整个系统。具体说来,EasyPR中PlateDetect与CharsRecognize各包括三个模块。EasyPR的处理流程,见下图:
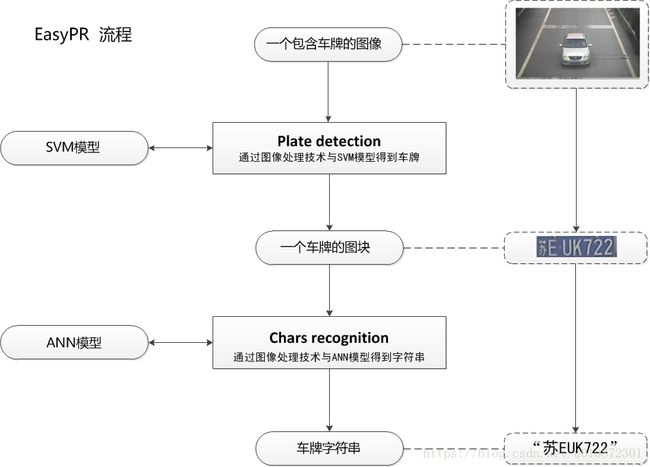
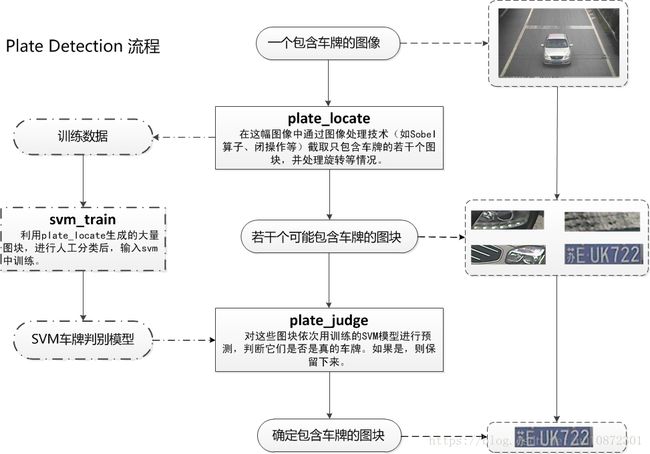
1、PlateDetect包括的是车牌定位,SVM训练,车牌判断三个过程,通过PlateDetect过程我们获得了许多可能是车牌的图块,将这些图块进行手工分类,聚集一定数量后,放入SVM模型中训练,得到SVM的一个判断模型,在实际的车牌过程中,我们再把所有可能是车牌的图块输入SVM判断模型,通过SVM模型自动的选择出实际上真正是车牌的图块。见下图。
2、PlateDetect过程结束后,我们获得一个图片中我们真正关心的部分--车牌。那么下一步该如何处理呢。下一步就是根据这个车牌图片,生成一个车牌号字符串的过程,也就是CharsRecognisze的过程,CharsRecognise过程中,一副车牌图块首先会进行灰度化,二值化,然后使用一系列算法获取到车牌的每个字符的分割图块。获得海量的这些字符图块后,进行手工分类,然后喂入神经网络的MLP模型中,进行训练。在实际的车牌识别过程中,将得到7个字符图块放入训练好的神经网络模型,通过模型来预测每个图块所表示的具体字符,例如图片中就输出了“苏EUK722”, 具体见下图。

至此一个完整的车牌识别过程就结束了,但是在每一步的处理过程中,有许多的优化方法和处理策略。尤其是车牌定位和字符分割这两块,非常重要,它们不仅生成实际数据,还生成训练数据,因此会直接影响到模型的准确性,以及模型判断的最终结果。
好了,下面开始进入平台搭建主题:
一、Linux平台下EasyPR环境搭建
编译opencv3.2,并将lib库文件指定全局环境
//安装cmake及一些依赖库
$ sudo apt-get install cmake
$ sudo apt-get install build-essential libgtk2.0-dev libavcodec-dev libavformat-dev libjpeg.dev libtiff4.dev libswscale-dev libjasper-dev
//从官网下载opencv并解压,cd命令进入opencv的目录:
$ unzip OpenCV-3.2.0.zip
$ cd opencv-3.2.0
$ mkdir build
$ cd build
$ cmake ..
$ sudo make -j8
$ sudo make install
//改成Opencv3.2版本的支持
gaohui@pdg-OptiPlex:~/opencv3.2.0/EasyPR-master$ vim include/easypr/config.h
//#define CV_VERSION_THREE_ZERO
#define CV_VERSION_THREE_TWO
//编译EasyPR
$ cmake .
$ make -j8 二、ARM平台下EasyPR环境搭建
1、交叉编译编译opencv3.2开发环境
$ cd opencv-3.2.0
$ mkdir build
$ cd build
$ vim toolchain.cmake
//输入
###########user defined#############
set( CMAKE_SYSTEM_NAME Linux )
set( CMAKE_SYSTEM_PROCESSOR arm )
set( CMAKE_C_COMPILERarm-none-linux-gnueabi-gcc )
set( CMAKE_CXX_COMPILERarm-none-linux-gnueabi-g++ )
###########user defined#############
set( CMAKE_FIND_ROOT_PATH"/usr/local/arm/opencv-depend" )
set( CMAKE_FIND_ROOT_PATH_MODE_PROGRAMNEVER )
set( CMAKE_FIND_ROOT_PATH_MODE_LIBRARY ONLY)
set( CMAKE_FIND_ROOT_PATH_MODE_INCLUDE ONLY)
######################################
//保存并退出,并编译支持交叉编译链的开发环境
$ cmake-DCMAKE_TOOLCHAIN_FILE=toolchain.cmake ../ 2、解压opencv压缩文件,得到文件夹。
#cmake-gui 打开cmake的gui界面,开始进行配置,配置过程如下图所示:
首先电脑得先安装arm-linux的交叉编译环境,这里就不介绍这个了,直接说重点。
(1)、在终端窗口输入sudo apt-get install cmake-qt-gui下载cmake图形界面
(2)、安装好后在终端窗口输入sudocmake-gui打开cmake的gui界面
(3)、在“where is the source code”中填入电脑中opencv源码的位置,“where to build the binaries”填入生成make编译文件的位置,然后点击configure按钮

(4)、选择最后一项
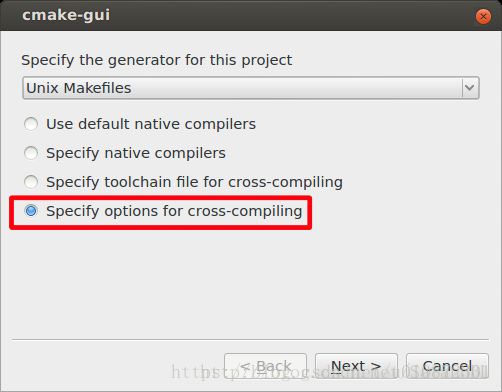
(5)、点击NEXT再跳出的界面中做如下设置
Operating System 选择目标系统Linux
Compilers中选择交叉编译器的gcc和g++
这里注意选择用什么编译,根据不同的编译选择编译命令的路径。
我是使用的arm-oe-linux-gnueabi来编译,找到编译器的安装路径:
gcc:/opt/hisi-linux/x86-arm/arm-histbv310-linux/bin/arm-histbv310-linux-gcc
g++:/opt/hisi-linux/x86-arm/arm-histbv310-linux/bin/arm-histbv310-linux-g++
Target Root选择交叉编译器的路径:/usr/local/arm-linux/arm-oe-linux-gnueabi/
include Mode选择Search only in Target Root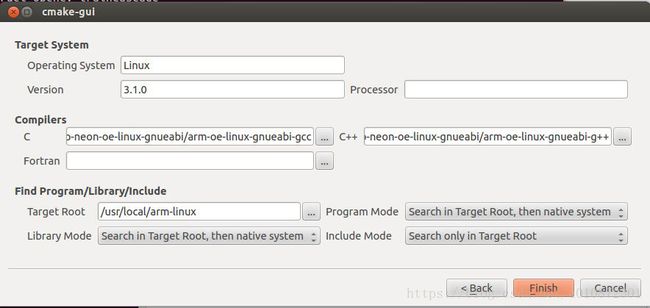
(6)、同时可以将CMAKE_INSTALL_PREFIX和CMAKE_FIND_ROOT_PATH改成你想要的路径,这个路径是opencv最后库文件和头文件的安装路径。确认在不存在其他问题后点击Generate生存Makefile文件,如果前面第三方的问题没有解决这里是会报错而无法生存Makefile。生成的Makefile文件和Cmake配置文件都在 Wher to build the binarier 中设置的文件夹下

(7)、修改编译选项
默认安装目录为 opencv-3.2.0/build/install ,改为 /usr/local/arm/opencv-install
CMAKE_INSTALL_PREFIX /usr/local/arm/opencv-install(提前创建目录)
去掉 WITH_CUDA
去掉 WITH_GTK
去掉 WITH_1394
去掉 WITH_GSTREAMER
去掉 WITH_LIBV4L (因为后面有另外一个WITH_V4L)
去掉 WITH_TIFF
去掉 BUILD_OPENEXR
去掉 WITH_OPENEXR
去掉 BUILD_opencv_ocl
去掉 WITH_OPENCL
根据自己的需要选择编译的选项,有的选项需要安装相应的依赖的库,否则编译会出错
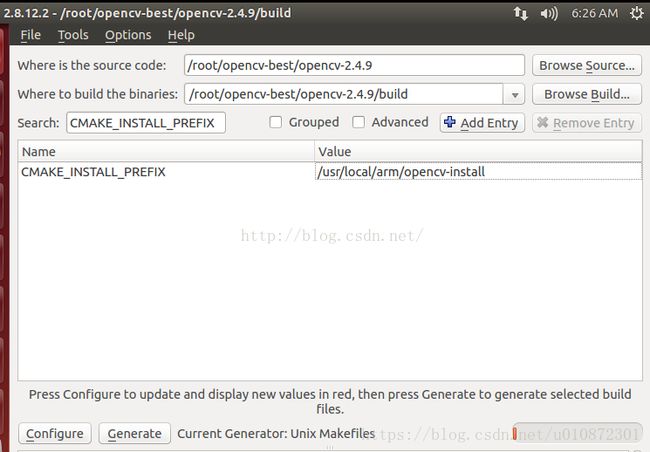
(8)、完成后 Generate ,生成Makefile文件:
修改 CMakeCache.txt, CMAKE_EXE_LINKER_FLAGS原来为空,加上
-lpthread -lrt
$ sodo make -j8
$ make install
3、交叉编译EasyPR-master,进入EasyPR-master修改,支持opencv3.2版本的头文件:
//改成Opencv3.2版本的支持
gaohui@pdg-OptiPlex:~/opencv3.2.0/EasyPR-master$ vim include/easypr/config.h
//#define CV_VERSION_THREE_ZERO
#define CV_VERSION_THREE_TWO
4、修改CMakeList.txt,支持板卡的交叉编译环境:
(1)交叉编译环境的thidrparty /CMakeList.txt文件:
## build CMakeList of the thidrparty.a
cmake_minimum_required(VERSION 3.0.0)
project(thirdparty_arm)
# c++11 required
set(CMAKE_CXX_STANDARD 11)
#set(CMAKE_CXX_STANDARD_REQUIRED ON)
#TODO:告知当前使用的是交叉编译方式,必须配置
SET(CMAKE_SYSTEM_NAME Linux)
#TODO:指定C交叉编译器,必须配置 TODO:或交叉编译环境器使用绝对地址。
SET(CMAKE_C_COMPILER "/opt/hisi-linux/x86-arm/arm-histbv310-linux/bin/arm-histbv310-linux-gcc")
#TODO:指定C++交叉编译器,必须配置 TODO:或交叉编译环境器使用绝对地址。
SET(CMAKE_CXX_COMPILER "/opt/hisi-linux/x86-arm/arm-histbv310-linux/bin/arm-histbv310-linux-gcc")
#TODO:添加头文件路径
include_directories(.)
include_directories("/work/gaohui/install/include/opencv")
include_directories("/work/gaohui/install/include")
#TODO:添加opencv动态链接库路径
LINK_DIRECTORIES("/work/gaohui/install/lib")
# OpenVC3 required
#find_package(OpenCV 3.1.0 REQUIRED)
#TODO: ds add
#set(CV_INCLUDE_DIRS
#-I/home/ds/build/opencv-3.1.0/install/include
#-I/home/ds/build/opencv-3.1.0/install/include/opencv
#)
#where to find header files
#include_directories(${OpenCV_INCLUDE_DIRS})
#include_directories(${CV_INCLUDE_DIRS})
#sources to be compiled
set(SOURCE_FILES
xmlParser/xmlParser.cpp
textDetect/erfilter.cpp
LBP/helper.cpp
LBP/lbp.cpp
mser/mser2.cpp
)
# pack objects to static library
add_library(thirdparty_arm STATIC ${SOURCE_FILES})(2)交叉编译EasyPR-master-arm下的CMakeList.txt文件:
## build CMakeList of the executable file
cmake_minimum_required(VERSION 3.0.0)
project(easypr)
# c++11 required
#set(CMAKE_CXX_STANDARD 11) #c++11标准也可以在这里设置
#set(CMAKE_CXX_STANDARD_REQUIRED ON)
#使用OpenMP,CPU加速
FIND_PACKAGE( OpenMP REQUIRED)
if(OPENMP_FOUND)
message("OPENMP FOUND")
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS}")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} ${OpenMP_EXE_LINKER_FLAGS}")
endif()
#TODO:告知当前使用的是交叉编译方式,必须配置
SET(CMAKE_SYSTEM_NAME Linux)
#TODO:指定C交叉编译器,必须配置 TODO:或交叉编译环境器使用绝对地址。
SET(CMAKE_C_COMPILER "/opt/hisi-linux/x86-arm/arm-histbv310-linux/bin/arm-histbv310-linux-gcc")
#TODO:指定C++交叉编译器,必须配置 TODO:或交叉编译环境器使用绝对地址。
SET(CMAKE_CXX_COMPILER "/opt/hisi-linux/x86-arm/arm-histbv310-linux/bin/arm-histbv310-linux-g++")
#TODO :添加从c++11
add_compile_options(-std=c++11)
#if (CMAKE_SYSTEM_NAME MATCHES "Darwin")
# set(CMAKE_PREFIX_PATH ${CMAKE_PREFIX_PATH} "/usr/local/opt/opencv3")
#endif ()
# OpenVC3 required
find_package(OpenCV 3.2.0 REQUIRED)
# where to find header files
include_directories(.)
include_directories(include)
#include_directories(${OpenCV_INCLUDE_DIRS})
#TODO:添加头文件路径
include_directories("/work/gaohui/install/include/opencv")
include_directories("/work/gaohui/install/include")
#TODO:添加opencv动态链接库路径
LINK_DIRECTORIES("/work/gaohui/install/lib")
# sub directories
add_subdirectory(thirdparty)
# sources to be compiled
set(SOURCE_FILES
src/core/core_func.cpp
src/core/chars_identify.cpp
src/core/chars_recognise.cpp
src/core/chars_segment.cpp
src/core/feature.cpp
src/core/plate_detect.cpp
src/core/plate_judge.cpp
src/core/plate_locate.cpp
src/core/plate_recognize.cpp
src/core/params.cpp
src/train/ann_train.cpp
src/train/annCh_train.cpp
src/train/svm_train.cpp
src/train/train.cpp
src/train/create_data.cpp
src/util/util.cpp
src/util/program_options.cpp
src/util/kv.cpp
)
# pack objects to static library
add_library(easypr STATIC ${SOURCE_FILES})
if (CMAKE_SYSTEM_NAME MATCHES "Darwin")
set(EXECUTABLE_NAME "demo_darwin_amd64")
elseif (CMAKE_SYSTEM_NAME MATCHES "Linux")
set(EXECUTABLE_NAME "demo_arm")
endif ()
# test cases
add_executable(${EXECUTABLE_NAME} test/main.cpp)
# link opencv libs,指定在链接目标文件的时候需要链接到外部库,其效果类似gcc的编译参数“-l”,可以解决外部库的依赖问题。
target_link_libraries(${EXECUTABLE_NAME} easypr thirdparty_arm -lopencv_shape -lopencv_stitching -lopencv_objdetect -lopencv_superres -lopencv_videostab -lopencv_calib3d -lopencv_features2d -lopencv_highgui -lopencv_videoio -lopencv_imgcodecs -lopencv_video -lopencv_photo -lopencv_ml -lopencv_imgproc -lopencv_flann -lopencv_core -ldl -lm -lpthread -lrt)
# MESSAGE(${CMAKE_BINARY_DIR}/../)
SET_TARGET_PROPERTIES(${EXECUTABLE_NAME} PROPERTIES RUNTIME_OUTPUT_DIRECTORY "${CMAKE_BINARY_DIR}/../")
如果生成C++ so库文件修改:
进入EasyPR/,修改CMakeLists.txt,找到
add_library(easypr STATIC $(SOURCE_FILES))
STATIC改为SHARED,修改为:
add_library(easypr SHARED ${SOURCE_FILES})
同样,进入Easy/thirdparty,修改CMakelists.txt,找到最后一行
add_library(thirdparty STATIC ${SOURCE_FILES})
修改为:
add_library(thirdparty SHARED ${SOURCE_FILES})
build.sh编译,EasyPR/_build下找到libeasypr.so;
/EasyPR/_build/thirdparty下找到libthirdparty.so三、训练机器学习 SVM 车牌监测算法模型和 ANN 字符识别神经网络模型
(1)训练机器学习 SVM 车牌监测算法模型
为了加快训练模型的速度,我将SVM模型和ANN模型训练放在服务器上,
在easypr的主目录下面新建了一个tmp文件夹,并且把svm.7z解压得到的svm文件夹移动到tmp文件夹下面,
则可以执行 $ ./demo svm --plates=tmp/svm --svm=tmp/svm_hist.xml,生成得到的tmp文件夹下面的svm_hist.xml就是训练好的模型,
替换model/svm_hist.xml就可以达到替换新模型的目的,替换前请先备份原始模型。
如何将自己的车牌图片生成车牌图块放入到tmp/svm目录中呢?
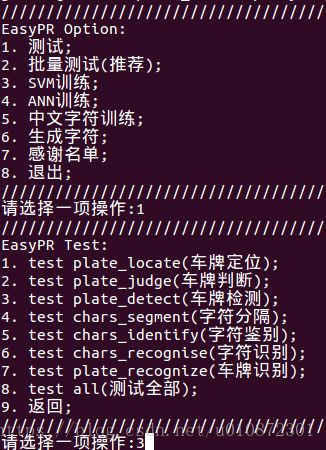
修改test/plate.hpp的代码,将车牌图片放在resources/image/test目录下,指定生成的车牌和非车牌图块放在resources/image/tmp/Result目录下,执行代码选择:
1. 测试;--》3. test plate_detect(车牌检测);
喝杯茶的功夫,此时会将所有的图片分割成图块(如何生成准确的车牌图块,后面会说),再人工分类,车牌目录我的经验把数据的70%用来训练,30%用来测试模型;非车牌以此类推。放入svm目录下,有车牌目录和非车牌目录,训练生成svm_hist.xml模型。
车牌和非车牌图块大小是136*36,否则会报错。
int test_plate_detect()
{
cout << "test_plate_detect" << endl;
int result;
static int ji = 0;
auto files = Utils::getFiles("resources/image/test");
int size = files.size();
if (0 == size) {
cout << "No File Found in general_test/native_test!" << endl;
return 0;
}
for (int i = 0; i < size; i++) {
string filepath = files[i].c_str();
Mat src = imread(filepath);
vector resultVec;
CPlateDetect pd;
pd.setPDLifemode(true);
result = pd.plateDetect(src, resultVec);
if (result == 0) {
size_t num = resultVec.size();
for (size_t j = 0; j < num; j++) {
CPlate resultMat = resultVec[j];
std::stringstream ss1(std::stringstream::in | std::stringstream::out);
ss1 << "resources/image/tmp/Result/imgplate" << ji++ << ".jpg";
imwrite(ss1.str(), resultMat.getPlateMat());
}
}
}
return result;
} 
(2)ANN 字符识别神经网络模型
在easypr的主目录下面新建了一个tmp文件夹,并且把ann.7z解压得到的ann文件夹移动到tmp文件夹下面,
则可以执行 $ ./demo ann --chars=tmp/ann --ann=tmp/ann.xml,生成得到的tmp文件夹下面的ann.xml就是训练好的模型,
替换model/ann.xml就可以达到替换新模型的目的,替换前请先备份原始模型。
如何将自己的车牌图块生成字符放入到tmp/ann目录中呢?
修改test/chars.hpp的代码,将车牌图块放在resources/image/test1目录下,指定生成的字符放在resources/image/tmp/Chars目录下,执行代码选择:
1. 测试;--》4. test chars_segment(字符分隔);
这需要一定时间,此时会将所有的图块分割成字符(如何生成准确的字符,后面会说),再人工分类(非常耗时),放入ann目录下,训练生成ann.xml模型。
车牌和非车牌图块大小是20*20,否则会报错。
int test_chars_segment()
{
std::cout << "test_chars_segment" << std::endl;
static int ji = 0;
int result;
auto files = Utils::getFiles("resources/image/test1");
int size = files.size();
if (0 == size) {
cout << "No File Found in general_test/native_test!" << endl;
return 0;
}
for (int i = 0; i < size; i++) {
string filepath = files[i].c_str();
Mat src = imread(filepath);
std::vector resultVec;
CCharsSegment plate;
result = plate.charsSegment(src, resultVec);
if (result == 0) {
size_t num = resultVec.size();
for (size_t j = 0; j < num; j++) {
cv::Mat resultMat = resultVec[j];
std::stringstream ss2(std::stringstream::in | std::stringstream::out); //gh
ss2 << "resources/image/tmp/Chars/imgchar" << ji++ << ".jpg";
imwrite(ss2.str(), resultMat);
}
}
}
return result;
} 四、如何提高字符识别准确率?
车牌号码识别主要包括图像灰度拉伸、牌照定位分割、二值化、字元切割、字元识别等5个模块。识别原理:识别模块通过对图像的智能分析,提取出包含车牌的相关区域,对车辆行进过程中的图像进行逐帧处理和识别,系统可捕获多个有效帧,对每一帧识别处理,经过预处理,将车牌切割成各个字符单元,并对每个字符单元进行分类识别。
系统能识别号牌字符包括:数字:0~9;字母:A~Z;31个省市简称:京、津、晋、冀、蒙、辽、吉、黑、沪、苏、浙、皖、闽、赣、鲁、豫、鄂、湘、粤、桂、琼、川、贵、云、藏、陕、甘、青、宁、新、渝。。。
提高字符识别准确率:
(1)保证你的SVM模型内的车牌图块数据准确,检测字符单元的字符,去除目录下的错误字符和人为不能判断的字符,这个过程非常耗时后面我把优化后的svm和ann数据公开。
(2)保证你有足够大的车牌图块和字符数据,来训练SVM和ANN模型。
(3)将固定位置的摄像头在白天、大角度、逆光、污损、夜间、下雨天的抓拍出来车牌图片分类,进行SVM和ANN模型参数优化。
(4)最后将31个省市简称中文字符,训练成中文模型,进行ANN中文模型参数优化。
(5)对于汉字识别率不足,虽然做了很多优化,在高鲁棒性的场景中完成精确识别。这个问题只有替换ANN到CNN才可能解决(主流的商业软件:火眼、文通,已经使用CNN),咨询过作者的想法:EasyPR支持高性能CPU计算且轻量的框架,所以如果使用深度学习框架Caffe会过于笨重,TensorFlow在C++端集成困难!
-----车牌图块------------------------------
std::cout << "Run \"demo svm\" for more usage." << std::endl;
{
easypr::SvmTrain svm("tmp/svm", "tmp/svm.xml");
svm.train();
}
or
easypr::SvmTrain svm(parser->get("plates")->c_str(), parser->get("svm")->c_str());
svm.train();
||
SvmTrain::SvmTrain(const char* plates_folder, const char* xml)
: plates_folder_(plates_folder), svm_xml_(xml)
||
void SvmTrain::train()
//SVM调优
svm_ = cv::ml::SVM::create();
svm_->setType(cv::ml::SVM::C_SVC);
svm_->setKernel(cv::ml::SVM::RBF);//CvSVM::RBF 径向基函数,也就是高斯核
svm_->setDegree(0.1); //0
// 1.4 bug fix: old 1.4 ver gamma is 1
svm_->setGamma(0.1); // 1//old 1.1
svm_->setCoef0(0.1); // 0
svm_->setC(1);
svm_->setNu(0.1); // 0
svm_->setP(0.1); // 0
svm_->setTermCriteria(cvTermCriteria(CV_TERMCRIT_ITER, 20000, 0.0001)); // 1000, 0.01 提高图块分类准确率 // 100000, 0.0001 old1.1 训练时间较长
||
void SvmTrain::prepare() //图块分类
||
cv::Ptr SvmTrain::tdata()
cv::Mat feature;
extractFeature(image, feature);
feature = feature.reshape(1, 1);
return cv::ml::TrainData::create(samples_, cv::ml::SampleTypes::ROW_SAMPLE, responses_);
||
void SvmTrain::test()
if (test_file_list_.empty()) {
this->prepare();
}
//下面测试SVM的准确率,回归率以及FScore
-----字符识别-------------------------------------------------
std::cout << "Run \"demo ann\" for more usage." << std::endl;
{
easypr::AnnTrain ann("tmp/ann", "tmp/ann.xml");
ann.train();
}
or
AnnTrain::AnnTrain(const char* chars_folder, const char* xml)
: chars_folder_(chars_folder), ann_xml_(xml)
ann.train();
||
AnnTrain::AnnTrain(const char* chars_folder, const char* xml)
: chars_folder_(chars_folder), ann_xml_(xml)
||
void AnnTrain::train()
//ANN调优
ann_->setLayerSizes(layers);
ann_->setActivationFunction(cv::ml::ANN_MLP::SIGMOID_SYM, 1, 1);
ann_->setTrainMethod(cv::ml::ANN_MLP::TrainingMethods::BACKPROP);
//ann_->setTermCriteria(cvTermCriteria(CV_TERMCRIT_ITER, 30000, 0.0001));
ann_->setTermCriteria(cvTermCriteria(CV_TERMCRIT_ITER, 30000, 0.0001));
ann_->setBackpropWeightScale(0.1);
ann_->setBackpropMomentumScale(0.1);
||
cv::Ptr AnnTrain::sdata(size_t number_for_count)
||
cv::Mat getSyntheticImage(const Mat& image)
生成数据:
result = translateImg(result, ran_x, ran_y);
OR
result = rotateImg(result, angle);
||
Mat charFeatures2
return cv::ml::TrainData::create(samples_, cv::ml::SampleTypes::ROW_SAMPLE,
train_classes);
||
void AnnTrain::test()
std::pair AnnTrain::identify(cv::Mat input)
if (type == 0) ch = identify(img);
if (type == 1) ch = identifyChinese(img);
||
cv::Mat feature = charFeatures2(input, kPredictSize); 最后公布我优化的车牌识别准确率,也许在不同环境下的识别准确率会有不同,但最终都在95%以上,符合项目工程需求:

五、使用OpenMP多核运算,提高运行速度
因为程序运行的速度和硬件平台、模型算法有很大关系:我们的硬件平台海思板卡型号Hi3798,4核64位Cortex A53处理器,GPU的架构Migard,型号MaliT720,
支持的规格OpenGL ES3.1、OpenCL1.1。
Linux下使用clock计时函数(clock_t t1=clock()),查找耗时的算法:评判指标、颜色定位(sobel算法)、车牌定位(sobel算法)、文字定位(MSER算法)。
如何对CPU和GPU加速呢?
1、对多核CPU使用:tbb和OpenMP
2、对图形GPU加速:OpenGL、OpenCL
通过对耗时算法的耗时分析,使用OpenMP多核加速,来提高算法整体的效率。
(1)在交叉编译EasyPR-master-arm下的CMakeList.txt文件中添加
FIND_PACKAGE( OpenMP REQUIRED)
if(OPENMP_FOUND)
message("OPENMP FOUND")
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS}")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} ${OpenMP_EXE_LINKER_FLAGS}")
endif()(2)主要关心的是在同一时间将一个任务划分成多个然后用多线程去完成。它们之间相互并不依赖,这将有利于分配不同的任务给不同的线程去执行。在循环结构可以进行并行(#pragma omp parallel for),可以进行分段并行(#pragma omp parallel sections)。
你还可以参考:
1、源码地址:https://github.com/cnhui/EasyPR-Chinese-license-plate-recognition-system
2、中文车牌识别系统,源码Git地址为:https://github.com/liuruoze/EasyPR
3、EasyPR--中文开源车牌识别系统 开发详解(1): http://www.cnblogs.com/subconscious/p/4001896.html