scrapy日志(log)中含有None行的处理办法(原因)
scrapy日志(log)中含有None行的处理办法(原因),本文主要介绍出现的原因以及不太合适的解决办法,为什么说不太合适,因为需要改官方源码或者日志等级。
在scrapy爬虫中,在debug的日志状态中,会出现类似下方含有None行的情况:

1. 首先来说出现这个问题的浅层次原因
- a. 出现的原因是我们再pipelines.py文件中,被使用的管道类中的“process_item”方法没有返回值或者返回值为None,比如下方:
class TestScrapyPipeline:
def process_item(self, item, spider):
# 此处方法没有返回值
print(item)
class TestScrapyPipeline:
def process_item(self, item, spider):
# 此处方法返回值为None
print(item)
return None
以上两种方法出现的结果分别是(“{'status': 200}”是print的结果,不属于日志范畴),结果中仍然会出现None

- b.如果对返回值进行修改的话,如下,所以这个日志值和“process_item”方法的返回值有关的:
class TestScrapyPipeline:
def process_item(self, item, spider):
# 修改方法返回值
print(item)
return {"test": item}
2. 再来说一下官方源码的原因
至于第1点中出现的结果,究其原因是scrapy源码对这个返回值进行了日志输出。scrapy的源码则是“scrapy.logformatter”,此处贴上原因(注意,此处的item是“process_item”的返回值,不是process_item的参数item),也可以看到当删除item和item处理错误时都会输出item相关数据:
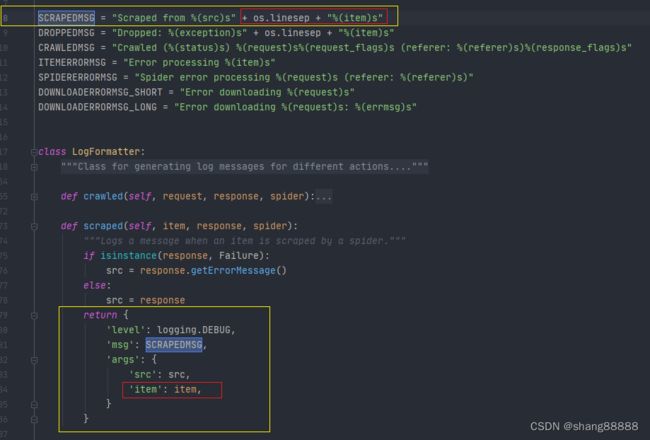
3. 最后来说下解决办法
- 修改日志等级
根据以上源码和测试可以看出,只有在日志等级为“DEBUG”时才会出现日志输出item的情况,所以可以将“settings.py”中的日志等级修改为“INFO”或者更高等级,如“LOG_LEVEL="INFO"”,此时DUBUG等级的日志就不会被输出。
- 修改scrapy源码
也即是将日志输出item的代码删除,即使上方源码图片中的红框部分,最终日志结果如下:

可以看到 ,没有None或者item的一行了。
最后再说明一下,日志等级为“DEBUG”时,是在调试或者测试时用于了解各个环节的情况,所以会输出item(None)也是正常的,但在真正的生产环境中,日志等级可以设置为“INFO”等较高等级的。