Fate集群 | 基于MNIST数据集的模型训练+模型预测 详细过程
文章目录
-
-
- 一、获取数据集并简单处理
-
- 1、分割数据集
- 2、拷贝数据集
- 二、模型训练
-
- 1、上传数据
-
- 1)host方
- 2)guest方
- 2、构建模型
- 3、修改配置文件
-
- 1)DSL简介
- 2)DSL配置文件
- 3)运行配置文件
- 4、提交任务,训练模型
- 三、模型预测
-
- 1、修改配置文件
- 2、模型部署
- 3、运行配置文件
- 4、进行模型预测
-
基于Fate的 DSL V2,需要提前在两台Ubuntu 16.04虚拟机上完成fate 集群部署,部署过程可以参考 使用Kubefate1.6在两台Ubuntu16.04虚拟机上部署Fate集群,本文详细记录了从下载数据集开始,到模型训练、模型预测的操作过程。由于网络上可以参考的资料少之又少,官方文档对我这样的新手又是及其不友好,看了好几遍也根本不知道我的错误如何解决。现在终于可以顺利完成了,把过程记录下来供大家参考。
一、获取数据集并简单处理
使用MNIST数据集进行联邦学习,MNIST是手写数字识别的数据集。从kaggle下载csv格式的数据集。
FATE训练时需要数据集有id,MNIST数据集里有6w条数据,模拟横向联邦学习。
1、分割数据集
把数据集分为两个各有3w条记录的数据集。
#第一行最前面加上id,第二行开始加序号,并用逗号作为分隔符。
awk -F'\t' -v OFS=',' '
NR == 1 {print "id",$0; next}
{print (NR-1),$0}' mnist_train.csv > mnist_train_with_id.csv
#将表头的label替换成y,在FATE里label的名字通常为y。
sed -i "s/label/y/g" mnist_train_with_id.csv
#将mnist_train_with_id.csv分割,每一个文件有30001行(一行标题和30000行数据)。会生成两个文件:mnist_train_3w.csvaa和mnist_train_3w.csvab。将两个文件重命名
split -l 30001 mnist_train_with_id.csv mnist_train_3w.csv
mv mnist_train_3w.csvaa mnist_train_3w_a.csv
mv mnist_train_3w.csvab mnist_train_3w_b.csv
sed -i "`cat -n mnist_train_3w_a.csv |head -n 1`" mnist_train_3w_b.csv
2、拷贝数据集
将两个文件(a、b)拷贝到两台机器的对应目录里:
/data/projects/fate/confs-
/shared_dir/examples/data
注:
#以机器A示例,拷贝文件的命令
cp mnist_train_3w_a.csv /data/projects/fate/confs-10001/shared_dir/examples/data/
可能用到的:
#将文件拷贝到另一台机器的桌面上
scp mnist_train_3w_b.csv [email protected]:/home/xxx/Desktop
二、模型训练
1、上传数据
1)host方
-
进入目录
/data/projects/fate/confs-
/shared_dir/examples/dsl/v2/homo_nn 注:
需要替换成自己节点的party id -
新建
upload_data_host.json:
{
"file": "examples/data/mnist_train_3w_a.csv",
"head": 1,
"partition": 10,
"work_mode": 1,
"table_name": "homo_mnist_host",
"namespace": "homo_mnist_host"
}
- 保存文件后上传数据,首先进入host的python容器:
docker exec -it confs-<partyID>_python_1 bash
- 进入容器后,上传数据
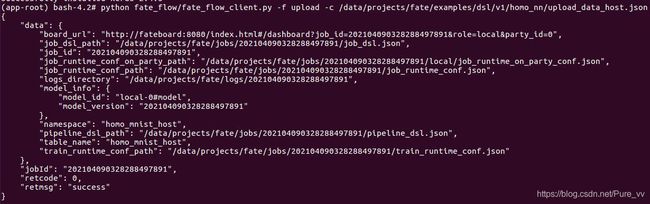
python fate_flow/fate_flow_client.py -f upload -c /data/projects/fate/examples/dsl/v2/homo_nn/upload_data_host.json
数据上传成功的截图
2)guest方
- 同理,进入对应目录:
/data/projects/fate/confs-<partyID>/shared_dir/examples/dsl/v2/homo_nn
- 新建
upload_data_guest.json
{
"file": "examples/data/mnist_train_3w_b.csv",
"head": 1,
"partition": 10,
"work_mode": 1,
"table_name": "homo_mnist_guest",
"namespace": "homo_mnist_guest"
}
注意file,table_name和namespace的变化
- 上传数据,过程同上
2、构建模型
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
model = Sequential()
model.add(Dense(512,activation='relu',input_shape=(784,)))
model.add(Dense(256,activation='relu'))
model.add(Dense(10,activation='softmax'))
//得到json格式的模型:
json = model.to_json()
print(json)
注:进入python容器之后,没安装tensorflow和keras的话需要进行安装(如:pip install tensorflow),之后输入python,进入python解释器,直接敲上面的代码即可。
获取到模型的json格式,一会要用到
{"class_name": "Sequential", "config": {"name": "sequential", "layers": [{"class_name": "InputLayer", "config": {"batch_input_shape": [null, 784], "dtype": "float32", "sparse": false, "ragged": false, "name": "dense_input"}}, {"class_name": "Dense", "config": {"name": "dense", "trainable": true, "batch_input_shape": [null, 784], "dtype": "float32", "units": 512, "activation": "relu", "use_bias": true, "kernel_initializer": {"class_name": "GlorotUniform", "config": {"seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}, {"class_name": "Dense", "config": {"name": "dense_1", "trainable": true, "dtype": "float32", "units": 256, "activation": "relu", "use_bias": true, "kernel_initializer": {"class_name": "GlorotUniform", "config": {"seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}, {"class_name": "Dense", "config": {"name": "dense_2", "trainable": true, "dtype": "float32", "units": 10, "activation": "softmax", "use_bias": true, "kernel_initializer": {"class_name": "GlorotUniform", "config": {"seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}]}, "keras_version": "2.4.0", "backend": "tensorflow"}
3、修改配置文件
1)DSL简介
为了让任务模型的构建更加灵活,目前 FATE 使用了一套自定的领域特定语言 (DSL) 来描述任务。在 DSL 中,各种模块(例如数据读写 data_io,特征工程 feature-engineering, 回归 regression,分类 classification)可以通向一个有向无环图 (DAG) 组织起来。通过各种方式,用户可以根据自身的需要,灵活地组合各种算法模块。
2)DSL配置文件
注:可以使用示例文件test_homo_dnn_multi_layer_dsl.json,我是新建的文件m_dsl.json
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"dataio_0": {
"module": "DataIO",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"homo_nn_0": {
"module": "HomoNN",
"input": {
"data": {
"train_data": [
"dataio_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
}
}
}
3)运行配置文件
注:不是运行配置文件,而是另外一个配置文件,这个文件叫做,运行配置文件(Submit Runtime Conf),可参考示例文件test_homo_dnn_multi_layer_conf.json 我是新建 m_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 10002
},
"role": {
"arbiter": [
10001
],
"host": [
10001
],
"guest": [
10002
]
},
"job_parameters": {
"common": {
"work_mode": 1,
"backend": 0
}
},
"component_parameters": {
"common": {
"dataio_0": {
"with_label": true
},
"homo_nn_0": {
"encode_label":true,
"max_iter": 10,
"batch_size": -1,
"early_stop": {
"early_stop": "diff",
"eps": 0.0001
},
"optimizer": {
"learning_rate": 0.05,
"decay": 0.0,
"beta_1": 0.9,
"beta_2": 0.999,
"epsilon": 1e-07,
"amsgrad": false,
"optimizer": "Adam"
},
"loss": "categorical_crossentropy",
"metrics": [
"Hinge",
"accuracy",
"AUC"
],
"nn_define": {"class_name": "Sequential", "config": {"name": "sequential", "layers": [{"class_name": "InputLayer", "config": {"batch_input_shape": [null, 784], "dtype": "float32", "sparse": false, "ragged": false, "name": "dense_input"}}, {"class_name": "Dense", "config": {"name": "dense", "trainable": true, "batch_input_shape": [null, 784], "dtype": "float32", "units": 512, "activation": "relu", "use_bias": true, "kernel_initializer": {"class_name": "GlorotUniform", "config": {"seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}, {"class_name": "Dense", "config": {"name": "dense_1", "trainable": true, "dtype": "float32", "units": 256, "activation": "relu", "use_bias": true, "kernel_initializer": {"class_name": "GlorotUniform", "config": {"seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}, {"class_name": "Dense", "config": {"name": "dense_2", "trainable": true, "dtype": "float32", "units": 10, "activation": "softmax", "use_bias": true, "kernel_initializer": {"class_name": "GlorotUniform", "config": {"seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}]}, "keras_version": "2.4.0", "backend": "tensorflow"},
"config_type": "keras"
}
},
"role": {
"guest": {
"0": {
"dataio_0": {
"with_label": true,
"output_format": "dense"
},
"reader_0": {
"table": {
"name": "homo_mnist_guest",
"namespace": "homo_mnist_guest"
}
}
}
},
"host": {
"0": {
"dataio_0": {
"with_label": true
},
"reader_0": {
"table": {
"name": "homo_mnist_host",
"namespace": "homo_mnist_host"
}
}
}
}
}
}
}
说一下要改的和要注意的地方:
-
initiator,任务发起方,根据自己情况更改
-
role,角色定义部分,要根据自己部署的party id修改
-
job_parameters.common.work_mode 0表示单机版,1表示集群版
-
component_parameters.common.homo_nn_0下面增加
"encode_label":true,,表示使用独热编码,否则一会训练时会发生错误
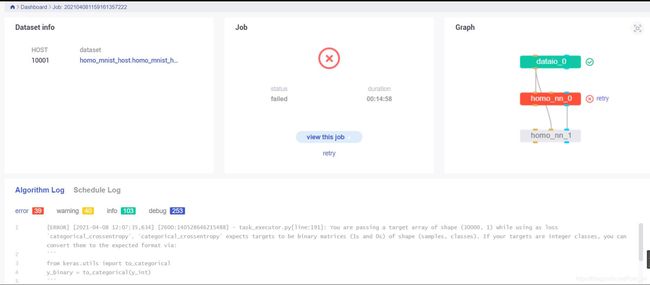
-
component_parameters.common.homo_nn_0.nn_define 把刚才模型的json格式放上
-
component_parameters.role里面guest 和host的
name和namespace根据上传数据时所定义的名字进行修改,这里按照我之前上传的配置json进行对应修改。
4、提交任务,训练模型
将新建(或修改后)的m_dsl.json和m_conf.json文件保存后,进行任务的提交,进入python容器(命令行显示(app-root) bash-4.2# )后,输入下面命令提交任务:
python fate_flow/fate_flow_client.py -f submit_job -c /data/projects/fate/examples/dsl/v2/homo_nn/m_conf.json -d /data/projects/fate/examples/dsl/v2/homo_nn/m_dsl.json
job提交成功截图:
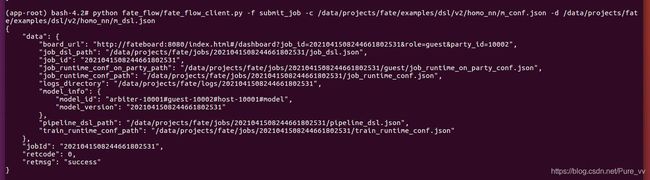
提交后可以在fate board(http://机器IP地址:8080/)可视化的查看任务进度,点击红框标注位置可以看到任务更为详细的信息
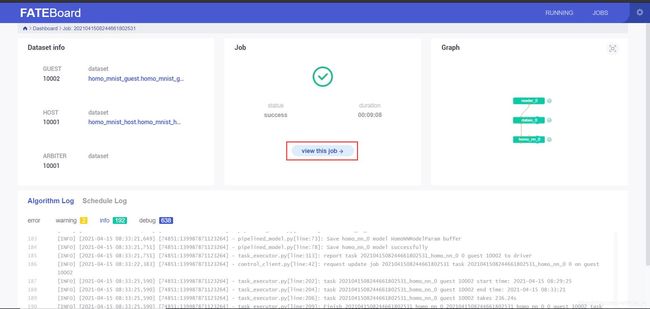
三、模型预测
进入python容器:
docker exec -it confs-<partyID>_python_1 bash
由于要使用flow命令行来进行模型部署,如果没安装的话,先安装一下fate client
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ fate_client
flow初始化
flow init --ip 192.168.xxx.xxx --port 9380

1、修改配置文件
可以使用示例文件test_homo_dnn_multi_layer_predict_dsl.json,我新建了p_dsl.json
{
"components": {
"dataio_0": {
"input": {
"data": {
"data": [
"reader_0.data"
]
},
"model": [
"pipeline.dataio_0.model"
]
},
"module": "DataIO",
"output": {
"data": [
"data"
]
}
},
"homo_nn_0": {
"input": {
"data": {
"test_data": [
"dataio_0.data"
]
},
"model": [
"pipeline.homo_nn_0.model"
]
},
"module": "HomoNN",
"output": {
"data": [
"data"
]
}
},
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
}
}
}
2、模型部署
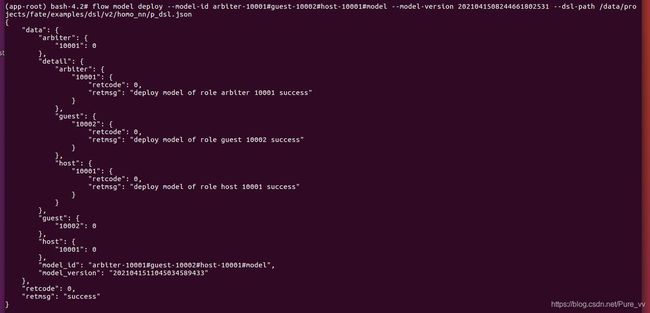
根据上一次训练的model version和model id部署模型,指定新建好的p_dsl.json文件
flow model deploy --model-id arbiter-10001#guest-10002#host-10001#model --model-version 2021041508244661802531 --dsl-path /data/projects/fate/examples/dsl/v2/homo_nn/p_dsl.json
部署完成截图:
3、运行配置文件
可以参考示例文件test_homo_dnn_multi_layer_predict_conf.json,我新建了文件p_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 10002
},
"role": {
"arbiter": [
10001
],
"host": [
10001
],
"guest": [
10002
]
},
"job_parameters": {
"common": {
"work_mode": 1,
"backend": 0,
"job_type": "predict",
"model_id": "arbiter-10001#guest-10002#host-10001#model",
"model_version": "2021041511045034589433"
}
},
"component_parameters": {
"role": {
"guest": {
"0": {
"reader_0": {
"table": {
"name": "homo_mnist_test",
"namespace": "homo_mnist_test"
}
}
}
},
"host": {
"0": {
"reader_0": {
"table": {
"name": "homo_mnist_test",
"namespace": "homo_mnist_test"
}
}
}
}
}
}
}
注:
-
job_parameters.model_id和model_version要根据自己的模型修改,注意是部署之后输出信息中的对应信息!!
-
component_parameters下host和guest的table
name和namespace要注意修改,下面给出我的test数据集准备过程:类似于之前的上传数据,新建
upload_data_test.json,并处理数据集awk -F'\t' -v OFS=',' ' NR == 1 {print "id",$0; next} {print (NR-1),$0}' mnist_test.csv > mnist_test_with_id.csv sed -i "s/label/y/g" mnist_test_with_id.csv拷贝到这个路径下,然后上传数据
/data/projects/fate/confs-
/shared_dir/examples/data 新建
upload_data_test.json{ "file": "examples/data/mnist_test_with_id.csv", "head": 1, "partition": 10, "work_mode": 1, "table_name": "homo_mnist_test", "namespace": "homo_mnist_test" }注意file,table_name和namespace的变化
保存文件后上传数据,首先进入host的python容器:
docker exec -it confs-<partyID>_python_1 bash进入容器后,上传数据
python fate_flow/fate_flow_client.py -f upload -c /data/projects/fate/examples/dsl/v2/homo_nn/upload_data_test.json注:我在host和guest双方都进行了数据上传工作,貌似不需要这样,host方上传即可
4、进行模型预测
guest方发起模型预测任务
python fate_flow/fate_flow_client.py -f submit_job -c /data/projects/fate/examples/dsl/v2/homo_nn/p_conf.json -d /data/projects/fate/examples/dsl/v2/homo_nn/p_dsl.json
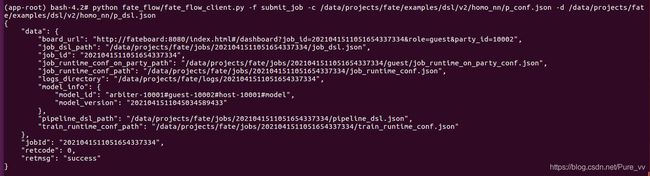
可以在fate board观察到 job 的进度

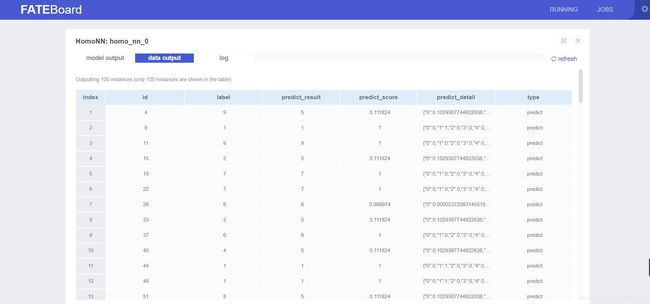
点击view this job 可以看到更详细的信息

点击模块后,再点击view the outputs可以看到更加详细的模块输入输出状况
参考文章:
官方文档
使用FATE进行图片识别的深度神经网络联邦学习
(四)微众Fate-横向联邦学习-预测
fate框架找不到 flow 命令