Fate横向联邦学习-训练评估
1. 准备上传数据
我们直接使用Fate提供的案例数据目录在examples/data/breast_homo_guest.csv、examples/data/breast_homo_host.csv、
这里上传数据需要准备host以及guest两方的上传数据
根据官方解释在Fate的概念中分成3种角色,Guest、Host、Arbiter
Guest表示数据应用方,Host是数据提供方,在纵向算法中,Guest往往是有标签y的一方。arbiter是用来辅助多方完成联合建模的,主要的作用是用来聚合梯度或者模型,比如纵向lr里面,各方将自己一半的梯度发送给arbiter,然后arbiter再联合优化等等,arbiter还参与以及分发公私钥,进行加解密服务等等。一般是由数据应用方Guest发起建模流程。
2.编写上传数据配置upload_data_role.json
编写host的上传配置文件upload_data_host.json
{
"file": "examples/data/breast_homo_host.csv",
"head": 1,
"partition": 10,
"work_mode": 0,
"namespace": "homo_breast_host",
"table_name": "homo_breast_host"
}
#1.5.0以后版本
{
"file": "examples/data/breast_homo_host.csv",
"head": 1,
"partition": 10,
"work_mode": 0,
"namespace": "experiment",
"table_name": "breast_homo_host"
}
字段说明:
- file: 文件路径
- head: 指定数据文件是否包含表头,0 表示不需要 1 表示需要
- partition: 指定用于存储数据的分区数
- work_mode: 指定工作模式,0代表单机版,1代表集群版
- table_name&namespace: 存储数据表的标识符号
编写guest的上传配置文件upload_data_guest.json
{
"file": "examples/data/breast_homo_guest.csv",
"head": 1,
"partition": 10,
"work_mode": 0,
"namespace": "homo_breast_guest",
"table_name": "homo_breast_guest"
}
#1.5.0以后版本
{
"file": "examples/data/breast_homo_guest.csv",
"head": 1,
"partition": 10,
"work_mode": 0,
"namespace": "experiment",
"table_name": "breast_homo_guest"
}
3. 上传数据
上传数据命令:
python ${your_install_path}/fate_flow/fate_flow_client.py -f upload -c ${upload_data_json_path}
${your_install_path}: fate的安装目录
${upload_data_json_path}:上传数据配置文件路径
注:运行此命令进入fate节点内部
docker exec -it fate_python bash
#1.5.0版本以后
docker exec -it standalone_fate bash输入以下命令导入训练数据、测试数据以及评估数据:
python fate_flow/fate_flow_client.py -f upload -c examples/federatedml-1.x-examples/homo_logistic_regression/upload_data_guest.json
python fate_flow/fate_flow_client.py -f upload -c examples/federatedml-1.x-examples/homo_logistic_regression/upload_data_host.json
python fate_flow/fate_flow_client.py -f upload -c examples/federatedml-1.x-examples/homo_logistic_regression/upload_data_test.json1.5.0版本以后可以使用flow命令:
#上传数据:
flow data upload -c examples/dsl/v2/homo_logistic_regression/upload_data_guest.json --drop
flow data upload -c examples/dsl/v2/homo_logistic_regression/upload_data_host.json --drop
flow data upload -c examples/dsl/v2/homo_logistic_regression/upload_data_test.json --drop#查看fate表的相关信息(真实存储地址,数量,schema等) :
flow table info -n experiment -t homo_breast_guest#删除fate表数据:
flow table delete -n experiment -t homo_breast_guest控制台显示以下提示表示上传成功

打开fate监控面板fate_board
http://localhost:8080
根据上传完之后的job_id查询得,刚刚上传的两个任务
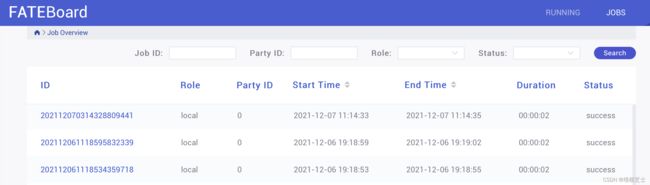
选择具体的任务查看详细信息

4. 建模
4.1 编写dsl配置
为了让任务模型的构建更加灵活,目前 FATE 使用了一套自定的领域特定语言 (DSL) 来描述任务。在 DSL 中,各种模块(例如数据读写 data_io,特征工程 feature-engineering, 回归 regression,分类 classification)可以通向一个有向无环图 (DAG) 组织起来。通过各种方式,用户可以根据自身的需要,灵活地组合各种算法模块。
DSL配置文件对每个组件既会定义输入数据及模型,也会定义输出数据及模型。作为下游组件会以上游组件的输出作为其输入。
DSL配置文件主要由组件名,模块,输入,输出,是否需要部署等构成
- component_name:一个组件的名称,后缀以下划线加数字方式,例如dataio_0,通常数字都以0开始
- module:FATE支持的算法模块中可选项,选择其中一个(Dataio,Intersect,Federated sampling,Feature scale,Hetero Feature Binning,Onehout encoder,Hetero feature selection,union,Hetero-lr,local baseline,Hetero-LinR,Hetero-Poisson,Homo-LR,Homo-NN,Hetero Secure Boosting,Evaluation,Hetero Pearson,Hetero-NN)
- input:有两种类型的输入:一种是data(数据),一种是model(模型)。 data又分为三类:1. 普通数据。用于dataio,feature_engineering和evaluation的;2. 训练数据 。主要使用于一些逻辑回归模型中(如homo_lr,hetero_lr,secure_boost) ;3. 测试评估数据。如果训练数据指定了,将会被作为测试集,如果训练数据没有制定,将会被作为预测或转换任务
- output:同样和输入一样有两种类型的输出:一种是data(数据),一种model(模型)
- need_deploy:两个可选值:true或false。表示组件是否需要部署用于在线推理。这个字段仅用于在线推理【推理】DSL配置
为了尝试多一点的组件,我们的实践将涵盖训练以及评估模型。
/fate/examples/federatedml-1.x-examples/homo_logistic_regression/test_homolr_evaluate_job_dsl.json
1.7.0版本的dsl配置文件:
/data/projects/fate/examples/dsl/v2/homo_logistic_regression/homo_lr_train_eval_dsl.json
4.1.1 建模数据流定义
使用dataio组件,基于上一步上传好的数据定义建模数据输入/输出
这个例子里面定义了两个dataio,分别输出训练数据以及评估数据
"dataio_0": {
"module": "DataIO",
"input": {
"data": {
"data": [
"args.train_data"
]
}
},
"output": {
"data": ["train"],
"model": ["dataio"]
}
},
"dataio_1": {
"module": "DataIO",
"input": {
"data": {
"data": [
"args.eval_data"
]
},
"model": [
"dataio_0.dataio"
]
},
"output": {
"data": ["eval_data"]
}
},4.1.2 训练输入输出定义
"homo_lr_0": {
"module": "HomoLR",
"input": {
"data": {
"train_data": [
"dataio_0.train"
]
}
},
"output": {
"data": ["train"],
"model": ["homolr"]
}
},将dataio_0的输出对象作为训练的输入数据对象,输出横向联邦学习逻辑回归训练模型以及训练数据。
同理对评估数据进行训练定义,将dataio_1的输出对象以及homo_lr0的训练模型作为评估的输入数据对象,输出横向联邦学习逻辑回归训练模型以及评估数据。
组件结构体具体说明:
https://github.com/FederatedAI/FATE/blob/master/doc/tutorial/dsl_conf/dsl_conf_v2_setting_guide.md https://github.com/FederatedAI/FATE/blob/master/doc/tutorial/dsl_conf/dsl_conf_v2_setting_guide.md
https://github.com/FederatedAI/FATE/blob/master/doc/tutorial/dsl_conf/dsl_conf_v2_setting_guide.md
4.1.2 评估输入输出定义
对评估数据集基于homo_lr_0输出的模型进行训练并且输出预测结果以及模型。
"homo_lr_1": {
"module": "HomoLR",
"input": {
"data": {
"eval_data": [
"dataio_1.eval_data"
]
},
"model": [
"homo_lr_0.homolr"
]
},
"output": {
"data": ["predict"],
"model": ["homolr"]
}
},4.2 编写运行配置
运行配置主要是用于指定guest、host、arbiter运行dsl任务相关配置,具体查看
https://github.com/FederatedAI/FATE/blob/master/doc/tutorial/dsl_conf/dsl_conf_v2_setting_guide.mdhttps://github.com/FederatedAI/FATE/blob/master/doc/tutorial/dsl_conf/dsl_conf_v2_setting_guide.md
运行时配置文件,用于对各方中所有组件设置参数
- initiator:指定发起人的角色和party_id
- role:定义各种角色和其对应所属的party_id
- role_paramters:根据角色不同参数有所不同,
- algorithm_parameters:算法中的参数
/fate/examples/federatedml-1.x-examples/homo_logistic_regression/test_homolr_evaluate_job_conf.json
1.7.0版本的conf配置文件:
/data/projects/fate/examples/dsl/v2/homo_logistic_regression/homo_lr_train_eval_conf.json
4.2.1 定义建模角色以及运行模式
"initiator": {
"role": "guest",
"party_id": 10000
},
"job_parameters": {
"work_mode": 0
},
"role": {
"guest": [10000],
"host": [10000],
"arbiter": [10000]
},
"role_parameters": {4.2.2 定义角色参数
主要包括data数据结构定义以及组件配置按照角色区份。
4.2.2.1 guest角色参数
"guest": {
"args": {
"data": {
"train_data": [{"name": "homo_breast_guest", "namespace": "homo_breast_guest"}],
"eval_data": [{"name": "homo_breast_test", "namespace": "homo_breast_test"}]
}
},
"dataio_0":{
"with_label": [true],
"label_name": ["y"],
"label_type": ["int"],
"output_format": ["dense"]
}
},4.2.2.2 host角色参数
"host": {
"args": {
"data": {
"train_data": [{"name": "homo_breast_host", "namespace": "homo_breast_host"}],
"eval_data": [{"name": "homo_breast_test", "namespace": "homo_breast_test"}]
}
},
"dataio_0":{
"with_label": [true],
"label_name": ["y"],
"label_type": ["int"],
"output_format": ["dense"]
},
"evaluation_0": {
"need_run": [false]
},
"evaluation_1": {
"need_run": [false]
}
}4.3 定义算法配置
具体查看算法参数
FATE/python/federatedml/param at master · FederatedAI/FATE · GitHubhttps://github.com/FederatedAI/FATE/tree/master/python/federatedml/param
"algorithm_parameters": {
"homo_lr_0": {
"penalty": "L2",
"optimizer": "sgd",
"eps": 1e-5,
"alpha": 0.01,
"max_iter": 20,
"converge_func": "diff",
"batch_size": 320,
"learning_rate": 0.15,
"init_param": {
"init_method": "zeros"
},
"cv_param": {
"n_splits": 4,
"shuffle": true,
"random_seed": 33,
"need_cv": false
}
},
"evaluation_0": {
"eval_type": "binary"
}
}5. 开始训练评估任务
具体命令如下:
python {fate_install_path}/fate_flow/fate_flow_client.py -f submit_job -c ${runtime_config} -d ${dsl}
${runtime_config}:运行配置文件路径${dsl}:dsl文件路径
控制台输出命令:
python fate_flow/fate_flow_client.py -f submit_job -c examples/federatedml-1.x-examples/homo_logistic_regression/test_homolr_evaluate_job_conf.json -d examples/federatedml-1.x-examples/homo_logistic_regression/test_homolr_evaluate_job_dsl.json
1.5.0版本以后可以使用flow命令:
flow job submit -c examples/dsl/v2/homo_logistic_regression/homo_lr_train_eval_conf.json -d examples/dsl/v2/homo_logistic_regression/homo_lr_train_eval_dsl.json控制台与监控面板显示如下信息

显示运行进度:

6. 查看结果
通过监控面板查看job执行结果 ,通过job_id查询对应任务

可以看到建模的每个过程组成的DAG图
6.1 查看dataio_0执行结果
根据dsl定义的输出我们点击"view the outputs"查看结果如何

由于输出类型是data类型,可以在"data output"看到输入的数据列表项如上

点击"log"可以查看日志
6.2 查看dataio_1执行结果
dataio_1是用于评估的数据,数据输出结果如下

6.3 查看分析训练结果
6.3.1 homo_lr_0
homo_lr_0是分别在guest、host训练homo_breast_guest以及homo_breast_host得出最终模型

下面表格列出所有特征variable以及通过LR分类得出特征对应权值weight

最大迭代次数(iterations):20
是否收敛(converged):false
下面还有一个曲线图,表示LR损失函数值随着迭代次数的变化

查看data output 训练结果如下

id:id
label: 标签值,真实结果
predict_result: 预测结果
predict_score: 预测得分
predict_detail:预测结果的细节
6.3.2 homo_lr_1
home_lr_1是基于homo_lr_0预测test数据集的结果。
输出模型结果如下:

查看data output 训练结果如下:

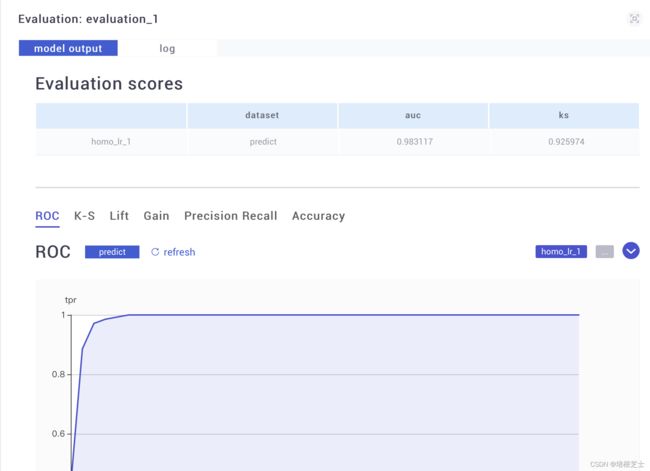
6.4 查看模型评估结果
6.4.1 homo_lr_0模型评估evalation_0 结果
模型评估结果如下:

这里的auc值、ks值显示训练数据集的正样本概率以及好坏样本累计差异率
下面是几种常见评估曲线


6.4.2 homo_lr_1模型评估evalation_1 结果
homo_lr_1使用homo_lr_0训练的模型对test数据集进行预测,得出的结果如下图,相对evalation_0各部分指标略有下降。