【轻量化深度学习】Efficient On-Device Deep Learning Research
Effecient On-Device Deep Learning Research
Student : Wenxuan Zeng
School : University of Electronic Science and Technology of China
Date : 2022.3.25 - 2022.4.3
文章目录
- Effecient On-Device Deep Learning Research
-
- 1 What are the major challenges to run an NLP model efficiently on the edge, e.g., mobile cpu or micro controller?
-
- 1.1 Model perspective
- 1.2 Edge-device perspective
- 1.3 Data perspective
- 2 How can we mitigate the challenges? Pick one technique for a fairly deep dive.
-
- 2.1 Knowledge distillation (KD)
- 2.2 Quantization
- 2.3 Pruning
- 2.4 Low-rank approximation
- 2.5 Weight-sharing / Parameter-sharing
- 2.6 Dynamic networks with adaptive depth/width
- 2.7 Attention
- 2.8 Better model structure
- 2.9 Weight-Sharing NAS
- 2.10 Hardware
- 2.11 Compiler support
- 3 Paper Understanding
-
- 3. 1 Attention Is All You Need
- 3.2 BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding
- 3.3 MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
- 3.4 BinaryBERT: Pushing the Limit of BERT Quantization
- 3.5 EdgeBERT: Sentence-Level Energy Optimizations for Latency-Aware Multi-Task NLP Inference
- 4 我对Efficient AI的一些思考 ⭐
1 What are the major challenges to run an NLP model efficiently on the edge, e.g., mobile cpu or micro controller?
1.1 Model perspective
-
Heavy model size
- 例如:BERT有12层Transformer结构,参数高达109M(Embedding size=768,FFN size=3072,#Head=12)
-
High latency
- 例如:BERT的
LayerNorm + GeLU在真实环境下延迟为192ms
- 例如:BERT的
-
High cost of computation and memory
- 例如:BERT基本模型在本机32位浮点内存(FP32)中消耗了432MB内存
1.2 Edge-device perspective
- Limited and shared bandwidth to the memory of micro-controllers
- Limitated compute and storage resources
- Energy consumption
- Security and privacy
1.3 Data perspective
- High cost of data movement -> In-Sensor / Near-Sensor computing
- Continuous high resolution model inputs -> Effcient compilation of multi-stream models / Hardware-aware model design
2 How can we mitigate the challenges? Pick one technique for a fairly deep dive.
首先放上一张生动的图,从左往右一次是知识蒸馏、量化、剪枝。然后下面开始介绍我了解到的模型压缩技术以及收集到的相关文献。

2.1 Knowledge distillation (KD)
-
Description
一种简单而有效的模型压缩 / 训练方法,将教师模型(规模大,表现好)所学习到的知识迁移到学生模型(规模小,表现不如大模型好)上,使学生模型具有规模小的同时表现好的特点。常见的知识蒸馏方法有KD算法(用两个loss function求加权平均)、TAS算法(多级知识蒸馏,利用一个中等规模的网络(助教)弥补学生模型和教师模型的差距)。
在BERT的轻量化研究中,人们提出了各式各样的蒸馏方式。我对此非常感兴趣,所以我选择对蒸馏技术进行了较为深入的学习(附在另一个文档中)。
-
Related works
-
Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter (NIPS’19)
简介:成功将BERT深度减半,通过预训练阶段和可选的微调阶段的知识蒸馏。Distilbert的参数压缩到了52M。
-
Patient knowledge distillation for bert model compression (ACL’19)
简介:蒸馏BERT到较浅的学生,通过知识蒸馏和多个中间层上隐藏状态的额外的知识转移。
-
Small and practical bert models for sequence (ACL’19)
简介:将多语言BERT蒸馏到一个更小的BERT中,完成序列标签的任务。
-
Distilling task specifific knowledge from bert into simple neural (arXiv’19)
简介:将BERT蒸馏到一个极小的BiLSTM中。
-
Tinybert: Distilling bert for natural language understanding (ACL’20)
简介:对BERT用分层蒸馏策略,在预训练和微调阶段中进行,同时作者提出了注意力矩阵的蒸馏。Tinybert的参数压缩到了14.5M。
-
MobileBERT:a Compact Task-Agnostic BERT for Resource-Limited Devices (ACL’20)
简介:将知识从较大的BERT蒸馏到MobileBERT中,模型结构中加入了瓶颈结构和平衡机制。将BERT模型压缩4倍。
(详细方法记录在了后文中)
-
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers (NIPS’20)
简介:蒸馏self-attention模块,提出value之间的scaled dot-product (Value-Relation) 作为新的深度自注意力知识,同时引入teacher assistant模型去辅助大模型的蒸馏。
-
2.2 Quantization
-
Description
不需要设计更小的模型架构,而是采用更低位的固定表达(比如8bit / 4bit / 2bit / 1bit)代替32位浮点参数。量化其实就是通过降低模型精度的方式来减少模型的存储空间,所需计算资源大大减少。TensorFlow Lite toolkit中有量化的工具可以供我们使用 (MobileBERT直接使用了这个工具,进一步压缩了4倍大小)。
一种极端的量化方式是二值量化(binarization),仅用-1和+1表示权重,每个权重仅占用1bit,所以模型压缩到了原来的1/32,效率极高。
量化的有效性:容易想到,量化会损失精度(相当于给网络引入noise),而神经网络对噪声不太敏感,所以控制好量化程度,能尽可能避免精度影响;量化后,权重的位数少了,所需存储空间和计算资源减少;从体系结构考虑,量化能够节能和减小芯片面积。
-
Related works
-
Q8bert: Quantized 8bit bert (NIPS’19)
简介:32-bit -> 2-bit,将权值和激活值量化为8-bit的对称线性量化方案。
-
Q-bert: Hessian based ultra low precision quantization of bert (AAAI’20)
简介:32-bit -> 2-bit,提出基于Hessian信息的混合精度量化,以及用于组量化机制的技术。
-
Ternarybert: Distillation-aware ultra-low bit (EMNLP’20)
简介:32-bit -> 2-bit,使用了基于近似的三元化方法和感知损失的三元化方法,并与蒸馏结合在一起。
-
AdaptiveFloat: A Floating-point based Data Type for Resilient Deep Learning Inference (arXiv’20)
简介:设计适合深度学习的浮点数数据类型。 (EdgeBERT的技术之一)
-
BinaryBERT:Pushing the Limit of BERT Quantization (ACL’21)
简介:32-bit -> 1-bit 首次将BERT的量化推到了极限,也就是将权重量化到1-bit (1/32)。(详细方法记录在了后文中)
-
Training with quantization noise for extreme model compression (ICLR’21)
简介:32-bit -> 2-bit,提出Quantization noise训练方式,提高量化的适应能力。
-
BIBERT: ACCURATE FULLY BINARIZED BERT (ICLR’22)
简介:32-bit -> 1-bit,引入Bi-Attention(二值注意力)机制,解决前向传播中二值化后的注意力机制的信息退化问题;提出方向匹配蒸馏(Direction-Matching Distillation)方法,解决后向传播中蒸馏的优化方向不匹配问题。
-
2.3 Pruning
-
Description
找出网络中冗余的部分并删除,这部分不再参与前向或反向传播,减少模型的计算量和存储量。
常见的剪枝可以是:① 连接权重:权重剪枝类似mask为0,理论上这样做不减小模型大小,但是可以通过稀疏矩阵实现,从而减小模型的存储压力;② 神经元:给冗余的神经元剪枝相当于drop-out,减小了模型大小,性能损失也不大;③ 权重矩阵:类似减少attention机制中的multi-head数量。
-
Related works
-
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding (ICLR’16)
简介:零阶网络剪枝 (EdgeBERT的技术之一)
-
Reducing Transformer Depth on Demand with Structured Dropout (ICLR’20)
简介:通过dropout从大模型中采样子网络,提出LayerDrop方法做BERT的剪枝。
-
Movement Pruning: Adaptive Sparsity by Fine-Tuning (NIPS’20)
简介:一阶网络剪枝 (EdgeBERT的技术之一)
-
Are Sixteen Heads Really Better than One? (NIPS’21)
简介:对Multi-Head中的#Head进行了研究,发现很多head是冗余的,可以删除。
-
2.4 Low-rank approximation
-
Description
从分解矩阵运算的角度对模型计算过程优化,通过线性代数方法将参数矩阵分解为一些列小矩阵组合,使小矩阵的组合在表达能力上和原始卷积层一样(CV方向)。这种方式能保持模型精度,同时极大地降低参数存储所占空间,按照从浅到深的顺序逐层做低秩近似。
-
Related works
-
A tensorized transformer for language modeling (NIPS’19)
简介:利用张量分解的逆过程,证明在保持Transformer原有信息的同时,可以将其Multi-head Attention机制降低一半的参数。
-
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations (ICLR’20)
简介:ALBERT抛弃了BERT预训练的参数,只继承了BERT设计思想。主要有三点改进:嵌入层分解、参数共享、任务改变(上下句预测任务 -> 句序预测任务)。ALBERT的参数压缩到了12M。(EdgeBERT的基础模型)
-
2.5 Weight-sharing / Parameter-sharing
-
Description
通过在多个layer之间共享模型的参数,实现参数量的减小,从而使模型具有更小的规模和更高的效率。
-
Related works
-
Universal transformers (ICLR’19)
简介:结合Transformer和RNN的优点,具有全局感知性和时间上的递归性。
-
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations (ICLR’20)
简介:ALBERT抛弃了BERT预训练的参数,只继承了BERT设计思想。主要有三点改进:嵌入层分解、参数共享、任务改变(上下句预测任务 -> 句序预测任务)。ALBERT的参数压缩到了12M。(EdgeBERT的基础模型)
-
2.6 Dynamic networks with adaptive depth/width
-
Description
模型的深度和宽度并不是一成不变的,通过自适应的方式减少模型的深度或宽度,可以达到轻量化模型的目的。
-
Related works
-
DynaBERT: Dynamic BERT with Adaptive Width and Depth (NIPS’20)
简介:对模型的宽度和深度进行自适应的训练。
-
Deebert: Dynamic early exiting for accelerating bert inference (ACL’20)
简介:基于熵的提前退出机制,让简单的文本经过较少的计算,复杂的文本经过较多的计算。(EdgeBERT的技术之一)
-
Bert loses patience: Fast and robust inference with early exit (NIPS’20)
简介:采用Patience-based early exit机制,在预训练模型的每一层都整合一个内部分类器,当内部分类器的中间预测在预定步数内都没有改变时动态的停止推理,可以用更少的层做预测,同时避免了一定的过拟合。
-
2.7 Attention
-
Description
Transformer是基于attention机制的,过多的attention计算会导致较大的计算量,所以可以通过自适应注意力机制、审视注意力机制中重要的部分,都能压缩模型。
-
Related works
-
Adaptive Attention Span in Transformers (ACL’19)
简介:提出动态注意力范围(自适应注意力范围),在Transformer的多头注意力机制中,每个head都会关注所有的token,自适应注意力机制为每个head分配一个mask,使得每个token只计算周围的token,降低计算attention时的开销。(EdgeBERT的技术之一)
-
SparseBERT: Rethinking the Importance Analysis in Self-attention (ICML’21)
简介:在预训练时动态地研究了注意力矩阵地变化并重新思考了self-attention中位置的重要性。一个有趣的结论是注意力矩阵的对角线元素和其他位置相比是最不重要的。本文从通用近似定理的角度上证明了这些位置是可以被舍弃的。为了进一步降低self-attention的计算复杂度,提出可微分注意掩码(DAM)算法,可以用于指导SparseBERT的设计。
-
Are Sixteen Heads Really Better than One? (NIPS’21)
简介:对Multi-Head中的#Head进行了研究,发现很多head是冗余的,可以删除。
-
2.8 Better model structure
-
Description
直接对模型的内部结构做改进,用计算量更小的方式替换模型中一些计算量大的模块。
-
Related works
-
SqueezeBERT: What can computer vision teach NLP about efficient neural networks? (ACL’20)
简介:将CV中的技术迁移到NLP领域,用分组卷积(grouped convolution)替换自注意层中的几个操作。
-
2.9 Weight-Sharing NAS
-
Description
NAS自动地优化神经网络,能够使网络在一定条件的限制下(比如FLOPs,延迟,内存占用等因素)达到最高的精度。Weight-Sharing NAS构建一个集成了搜索空间内所有网络的超网络。主要分为两个阶段:超网络的训练和超网络的采样/评估。
目前Weight-Sharing NAS存在的两大挑战是:如何定制搜索空间;如何训练超网络。

Weight-Sharing NAS联合训练超网络和自网络以降低训练成本,超网络训练直接决定了搜索网络的准确率,要考虑两点:如何在训练时采样子网络;如何促使子网络汇聚。训练可以描述为如下过程(Knowledge distillation):

-
Related works
下面介绍的是李萌老师关于Weight-sharing的几篇paper,分别针对性地解决了NAS中的问题。
-
ScaleNAS: One-Shot Learning of Scale-Aware Representations for Visual Recognition
解决搜索空间局限性的问题,本文采用灵活的搜索空间,允许任意数量的块和跨尺度的特性融合。
-
AttentiveNAS: Improving Neural Architecture Search via Attentive Sampling (CVPR’21)
解决采样子网络的问题,带注意力采样的超网络训练策略,专注于pareto front的子网络采样。
-
AlphaNet: Improved Training of Supernets with Alpha-Divergence (ICML’21)
解决KL散度所带来的问题,依靠知识蒸馏的超网络训练促使子网络的汇集,传统的知识蒸馏利用KL散度作为loss指标,可能带来的问题对教师网络的不确定性的高估。本文提出的Alpha-divergence确实平衡了高估和低估的问题。
-
2.10 Hardware
-
Related works
- EdgeBERT:Sentence-Level Energy Optimizations for Latency-Aware Multi-Task NLP Inference (MICRO’21)
- 2020年CANAO编译器感知的神经网络结构优化框架:
- 基于轻量级多项式的层融合技术(Lightweight Polynomial-based Layer Fusion)
- 编译器感知的神经结构搜索技术(Compiler-aware Neural Architecture Search)
-
引用李萌老师的一期 Talk《Efficient Audio-Visual Understanding on AR Devices》中的一句话:
不能只靠网络或硬件架构来优化,我们需要一种软硬件协同的范式转变。

2.11 Compiler support
-
Description
Compiler tool对于高效执行是至关重要的,为SOTA高效网络架构和操作提供支持(如Depthwise/Group Convolutions, Attention Layers);也为multi-pathway架构中的layer scheduling提供支持(通过避免DRAM访问实现显著的性能/能耗优化,通过避免存储瓶颈实现显著的的延迟优化)
3 Paper Understanding
3. 1 Attention Is All You Need
链接:https://arxiv.org/pdf/1706.03762.pdf (NIPS’17)
有关Self-attention和Transformer的学习和理解,记录在我的博客中:https://xuanland.cn/index.php/archives/46/
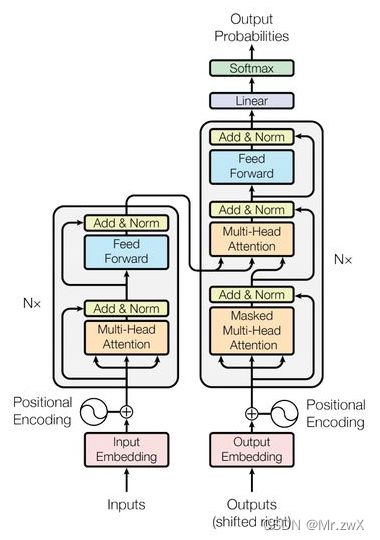
理解: Transformer由encoder和decoder两部分构成。在encoder中,输入input embedding,通过multi-head attention计算input对应的embedding;在decoder中,是一个autoregressive的形式,前一个预测出来的结果作为后一个预测的输入,decoder中的attention是带mask的,因为每个词只能看到前面的词。Encoder和decoder通过cross-attention连接在一起,Add过程也就是residual,将输入和输出求和,然后Norm过程是layer norm。采用self-attention时不没有考虑词向量的位置信息,所以Transformer也加入了位置编码,与输入向量拼接在一起。
3.2 BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding
链接:https://arxiv.org/pdf/1810.04805.pdf
有关BERT模型的学习和理解,记录在我的博客中:https://xuanland.cn/index.php/archives/48/

理解: BERT是Transformer的encoder部分,即通过self-attention计算input对应的embedding表达。BERT分为pre-train和fine-tune两部分,前者采用masked language model (MLM) 生成双向语言表征,后者是通过模型微调完成各种各样的下游任务。
3.3 MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
链接:https://arxiv.org/pdf/2004.02984.pdf

-
特点: ① 支持资源有限设备的部署;② 任务无关;③ (翻转)瓶颈结构;④ 自注意力和前馈神经网络的平衡机制; ⑤ 减小模型宽度而不是深度;⑥ 知识蒸馏。
-
动机: 轻量化BERT模型,任务无关的优化有更小的成本,并且以前的工作没有去考虑减小模型的宽度。
-
训练过程: 首先设计一个翻转瓶颈结构的BERT教师模型,然后将教师模型的知识蒸馏到MobileBERT上。
-
操作优化: ① 将layer norm换成NoNorm的element-wise线性变换;② 将gelu()换成relu()。
-
Embedding因数分解: 为了压缩embedding layer,将word emdedding维度减小到128,然后在原始token embedding上用1D卷积(卷积核大小为3)来产生维度为512的输出。
-
训练策略: ① 辅助知识迁移:将中间知识的迁移作为知识蒸馏的辅助任务;② 联合知识迁移:先联合训练所有层级的知识迁移的MobileBERT,然后通过预训练蒸馏继续训练;③ 渐进式知识迁移:在知识迁移中渐进地训练每一层。
-
MobileBERT架构搜索: 设置相同的参数大小(25M)但是注意力和前馈网络之间不同的参数比例,影响了不同程度的平衡。
-
量化: 采用了TensorFlow Lite中的标准训练后量化,继续压缩了4倍模型。
-
结论: ① 模型深而窄是必要的; ② 瓶颈/翻转瓶颈结构可以实现有效的分层知识迁移;③ 渐进的知识迁移能有效训练模型。
3.4 BinaryBERT: Pushing the Limit of BERT Quantization
链接:https://arxiv.org/pdf/2012.15701.pdf

- 特点: ① 二值化的极限量化(1-bit);② 基于边缘设备的自适应分解。
- 动机: 将模型权重二值化能极大程度优化模型,甚至可以说把BERT量化推到极限(从未有人尝试1-bit)。但是二值化难以训练,会带来陡峭的性能下降问题,与此同时,三元化模型有相对平坦和光滑的loss,所以提出三元化权重分解,用一半大小的三元化模型的分解作为二值化BERT的初始化。
- 训练过程: 首先训练一半大小的三元化BERT到收敛,然后通过TWS操作(ternary weight splitting)分解潜在的全精度权重。为了继承分割后的三元化模型的性能,TWS操作符需要分割等价性(即相同的输出有相同的输入)。
- 训练二值化BERT的困难: 从32-bit降到1-bit导致性能陡峭下降(而2-bit则较平滑),经过对loss的分析,提出三元化权重分解的方法来解决上述问题。
- 带知识蒸馏的训练方式: 采用中间层蒸馏的方式,从全精度教师网络的embedding、注意力的输出M和FFN的输出F蒸馏到量化的学生网络。目标是最小化每层的平均误差(MSE),求和得到目标函数。对于预测层蒸馏,目标是最小化量化的学生预测值与教师预测值之间的soft cross-entropy (SCE)。
- 自适应分裂: 基于二值化的参数敏感性和边缘设备的资源限制,BinaryBERT可以灵活调整宽度。给定资源限制(比如模型大小和计算的FLOPs),首先训练一个自适应混合精度模型(敏感部分为三元,其余部分为二值),然后分裂三元权重为二值。因此,自适应分裂最终对所有权重矩阵具有一致的算术精度(1-bit),这通常比混合精度矩阵更容易部署。
3.5 EdgeBERT: Sentence-Level Energy Optimizations for Latency-Aware Multi-Task NLP Inference
链接:https://arxiv.org/pdf/2011.14203.pdf

-
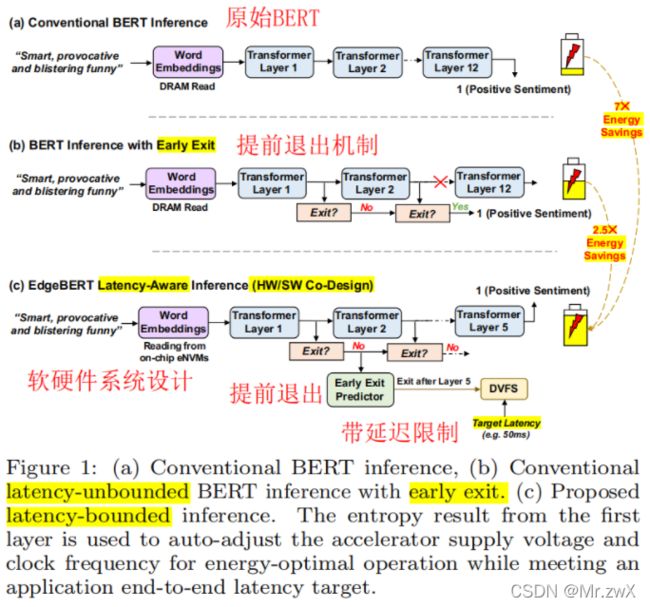
特点: ① 软件和硬件协同的优化方法(algorithm-hardware co-design);② 延迟感知的能量优化(latency-aware energy optimization):采用基于熵的提前退出预测,以在语句粒度上执行动态电压频率缩放(DVFS),以在遵守规定目标延迟的同时实现最小的能量消耗。
-
动机: BERT庞大的运算和内存需求使得他们部署在边缘平台上尤为困难。所以提出EdgeBERT这样一个软硬件协同、延迟感知能量优化的模型。另外,为了最大化这些算法在始终开启和中间边缘计算设置中的协同效益,设计了一款12nm的可扩展硬件加速系统。
-
EdgeBERT和其他模型的对比
-
软件优化
下图为软件方面的优化,EdgeBERT主要在ALBERT的基础上进行优化,并融入了基于熵的提前退出机制,自适应注意力范围,网络剪枝,动态浮点数的量化等技术。
Entropy-based Early Exit
在Transformer的输出处添加一个轻量级的分类器,基于结构和上下文的复杂性来决定是否退出。分类器计算出的熵值衡量了数据的不确定性,更小的熵值意味着对分类结果的正确性有更大的信心。
Adaptive Attention Span
多头注意力存在很大计算量,并且一些head可能是无用的,或者不需要去注意整个范围内的tokens。所以引入可学习的参数z作为mask,去自动地学习最佳的span。
Network Pruning
考虑了两种剪枝,一种是movement pruning,另一种是magnitude pruning。
Floating-Point Quantization
设计适合深度学习的浮点数数据类型。IEEE 754二进制浮点数标准为:符号位(S)、指数偏移值(E)、分数值(F),一个数表示为: V = S × 2 E r e a l × F V=S\times 2^{E_{real}}\times F V=S×2Ereal×F,其中 E r e a l = E + E b i a s E_{real}=E+E_{bias} Ereal=E+Ebias。AdaptiveFloat就是根据模型动态地修改 E b i a s E_{bias} Ebias,使得其表达范围能覆盖最大的tensor值即可。
下图为软件优化的设计图:

-
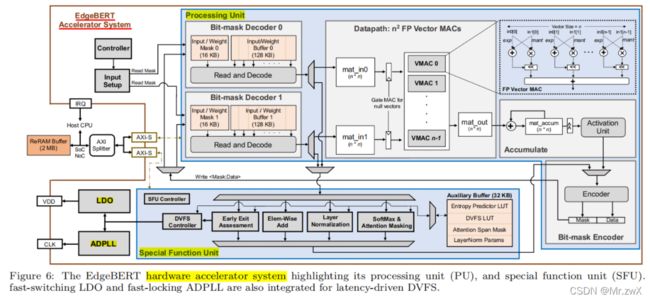
硬件优化
首先是在选择存储介质方面,从嵌入层和其他参数两个方面进行考虑
对于嵌入层,其功能是存embedding向量,EdgeBERT在做下游任务的fine-tune时通常不对embedding修改,所以这类参数相当于只读(read-only),那么对快速读取有较高要求,同时希望能够在掉电时依然保持原有数据来降低数据读写开销,因此适用耗能低、读取速度快的eNVM(Embedded Non-Volatile Memory,嵌入式非挥发性记忆体),本文选取的是基于MLC的ReRAM,一种低功耗、高速度的RAM。
对于其他参数,需要在fine-tune时改变,文中使用SRAM(与计算机内存的DRAM不同,SRAM更贵但功耗更低、带宽更高,常被用于制造cache或寄存器)。
另外,硬件加速系统也是本文的杀手锏,下图为硬件加速系统的设计图:
4 我对Efficient AI的一些思考 ⭐
- 在本次的学习中,我从模型效率这个方面入手(阻碍AI落地的另一个重要因素是安全性,在之后我会展开学习),阅读了一些相关文献,也去认真看了两期 talks(Efficient AI & Weight-sharing NAS),受益匪浅。从算法层面来看,轻量化深度学习模型的方式很多,并且每一种方式都有各种各样的创新。正是因为大家不断为Efficient AI这个领域做贡献,才使得AI的落地进入现实。
- 本次学习主要接触到的模型压缩方法有知识蒸馏、剪枝、量化、参数共享、自适应深度/宽度、注意力优化、权重共享NAS、硬件加速等等,不管是哪类方法,我都初步感受到了它吸引我去研究的地方(比如蒸馏,在另一篇文档中我做了更深入的调研,在此过程中也产生了一些自己的思考;比如量化,我想更深入地去学习低精度表示为何仍能维持高精度推理;比如自适应注意力范围,这是我之前从未考虑的点,我认为甚至可以用更巧妙的方式去实现;比如AI/HW Co-Design,我想去探索怎么样的协同设计使系统效率最高…)。
- 我认为AI/HW Co-Design一定是未来发展的方向,要实现AI真正的落地,一定要考虑模型的效率和安全性。那么算法与硬件的协同,就好像给理论与实际搭上了一座桥梁。