【综述】Recent Advances and Challenges in Task-oriented Dialog Sytems

本文主要总结对话系统的最新进展及其面临的挑战。除此之外,还会讨论以下三个关键的主题:
- 提高数据的使用效率,推动对话模型在低资源情况下的效果
- 为策略学习建立多轮动态模型,达到更好的任务完成效果
- 融合领域本体知识进入对话系统
另外,还将介绍对话评估的发展、广泛使用的公开数据集。
一、介绍
开放领域和任务导向的对话系统不同之处:对话系统是以解决在一个或者多个领域中的一些特别的任务为目标的。[1]
目前的对话系统大概分为两种:pipline方法 和 end-to-end 方法:
1. Pipline方法
对话系统被分为以下几个模块:natural language understanding (NLU), dialog state tracking (DST), dialog policy (Policy) and natural language generation (NLG)。
当然也有一些结合方法:word-level DST[2, 3](联合NLU和DST)、word-level policy [4,5] (联合 and NLG).
需要大量的标注的对话数据去训练每个组成部分,因此也比end-to-end具有更多可解释性和稳定性。因此很多商业系统都建立在这个方法之上。
2. End-to-end 方法
直接地将文本上下文作为输入,然后给出直接的自然语言回答。
该方法则更容易进行构建,但非常的不可控。
Pipline方法中更多关注在dialog state tracking (DST)和dialog policy (Policy)模块,并且也被成为对话管理(Dialog Management)模块。因为NLU和NLG是非常独立的自然语言处理任务,在对话系统中很少任务交织在一起。基于领域主题,DST可以被视为一个通过预测每个槽位值的分类任务。当数据量不充足的时候,就会出现OOV(out of vocabulary)问题和不能很好地泛化到一个新的领域。
对话策略学习任务,可以被看作是一个强化学习任务。和熟知的强化学习任务不一样的是,对话策略学习需要真实的人类去提供environment。另外,大多数现有的方法都是使用人工定义rewards,比如任务完成率和会话轮数,这些并不能很好地评价系统的表现。
对于end-to-end方法,在一个有限的特定领域数据集中,数据饥饿让seq2seq模型很难去学习到有效的槽填充(slot filling).知识库查询问题除了encoder和decoder,还需要模型生成一个中间序列,这是不直接的一种方式。另一个缺点是,encoder-decoder框架利用一个词级策略,这会导致次优的表现,因为策略和语言作用是相互联系在一起的。
最后总结三点关键性问题:
- 数据有效利用:很多方法都需要大量的数据训练模型,将碰到数据饥饿现象。另外,任务型对话系统需要特定领域的数据,这又非常难进行收集和标注,因此在低资源下学习是主要问题之一。
- 多轮动态:对比开放领域的对话系统,任务型对话系统更强调目标驱动的多轮策略。每一轮的对话中,系统的行动应该符合对话历史,并且引导随后的对话到更高的reward。另外,model-free的强化学习方法不适合直接的用于任务型对话系统,因为难得的训练环境和不完美的reward定义。因此,很多的解决方法是提出去解决血多多轮交互训练的问题,为了达到更好的策略学习,包括model-base策略、reward评价和end-to-end策略学习。
- 融合主体:许多任务型对话系统不得不查询知识图谱去检索实体进行答案生成。在pipline方法种,知识图谱的查询主要是根据DST的结果进行组织的。和pipline模型相比,end-to-end方法绕开(bypass)模块化(modular)的、需要细粒度标注和领域经验的模型。但是,这个简化让组织一个查询非常难,因为没有准确的状态表示。
二、模型和方法
对话系统可以粗劣地分为两类:pipline和end-to-end。
在pipline方法中,模型主要分为NLU、DST、Diaglog Policy和NLG;对话策略模块是在复合系统中进行训练的。虽然NLU-DST-Policy-NLG的框架是pipline方法的非常典型的结构,但仍然由其他类型的结构。最近,由归并部分典型模块的研究,比如word-level DST和word-level policy,使得pipline的结构具有多样性。
在end-to-end方法中,对话系统使用的是end-to-end方式进行训练。训练程序就像是生成一个回答文本基于给定的对话文本和后台的知识图谱。

2.1 Natural Language Understanding
NLU模块将用户文本映射到一个结构化的语义表示。Dialog act是目前比较流行的语义表示模式,它由意图识别和槽值进行决定,如表1。
意图类型是高级的文本分类(如Query和Inform),用来表示文本的功能。
槽值对是句子中提到的、特定任务的语义成分。
以上两个都是跟知识本体有关的,能用于查询知识图谱。基于dialog act结构,NLU能进一步分为意图识别和槽值抽取。前者一般被认为是一个意图分类任务,将文本作为输入;而槽值识别则是一个序列标注任务。


其中 d d d表示意图类别, y 1 y_1 y1到 y n y_n yn是每个token的标签。
序列模型强大的能力所以被广泛用于意图识别和槽值抽取任务。这些模型的隐藏层输出表示对应的 y i y_i yi,使用最终的隐藏状态作为句子的意图 d d d 。CNN和递归神经网络也被广泛使用了。被广泛用于传统序列标注任务的CRF,结合RNN和CNN来提升效果[6-8]。最近BERT变成了另一个很流行的选择[9-11]。另外,在注意力机制被用于词和句子表示之间的交互的时候,也有一些模型能强化意图分类和槽标注的联系,如使用一个intent gate去引导槽值标记任务。
2.2 Dialog State Tracking
DST通过将完整的对话文本作为输入,来评估用户每个时间步的目的。DST在第 t t t 个时间步可以被认为是前面所有轮次到 t t t的抽象表示。早期的成果中,采用一些对话状态的固定集合来表示,在马尔可夫决策过程(MDP)中,规范状态转换。PDMDP进一步采用部分可被观察的观察现象,并且这让它在复杂的情况下有更好的健壮性[12-15]。最近的成果breif state被采用于表示对话状态表示,这个state是由表达用户意图的slot-value pairs组合而成,因此这个问题可以看成是一个多分类问题:

第 i i i个slot,有一个tracker p i p_i pi , u i u_i ui 表示文本在第t轮的表示。第 i i i 个slot在第 t t t轮所表示的类别是 d i , t d_{i,t} di,t 。但是,当在运行时,面对之前透明的值时,这种方法是由缺陷的。另外,也有些成果将DST任务作为MRC任务来处理[16-17]。在最近的工作中,slot又被分为两种类型:自由形式和固定词表。前者则对每一个slot不采用固定的词汇表,这也意味着模型不能通过分类器来预测槽对应的值。对于自由形式的slot,一个重要的方面是它能通过文本,直接生成slot-value或者通过预测值的种类/范围。在生成方法中,一般使用slot对应的词一个decoder去生成slot值。但是对于单独的词,这个方法也会失败,因为词表也是有限的,而span-based methods,采用文本中展示的值,并且预测span中开始和结束的位置。
2.3 Dialog Policy
DP生成下一个系统行动。因为在一个会话中的,对话行为会被按顺序产生,它经常会被表示为一个马尔可夫决策过程MDP,这些我们可以用强化学习进行解决。就像图3所展示的,在特定的实践部t,用户采取了行为 a t a_t at ,并接收到一个奖励 R t R_t Rt和状态更新到 S t S_t St .
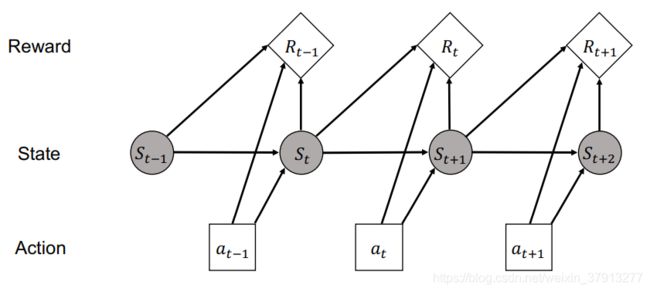
一种典型的方法是,基于对话语料,通过监督学习或者模仿学习,先在线下训练对话传策略,然后使用真实的用户对强化学习模型进行微调。但由于真实的对话很难得,用户模仿技术被用于提供训练对话。
人类的对话能看成是一个马尔可夫决策过程:在每个时间步,通过确定的行为 a a a ,系统从状态 s s s转移到一个新的状态 s ′ s' s′ 。因此强化学习经常用于解决对话系统中的MDP问题。
通过学习真实用户之间的交流,Model-free的强化学习方法控制着早期的Neural dialog policy,比如DQN和Policy Gradiant方法。对于复杂的多领域对话,采用分层的RL模型来首先确定目前轮次所属的领域,然后选择该领域中的一个行为action。训练一个强化学习策略模型需要大量的交互数据,一个解决方法是使用用户模仿,用另一个对话系统来提供训练和评价环境。但是,用户模拟不能完全地模仿真实人类地对话,然后归纳偏差会导致模型在真实人类对话产生不好的效果。因此,RL模型会模拟环境,以更好地应对对话策略学习。在model-base的强化学习方法中,环境被用于动态地模拟对话[18-20]。然后,强化学习训练阶段,模型在对话策略从真实用户和模拟环境中轮流地被训练。
2.4 Natural Language Generation
通过DP产生的对话行动act,自然语言生成模块经常被作为一个重要的自然语言生成任务,将act映射成自然语言文本。NLG将diaglog act作为输入,并将回答作为输出。为了能进一步提升用户体验,生成的文本应该:
-
为了完成任务,充分调查diaglog act的语义
-
自然地、具体的、能给与有效消息的、相似的接近人类语言;另一个问题是如何在优先训练数据建立一个健壮的NLG。
2.5 End-to-End Methods
一般而言,pipline系统的每个模块是分开优化的。模块化的结构导致了模型设计非常复杂,每个模块的表现也并非一定要推动整个系统发展。End-to-end方法是受在end-to-end方法中,使用自然模型建立的开放对话系统的启发,如图4.大部分方法都是依托于seq2seq框架,并通过基于梯度的方法进行优化。
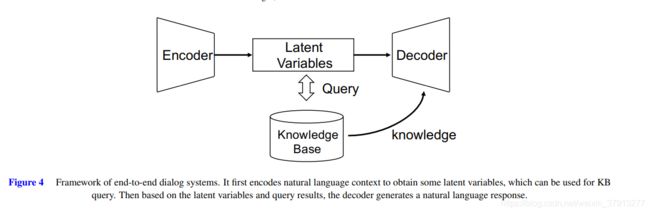
端到端方法中,模型训练计算出回答的最大可能性概率预测。有人还把它当作MRC任务做,把对话历史作为上下文,用户提供的文本作为问题,系统回答作为答案。
缺点是数据不足,且并不能很好地进行挖掘状态特征。
三、评价标准
大部分的评价学习遵循PARADISE框架,他们考虑两方面:对话花费(如轮数)和任务是否完成。对于对话系统方法的评价大概分为一下三类。
3.1 Automatic Evaluation
自动化评价被广泛地应用,因为它非常快速、容易且客观。它为每一个模块定义了自动化的度量:
- NLU:slot F1、intent accuracy
- DST:slot accuracy、joint state accuracy
- Policy Optimization:inform rate、match rate、task success rate
- NLG:BLEU、perplexity
3.2 Simulated Evaluation
在训练基于强化学习的机器人(agents)中,对话系统的一个用户模拟器模仿用户的行为也可以进行评估对话系统。因为,任务型对话系统的用户目标是某种可枚举的形式,以至于他能可行的去利用领域只是建立一个像人类一样进行交互的用户名模拟器,来进行仿真评估(simulated evaluation)。
主要的优点如下:
- 系统可通过一种end-to-end的方法进行评估
- 推断期间可以允许进行多轮的交互
- 综合对话数据能被充分地生成降低成本
3.3 Human Evaluation
人工评估还是需要的,比如simulated environment和真实对话的协数据转换、回答生成的质量。指标包括:任务完成率、重复轮数率、冗余轮数率、用户满意分数等。
一般来说都会将这个评估进行众包,然后大概被分为两种方式:
- 非直接评估:阅读模拟用户和对话系统之间的仿真对话,然后根据各项评分。
- 直接评估:直接与对话系统沟通进行评分。
四、语料
语料有单个领域的对话预料[21-24],也有多个领域的对话语料[25-27] ,还有中文的语料[28]。
有三种收集语料的方法:human-to-machine (H2M)、machine-to-machine (M2M)、humanto-human (H2H)。

五、挑战
5.1 Data Efficiency
任务型对话系统需要细粒度的标注数据,比如(diaglog act和state label)。但往往很难得到,因为一方面是特定领域的数据难以获取,另一方面标注需要大量人力。
解决的方法有如下:
1. 迁移学习
一般我们假设训练集和测试集有相同的分布,但真实世界不尽然。可能这个任务比较多数据,另一个任务比较少数据,迁移学习可以从source task到target task进行知识迁移。然后除了在领域级别的迁移,知识还能在许多维度进行迁移。
DQN policy经常用于用户之间的迁移,Q-function用于对所有的用户并且有个性化的一个对于特定的每个用户[29]。
还有在不同语言上进行迁移的。
另外一些强化学习方法也是可以做到的,比如ACER[30]、BBQ-Network[31]
2. 无监督学习
评估奖励信号对于对话策略学习(DP)是否非常重要的一个环节,特别是基于强化学习的。把DP作为一个生成器,把奖励函数作为一个鉴别器,GAN能够用于学习奖励函数,以一种无监督的方式。
很多学习方法中,对话系统的本体由该领域的人类专家进行精心的领域工程进行构建。另一条工作路线在这个工程中,是通过无标签的语料自动的学习对话结构。variational autoencoder (VAE)[32] 方法也曾经用在这个工作中。
3. 用户仿真User simulation
User simulation能够缓解基于RL的DP模型的数据接问题。早期的方法聚焦于agenda-base的user simulation(ABUS)[33],它使用探索式的方法使用一个像栈一样的结构表示用户的目标。建立一个agenda-based simulator需要人类专家定义对应的agenda和启发规则。但该方法缺乏对话系统的语言学变体,因此效果也一般。
近期,学者们提出使用数据驱动的方法进行构建User simulatior来解决上述问题。如,diag act level seq2seq user simulation mode、neural user simulator (NUS)[33]、hierarchical seq2seq user simulator (HUS)[34]、extended HUS to a variational version (VHUS)。
另外一个使用数据驱动训练user simulatior的方法,现在对话语料上使用监督学习训练simulator,然后使用强化学习微调所有模型。
以上的user simulator是基于human-agent对话数据进行训练的。
5.2 Multi-turn Dynamics
对比开放领域的对话系统,任务型对话系统除了关注生成可解释性、一致性、人性化回答,还要关注任务的完成。因此dialog management 扮演了一个非常重要的角色。
近年对于对话管理的研究主要集中在一下三个方面
1. Generative DST
DST扮演了一个非常重要的角色,最近的DST学习使用一个词级的结构,将自然语言作为输入而没有NLU,避免NLU导致的误差传递。早期的DST方法,belief state被广泛应用,因为当时DST被当作一个分类任务。还有人用RNN进行DST,然后将文本和ASR作为输入特征。Nikola等人还提出了Neural Belief Tracker(NBT)[2],一个词级的直接读取自然语言文本的DST。
最近,一些多领域的对话数据集的提出,与单领域的对比,他们需要去判断slot-values的领域值。
Wu等人提出TRADE,一个使用seq2seq模型的可变的多领域DST模型,去预测值。并且参数是在多个领域进行共享,使用zero-shot DST到许多不确定的领域。
COMER[35]仅有在第一次决定领域和slot的时候降低计算复杂性。
上述方法,都是先首次输入领域和slot名字给decoder,然后再决定他们的值。如果我们将领域和slot名字作为“问题的一种形式,那么该模型就会被看作是一个QA模型,把之前的轮数作为上下文,领域slot名字作为问题和问题的值。
DSTQA[36]加入更多的成分到“问题”,比如领域和slot的具体描述。还能用GNN。
2. Dialog Planning
早期的方法是使用Model-free RL方法进行Neural dialog policy。数据饥饿,需要大量的交互数据才能训练Policy model。一个常规的解决办法是使用user simulator,但又不能完全的模仿人类。
为了解决这些问题,提出了对环境进行建模,策划对话策略的学习。model-base RL方法,环境是被建模用于模仿动态的对话。Peng等提出了Deep Dyna-Q(DDQ)[37]框架,它融合了基于模型的策略到任务型对话系统。DDQ方法中,有一个世界模型,它是基于真实的用户体验进行训练,用来捕捉动态的环境。DP是通过所有的直接RL和真实的用户进行训练的,然后仿真RL是使用世界模型。训练期间,世界模型同时也被训练,它基于不断增长的真是经验和监督学习。世界模型的表现,对于策略学习非常重要,并且再训练期间持续性提高。但是,真实的概率vs模仿的经验是使用于Q-learning固定在最原始的DDQ框架,因此控制策略被提出用于缓解这个问题。
以上的方法都是参考back-ground planning,它使用世界模型在仿真经验中进行策略的训练。另一种方法是decision time planning,他是基于一些仿真经验,直接决定在状态St的情况下,接下来会是哪一个动作。
一些成果采用的是dialog rollout planning 到谈判对话中,他的agent仿真在特的那个状态St完整的对话的所有回答,并采用最高奖励的那个回答会被采用。
3. User Goal Estimation
RL-based对话模型中,用户目标很重要,奖励信号有间接反映用户目标,因为他能反映用户的满足度。一个典型的方法定义奖励函数是,通过分配大量积极的分数在成功的对话的结束阶段,然后分配小一点的分数在消极的样本,用这样的方式去激励短对话。在真实应用中,用户的目的是获取不到的情况,奖励也不能被有效地进行计算了。另一个问题是:通过真实用户客观的规律和主观的判断,奖励分数不连续。为了解决这些问题,一些研究通过学习无依赖的奖励函数来提供一个可靠的监督学习信号。
一种方法来评估奖励函数是通过标注数据,进行线下学习。然后奖励函数就可以被视为一个监督式的分类或者回归任务了。标注的分数不是从人工标注或者用户仿真进行得到了。缺点是,标注数据需要大量人力。
另一个方法是线上学习,奖励评估就可以被视为一个Gaussian Process regression任务。在这种情况下,采用主动学习来减少估计实际奖励信号的需求,在这种情况下,当不确定性得分超过阈值时,只要求用户提供反馈。
相比于通过标注的标签来评估奖励信号,Inverse RL(IRL)的目的是通过观察专业的示范去恢复奖励函数。Adversarial Learning经常用于对话奖励评估[38-39]。
5.3 Ontology Integration
对话系统的一个重要问题是把对话本体和对话模型进行融合,包括领域模式和知识库。许多之前的模型中,领域模式被预定义并且高度依赖于语料,比如,酒店领域的slot包括了:地址范围、烹饪方式、价格范围等等…查询数据库和检索结果作为产生结果的重要步骤,现在已经做了很多努力再整合延伸数据库和api调用方面。
本体融合变得更具有 挑战性,因为任务领域非常大量。虽然预定义本体能被考虑进模型,但这些方法能和领域schema结合且不能被轻易地迁移。虽然end-to-end方法缓解了这个schema integration问题,但它对上下文信息和知识数据库微不足道,不同于pipline方法,没有准确的dialog state表示去生成知识库的查询,然后就介绍了两种方法。
1. Schema Integration
Schema integration非常重要,原因是NLU和DST的值预测、在Policy的行动选择高度依赖于领域schema。早期的NLU方法使用分类器进行意图检测,使用序列标注进行槽值识别。因此schema integration主要反映在模型的输出层。早期的DST方法使用是,通过给定一个每个slot值的范围及基于其上面的概率分布进行表示。对于NLG方法,输入经常是dialog acts,编码输入结构是高度依赖于表示结构。
以上的schema方法大体上都是通过schema和model耦合在一起,而在可扩展性和领域泛化能力很弱。最近的方法都尝试解开domain scheme 和模型设计。Convlab[40]提供额外的用户对话行为标注,帮在MultiWOZ数据集[41]上,提高开发者将NLU模型应用于多领域、多意图的情况。COMER使用考虑用户在slot values上的表现的优先级操作,扩展对话状态的表示。其他工作使用QA的方法进行DST,他们使用领域slot描述作为问题,值作为答案。这种方式断开了和领域schema的联系,并且通过自然语言表达领域,这昂更容易进行知识迁移。对于NLG任内务,Peng等采用SC-GPT[42],它组织对话行为作为一个序列,并输入到生成模型。通过预训练大量的da-response对,模型能够有效地捕捉到基于序列的对话行为的语义结构。ZSDG[43]学习了一个跨领域的嵌入式空间,并且能通过使用最少的数据生成新的状态。
2. Knowledge Base Integration
查外部知识库来获取用户需要的信息也非常重要。早期方法或者pipline系统,在对话期间,通过发出一个基于目前对话状态信息的query,从知识库中查询所需记录。不用中间的监督学习,训练一个end-to-end对话系统,这回更吸引人,因为对话情景不断地复杂。和pipline不同的是,end-to-end模型中没有准确的结构来表示对话状态。因此在end-to-end地训练中,知识库的交互是通过使用中介的潜在表示模型,并通过无缝地训练。
CopyNet和End-to-end Memory Networks被广泛用于通过注意力机制,将知识融入对话系统。复制机制,可以被看作是一个记忆网络,他的隐藏层由记忆单元组成。Eric等[44]使用一个基于copy地方法,它依赖于潜在地自然嵌入来参照对话历史和copy相关的之前的文本进行decoding。但是他们只能生成提到过的实体。最近的工作中使用记忆网络对之前的文本和知识进行融合,这些方法中,对话上下文和知识库分别用了两个记忆网络;然后在解码部分,解码器的隐藏状态被用于从记忆中选择查询和复制的信息。一个关键性问题是,对话文本和知识库是从不同源的信息中进行异构组成的。Lin等[45],提出通用存储上下文意识记忆的历史信息,并且将数据库的元组存储到一个context-free记忆中。还有一种两步KB检索,通过先决定实体所在的row,然后选择向相关的额KB列,来用于改善实体之间的一致性。
对于不适用介质监督的、完全的end-to-end方法,有一些end-to-ed模型通过对话行为和belief state标注,整合领域先前的知识到模型。Williams等[46]提出了hybrid code networks (HCNs),结合RNN和领域知识编码作为软件和模板,减少对训练数据的需求。Wen等[47]使用一个模块化的end-to-end任务型对话系统,通过结合多个预训练成分,然后使用RL模型进行微调。但是以上方法,相比于seq2seq模型,更像是pipline的简化版。
六、讨论和趋势
预训练模型:准确捕捉语义知识,从大规模数据中学习
领域适应:就是迁移学习的问题
健壮性:情景不断复杂、精度要求又很高,比如医疗系统
端到端模型:目前的端到端模型并不是真正的端到端,可能还是需要结合及一些基于规则的方法,比如Neural Symbolic Mechine
参考文献
[1]Hongshen Chen, Xiaorui Liu, Dawei Yin, and Jiliang Tang. A survey on dialogue systems: Recent advances and new frontiers. Acm Sigkdd Explorations Newsletter, 19(2):25–35, 2017
[2]Nikola Mrksiˇ c, Diarmuid ´ O S ´ eaghdha, Tsung-Hsien Wen, Blaise ´ Thomson, and Steve Young. Neural belief tracker: Data-driven dialogue state tracking. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1777–1788, 2017.
[3] Chien-Sheng Wu, Andrea Madotto, Ehsan Hosseini-Asl, Caiming Xiong, Richard Socher, and Pascale Fung. Transferable multi-domain state generator for task-oriented dialogue systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 808–819, Florence, Italy, July 2019. Association for Computational Linguistics.
[4] Tiancheng Zhao, Kaige Xie, and Maxine Eskenazi. Rethinking action spaces for reinforcement learning in end-to-end dialog agents with latent variable models. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1208–1218, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics.
[5] Wenhu Chen, Jianshu Chen, Pengda Qin, Xifeng Yan, and William Yang Wang. Semantically conditioned dialog response generation via hierarchical disentangled self-attention. arXiv preprint arXiv:1905.12866, 2019
[6]Kaisheng Yao, Geoffrey Zweig, Mei-Yuh Hwang, Yangyang Shi, and Dong Yu. Recurrent neural networks for language understanding. In INTERSPEECH, 2013.
[7] Kaisheng Yao, Baolin Peng, Yu Zhang, Dong Yu, Geoffrey Zweig, and Yangyang Shi. Spoken language understanding using long shorterm memory neural networks. In IEEE Spoken Language Technology Workshop, 2014.
[8] Dilek Hakkani-Tur, G ¨ okhan T ¨ ur, Asli C¸ elikyilmaz, Yun-Nung Chen, ¨ Jianfeng Gao, Li Deng, and Ye-Yi Wang. Multi-domain joint semantic frame parsing using bi-directional RNN-LSTM. In INTERSPEECH, 2016.
[9]Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT, 2019.
[10] Qian Chen, Zhu Zhuo, and Wen Wang. BERT for joint intent classification and slot filling. arXiv preprint arXiv:1902.10909, 2019.
[11]Giuseppe Castellucci, Valentina Bellomaria, Andrea Favalli, and Raniero Romagnoli. Multi-lingual intent detection and slot filling in a joint bert-based model. arXiv preprint arXiv:1907.02884, 2019.
[12] Steve Young, Milica Gasiˇ c, Blaise Thomson, and Jason D Williams. ´ Pomdp-based statistical spoken dialog systems: A review. Proceedings of the IEEE, 101(5):1160–1179, 2013.
[13] Steve Young. Using pomdps for dialog management. In 2006 IEEE Spoken Language Technology Workshop, pages 8–13. IEEE, 2006.
[14]Jason D Williams and Steve Young. Scaling up pomdps for dialog management: The“summary pomdp”method. In IEEE Workshop on Automatic Speech Recognition and Understanding, 2005., pages 177–182. IEEE, 2005.
[15]Jost Schatzmann, Blaise Thomson, Karl Weilhammer, Hui Ye, and Steve Young. Agenda-based user simulation for bootstrapping a pomdp dialogue system. In Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Companion Volume, Short Papers, pages 149–152. Association for Computational Linguistics, 2007.
[16]28 Shuyang Gao, Abhishek Sethi, Sanchit Agarwal, Tagyoung Chung, and Dilek Hakkani-Tur. Dialog state tracking: A neural reading comprehension approach. In Proceedings of the 20th Annual SIGdial Meeting on Discourse and Dialogue, pages 264–273, Stockholm, Sweden, September 2019. Association for Computational
[17]Linguistics. 29 Julien Perez. Machine reading method for dialog state tracking, January 21 2020. US Patent 10,540,967.
[18] Baolin Peng, Xiujun Li, Jianfeng Gao, Jingjing Liu, and Kam-Fai Wong. Deep Dyna-Q: Integrating planning for task-completion dialogue policy learning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2182–2192, Melbourne, Australia, July 2018.
[19]Association for Computational Linguistics. 41 Yuexin Wu, Xiujun Li, Jingjing Liu, Jianfeng Gao, and Yiming Yang. Switch-based active deep dyna-q: Efficient adaptive planning for task-completion dialogue policy learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 7289–7296, 2019.
[20] Shang-Yu Su, Xiujun Li, Jianfeng Gao, Jingjing Liu, and Yun-Nung Chen. Discriminative deep Dyna-q: Robust planning for dialogue policy learning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3813–3823, Brussels, Belgium, October-November 2018. Association for Computational Linguistics.
[21]Tsung-Hsien Wen, David Vandyke, Nikola Mrksiˇ c, Milica Gasic, ´ Lina M Rojas Barahona, Pei-Hao Su, Stefan Ultes, and Steve Young. A network-based end-to-end trainable task-oriented dialogue system. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 438–449, 2017
[22]Mihail Eric, Lakshmi Krishnan, Francois Charette, and Christopher D Manning. Key-value retrieval networks for task-oriented dialogue. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, pages 37–49, 2017
[23] Matthew Henderson, Blaise Thomson, and Jason D Williams. The second dialog state tracking challenge. In Proceedings of the 15th annual meeting of the special interest group on discourse and dialogue (SIGDIAL), pages 263–272, 2014.
[24]Layla El Asri, Hannes Schulz, Shikhar Kr Sarma, Jeremie Zumer, Justin Harris, Emery Fine, Rahul Mehrotra, and Kaheer Suleman. Frames: a corpus for adding memory to goal-oriented dialogue systems. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, pages 207–219, 2017.
[25]Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Inigo ˜ Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gasic. Multiwoz-a large-scale multi-domain wizard-of-oz dataset for taskoriented dialogue modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 5016– 5026, 2018.
[26] Denis Peskov, Nancy Clarke, Jason Krone, Brigi Fodor, Yi Zhang, Adel Youssef, and Mona Diab. Multi-domain goal-oriented dialogues (multidogo): Strategies toward curating and annotating large scale dialogue data. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLPIJCNLP), pages 4518–4528, 2019.
[27] Bill Byrne, Karthik Krishnamoorthi, Chinnadhurai Sankar, Arvind Neelakantan, Ben Goodrich, Daniel Duckworth, Semih Yavuz, Amit Dubey, Kyu-Young Kim, and Andy Cedilnik. Taskmaster-1: Toward a realistic and diverse dialog dataset. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4506–4517, 2019.
[28] Qi Zhu, Kaili Huang, Zheng Zhang, Xiaoyan Zhu, and Minlie Huang. Crosswoz: A large-scale chinese cross-domain task-oriented dialogue dataset. Transactions of the Association for Computational Linguistics, 2020.
[29]Kaixiang Mo, Yu Zhang, Shuangyin Li, Jiajun Li, and Qiang Yang. Personalizing a dialogue system with transfer reinforcement learning. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[30] Gellert Weisz, Paweł Budzianowski, Pei-Hao Su, and Milica Ga ´ siˇ c.´ Sample efficient deep reinforcement learning for dialogue systems with large action spaces. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(11):2083–2097, 2018.
[31]Zachary Lipton, Xiujun Li, Jianfeng Gao, Lihong Li, Faisal Ahmed, and Li Deng. Bbq-networks: Efficient exploration in deep reinforcement learning for task-oriented dialogue systems. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[32]Weiyan Shi, Tiancheng Zhao, and Zhou Yu. Unsupervised dialog structure learning. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1797–1807, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics.
[33]Jost Schatzmann, Blaise Thomson, Karl Weilhammer, Hui Ye, and Steve Young. Agenda-based user simulation for bootstrapping a pomdp dialogue system. In Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Companion Volume, Short Papers, pages 149–152. Association for Computational Linguistics, 2007.
[33]Florian Kreyssig, Inigo Casanueva, Paweł Budzianowski, and Milica ˜ Gasic. Neural user simulation for corpus-based policy optimisation of spoken dialogue systems. In Proceedings of the 19th Annual SIGdial Meeting on Discourse and Dialogue, pages 60–69, 2018.
[34]Izzeddin Gur, Dilek Hakkani-T ¨ ur, Gokhan T ¨ ur, and Pararth Shah. ¨ User modeling for task oriented dialogues. In 2018 IEEE Spoken Language Technology Workshop (SLT), pages 900–906. IEEE, 2018.
[35]Liliang Ren, Jianmo Ni, and Julian McAuley. Scalable and accurate dialogue state tracking via hierarchical sequence generation. arXiv preprint arXiv:1909.00754, 2019.
[36]Liliang Ren, Jianmo Ni, and Julian McAuley. Scalable and accurate dialogue state tracking via hierarchical sequence generation. arXiv preprint arXiv:1909.00754, 2019.
[37]Baolin Peng, Xiujun Li, Jianfeng Gao, Jingjing Liu, and Kam-Fai Wong. Deep Dyna-Q: Integrating planning for task-completion dialogue policy learning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2182–2192, Melbourne, Australia, July 2018. Association for Computational Linguistics.
[38] Bing Liu and Ian Lane. Adversarial learning of task-oriented neural dialog models. arXiv preprint arXiv:1805.11762, 2018.
[39] Ryuichi Takanobu, Hanlin Zhu, and Minlie Huang. Guided dialog policy learning: Reward estimation for multi-domain task-oriented dialog. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 100–110, 2019
[40] Sungjin Lee, Qi Zhu, Ryuichi Takanobu, Zheng Zhang, Yaoqin Zhang, Xiang Li, Jinchao Li, Baolin Peng, Xiujun Li, Minlie Huang, et al. Convlab: Multi-domain end-to-end dialog system platform. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 64–69, 2019
[41] Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Inigo ˜ Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gasic. Multiwoz-a large-scale multi-domain wizard-of-oz dataset for taskoriented dialogue modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 5016– 5026, 2018
[42] Baolin Peng, Chenguang Zhu, Chunyuan Li, Xiujun Li, Jinchao Li, Michael Zeng, and Jianfeng Gao. Few-shot natural language generation for task-oriented dialog. arXiv preprint arXiv:2002.12328, 2020.
[43] Baolin Peng, Chenguang Zhu, Chunyuan Li, Xiujun Li, Jinchao Li, Michael Zeng, and Jianfeng Gao. Few-shot natural language generation for task-oriented dialog. arXiv preprint arXiv:2002.12328, 2020.
[44] Mihail Eric and Christopher D Manning. A copy-augmented sequence-to-sequence architecture gives good performance on taskoriented dialogue. arXiv preprint arXiv:1701.04024, 2017
[45] Zehao Lin, Xinjing Huang, Feng Ji, Haiqing Chen, and Ying Zhang. Task-oriented conversation generation using heterogeneous memory networks. arXiv preprint arXiv:1909.11287, 2019
[46]Jason D. Williams, Kavosh Asadi, and Geoffrey Zweig. Hybrid code networks: practical and efficient end-to-end dialog control with supervised and reinforcement learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 665–677, Vancouver, Canada, July 2017. Association for Computational Linguistics.
[47]Tsung-Hsien Wen, David Vandyke, Nikola Mrksiˇ c, Milica Gasic, ´ Lina M Rojas Barahona, Pei-Hao Su, Stefan Ultes, and Steve Young. A network-based end-to-end trainable task-oriented dialogue system. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 438–449, 2017.