(CoaT)Co-Scale Conv-Attentional Image Transformers
文章目录
- Co-Scale Conv-Attentional Image Transformers
- 一、Conv-Attention Module
-
- 1.代码
- 二、Co-Scale Conv-Attentional Transformers
-
- 1.代码
Co-Scale Conv-Attentional Image Transformers
- 提出一种新的atten计算方法-Factorized Attention
- 提出一种新的相对位置编码方法,通过atten中的q和v来计算相对位置编码
- 运用了卷积位置编码,通过对atten计算前的tokens运用卷积来获得位置编码
- 提出一种多尺度backbone结构-CoaT Serial Block
- 提出一种多尺度解码器结构-CoaT Parallel Block

一、Conv-Attention Module
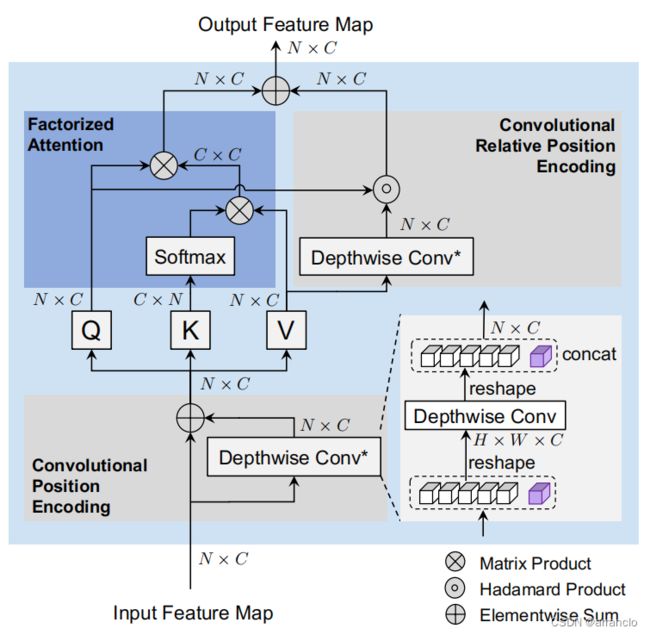
- Factorized Attention Mechanism
- Convolutional Relative Position Encoding
- Convolutional Position Encoding
1.代码
FactorAtt_ConvRelPosEnc:qkv由线性层得到,分出head维后,先将k的转置和v相乘,再将q与前面结果相乘,加上相对位置编码,再经过一个线性层后得到输出。
class FactorAtt_ConvRelPosEnc(nn.Module):
""" Factorized attention with convolutional relative position encoding class. """
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., shared_crpe=None):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop) # Note: attn_drop is actually not used.
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# Shared convolutional relative position encoding.
self.crpe = shared_crpe
def forward(self, x, size):
B, N, C = x.shape
# Generate Q, K, V.
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # Shape: [3, B, h, N, Ch].
q, k, v = qkv[0], qkv[1], qkv[2] # Shape: [B, h, N, Ch].
# Factorized attention.
k_softmax = k.softmax(dim=2) # Softmax on dim N.
k_softmax_T_dot_v = einsum('b h n k, b h n v -> b h k v', k_softmax, v) # Shape: [B, h, Ch, Ch].
factor_att = einsum('b h n k, b h k v -> b h n v', q, k_softmax_T_dot_v) # Shape: [B, h, N, Ch].
# Convolutional relative position encoding.
crpe = self.crpe(q, v, size=size) # Shape: [B, h, N, Ch].
# Merge and reshape.
x = self.scale * factor_att + crpe
x = x.transpose(1, 2).reshape(B, N, C) # Shape: [B, h, N, Ch] -> [B, N, h, Ch] -> [B, N, C].
# Output projection.
x = self.proj(x)
x = self.proj_drop(x)
return x # Shape: [B, N, C].
ConvRelPosEnc:将v的head维合入到通道维,按照head数将通道维分为三份,形成三份v,对每份v进行不同的Depthwise-Conv(通过分组卷积实现,组数等于通道数,即每个通道一个卷积核),卷积的kernel-size不同,但卷积后的HW和C不变,将卷积后的三份v按C连接成一份v,再让q和v按元素相乘,cat上由0初始化的对应CLS_token的位置编码,形成最终的位置编码。
class ConvRelPosEnc(nn.Module):
""" Convolutional relative position encoding. """
def __init__(self, Ch, h, window): # window {3:2, 5:3, 7:3}
"""
Initialization.
Ch: Channels per head.
h: Number of heads.
window: Window size(s) in convolutional relative positional encoding. It can have two forms:
1. An integer of window size, which assigns all attention heads with the same window size in ConvRelPosEnc.
2. A dict mapping window size to #attention head splits (e.g. {window size 1: #attention head split 1, window size 2: #attention head split 2})
It will apply different window size to the attention head splits.
"""
super().__init__()
if isinstance(window, int):
window = {window: h} # Set the same window size for all attention heads.
self.window = window
elif isinstance(window, dict):
self.window = window
else:
raise ValueError()
self.conv_list = nn.ModuleList()
self.head_splits = []
for cur_window, cur_head_split in window.items(): # {3:2, 5:3, 7:3}
dilation = 1 # Use dilation=1 at default.
padding_size = (cur_window + (cur_window - 1) * (dilation - 1)) // 2 # Determine padding size. Ref: https://discuss.pytorch.org/t/how-to-keep-the-shape-of-input-and-output-same-when-dilation-conv/14338
cur_conv = nn.Conv2d(cur_head_split*Ch, cur_head_split*Ch, # 通道数不变
kernel_size=(cur_window, cur_window), # stride的默认值为1
padding=(padding_size, padding_size), # 卷积后HW不变
dilation=(dilation, dilation),
groups=cur_head_split*Ch, # 组数等于输入通道数
)
self.conv_list.append(cur_conv)
self.head_splits.append(cur_head_split) # Ch是每个head的通道数
self.channel_splits = [x*Ch for x in self.head_splits] # 把通道维度分为几份,每份的数量为Ch的整数倍,相当于每几个head为一份
def forward(self, q, v, size):
B, h, N, Ch = q.shape
H, W = size
assert N == 1 + H * W
# Convolutional relative position encoding.
q_img = q[:,:,1:,:] # Shape: [B, h, H*W, Ch].
v_img = v[:,:,1:,:] # Shape: [B, h, H*W, Ch].
v_img = rearrange(v_img, 'B h (H W) Ch -> B (h Ch) H W', H=H, W=W) # Shape: [B, h, H*W, Ch] -> [B, h*Ch, H, W].
v_img_list = torch.split(v_img, self.channel_splits, dim=1) # Split according to channels. 将v按照通道维度分为多份,(2*Ch, 3*Ch, 3*Ch)
conv_v_img_list = [conv(x) for conv, x in zip(self.conv_list, v_img_list)] # 对每份v分别做卷积,每份通道数不变,HW不变,kernel-size不同 (3, 5, 7)
conv_v_img = torch.cat(conv_v_img_list, dim=1) # 将每份v重新cat成一份v,通道数不变
conv_v_img = rearrange(conv_v_img, 'B (h Ch) H W -> B h (H W) Ch', h=h) # Shape: [B, h*Ch, H, W] -> [B, h, H*W, Ch].
EV_hat_img = q_img * conv_v_img # 每个元素相乘
zero = torch.zeros((B, h, 1, Ch), dtype=q.dtype, layout=q.layout, device=q.device) # 对应CLS_token
EV_hat = torch.cat((zero, EV_hat_img), dim=2) # Shape: [B, h, N, Ch].
return EV_hat
ConvPosEnc:将计算atten前的tokens分离出cls_token再经过一个输入前后HW和C都不变的卷积,得到位置编码,加上位置编码再cat上cls_token得到输出。
class ConvPosEnc(nn.Module):
""" Convolutional Position Encoding.
Note: This module is similar to the conditional position encoding in CPVT.
"""
def __init__(self, dim, k=3):
super(ConvPosEnc, self).__init__()
self.proj = nn.Conv2d(dim, dim, k, 1, k//2, groups=dim)
def forward(self, x, size):
B, N, C = x.shape
H, W = size
assert N == 1 + H * W
# Extract CLS token and image tokens.
cls_token, img_tokens = x[:, :1], x[:, 1:] # Shape: [B, 1, C], [B, H*W, C].
# Depthwise convolution.
feat = img_tokens.transpose(1, 2).view(B, C, H, W)
x = self.proj(feat) + feat # self.proj(feat) 卷积位置编码
x = x.flatten(2).transpose(1, 2)
# Combine with CLS token.
x = torch.cat((cls_token, x), dim=1)
return x
二、Co-Scale Conv-Attentional Transformers
- CoaT Serial Block:
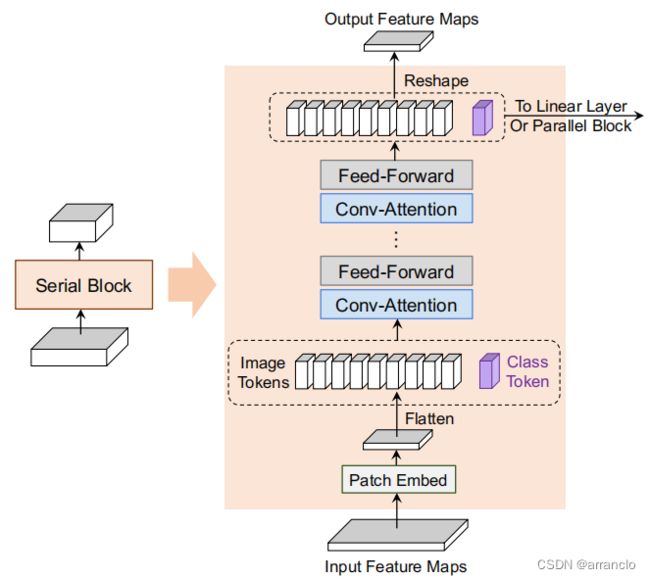
- CoaT Parallel Block:

1.代码
CoaT的forward函数:
- encoder:每个stage通过通过patch_embed和后面的reshape来降低特征图的HW,每个stage有一个单独初始化的cls_token,tokens在传入SerialBlocks前cat上cls_token,传入后分离,再传入下一个stage进行迭代
- decoder:将encoder里每个stage中传入SerialBlocks后还未分离cls_token的tokens及其特征图的HW共同传入ParallelBlocks,最终可以返回多尺度的特征图或者经过cat和aggregate的最终的cls_token
def forward_features(self, x0):
B = x0.shape[0]
# Serial blocks 1.
x1, (H1, W1) = self.patch_embed1(x0) # 通过patch_embed(卷积加flatten)和后面的reshape回三维来进行降低HW
x1 = self.insert_cls(x1, self.cls_token1) # 每个stage有一个单独初始化的cls_token
for blk in self.serial_blocks1:
x1 = blk(x1, size=(H1, W1)) # SerialBlocks (pos-enc、atten、mlp)
x1_nocls = self.remove_cls(x1) # 去掉cls_token,以便于传入下一个stage
x1_nocls = x1_nocls.reshape(B, H1, W1, -1).permute(0, 3, 1, 2).contiguous() # reshape回三维,传入下一个stage
# Serial blocks 2.
x2, (H2, W2) = self.patch_embed2(x1_nocls)
x2 = self.insert_cls(x2, self.cls_token2)
for blk in self.serial_blocks2:
x2 = blk(x2, size=(H2, W2))
x2_nocls = self.remove_cls(x2)
x2_nocls = x2_nocls.reshape(B, H2, W2, -1).permute(0, 3, 1, 2).contiguous()
# Serial blocks 3.
x3, (H3, W3) = self.patch_embed3(x2_nocls)
x3 = self.insert_cls(x3, self.cls_token3)
for blk in self.serial_blocks3:
x3 = blk(x3, size=(H3, W3))
x3_nocls = self.remove_cls(x3)
x3_nocls = x3_nocls.reshape(B, H3, W3, -1).permute(0, 3, 1, 2).contiguous()
# Serial blocks 4.
x4, (H4, W4) = self.patch_embed4(x3_nocls)
x4 = self.insert_cls(x4, self.cls_token4)
for blk in self.serial_blocks4:
x4 = blk(x4, size=(H4, W4))
x4_nocls = self.remove_cls(x4)
x4_nocls = x4_nocls.reshape(B, H4, W4, -1).permute(0, 3, 1, 2).contiguous()
# Only serial blocks: Early return.
if self.parallel_depth == 0:
if self.return_interm_layers: # Return intermediate features for down-stream tasks (e.g. Deformable DETR and Detectron2).
feat_out = {}
if 'x1_nocls' in self.out_features:
feat_out['x1_nocls'] = x1_nocls
if 'x2_nocls' in self.out_features:
feat_out['x2_nocls'] = x2_nocls
if 'x3_nocls' in self.out_features:
feat_out['x3_nocls'] = x3_nocls
if 'x4_nocls' in self.out_features:
feat_out['x4_nocls'] = x4_nocls
return feat_out
else: # Return features for classification.
x4 = self.norm4(x4)
x4_cls = x4[:, 0]
return x4_cls
# Parallel blocks.
for blk in self.parallel_blocks:
x1, x2, x3, x4 = blk(x1, x2, x3, x4, sizes=[(H1, W1), (H2, W2), (H3, W3), (H4, W4)]) # 传入的是不同stage的cat了cls_token的经过了SerialBlocks的多尺度特征图
if self.return_interm_layers: # Return intermediate features for down-stream tasks (e.g. Deformable DETR and Detectron2).
feat_out = {} # 返回特征图,做其他任务
if 'x1_nocls' in self.out_features:
x1_nocls = self.remove_cls(x1)
x1_nocls = x1_nocls.reshape(B, H1, W1, -1).permute(0, 3, 1, 2).contiguous()
feat_out['x1_nocls'] = x1_nocls
if 'x2_nocls' in self.out_features:
x2_nocls = self.remove_cls(x2)
x2_nocls = x2_nocls.reshape(B, H2, W2, -1).permute(0, 3, 1, 2).contiguous()
feat_out['x2_nocls'] = x2_nocls
if 'x3_nocls' in self.out_features:
x3_nocls = self.remove_cls(x3)
x3_nocls = x3_nocls.reshape(B, H3, W3, -1).permute(0, 3, 1, 2).contiguous()
feat_out['x3_nocls'] = x3_nocls
if 'x4_nocls' in self.out_features:
x4_nocls = self.remove_cls(x4)
x4_nocls = x4_nocls.reshape(B, H4, W4, -1).permute(0, 3, 1, 2).contiguous()
feat_out['x4_nocls'] = x4_nocls
return feat_out
else: # 做分类
x2 = self.norm2(x2)
x3 = self.norm3(x3)
x4 = self.norm4(x4)
x2_cls = x2[:, :1] # Shape: [B, 1, C].
x3_cls = x3[:, :1]
x4_cls = x4[:, :1]
merged_cls = torch.cat((x2_cls, x3_cls, x4_cls), dim=1) # Shape: [B, 3, C].
merged_cls = self.aggregate(merged_cls).squeeze(dim=1) # Shape: [B, C]. # torch.nn.Conv1d
return merged_cls
SerialBlock:Convolution Position Encoding、Convolutional Relative Position Encoding、Factorized Attention、MLP
class SerialBlock(nn.Module):
""" Serial block class.
Note: In this implementation, each serial block only contains a conv-attention and a FFN (MLP) module. """
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,
shared_cpe=None, shared_crpe=None):
super().__init__()
# Conv-Attention.
self.cpe = shared_cpe
self.norm1 = norm_layer(dim)
self.factoratt_crpe = FactorAtt_ConvRelPosEnc(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpe)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
# MLP.
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, size):
# Conv-Attention.
x = self.cpe(x, size) # Apply convolutional position encoding.
cur = self.norm1(x)
cur = self.factoratt_crpe(cur, size) # Apply factorized attention and convolutional relative position encoding.
x = x + self.drop_path(cur)
# MLP.
cur = self.norm2(x)
cur = self.mlp(cur)
x = x + self.drop_path(cur)
return x
ParallelBlock:除第一个stage的特征图外,对每个stage的特征图运用Convolution Position Encoding、Convolutional Relative Position Encoding和Factorized Attention,然后将每个stage的输出加上另外两个stage经过上/下采样后的输出,再经过一层mlp,得到最终多尺度的输出(第一个stage的特征图不做处理直接输出)。
class ParallelBlock(nn.Module):
""" Parallel block class. """
def __init__(self, dims, num_heads, mlp_ratios=[], qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,
shared_cpes=None, shared_crpes=None):
super().__init__()
# Conv-Attention.
self.cpes = shared_cpes
self.norm12 = norm_layer(dims[1])
self.norm13 = norm_layer(dims[2])
self.norm14 = norm_layer(dims[3])
self.factoratt_crpe2 = FactorAtt_ConvRelPosEnc(
dims[1], num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[1]
)
self.factoratt_crpe3 = FactorAtt_ConvRelPosEnc(
dims[2], num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[2]
)
self.factoratt_crpe4 = FactorAtt_ConvRelPosEnc(
dims[3], num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[3]
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
# MLP.
self.norm22 = norm_layer(dims[1])
self.norm23 = norm_layer(dims[2])
self.norm24 = norm_layer(dims[3])
assert dims[1] == dims[2] == dims[3] # In parallel block, we assume dimensions are the same and share the linear transformation.
assert mlp_ratios[1] == mlp_ratios[2] == mlp_ratios[3]
mlp_hidden_dim = int(dims[1] * mlp_ratios[1])
self.mlp2 = self.mlp3 = self.mlp4 = Mlp(in_features=dims[1], hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def upsample(self, x, output_size, size):
""" Feature map up-sampling. """
return self.interpolate(x, output_size=output_size, size=size)
def downsample(self, x, output_size, size):
""" Feature map down-sampling. """
return self.interpolate(x, output_size=output_size, size=size)
def interpolate(self, x, output_size, size):
""" Feature map interpolation. """
B, N, C = x.shape
H, W = size
assert N == 1 + H * W
cls_token = x[:, :1, :]
img_tokens = x[:, 1:, :]
img_tokens = img_tokens.transpose(1, 2).reshape(B, C, H, W)
img_tokens = F.interpolate(img_tokens, size=output_size, mode='bilinear') # FIXME: May have alignment issue.
img_tokens = img_tokens.reshape(B, C, -1).transpose(1, 2)
out = torch.cat((cls_token, img_tokens), dim=1)
return out
def forward(self, x1, x2, x3, x4, sizes):
_, (H2, W2), (H3, W3), (H4, W4) = sizes
# Conv-Attention.
x2 = self.cpes[1](x2, size=(H2, W2)) # Note: x1 is ignored.
x3 = self.cpes[2](x3, size=(H3, W3))
x4 = self.cpes[3](x4, size=(H4, W4))
cur2 = self.norm12(x2)
cur3 = self.norm13(x3)
cur4 = self.norm14(x4)
cur2 = self.factoratt_crpe2(cur2, size=(H2,W2))
cur3 = self.factoratt_crpe3(cur3, size=(H3,W3))
cur4 = self.factoratt_crpe4(cur4, size=(H4,W4))
upsample3_2 = self.upsample(cur3, output_size=(H2,W2), size=(H3,W3))
upsample4_3 = self.upsample(cur4, output_size=(H3,W3), size=(H4,W4))
upsample4_2 = self.upsample(cur4, output_size=(H2,W2), size=(H4,W4))
downsample2_3 = self.downsample(cur2, output_size=(H3,W3), size=(H2,W2))
downsample3_4 = self.downsample(cur3, output_size=(H4,W4), size=(H3,W3))
downsample2_4 = self.downsample(cur2, output_size=(H4,W4), size=(H2,W2))
cur2 = cur2 + upsample3_2 + upsample4_2
cur3 = cur3 + upsample4_3 + downsample2_3
cur4 = cur4 + downsample3_4 + downsample2_4
x2 = x2 + self.drop_path(cur2)
x3 = x3 + self.drop_path(cur3)
x4 = x4 + self.drop_path(cur4)
# MLP.
cur2 = self.norm22(x2)
cur3 = self.norm23(x3)
cur4 = self.norm24(x4)
cur2 = self.mlp2(cur2)
cur3 = self.mlp3(cur3)
cur4 = self.mlp4(cur4)
x2 = x2 + self.drop_path(cur2)
x3 = x3 + self.drop_path(cur3)
x4 = x4 + self.drop_path(cur4)
return x1, x2, x3, x4