YOLO论文总结
YOLO总结
- YOLO总结
- 目录
- 一、YOLOv1
-
- 1.1 基本理念
- 1.2 YOLO网络结构
- 1.3 YOLO解析
- 1.4 YOLOv1的一些说明
-
- 二、YOLOv2
-
- 2.1 多种技术
- 2.1.1 Batch Norm
- 2.1.2 High Resolution Classifer
- 2.1.3 Convolutional with anchor
- 2.1.4 采用k-means计算anchor尺寸
- 2.1.5 新网络结构-Darknet-19
- 2.1.6 直接定位预测(Direct location prediction)
- 2.1.7 细粒度特征
- 2.1.8 多尺度输入的训练方式
- 2.2 损失函数
- 2.1 多种技术
-
- 三、YOLOv3
-
-
- 3.1 使用残差网络结构
- 3.2使用FPN网络结构
- 3.3 其他尝试
-
-
- 四、总结
- 1)存在的问题
- 2)受到的启示
- 参考文献
目录
一、YOLOv1
1.1 基本理念
YOLO直接将原始图分割成互不重合的小方块,然后利用卷积操作的空间不变性,最终输出网格(grid)形式的fmps,grid的每个单元方格(cell)对应着原始图的一个方块区域;最后用每个cell预测那些中心点在给cell的目标(GT)。如下图所示,为输出grid与原图区域对应关系简约示意图

1.2 YOLO网络结构
下图是YOLOv1的网络结构示意图(来源于论文),可以清晰地看出网络框架的设计,从原图输入到预测网格(Grid)的输出;关于具体细节——原图如何映射到输出Grid上的;下节YOLO解析会给出解析示意图。

1.3 YOLO解析
根据下图所示,YOLO识别是通过对原图进行稀疏采样(才49个区域采样),然后对含有对象的区域(即该对象中心点落入该区域中)进行损失计算;只有 Priou P r i o u 的计算才是对所有采样区域进行计算。

1.4 YOLOv1的一些说明
- YOLO计算时,将GT大小映射到(0,1)之间,方便代码执行时的转换;
- YOLO的激活函数采用的是Leaky ReLU, 而不是ReLU(PReLU,Leaky ReLU有时可代替ReLU,能取得更好的效果)
- 关于最后Grid每个cell都预测30个值,这30个值的划分如上图所示,具体解释如下
- 20: 类别预测,每个cell只预测一套分类概率值(class predictions,其实是置信度下的条件概率值),被两个box共享使用。
- 2:是两个 Priou∗IOUtruthpred P r i o u ∗ I O U p r e d t r u t h ,也就是只有当 Priou P r i o u =1,也就是含有对象的那3个cell,才有对 IOUtruthpred I O U p r e d t r u t h 的预测,其他cell的iou预测都为0。在执行预测时,这两个值需要与类别预测的输出概率(20的softmax输出)相乘得到最终的预测确信度。
- 8:是两个坐标预测,每个(x,y,w,h);需要注意的是这个坐标不同于Fast RCNN中给出的计算,中心坐标的预测值 (x,y) 是相对于每个单元格左上角坐标点的偏移量(偏移值的归一化),并且单位是相对于单元格大小的, x^=xGTcenter−xgridtopleft x ^ = x c e n t e r G T − x t o p l e f t g r i d ,w,h则是相对于原图的大小(YOLOv1没有用anchor,因而是指将w,h归一化).

- 注意输入的图都要resize成(size,size);
二、YOLOv2
对YOLOv1存在的一些不足进行了改进,如下图所示,添加了多种技术:

注:暂不介绍YOLO9000
2.1 多种技术
2.1.1 Batch Norm
BN技术能提升模型收敛速度且有一定防止过拟合作用,YOLOv2中每个卷积层后添加了BN,且去掉了dropout技术;带来了2.4%的精度提升。
2.1.2 High Resolution Classifer
这个技术的意思是说,在YOLO训练前,网络参数是先在ImageNet数据集上做分类任务学习来的;而一般ImageNet上做分类任务时,输入图片大小是224*224;然这种低分辨率的学习,不利于目标检测模型,因而论文中改进了Imagenet上训练时的输入大小,使用了448*448的图片作为输入,训练识别高分辨率的分类器;使用这一trick,YOLOv2提升4%;高分辨率对模型性能影响还是很大的。
2.1.3 Convolutional with anchor
- YOLOv1使用全连接层,将图划分成7x7网格进行预测,然而这种方式在训练中需要模型学习适应不同物体的形状比较困难,导致精度定位方面表现较差。因而YOLOv2打算采用Faster RCNN中RPN中的anchor技术——这项技术使得模型易于学习(也就是将模型框的预测转化为对已知窗体transform预测,预测先验框的offset值),因此,作者去掉全连接层,用卷积层和anchor box用来预测对象框。
- 为了提高分辨率,去掉最后一个pool层
- 一般不使用mutli scale作为输入时,输入采用416*416, 而不是448*448;因为416*416的输入,能产生13*13的grid,这样能使中心有一个cell;这样的好处是:对于大物体而言,他们中心点往往落入图片中心位置,此时用特征图中心cell去预测这些物体的对象框会相对容易些(有待考察);
- 相对于YOLOv1,YOLOv2每个cell预测5个框,每个框都有独立的类别概率预测,也就是每个cell输出长度为5*(20+4+1) = 125。注意这种方式与SSD很是类似,当时不同的是:SSD将bg作为一个新类别进行预测,没有置信度IOU的预测;而YOLO预测置信度IOU,从而区分了bg与pos。注:置信度预测技巧与将bg作为新类别单独预测的技巧,具有异曲同工之妙
- 使用anchor技术之后,导致了mAP稍微下降(可能YOLOv2的训练方法还是使用YOLOv1的方式,用SSD的方式训练YOLOv2能否有所提升,有待考察),但是YOLOv2的召回率大大提升了, 81%→88% 81 % → 88 % ;因为YOLOv2的采样数目变上千个(13*13*num_anchors),而YOLOv1的采样数目才(7*7*2=98)个;
2.1.4 采用k-means计算anchor尺寸
不同于SSD和Faster RCNN中的先验框(人为设定,带有主观性),YOLOv2中采用k-means方法,对训练集中的GT大小进行聚类分析,主要的目的是使得设定的先验框与GT的iou更好,这样设定的先验框比较合适,模型更容易学习,能做出更好的预测;
2.1.5 新网络结构-Darknet-19
使用Darknet-19之后,YOLOv2的mAP值没有显著提升,但是计算量却可以减少约33%。
2.1.6 直接定位预测(Direct location prediction)
- YOLOv2借鉴了RPN中的anchor offsets的方式,但是Faster RCNN的RPN方式存在一个问题:就是这种计算没有约束性,预测边框很容易向任何方向偏移;如当 t_x=1 时边界框将向右偏移先验框的一个宽度大小,而当 t_x=-1 时边界框将向左偏移先验框的一个宽度大小,因此每个位置预测的边界框可以落在图片任何位置,这导致模型的不稳定性,在训练时需要很长时间来预测出正确的offsets。
- 因此,YOLOv2没有完全按照RPN的方式计算要预测的目标偏移;而是使用YOLOv1的方式,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1),防止偏移过多。节给出了YOLOv2位置偏移目标计算的示意图。聚类和这种约束偏移方式,使得YOLOv2mAP提升约5%.
- YOLOv2用了anchor,采用下图所示进行tw,th的计算,其中Pw,Ph表示anchor的宽长,归一化到(0,1)之间;
其中x,y是GT中心点相对于其所在cell的左上角坐标的相对位置,如下图所示红圈部分:
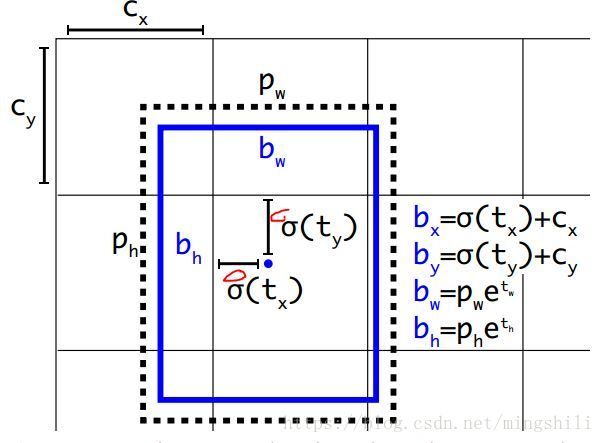
2.1.7 细粒度特征
由于网络前面的特征图分辨率高(更精细),因而对于预测小物体有一定的好处。所以,YOLOv2采用了类似SSD的思想,利用passthrough层,将更大分辨率的特征图用于最终预测;YOLOv2所利用的Fine-Grained Features是 26×26 26 × 26 大小的特征图(最后一个maxpooling层的输入),对于Darknet-19模型来说就是大小为 26×26×512 26 × 26 × 512 的特征图。不过不同于SSD和ResNet的shortcut, passthrough层抽取前面层的每 2×2 2 × 2 的局部区域,然后将其转化为channel维度,对于 26×26×512 26 × 26 × 512 的特征图,经passthrough层处理之后就变成了 13×13×2048 13 × 13 × 2048 的新特征图(特征图大小降低4倍,而channles增加4倍,图6为一个实例),这样就可以与后面的 13×13×1024 13 × 13 × 1024 特征图连接在一起形成 13×13×3072 13 × 13 × 3072 大小的特征图,然后在此特征图基础上卷积做预测。下图为这种操作的示意图:
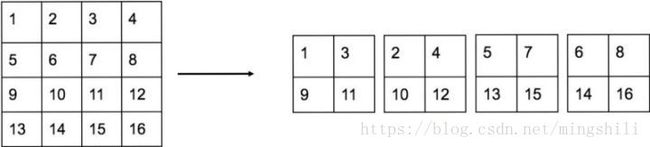
注:该图来自于https://zhuanlan.zhihu.com/p/35325884
使用Fine-Grained Features之后YOLOv2的性能有1%的提升。不过作者后期在passthrough前添加了一个64*1*1卷积层,将特征图厚度减小(减小后面的计算量),然后再使用passthrough trick;
2.1.8 多尺度输入的训练方式
由于YOLOv2网络结构只有卷积和池化,因此,YOLOv2的输入可以不限于416*416;因此为了增加模型鲁棒性,YOLOv2采用了多尺度输入训练策略,具体来说就是在训练过程中每间隔一定的iterations之后改变模型的输入图片大小。由于YOLOv2的下采样总步长为32,输入图片大小选择一系列为32倍数的值: {320,352,...,608} { 320 , 352 , . . . , 608 } ,输入图片最小为 320×320 320 × 320 ,此时对应的特征图大小为 10×10 10 × 10 (不是奇数了,确实有点尴尬),而输入图片最大为 608×608 608 × 608 ,对应的特征图大小为 19×19 19 × 19 。在训练过程,每隔10个iterations随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练。 注意,这只是测试时输入图片大小不同,而实际上用的是同一个模型(采用Multi-Scale Training训练)。
2.2 损失函数
置信度预测损失计算:
λnoobj∑h∗wi=0∑num_ancj=01max_iou<thred(0iou−piouij)2 λ n o o b j ∑ i = 0 h ∗ w ∑ j = 0 n u m _ a n c 1 m a x _ i o u < t h r e d ( 0 i o u − p i j i o u ) 2 预测框与背景框(与GT的iou<0.6的框)预测置信度误差计算
+λobj∑h∗wi=0∑num_ancj=0(IOUjtruth−piouij)2 + λ o b j ∑ i = 0 h ∗ w ∑ j = 0 n u m _ a n c ( I O U t r u t h j − p i j i o u ) 2 预测框与GT框的置信度误差计算
类别预测损失计算:
+λclass∑h∗wi=0∑num_ancj=0∑Cc=1(truthc−pcij)2 + λ c l a s s ∑ i = 0 h ∗ w ∑ j = 0 n u m _ a n c ∑ c = 1 C ( t r u t h c − p i j c ) 2
坐标预测损失计算:
+λcoord∑h∗wi=0∑num_ancj=01truthj∑r∈(x,y,w,h)(truthr−prij)2 + λ c o o r d ∑ i = 0 h ∗ w ∑ j = 0 n u m _ a n c 1 j t r u t h ∑ r ∈ ( x , y , w , h ) ( t r u t h r − p i j r ) 2 与GT框的误差计算
+λprior∑r∈(x,y,w,h)(priorrj−prij) + λ p r i o r ∑ r ∈ ( x , y , w , h ) ( p r i o r j r − p i j r ) 与先验框的误差计算
详细解释:
- 第一项loss是计算置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差;然后再计算正例的置信度损失,也就是与GT匹配的预测框各个损失。
- 第二项类别损失预测,对所有采样进行类别预测。
- 第三项坐标预测,首先是预测框与GT框的误差计算,其次是只前期计算预测框与先验框的误差计算。也就是说在训练前期使预测框快速学习到先验框的形状。
三、YOLOv3
两大变化点:
3.1 使用残差网络结构
YOLOv3的特征提取器是一个残差模型,因为包含53个卷积层,所以称为Darknet-53,从网络结构上看,相比Darknet-19网络使用了残差单元,所以可以构建得更深。
3.2使用FPN网络结构
采用FPN架构(Feature Pyramid Networks for Object Detection)来实现多尺度检测。YOLOv3采用了3个尺度的特征图(当输入为 416×416 416 × 416 时): ( 13×13 13 × 13 ) , ( 26×26 26 × 26 ) , ( 52×52 52 × 52 ) 。
3.3 其他尝试
1) 有效尝试:
- 用sigmoid代替softmax,也就是对20个类别分别用sigmoid,而不是对20个类别输出用softmax进行概率转化。因为有些boundingbox包括多标签(不能很好的适用其它数据集);使用独立的logistic分类器与二值交叉熵损失;
- 仅预测与GT最匹配的几个anchor,也就是,就算是大于某个阈值,如果不是与GT最好的overlap,也是不用于损失计算的
2)无效尝试
- 用线性函数激活代替逻辑函数激活,预测坐标x,y,导致mAP下降
- Focal Loss技术,也导致2个点的下降;这可能因为YOLO不存在Focal loss要解决的问题——大量损失来自于类别不平衡的问题。
四、总结
从YOLO的不断改进中可以得出,做目标检测时,使用anchor技术,采用全卷积进行预测,使用残差链接以及利用多尺度特征图作预测能贡献很好的性能提升;
而对于one-stage方法,它们想要一步到位,直接采用“RPN”网络作出精确的预测,因此,要在网络设计上做很多的tricks。YOLOv2的一大创新是采用Multi-Scale Training策略,这样同一个模型其实就可以适应多种大小的图片了。
1)存在的问题
- YOLO 精度还有待提升,可能是稀疏采样的问题,所以应该添加更多的trick来弥补稀疏采样的不足
- YOLO不能更加精确地定位问题,即不能很好地预测高iou的框
2)受到的启示
- YOLO的速度在于它的稀疏采样(如YOLOv1才7*7*2=98个区域采样),但是这样导致性能不如密集采样的一些网络要好,所以可以想方法提高区域采样准确性
- YOLO的定位可能取决于前面卷积网络的特征提取,所以应该构建一种针对这种稀疏采样的卷积神经网络结构。
注: 该文章主要参考他人博客,以及有一些自己的理解,如有错误,欢迎指正,谢谢!
参考文献
1 : https://zhuanlan.zhihu.com/p/32525231