K-SVD可以看做K-means的一种泛化形式,K-means算法总每个信号量只能用一个原子来近似表示,而K-SVD中每个信号是用多个原子的线性组合来表示的。
K-SVD算法总体来说可以分成两步,首先给定一个初始字典,对信号进行稀疏表示,得到系数矩阵。第二步根据得到的系数矩阵和观测向量来不断更新字典。
设D∈R n×K,包含了K个信号原子列向量的原型{dj}j=1K,y∈R n的信号可以表示成为这些原子的稀疏线性结合。也就是说y=Dx,其中x∈RK表示信号y的稀疏系数。论文中采用的是2范数来计算误差。当n

其中(P0)指的是零范数,也就是非零元素的个数。
如上所述,首先要进行稀疏表示,也就是论文中第‖部分所说的准备工作——稀疏编码。根据给定的信号y和初始字典D来求解稀疏表示系数。该问题可通过求解公式(1)或(2),通过追踪算法来找到最接近的解。L0范数问题是一个NP难的问题,文章大概介绍了集中方法进行求解,例如以MP和OMP为代表的贪婪算法,以BP为代表的凸优化方法等等,这里就不再详细介绍。
第Ⅲ部分讲解的是初始字典的选择。给定集合  存在字典D,对于每一个yk,通过求解公式(1)中的问题,我们能得到它的稀疏表示xk。
存在字典D,对于每一个yk,通过求解公式(1)中的问题,我们能得到它的稀疏表示xk。
A K-means泛化
稀疏表示和聚类(向量量化)有相似之处。在聚类方法中,我们要找到一组描述性向量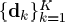 ,每一个样本能被唯一一个描述性向量表示。(和该样本距离最近的原子,距离的计算通常是欧式距离)。K-means的流程大致可分为两步:i)给定,找到与训练信号距离最近的原子,将信号分成该原子所在的聚类;ii)根据i中的结果,更新dk以更好的近似训练信号。我们可以把这种情况认为是在稀疏表示只能用一个原子来近似原信号的特殊情况,在这种情况下,对应的近似原子的稀疏系数也只有一个。而在稀疏表示中,每个信号是用dk中的某几个原子的线性组合来表示的,所以我们可以认为稀疏表示问题是聚类算法K-means的一种广义泛化。
,每一个样本能被唯一一个描述性向量表示。(和该样本距离最近的原子,距离的计算通常是欧式距离)。K-means的流程大致可分为两步:i)给定,找到与训练信号距离最近的原子,将信号分成该原子所在的聚类;ii)根据i中的结果,更新dk以更好的近似训练信号。我们可以把这种情况认为是在稀疏表示只能用一个原子来近似原信号的特殊情况,在这种情况下,对应的近似原子的稀疏系数也只有一个。而在稀疏表示中,每个信号是用dk中的某几个原子的线性组合来表示的,所以我们可以认为稀疏表示问题是聚类算法K-means的一种广义泛化。
根据K-means的步骤,我们可以近似写出稀疏表示的步骤:首先是稀疏编码,也就是根据给定的初始字典得到信号的稀疏系数,接着根据得到的稀疏系数矩阵去更新字典。

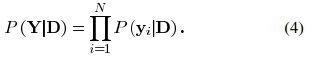
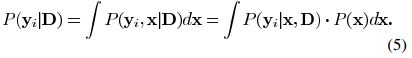
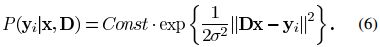





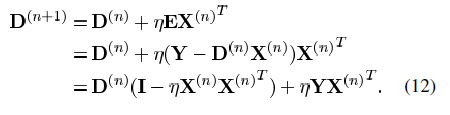
B 最大似然法
最大似然法应用概率推理来构造字典矩阵D。模型如公式(3)所示:
其中x为信号的稀疏表示,v为方差为σ2的残差向量。给定信号,考虑似然函数P(Y|D),找到合适的使得似然函数最大的字典矩阵D。首先我们假设yi之间是互相独立的,则我们可将似然函数写成:
第二个假设针对隐藏变量x,我们通过公式(5)来计算信号中的某一元素的似然函数:
结合公式(3)我们有:
假定表示向量X的元素是零均值的独立同分布,通常是柯西或者拉普拉斯分布。在论文中我们假定是拉普拉斯分布,则有:
x上的积分难以计算,所以我们用P(yi,x|D)处的极值来进行代换,则问题变成:
公式(8)中,字典D无惩罚项,而x i前乘上了一个惩罚因子,所以求解过程为了使稀疏系数的均值趋向于0,需要增加字典的元素个数,即字典矩阵的列数。我们可以通过约束信号中的每一个元素的二范数来解决上述问题。基于此,输出的稀疏的方差能保持在一个合适的稳定水平。
对于公式(8)的求解可采用一种迭代的方法,主要包含了两大步骤:
C MOD(method of optimal directions)方法
该方法和K-means的方法非常相似,首先使用OMP或者FOCUSS方法来进行稀疏编码,接着进行字典更新。MOD的最大优点是它更新字典的速度快,方法简便。假定每个信号的稀疏系数是已知的,定义误差ei=yi-Dxi,则均方误差表示为:
Y和X表示矩阵,它们的列分别用yi和xi来表示。‖A‖F表示Frobenius范数,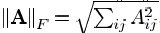
假定X是已知的,也就是我们已经求出了稀疏系数,接着对字典矩阵进行更新,当误差达到最小时,字典达到最优。对公式(10)中的D进行求导,得到(Y-DX)XT=0,进而我们有公式(11):
Y和X表在更新字典的时候,公式(11)在已知X稀疏的情况下能达到最好的效果,但是计算时间长。如果用最陡下降法来代替OMP和FOCUSS来估计Xi,会达到更好的效果。例如在公式(9)中我们用二阶(牛顿)来替换一阶,可将公式(9)重写为:
经过多次迭代,令系数足够小,则我们能得到公式(11)中所更新的矩阵一样的结果。但是该方法在迭代过程中的结果只是当前最佳解的近似解,而MOD方法在每次迭代中都能达到最优的结果。上述两种方法都需要字典矩阵的列进行标准化。
D 最大后验概率方法
类似于最大似然函数方法,我们将似然函数用后验概率P(D|Y)取代。根据贝叶斯法则有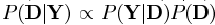 ,则我们可以继续使用似然函数的形式,并将先验概率作为一个新的项加入到式子中。
,则我们可以继续使用似然函数的形式,并将先验概率作为一个新的项加入到式子中。

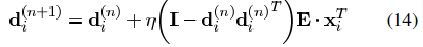

在已有的研究工作中考虑了多种先验概率P(D)的情况并且提出了相应的求解公式。这些方法用迭代梯度下降法来取代直接对n*n矩阵的求逆运算。先验概率P(D)具有单位Frobenius范数,更新公式如下所示:
公式(13)中的前两项与公式(9)中的相同。最后一项对约束的偏差进行补偿。D中的不同列允许有不同的范数值。在补偿项的作用下,范数值很小的列将会被舍弃,因为它们所需的系数要相当大,系数越大惩罚因子也越大。
据此,我们限制D中的列必须满足单位L2范数。则重写更新公式如下:
E 联合正交基
将字典表示成正交基的集合形式:D=[D1,D2,...DL],其中Dj∈IR n×n,j=1,2,...L是正交矩阵。这种矩阵的结构要求十分严格,但更新速度更快。
稀疏表示X矩阵可以分成L片,每一个都指向不同的正交基,则X=[X1,X2,...XL]T。其中Xi是包含了正交矩阵Di系数的矩阵。
联合正交基能简化稀疏编码阶段的追踪算法。这种方式将(P 1,ε)的求解简化为序列收缩,在计算某个Xi的时候X的其他系数是固定的。假设稀疏已知,则该算法将循序更新D的每一项Dj。第一个D j通过计算残差矩阵来获得:
接着通过计算矩阵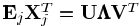 的奇异值分解,设已知系数为Xj,误差为Ej,计算最小二乘约束
的奇异值分解,设已知系数为Xj,误差为Ej,计算最小二乘约束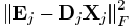 得到第j个正交基为Dj=UVT。Dj必须为正交的,用更新的基来重新表示数据矩阵Y,带入残差矩阵中,使得误差较少,通过这种方式分别独立更新D的每一项。
得到第j个正交基为Dj=UVT。Dj必须为正交的,用更新的基来重新表示数据矩阵Y,带入残差矩阵中,使得误差较少,通过这种方式分别独立更新D的每一项。
和之前的算法比较,此算法具有两个不同的地方,第一是字典矩阵的形式是确定的,第二是更新字典矩阵中的每项的次序。但是由于矩阵中的每一项和它们所对应系数的耦合问题,仿真结果比之前的算法差。
F 总结
总结字典训练算法所需要的性质
灵活性:算法可以灵活的和追踪算法共同合作。则根据得到的字典,可以选择在时间或是用途上合适的算法。MOD和MAP方法能够胜任这种情况,因为它们的稀疏编码和字典更新是分阶段进行的。
简单:算法不仅要足够简便,即它们与K-means方法的相似程度。算法应像K-means方法一样易于理解和可实现性高。例如MOD方法,但是MOD方法仍具有很大的提升空间。
高效:算法应具有较低的复杂度和较快的收敛速度。上述算法的运行时间都比较长,MOD方法的二阶更新适合字典矩阵大的情况下,因为它包含了矩阵求逆的工作。字典的更新先于系数的重新计算,这种顺序对于训练速度来说有很大的局限。
目标明确:好的算法应该具有明确的目标函数来评估解决方案的质量。如果忽略了这一事实,即使算法能够达到比较小的均方误差和稀疏性,但是可能会导致在全局中振荡的出现。
Ⅳ K-SVD算法
K-SVD算法是K-means的一种推广,具有灵活性可以联合不同的追踪算法。当一个信号用一个原子来表示时,使用gain-shape VD(矢量量化)来进行字典训练,当原子的系数要求为标准形式时,此时的K-SVD相当于K-means。由于稀疏编码的高效性以及Gauss-Seidel-like加速了字典的更新,K-SVD算法效率高。该算法的步骤之间是相关的。
A K-means泛化
包含K个代码字(特征)的代码本通过最近邻域分配可以用来表示多个向量(信号)(N≥K)。根据信号周围最近的代码字的选择,我们可以轻松的将Rn中的信号进行压缩或者描述为多个聚类。基于预期的最大化进程,K-means方法可以将协方差矩阵模糊分配给每个聚类,则信号可以抽象为混合高斯模型。
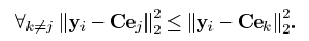
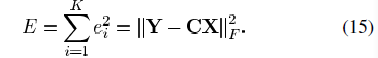


我们将代码本矩阵表示为C=[C1,C2,...CK],每列代表一个代码字。当C给定时,通过计算欧式距离,每个信号都将划分为离它最近的代码字所在的类。将yi记为yi=Cxi。其中xi=ei,选择第j个索引时,只有第j项非零,其他项都为0,第j个索引的选择表示如下:
是在极端情况下的选择表示,即yi仅有一个原子表示,并且原子所对应的系数为1。yi的均方误差定义为 ,则总的MSE为:
,则总的MSE为:
VQ训练所要解决的问题是找到一个使得误差E最小的代码本,并且该问题受限于X的结构,即X的列是从一些很小的基中选择的,据此我们将问题表示为如下:
K-means方法是设计VQ的最佳的代码本。在每次迭代中包含了两个步骤,第一是对X的稀疏表示,第二是对代码本的更新,具体步骤如下图所示:
在稀疏编码阶段,我们假定代码本C(J-1)已知,令X可变,使得公式(16)最小。在字典更新阶段,我们令第一阶段中使(16)最小的X固定,更新C使式(16)最小。据此,在每次迭代中,MSE要么减少要么不变。算法保证了MSE单调递减,最终收敛到局部最小。注意我们在这里并没有讨论迭代的终止条件,这是因为迭代条件可根据需求进行选择,并且易于实现和操作。



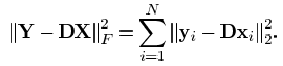
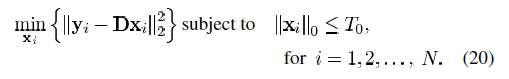
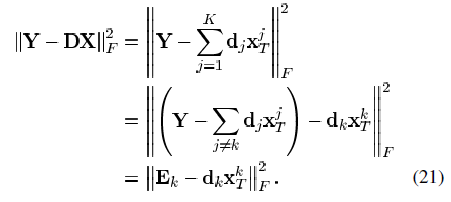

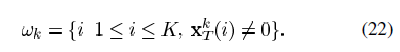
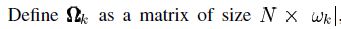 除了(ωk(i),i)th 的项其他都是0。则
除了(ωk(i),i)th 的项其他都是0。则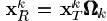 去除了零元素,是对行向量XTK的收缩后的结果。行向量XRK的长度为ωk。同理
去除了零元素,是对行向量XTK的收缩后的结果。行向量XRK的长度为ωk。同理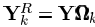 为n×ωk的矩阵,包含了使用了dk原子的信号的集合。同样我们有
为n×ωk的矩阵,包含了使用了dk原子的信号的集合。同样我们有 为除去没有用到dk原子的信号,并且不包含dk原子的误差。
现在我们返回到式(21),我们的目标是找到dk和
为除去没有用到dk原子的信号,并且不包含dk原子的误差。
现在我们返回到式(21),我们的目标是找到dk和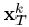 使得式(21)中的目标函数最小,我们令
使得式(21)中的目标函数最小,我们令 与原信号有同样的支撑集,则最小化可以等价为
与原信号有同样的支撑集,则最小化可以等价为




B K-SVD
稀疏表示可以认为是式(16)中向量量化目标函数的泛化形式,每个信号不再只由一个原子进行表示,在稀疏表示中我们允许每个输入信号能表示成为几个代码字的线性组合。在稀疏表示中我们将代码字成为字典元素。对应的,系数向量也不止一个,并且不要求一定为1,可以有不同的值。对应式(16),稀疏表示的目标函数是找到最佳的字典矩阵以稀疏表示信号Y,目标函数如式(17)中所示:
或者可以写成式(18)
其中T0是稀疏表示的稀疏中非零元素的数量的上限值,也就是系数向量中的最大差异度。
式(17)(18)是类似的,本文主要讨论第一种情况。
在本文算法中,通过迭代的方式使得式(17)最小。首先固定字典矩阵D,找到最佳的系数矩阵X,也就是使得(17)最小的X。但是找到最佳的X几乎是不可能的,所以我们采用近似追踪方法来寻找最接近的X。只要能够根据固定和预先定义的非零项To进行求解的算法即可采纳。
当第一阶段稀疏表示完成后,第二阶段即要完成字典矩阵的更新。在字典的更新中,每次迭代过程中只更新矩阵的一列。基本思想是固定其他所有列的值不变,除了当前要更新的列dk,找到一个新列dk~使得它的系数式MSE最小。第三部分中所描述的方法保持X不变以此来更新D。而本文的方法不同,依序按列来更新矩阵,并且相关系数是可变的。从某种意义上来说,这种方法独立更新每一列,如同K-means方法每次更新一个信号,是K-means的直接泛化。在K-means方法中,在ck的更新过程中X的非零项是固定的,因为K-means方法(gain-shape VQ)列更新是相互独立的。
D的列更新可以用奇异值分解方法。此外,由于后续的列更新基于更多的相关稀疏,SVD允许在字典更新时更改系数的值来加快收敛速度。该算法的整体效果与Gauss-Seidel的梯度下降非常近似。
有些算法尝试略过稀疏编码的阶段,直接更新字典D的列,系数是固定的,采用循环的方式来不断对字典进行更新。但是这种算法的效果并不好,因为稀疏表示的支撑集是不变的,并且该算法容易陷入局部最小。
C K-SVD 细节描述
这一节将详细描述K-SVD算法。目标函数为:
先讨论稀疏编码阶段,在这一阶段中,我们假定D是固定的,考虑式(19)的优化问题是找到寻找矩阵X中的系数所构成的系数表示的最优搜索。惩罚项可以重写为
则式(19)中的问题可以分解成N个不同的问题:
该问题可以采用追踪算法轻松求解。当T0足够小,求出的解将非常接近理想值,但却很难计算。
接着讨论第二个阶段,根据第一阶段求出的非零系数来更新字典。假定X和D都是固定的,当前只对一列进行更新,设为dk,相应的系数为XTK(即为矩阵X的第k行,不同于X的第k列xk),则我们将式(19)中的惩罚项重写为
将DX的乘积表示成为K个秩为1的矩阵的总和。其中K-1个项是固定的,只有当前待更新的项k是可变的,Ek表示除去第k个信号之外,其他所有信号的残差。
SVD的任务即为找到dk和XTK,SVD在Frobenius范数下找到与Ek最接近的秩1矩阵。该矩阵能有效的减少式(21)中的误差。但是,这一步很有可能会出错,因为在更新dk的时候,我们没有对稀疏进行约束,则我们得到的XT
会是满向量,即大多素元素都为非零的向量。因此我们定义为使用dk的信号元素{yi}的索引,也就是非零项所在的位置。
式(23)可以直接使用SVD方法进行求解,SVD方法将矩阵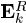 分解为
分解为 ,我们定义
,我们定义 为矩阵U的第一列,
为矩阵U的第一列, 为矩阵V的第一列乘上Δ(1,1)。注意式(23)的求解需要:i)D中的列标准化;ii)得到的稀疏表示要么保持不变要么值减少。
为矩阵V的第一列乘上Δ(1,1)。注意式(23)的求解需要:i)D中的列标准化;ii)得到的稀疏表示要么保持不变要么值减少。
类似于K-means的形式,我们将该算法称为K-SVD,算法流程如下图所示。
考虑K-SVD算法是否收敛。首先讨论稀疏编码阶段:找到最佳描述信号yi的不超过T0个的几个原子的线性组合。在这一阶段,假定字典矩阵是固定的,每一个编码步骤都会使式(19)中的误差‖Y-DX‖F2减少。另外,在更新阶段中,对于dk的更新,我们能保证MSE要么不变要么减少,这一更新并不违反稀疏约束。上述步骤保证了MSE的单调递减,因此算法能够收敛。但是这些都基于式(20)中追踪算法求出了鲁棒的结果而言,所以收敛性并不一定每次都能保证。当T0足够小,OMP、BP和FOCUSS算法都能得到比较好的结果,此时收敛是保证的。如果需要,可以进行人为的保证收敛,找到一个已有的保证收敛的追踪算法,在此基础上选择效果优于该算法的进行求解,这样我们可以提高算法的性能并且保证收敛性,事实上,从仿真结果来看,我们的算法都保证了收敛性,因此不需要人为的外部干预。
D 从K-SVD回到K-means
当T0=1时,回到了gain-shape VQ的情况,K-SVD变成了代码本训练的问题。当T0=1时,矩阵X每列只有一个非零项,则式(23)中的计算变为:
这是因为Ωk只用了Ek中用到dk的那些列,也就是说,没有用到别的原子,也就是对所有j来说,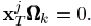 则SVD是直接对ωk中的信号进行操作的,D中的K列的更新之间也是相互独立的,类似于一个顺序更新过程或者说是平行过程,如同K-means更新聚类的中心一样。除了限制T0=1,我们还可以进一步限制X的非零项为1,此时问题完全变成了之前所说的经典的聚类问题。在这种情况下,都是1,也就是=1T。K-SVD方法需要用秩为1的矩阵dk·1T来近似误差矩阵
则SVD是直接对ωk中的信号进行操作的,D中的K列的更新之间也是相互独立的,类似于一个顺序更新过程或者说是平行过程,如同K-means更新聚类的中心一样。除了限制T0=1,我们还可以进一步限制X的非零项为1,此时问题完全变成了之前所说的经典的聚类问题。在这种情况下,都是1,也就是=1T。K-SVD方法需要用秩为1的矩阵dk·1T来近似误差矩阵 。求出的结果是
。求出的结果是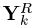 的平均值。如同K-means方法所做的那样。K-SVD算法容易陷入局部最小解,本文实验证明在下述变量满足的情况下,可避免此种情况的发生。
的平均值。如同K-means方法所做的那样。K-SVD算法容易陷入局部最小解,本文实验证明在下述变量满足的情况下,可避免此种情况的发生。


当系数的数量是固定的时候,我们发现FOCUSS能在每次迭代过程中提供最好的近似结果,但是从运行时间来看,OMP的运行时间最短。
当字典元素没有被充分利用的时候(与字典元素和信号的个数有关),可以使用最少原子表示的信号元素正规化后来代替(即当稀疏表示没有用到字典中的元素的时候将会被代替)。因为信号元素的数量远远超过字典元素的数量,而且我们使用的模型假设字典中的原则都是等概率被利用的,所以这样的代替方式能够有效的避免结果成为局部最小解并且防止过度拟合。
类似于移除字典中没有被利用的原子的司令,我们发现除去字典中过于接近的原子也能起到效果。如果找到这样的一对原子(当它们的内积的绝对值超过某个门限值的时候)其中一个元素将会被由最少的原子线性组合形成的信号所代替。
Ⅴ 仿真
A 数据生成
随机矩阵D(或者说是生成字典)大小为20*50,每一列互相独立,都为均匀分布,并且都满足标准的单位2范数。则产生维度为20的1500个信号 ,每一个都有字典中的三个不同的原子组成,互相独立,满足均匀分布。系数随机并且处在独立的位置,不同SNR的白高斯噪声将叠加在结果数据信号中。
,每一个都有字典中的三个不同的原子组成,互相独立,满足均匀分布。系数随机并且处在独立的位置,不同SNR的白高斯噪声将叠加在结果数据信号中。
B 应用SVD
字典根据数据信号进行初始化,系数采用OMP方法进行求解,迭代的最大次数设置为80
C 比较
使用MOD方法和OMP方法进行比较,MOD执行80次迭代,FOCUSS方法作为分解方法。
D 结果
训练字典和已知的字典进行比较。找到训练字典中与生成字典中最接近某列的那一项,计算距离
当式(25)的值小于0.01时即为成功,其中di为我们预先生成的字典中的第i列,而di~为训练字典中最接近该列的列。实验重复50次,计算每次实验中的成功概率。图3中显示了噪声水平为10,20,30dB的情况下的训练情况。
对于大小不同的字典来说(例如20*30),迭代次数越多,MAP方法的效率越接近K-SVD。
参考文献:M. Aharon, M. Elad, A.M. Bruckstein.K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation[J].IEEE Transactions on,2006,54(11):4311-4322
另可参考博客:
http://blog.csdn.net/wwf_lightning/article/details/72994303
http://blog.csdn.net/cc198877/article/details/9167989