pytorch 模型训练(以CIFAR10数据集为例)
在pytorch模型训练时,基本的训练步骤可以大致地归纳为:
准备数据集--->搭建神经网络--->创建网络模型--->创建损失函数--->设置优化器--->训练步骤开始--->测试步骤开始
本文以pytorch官网中torchvision中的CIFAR10数据集为例进行讲解。
需要用到的库为(这里说一个小技巧,比如可以在没有import对应库的情况下先输入"torch",,之后将光标移到torch处单击,这时左边就会出现一个红色的小灯泡,点开它就可以import对应的库了):
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter准备数据集
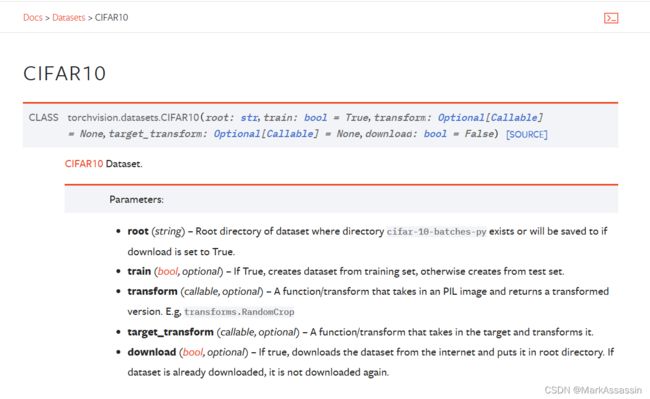
数据集分为“训练数据集”+“测试数据集”。CIFAR数据集是由50000训练集和10000测试集组成。这里可以调用torchvision.datasets对CIFAR10数据集进行获取:
#训练数据集
train_data=torchvision.datasets.CIFAR10(root='./dataset',train=True,transform=torchvision.transforms.ToTensor(),download=True)
#测试数据集
test_data=torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=torchvision.transforms.ToTensor(),download=True)
#利用dataloader来加载数据集
train_data_loader=DataLoader(train_data,batch_size=64)
test_data_loader=DataLoader(test_data,batch_size=64)root是数据集保存的路径,这里笔者使用的是相对路径;对于训练集train=True,而测试集train=False;transform是将数据集的类型转换为tensor类型;download一般设置为True。之后利用DataLoader对数据集进行加载即可,其中batch_size表示单次传递给程序用以训练的数据(样本)个数。
(这里可以再获取下测试集数据的长度,这样后面在测试步骤时就可以通过计算得到整体测试集上的准确率)
搭建神经网络
pytorch官网提供了一个神经网络的简单实例:
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))这个实例展示了神经网络的基本架构。
从百度上我们可以搜索到CIFAR10数据集的网络基本架构:
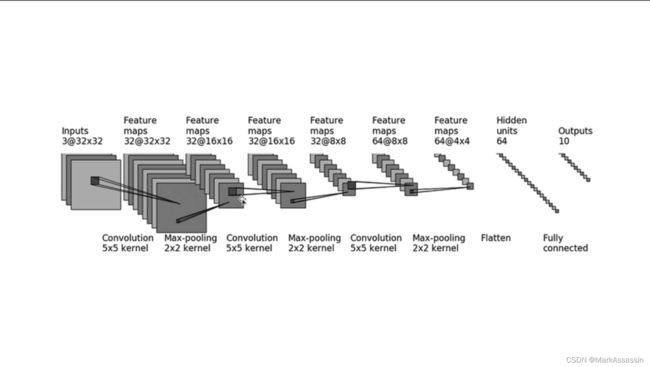
从原理图中可以看到,该网络从输入(inputs)到输出(outputs)先后经过了
卷积(Convolution)--->最大池化(Max-pooling)--->卷积--->最大池化--->卷积--->最大池化--->展平(Flatten)--->2次线性层
由此可以开始搭建神经网络,笔者将网络命名为MXC:
class Flatten(nn.Module):
def forward(self, input):
return input.view(input.size(0), -1)#搭建神经网络
class MXC(nn.Module):
def __init__(self):
super(MXC, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x注:这里Flatten类自己写的原因是笔者使用的torch版本中没有展平类,因此需要自己构建,可以参考解决 ImportError: cannot import name ‘Flatten‘ from ‘torch.nn‘_全幼儿园最聪明的博客-CSDN博客
创建网络模型
mxc=MXC()创建损失函数
loss_fn=nn.CrossEntropyLoss()设置优化器
learning_rate=1e-2
optimizer=torch.optim.SGD(params=mxc.parameters(),lr=learning_rate)这里params是网络模型;lr是学习速率,一般设置小一些(0.01)。
训练步骤+测试步骤开始
先设置一些参数
#设置训练网络的一些参数
#记录训练的次数
total_train_step=0
#记录测试的次数
total_test_step=0
#记录测试的准确率
total_accuracy=0
#训练的轮数
epoch=10将训练步骤和测试步骤放入一个大循环中,进入循环开始训练:
for i in range(epoch):
print("-----第{}轮训练开始------".format(i+1))
#训练步骤开始
for data in train_data_loader:
imgs,targets=data
output=mxc(imgs)
loss=loss_fn(output,targets)
#优化器优化模型
optimizer.zero_grad()#梯度清零
loss.backward()#反向传播
optimizer.step()#参数优化
total_train_step=total_train_step+1
if total_train_step%100==0:
print("训练次数:{} , Loss:{}".format(total_train_step, loss)) # 更正规的可以写成loss.item()
#测试步骤开始
total_test_loss=0
with torch.no_grad():
for data in test_data_loader:
imgs,targets=data
output=mxc(imgs)
loss=loss_fn(output,targets)
total_test_loss=total_test_loss+loss
accuracy=(output.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的准确率:{}".format(total_accuracy/test_data_size))
total_test_step=total_test_step+1#测试的次数,其实就是第几轮
#保存模型
torch.save(mxc,"mxc_cpu{}.pth".format(i+1))#mxc_1是cpu版的
print("模型已保存")这里每一个data中包含有图片+标签,需要将图片(imgs)放入之前搭建好的神经网络模型mxc中去。笔者这里设置的是每训练100次打印1次,训练完一轮后会将模型进行保存,注意文件类型是pth格式。
如果想让训练后的结果可视化,有两种方法:
1.在循环前调用SummaryWriter添加tensorboard:
#添加tensorboard
writer=SummaryWriter('./logs_train')并在循环的适当位置中插入writer.add_scalar:
if total_train_step%100==0:
print("训练次数:{} , Loss:{}".format(total_train_step, loss)) # 更正规的可以写成loss.item()
writer.add_scalar("train_loss",loss.item(),total_train_step)print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的准确率:{}".format(total_accuracy/test_data_size))
total_test_step=total_test_step+1#测试的次数,其实就是第几轮
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)在运行结束后,打开Terminal输入(注意,前面需要显示pytorch,因为只有在pytorch环境下才可以,如果没有显示还要切换到pytorch才行,可以输入activate pytorch):
tensorboard --logdir=logs_train --port=6007
这里的“logs_train”是在SummaryWriter中设置的保存路径。运行之后,就可以在tensorboard中查看随着训练次数的增加测试集上的Loss和准确率的趋势图像。
2.调用matlab库自己进行绘制
总结
本文简要介绍了pytorch模型训练的一个基本流程,并以CIFAR10数据集进行了演示。但这种方法是在CPU(device=“cpu”)上进行训练的,训练速度比较慢,如果数据集十分庞大不建议使用这种方法,应该在GPU(device=“cuda”)上进行训练。