使用LabelImg+python编程读取xml实现目标检测数据集、图像分类数据集的制作
前言
继上一篇博客自己设计了一个制作数据集的工具后,我发现该工具完全可以由labelimg(一款目标检测数据集制作软件)进行替代,等同于我上一个博客设计了一款低配版的labelimg~~,所以这里就教大家如何使用labelimg制作目标检测数据集,以及通过其xml文件来生成对应的图像分类数据集。
一、labelimg
1.1 labelimg下载
windows:
打开cmd终端输入以下命令(前提是装了python的情况下)
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
这是一款标注数据集的软件,常用于目标检测数据集制作。python可以直接通过命令行安装。
然后输入在终端输入:labelimg 即可打开该软件。

快捷键
- Ctrl + u 加载目录中的所有图像,鼠标点击Open dir同功能
- Ctrl + r 更改默认注释目标目录(xml文件保存的地址)
- Ctrl + s 保存
- Ctrl + d 复制当前标签和矩形框
- w 创建一个矩形框
- a 上一张图片
- d 下一张图片
- del 删除选定的矩形框
- Ctrl++ 放大 Ctrl-- 缩小
- ↑→↓← 键盘箭头移动选定的矩形框
经过该软件标注后生成的是xml文件。
二、图像截取分类存储
通过第一步我们可以制作出目标数据集,现在我们也可以根据生成的xml文件获取其中的信息来截取目标图片进行分类存储形成图像分类数据集。
1.XML文件内容的读取方法
对于xml文件的读取方式有很多种,这里用的xml.etree.ElementTree该库函数实现xml文件信息的读取。
读入数据
代码如下(示例):
tree = ET.parse(filename)#传入文件名获取到信息树tree
以下通过一个文件示例进行说明。
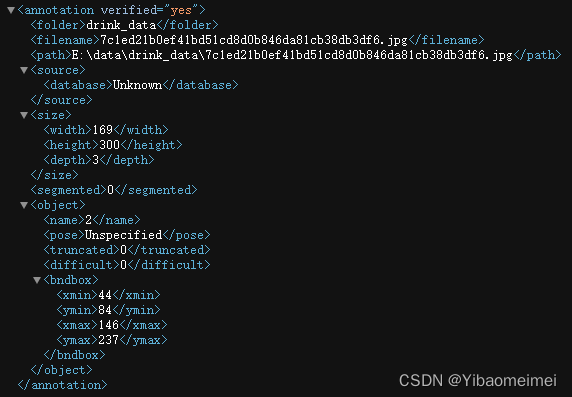
如上图所示,该文件内容就是经过labelimg标注的一张图片所产生的xml文件里面的内容。
层次结构大致如下:

正如tree 树一样,每个层级下的内容都可以通过findall一层一层的找到内容。
比如我们要获取图片路径path,则代码如下:
imgPath = tree.findall("path")[0].text
意思是找到当前子节点下所有的“path”,获取索引0(也就是第一个)所对应的文本内容。
获取多层节点下的内容
比如获取object下的xmin等坐标点信息,则需要多次进行查找。
tree.findall("object")[i].find("bndbox")[0].text
因为一个图像中标记了多个物品时会存在多个object,所以一般是循环访问遍历。该句的意思是获取索引为i的object的bndbox中的索引为0的文本内容,text则为获取文本内容的方法。
2 Opencv截取Roi区域
通过读取xml获取到标注物品的相关信息后,就可以进行roi区域的截取进行分类存储了。
opencv根据物品的坐标点截取对应区域的图像只需要使用切片即可实现。
img = cv2.imread(imgPath)
roiimg = img[ymin:ymax, xmin:ymax] #切片获取
cv2.imwrite("1.jpg", roiimg)#保存
这样便完成了图像roi区域的获取与保存。
3 代码
总的代码如下所示
import xml.etree.ElementTree as ET
import sys
import os
import cv2
import datetime as dt
class splitImg():
def __init__(self, savePath, xmlsPath):
self.xmin = []
self.ymax = []
self.ymin = []
self.xmax = []
self.imgPath = ""
self.name = []
self.savePath = savePath
self.xmlsPath = xmlsPath
def read_xml(self, filename):
self.name = []
self.ymin = []
self.xmin = []
self.ymax = []
self.xmax = []
#读取xml文件获取信息
tree = ET.parse(filename)
self.imgPath = tree.findall("path")[0].text
for i in range(len(tree.findall("object"))):
self.xmin.append(tree.findall("object")[i].find("bndbox")[0].text)
self.ymin.append(tree.findall("object")[i].find("bndbox")[1].text)
self.xmax.append(tree.findall("object")[i].find("bndbox")[2].text)
self.ymax.append(tree.findall("object")[i].find("bndbox")[3].text)
self.name.append(tree.findall("object")[i].find("name").text)
# print(len(tree.findall("object")))
# print(self.imgPath, "\n", self.box, "\n", self.name, "\n")
def selectROI(self):
#截取roi区域
img = cv2.imread(self.imgPath)
# print(self.ymin, "\n", self.ymax, "\n", self.xmin, self.xmax, "\n")
for i in range(len(self.name)):
roiImg = img[int(self.ymin[i]):int(self.ymax[i]), int(self.xmin[i]):int(self.xmax[i])]
#根据系统时间命名图像
now_time = dt.datetime.now().strftime("%Y%m%d%H%M%S%f")
saveName = os.path.join(self.savePath+"/"+self.name[i]+"/", str(now_time)[6:]+".jpg")
if not os.path.exists(self.savePath+"/"+self.name[i]+"/"):
os.mkdir(self.savePath+"/"+self.name[i]+"/")
cv2.imwrite(saveName, roiImg)
cv2.waitKey(1)
def run(self):
#运行函数
for file in os.listdir(self.xmlsPath):
if file.split(".")[1] == "xml":
path = os.path.join(self.xmlsPath, file)
self.read_xml(path)
self.selectROI()
if __name__ == '__main__':
xmlPath = "E:/data/drink_data/" #xml存储的根目录路径
savePath = "E:/data/test/" #需要保存截取图像的位置
aa = splitImg(savePath, xmlPath)
aa.run()
4 txt文件生成
为方便图像分类任务训练,这里再附上一个目录类容生成的代码,简单快捷。
import os
file_path = "E:/images" #图像存储路径的根目录
txtFile = "E:/images/train.txt" #保存的txt文件
if os.path.isdir(txtFile):
if not os.path.exists(txtFile):
os.mkdir(txtFile)
fp = open(txtFile, "w")
img_list = ["jpg", "png", "jpeg"]
for file in os.listdir(file_path):
if os.path.isdir(os.path.join(file_path, file)):
for name in os.listdir(os.path.join(file_path, file)):
if name.split(".")[1] in img_list:
fp.write(file+"/"+name+" "+file+"\n")
fp.close()
5 大致结果展示
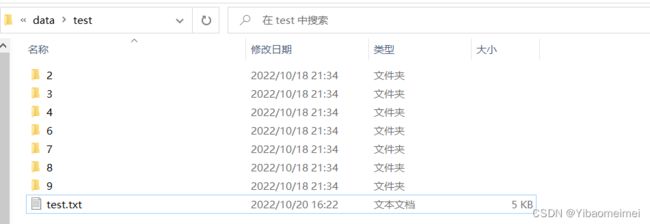
test.txt文件中的内容:

总结
到这里整个项目就结束了,即完成了目标检测数据集制作的同时,也生成了图像分类数据集,一举两得,这边博客基于上一篇博客的区别在于:使用了更便捷的工具labelimg(在做完上一个项目才发现,做的事好像就是labelimg做的事),不过也算是做的过程对qt进行了更进一步的了解与学习。
感谢大家观看。
