【文本检测】1、DBNet | 实时场景文本检测器

文章目录
-
- 一、背景
- 二、方法
-
- 2.1 二值化
- 2.2 Adaptive threshold
- 2.3 可变形卷积
- 2.4 生成标签
- 2.5 优化过程
- 三、效果
-
- 3.1 实验数据
- 3.2 实验细节
- 3.3 消融实验
- 3.4 和其他方法的对比
论文:Real-time Scene Text Detection with Differentiable Binarization
代码:https://github.com/MhLiao/DB
出处:AAAI 2020
本文贡献:
- 提出了二值化函数的近似形式 Differentiable Binarization,是完全可微的,保证了二值化过程能够和分割网络同时优化
- DB 可以简化其他方法中的繁重后处理过程,提高 infer 效率,并且能够得到更鲁棒的二值化特征图
- DB 可以和轻量化的 backbone 结合
- DB 在 infer 的时候可以移除,且不会降低模型效果,不会对 infer 带来额外的耗时
一、背景

文本检测是文本识别的基础,但文本检测也面临很多问题,比如其尺度和形状很多变,有水平、竖直、多方向、曲线形状等。
由于分割的方法能够提供 pixel-level 的结果,即能够更准确的识别出文本区域,包括曲线排列的文本,故基于分割方法的文本检测近来比较流行。
二值检测特征图的后处理对分割方法非常重要,这个过程能够将分割方法得到的概率特征图转换成文本区域的 bounding box 或 bounding region。但是,后处理的过程在推理的时候很耗时。
现有的方法一般使用如图 2 所示的后处理过程,如蓝色箭头:
- 首先,设定一个固定的阈值,将分割结果转化成二值图
- 然后,使用一下启发式的方法,如像素聚合,来将 pixels 聚合成 text 实例
本文中,作者提出了名为 Differentiable Binarization(DB)的差分二值化方法,可以在分割网络中实现二值化的过程,让 DB 模块和分割网络同时优化,能够自适应的调整二值化的阈值,能够简化后处理的阈值选取且提升效果。
本文方法的结构,如图 2 ,红色箭头:
- 本文的目标就是将二值过程嵌入分割网络来同时优化
- 图像中每个位置的阈值都可以被自适应的估计,于是就可以将前景和背景区分开来
- 但标准的二值化函数是不可微的,所以,作者又提出了一个 Differentiable Binarization 作为二值化的近似函数,是可微的。

二、方法
本文方法的主要结构如图 3 所示:
- 首先,将图像输入金字塔形式的 backbone
- 然后,将所有金字塔特征图上采样到相同的尺度,得到特征图 F,将 F 用于预测 probability map(P)和 threshold map(T)
- 之后,使用 P 和 T 来计算 binary map B ^ \hat{B} B^
- 在训练过程中,监督信号会监督 P、T、 B ^ \hat{B} B^,且 P 和 B ^ \hat{B} B^ 是共享监督信号的,
- 在推理过程中,可以通过 box formulation module 从 B ^ \hat{B} B^ 或 P 来得到 bounding box

2.1 二值化
1、标准二值化
给定从分割网络得到的 probability map P ∈ R H × W P \in R^{H \times W} P∈RH×W,将其二值化后,就会得到只包含 0 和 1 的二值化图,其中,0 表示背景,1 表示有效的文本区域,标准二值化过程如下:
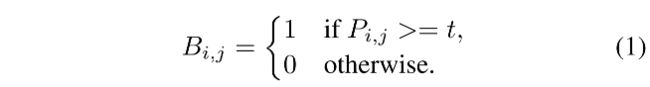
- t 是阈值
2、Differentiable binarization
如公式 1 所示的标准二值化是不可微的,所以不能和分割网络一起来训练,所以,本文作者提出了一个二值化的近似形式:
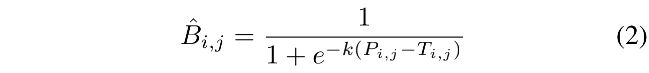
- B ^ \hat{B} B^ 是近似的二值图
- T 是从网络中学习到的 adaptive threshold map
- k 是一个增强因子,设定为 50
- 该近似的二值化函数和标准的二值函数类似,但可微,就可以随模型一起训练
DB 能够提升模型效果的原因可以用梯度的反向传播来解释,以二值化交叉熵 loss 为例。
定义 DB 函数为: f ( x ) = 1 1 + e − k x f(x) = \frac{1}{1+e^{-kx}} f(x)=1+e−kx1
- 其中, x = P i , j − T i , j x = P_{i,j}-T_{i,j} x=Pi,j−Ti,j
positive label 的 loss l + l_{+} l+ 和 negative label 的 loss l − l_{-} l− 如下:

loss 的梯度如下:

l + l_{+} l+ 和 l − l_{-} l− 的衍生物如图 4 所示,可以观察到:
- 使用增强因子 k 能够增强梯度
- 梯度的增强对
- 很多预测错误的区域(x<0 for L + L_+ L+,和 x>0 for L − L_- L−)很重要,所以能够促进网络优化,并有助于得到更具有区分力的预测结果
- 此外,由于 x = P i , j − T i , j x = P_{i,j}-T_{i,j} x=Pi,j−Ti,j,故 P 的梯度会随着 T 的前向和反向传播而被影响和缩放

2.2 Adaptive threshold
有监督和无监督的 threshold map 如图 6 中所示,尽管没有监督时,文本区域也会高亮,这说明 border-like threshold map 对最终结果是有益的,所示,作者使用了 border-like 的监督信号来获得更好的指导。

2.3 可变形卷积
可变形卷积被证明能够提供更灵活的感受野,对文本实例,尤其是一些边界实例会有更好的特征提取效果,所以,本文在 conv3、conv4、conv5 的所有 3x3 卷积层中都使用了可变形卷积。
2.4 生成标签
这里需要给 probability map 和 threshold map 都生成标签

1、probability map 标签生成:
1)给定 text image,每个多边形都被认为是一个待分割的集合:

- n 是顶点的个数,不同数据集中是不同的,如 ICDAR 2015 中是 4,CTW1500 是16
2)使用 Vatti clipping algorithm 方法进行多边形收缩,从 G G G 收缩为 G s G_s Gs,得到 positive area,偏移 D 是从原始的多边形区域的周长 L 和面积 A 计算得来的。

- r 是收缩比率,本文设置为 0.4
2、threshold map 标签生成
1)使用 D 和 G d G_d Gd 对 G 进行膨胀,作者认为 G s G_s Gs 和 G d G_d Gd 的 gap 是 text region 的 border,也就是边界区域
2)通过计算和 G 中的分割区域的最近距离,来生成 threshold map 的标签
2.5 优化过程
训练 loss:
![]()
- L s L_s Ls:probability map 的 loss
- L b L_b Lb:binary map 的 loss
- L t L_t Lt:threshold map 的 loss
- α = 1 \alpha = 1 α=1, γ = 10 \gamma=10 γ=10
1、 L s L_s Ls 和 L b L_b Lb 的 loss 都使用二值交叉熵,为了平衡正负样本,使用了难例挖掘
![]()
- S l S_l Sl 是正负样本 1:3 的样本集合
2、 L t L_t Lt 是计算了在膨胀文本多边形区域 G d G_d Gd 内的 prediction 和 label 的 L1 距离之和
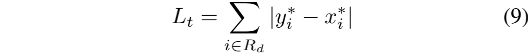
- R d R_d Rd:在膨胀多边形区域 G d G_d Gd 内的像素的索引
- y ∗ y* y∗:threshold map 的 label
推理过程:
推理的时候,可以使用 probability map 或 approximate binary map 来生成 text bounding boxes,两者生成的很接近。为了高效,作者使用 probability map 来生成,所以 threshold map 就可以舍弃了。
box 生成包含 3 步:
- probability map 首先使用 0.2 的阈值进行二值化
- 从二值图中得到连接的区域(收缩 text 区域的方式来实现)
- 使用 offset D ′ D' D′ 来进行收缩区域的膨胀, D ′ = A ′ × r ′ L ′ D' = \frac{A' \times r'}{L'} D′=L′A′×r′,其中, A ′ A' A′ 是收缩后多边形的面积, L ′ L' L′ 是收缩后多边形的周长, r ′ = 1.5 r'=1.5 r′=1.5
三、效果
对比的指标:P/R/F
- P:Precision
- R:Recall
- F:F1_Score
上述三个指标都可以通过混淆矩阵来得到,混淆矩阵如下:
| 预测:1 | 预测:0 | |
|---|---|---|
| 真实:1 | TP | FN |
| 真实:0 | FP | FN |
Precsion = T P T P + F P \text{Precsion} = \frac{TP}{TP+FP} Precsion=TP+FPTP
Recall = T P T P + F N \text{Recall} = \frac{TP}{TP+FN} Recall=TP+FNTP
F 1 = 2 P R P + R \text{F}_1 = \frac{2PR}{P+R} F1=P+R2PR
在精度或召回率较差的情况下,F1-score也会较差。只有当准确率和召回率都有很好的表现时,F1-score才会很高。
3.1 实验数据
- SynthText:包含 800k 图片,是从 8k 大图中抽取得到的,本文中用这个数据进行 pre-train
- MLT-2017 dataset:多语言数据集,包括 9 种语言,6 种字体,7200 张训练,1800 张验证,9000 张测试
- ICDAR 2015 dataset:包括 1000 张训练数据,500 张测试数据,从 google 得到,分辨率为 720x1280,标注到 word level
- MSRA-TD500 dataset:多语言数据集,包括英文和中文,300 张训练集,200 张测试集,标注到 text-line level
- CTW1500 dataset:主要关注曲线文本的一个数据集,包括 1000 训练集,500 测试集,标注到 text-line level
- Total-Text dataset:包括各种形状的 text,水平、多角度旋转、曲线形式等,1225 训练集,300 测试集,标注到 word level
3.2 实验细节
- 在 SynthText 上进行预训练,训练 100k iterations,然后再对应的数据集上 finetune 1200 epochs
- batch size 为 16
- 数据增强:① 在 (-10°,10°)内进行随机旋转;② 随机裁剪;③ 随机翻转
- 训练图像大小:所有图被 resize 到 640x640 大小
- 推理阶段,在保持原始纵横比的基础上,对每个数据集缩放到合适的大小,测试推理速度的时候保持 batch = 1,在 1080ti 上测试,infer 时间包括模型前向推理时间和后处理时间,后处理大概耗时占总推理时间的 30%。
3.3 消融实验
1、DB 的效果
如表 1 所示

2、可变形卷积的效果

3、对 threshold map 监督的效果

4、Backbone
resnet 50 比 resnet 18 高 2.1%(MSRA-TD500) 和 2.8%(CTW1500)
3.4 和其他方法的对比