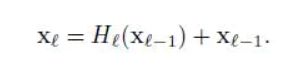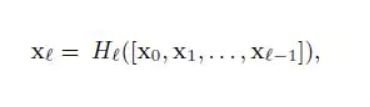- 深度学习图像分类数据集—桃子识别分类
AI街潜水的八角
深度学习图像数据集深度学习分类人工智能
该数据集为图像分类数据集,适用于ResNet、VGG等卷积神经网络,SENet、CBAM等注意力机制相关算法,VisionTransformer等Transformer相关算法。数据集信息介绍:桃子识别分类:['B1','M2','R0','S3']训练数据集总共有6637张图片,每个文件夹单独放一种数据各子文件夹图片统计:·B1:1601张图片·M2:1800张图片·R0:1601张图片·S3:
- CNN 猫狗识别:从理论到实战的深度解析
爱熬夜的小古
cnn深度学习人工智能
在计算机视觉领域,卷积神经网络(ConvolutionalNeuralNetwork,CNN)凭借其强大的特征提取和模式识别能力,成为图像分类任务的主流技术。猫狗识别作为经典的图像分类问题,不仅能帮助我们理解CNN的工作原理,还能为实际应用提供技术支持。本文将深入探讨CNN在猫狗识别中的应用,从理论基础到实战代码,带你全面掌握这项技术。一、CNN基础理论概述(一)CNN的核心组件卷积层:是CNN的
- 目前主流图像分类模型的详细对比分析
@comefly
闲聊linux运维服务器
以下是目前主流图像分类模型的详细对比分析,结合性能、架构特点及应用场景进行整理:一、主流模型架构分类与定量对比模型名称架构类型核心特点ImageNetTop-1准确率参数量(百万)计算效率典型应用场景ResNetCNN残差连接解决梯度消失,支持超深网络(如ResNet-152)76.1%25.6中等通用分类、目标检测ViTTransformer将图像分割为patches,用标准Transforme
- 【深度学习实战】当前三个最佳图像分类模型的代码详解
云博士的AI课堂
大模型技术开发与实践哈佛博后带你玩转机器学习深度学习深度学习人工智能分类模型机器学习TransformerEfficientNetConvNeXt
下面给出三个在当前图像分类任务中精度表现突出的模型示例,分别基于SwinTransformer、EfficientNet与ConvNeXt。每个模型均包含:训练代码(使用PyTorch)从预训练权重开始微调(也可注释掉预训练选项,从头训练)数据集目录结构:└──dataset_root├──buy#第一类图像└──nobuy#第二类图像随机拆分:80%训练,20%验证每个Epoch输出一次loss
- 中药细粒度图像分类
小lo想吃棒棒糖
分类数据挖掘人工智能
在细粒度图像分类(FGVC)领域,BilinearCNN(BCNN)模型因其能够捕捉图像中的局部特征交互而受到广泛关注。该模型通过双线性池化操作将两个不同CNN提取的特征进行外积运算,从而获得更加丰富的特征表示,这对于区分外观相似但属于不同子类别的物体尤其有效。然而,BCNN通常计算成本较高,限制了其在移动设备或资源受限环境下的应用。为了实现轻量化并保持高精度的细粒度分类,可以考虑将MobileN
- 时尚搭配助手,深度解析用Keras构建智能穿搭推荐系统
忆愿
高质量领域文章keras人工智能深度学习机器学习python
文章目录引言:当算法遇见时尚第一章数据工程:时尚系统的基石1.1数据获取的多元化途径1.2数据预处理全流程1.2.1图像标准化与增强1.2.2多模态数据处理第二章模型架构设计:从分类到推荐2.1基础CNN模型(图像分类)2.2多任务学习模型(属性联合预测)第三章推荐算法核心3.1协同过滤与内容推荐的融合第四章系统优化4.1注意力机制应用第五章实战演练5.2实时推荐API实现第六章前沿探索:时尚AI
- 支持向量机(SVM)在病理切片图像分类(癌细胞检测,Camelyon16/17、TCGA)中的应用与实现
猿享天开
支持向量机分类算法机器学习人工智能
支持向量机(SVM)在病理切片图像分类(癌细胞检测,Camelyon16/17、TCGA)中的应用与实现病理切片图像分类是医学影像分析的重要领域,特别是在癌细胞检测中,SVM因其对高维数据和小样本场景的优异性能,成为一种经典且有效的分类方法。本文将深入探讨SVM在Camelyon16/17和TCGA数据集上的应用,全面覆盖概念与原理、应用场景、及挑战与应对策略,欢迎感兴趣的阅读。[文中示例代码仅供
- 基于小样本的高光谱图像分类任务:CMFSL方法及Python实现
pk_xz123456
仿真模型算法深度学习分类python人工智能深度学习机器学习
基于小样本的高光谱图像分类任务:CMFSL方法及Python实现1.引言高光谱图像分类是遥感图像处理领域的重要研究方向,它在农业监测、环境评估、军事侦察等领域有着广泛的应用。与传统RGB图像不同,高光谱图像包含数百个连续的光谱波段,能够提供丰富的光谱信息。然而,高光谱图像分类面临着维度灾难、样本获取困难等挑战,特别是在小样本条件下,传统分类方法往往表现不佳。针对这一问题,本文介绍一种基于小样本的高
- 【机器学习笔记 Ⅱ】7 多类分类
巴伦是只猫
机器学习机器学习笔记分类
1.多类分类(Multi-classClassification)定义多类分类是指目标变量(标签)有超过两个类别的分类任务。例如:手写数字识别:10个类别(0~9)。图像分类:区分猫、狗、鸟等。新闻主题分类:政治、经济、体育等。特点互斥性:每个样本仅属于一个类别(区别于多标签分类)。输出要求:模型需输出每个类别的概率分布,且概率之和为1。实现方式One-vs-Rest(OvR):训练K个二分类器(
- 支持向量机(SVM)在肝脏CT/MRI图像分类(肝癌检测)中的应用及实现
猿享天开
医学影像支持向量机机器学习人工智能算法
博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++,C#,Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQLserver,Oracle,mysql,postgresql等进行开发应用,熟悉DICOM医学影像及DICOM协议,业余时间自学JavaScript,Vue,
- Python 图像分类入门
超龄超能程序猿
机器学习python分类开发语言
一、介绍图像分类作为深度学习的基础任务,旨在将输入图像划分到预定义的类别集合中。在实际的业务中,图像分类技术是比较常用的一种技术技能。例如,在安防监控中,可通过图像分类识别异常行为;在智能交通系统中,实现对交通标志和车辆类型的快速识别等。本文将通过安装包已有数据带你逐步了解使用Python进行图像分类的全过程。二、环境搭建在开始图像分类项目前,需要确保Python环境中安装了必要的库。主要包括:T
- CVPR 2024 图像、视频处理总汇(视频字幕、图像超分辨率、图像分类和压缩等)
点云SLAM
图形图像处理深度学习计算机视觉图像处理视频处理3DGSCVPR2024
1、Image/VideoCaptioning(图像/视频字幕)VisualFactChecker:EnablingHigh-FidelityDetailedCaptionGenerationPolos:MultimodalMetricLearningfromHumanFeedbackforImageCaptioning⭐codeprojectPanda-70M:Captioning70MVide
- ConvNeXT:面向 2020 年代的卷积神经网络
摘要视觉识别的“咆哮二十年代”始于VisionTransformer(ViT)的引入,ViT很快取代了ConvNet,成为图像分类任务中的最新最强模型。然而,vanillaViT在应用于目标检测、语义分割等通用计算机视觉任务时面临困难。HierarchicalTransformer(如SwinTransformer)重新引入了若干ConvNet的先验知识,使Transformer成为实用的通用视觉
- 【零基础学AI】第22讲:PyTorch入门 - 动态图计算与图像分类器实战
1989
0基础学AI人工智能pytorchpython机器学习sklearn深度学习
本节课你将学到理解PyTorch的核心概念和优势掌握张量(Tensor)的基本操作学会使用动态计算图构建神经网络实现一个完整的图像分类器项目训练模型并进行预测开始之前环境要求Python3.8+建议使用GPU(可选,CPU也能运行)内存:至少4GB需要安装的包#CPU版本(推荐新手)pipinstalltorchtorchvisionmatplotlibpillow#GPU版本(如果有NVIDIA
- 深度解析生成式 AI:从技术原理到实战应用
LNL13
人工智能
一、生成式AI:重构数字内容生产范式(一)技术定义与核心价值生成式人工智能(GenerativeAI)是通过深度学习模型自动创造文本、图像、代码、视频等内容的技术体系,其核心在于从数据中学习概率分布并生成符合人类认知的输出。与传统判别式AI(如图像分类)不同,生成式AI实现了从"识别"到"创造"的跨越,典型应用包括:文本领域:ChatGPT对话系统、小说自动生成图像领域:MidJourney艺术创
- Python机器学习实战——逻辑回归(附完整代码和结果)
小白熊XBX
机器学习机器学习python逻辑回归
Python机器学习实战——逻辑回归(附完整代码和结果)关于作者作者:小白熊作者简介:精通c#、Halcon、Python、Matlab,擅长机器视觉、机器学习、深度学习、数字图像处理、工业检测识别定位、用户界面设计、目标检测、图像分类、姿态识别、人脸识别、语义分割、路径规划、智能优化算法、大数据分析、各类算法融合创新等等。联系邮箱:
[email protected]科研辅导、知识付费答疑、个性化定制
- PyTorch实战:从零开始构建CIFAR-10图像分类模型 (附详细代码与图解)
电脑能手
pytorch分类人工智能深度学习python
PyTorch实战:从零开始构建CIFAR-10图像分类模型(附详细代码与图解)大家好!今天,我们将一起踏上一段激动人心的深度学习之旅:使用强大的PyTorch框架,从零开始构建一个卷积神经网络(CNN),来解决经典的CIFAR-10图像分类问题。无论你是深度学习的新手,还是希望巩固PyTorch基础知识的开发者,本文都将为你提供一个清晰、详尽的实战指南。本文目标读完本文,你将学会:加载和预处理C
- 图像分类:从基础原理到前沿技术
随机森林404
计算机视觉分类数据挖掘人工智能
引言在当今数字化时代,图像数据正以惊人的速度增长。从社交媒体上的照片分享到医疗影像诊断,从自动驾驶到工业质检,图像分类技术已经成为人工智能领域最基础也最重要的应用之一。本文将全面介绍图像分类的基础概念、发展历程、关键技术、应用场景以及未来趋势,帮助读者系统性地理解这一领域。第一章图像分类概述1.1什么是图像分类图像分类(ImageClassification)是计算机视觉中的一项核心任务,其目标是
- 深度学习之分类手写数字的网络
newyork major
卷积神经网络CNN深度学习人工智能
面临的问题定义神经⽹络后,我们回到⼿写识别上来。我们可以把识别⼿写数字问题分成两个⼦问题:把包含许多数字的图像分成⼀系列单独的图像,每个包含单个数字;也就是把图像,分成6个单独的图像分类单独的数字我们将专注于编程解决第⼆个问题,分类单独的数字。这样是因为,⼀旦你有分类单独数字的有效⽅法,分割问题是不难解决的。⼀种⽅法是尝试不同的分割⽅式,⽤数字分类器对每⼀个切分⽚段打分;如果数字分类器对每⼀个⽚段
- 贝叶斯网络与深度学习的结合:图像识别和分类
AI天才研究院
AI人工智能与大数据计算AI大模型企业级应用开发实战自然语言处理人工智能语言模型编程实践开发语言架构设计
本文我将为您撰写一篇关于"贝叶斯网络与深度学习的结合:图像识别和分类"的技术博客文章。这篇文章将深入探讨贝叶斯网络和深度学习在图像识别和分类领域的结合应用。我会遵循您提供的要求和结构模板,确保文章内容全面、深入且易于理解。让我们开始吧。贝叶斯网络与深度学习的结合:图像识别和分类关键词:贝叶斯网络、深度学习、图像识别、图像分类、概率推理、卷积神经网络、不确定性建模文章目录贝叶斯网络与深度学习的结合:
- 基于深度学习的线上问诊系统设计与实现(Python+Django+MySQL)
神经网络15044
深度学习算法神经网络python深度学习django机器学习人工智能算法目标检测
基于深度学习的线上问诊系统设计与实现(Python+Django+MySQL)一、系统概述本系统结合YOLOv8目标检测和ResNet50图像分类算法,构建了一个智能线上问诊平台。系统支持用户上传医学影像(皮肤照片/X光片),自动分析并生成诊断报告,同时提供医生审核功能。二、技术栈后端框架:Django4.2数据库:MySQL8.0深度学习:YOLOv8:皮肤病变区域检测ResNet50:肺炎X光
- 【EI会议征稿】东北大学主办第三届机器视觉、图像处理与影像技术国际会议(MVIPIT 2025)
诗远Yolanda
图像处理计算机视觉考研视频机器学习论文阅读
一、会议信息大会官网:www.mvipit.org官方邮箱:
[email protected]会议地点:辽宁沈阳主办单位:东北大学会议时间:2025年9月27日-9月29日二、征稿主题集中但不限于“机器视觉、图像处理与影像技术”等其他相关主题。机器视觉:视觉中的统计机器学习;立体视觉标定;几何建模与处理;人脸识别与手势识别;早期视觉和生物学启发的视觉;光流法和运动追踪;图像分割和图像分类;基于模型的视觉
- 基于MATLAB图像特征识别及提取实现图像分类
jghhh01
机器学习算法人工智能
基于MATLAB的图形处理程序,可以进行图像特征识别及提取,进而实现图像分类。hog_svm.m,2276svm_images/test_image/1.jpg,20980svm_images/test_image/2.jpg,18246svm_images/test_image/3.jpg,13835svm_images/test_image/4.jpg,18539svm_images/test
- 数据标注师学习内容汇总
试着
数据标注师学习数据标注师
目录文本标注图像标注语音标注文本标注词性标注1词性标注2实体标注关系标注事件标注1事件标注2意图标注关键词标注分类标注问答标注对话标注图像标注拉框标注关键点标注2D标注3D标注线标注目标跟踪标注OCR标注图像分类标注语音标注语音切割转写语音校对标注拼音和停顿标注
- 基于OpenCV图像分割与PyTorch的增强图像分类方案
从零开始学习人工智能
opencvpytorch分类
在图像分类任务中,背景噪声和复杂场景常常会对分类准确率产生负面影响。为了应对这一挑战,本文介绍了一种结合OpenCV图像分割与PyTorch深度学习框架的增强图像分类方案。通过先对图像进行分割提取感兴趣区域(RegionofInterest,ROI),再进行分类,可以有效减少背景干扰,突出关键特征,从而提高分类准确率。该方案在多种复杂场景下表现出色,尤其适用于图像背景复杂或包含多个对象的情况。一、
- DAY 43 复习日
yizhimie37
python训练营打卡笔记深度学习
@浙大疏锦行https://blog.csdn.net/weixin_45655710第一步:寻找并准备图像数据集在Kaggle等平台上,你可以找到大量用于图像分类任务的数据集,例如英特尔图像分类数据集(IntelImageClassification)或手写数字识别数据集(DigitRecognizer)。对于初学者,一个更便捷的选择是使用像TensorFlow或PyTorch这样深度学习框架内
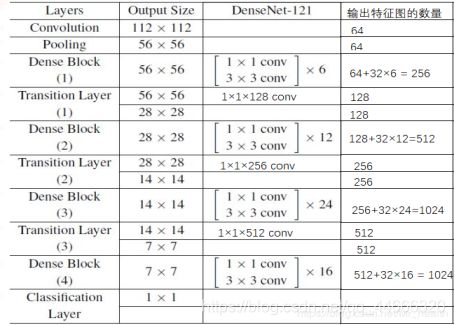
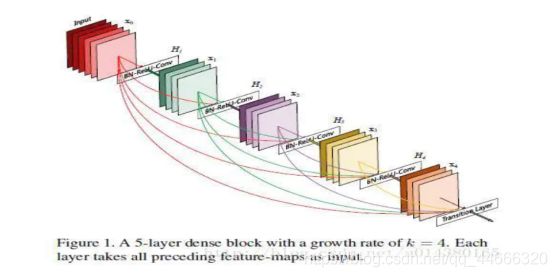
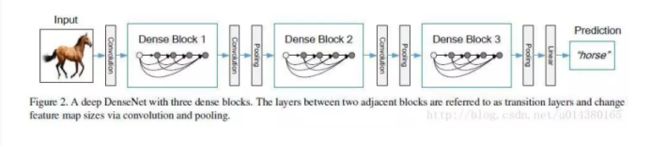
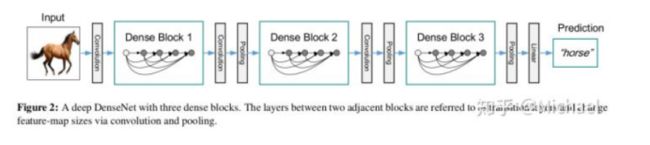
- Densenet模型花卉图像分类
深度学习乐园
分类数据挖掘人工智能
项目源码获取方式见文章末尾!600多个深度学习项目资料,快来加入社群一起学习吧。《------往期经典推荐------》项目名称1.【基于CNN-RNN的影像报告生成】2.【卫星图像道路检测DeepLabV3Plus模型】3.【GAN模型实现二次元头像生成】4.【CNN模型实现mnist手写数字识别】5.【fasterRCNN模型实现飞机类目标检测】6.【CNN-LSTM住宅用电量预测】7.【VG
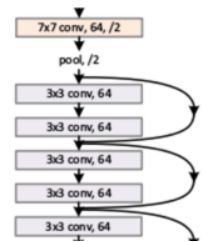
- ResNet(Residual Network)
不想秃头的程序
神经网络语音识别人工智能深度学习网络残差网络神经网络
ResNet(ResidualNetwork)是深度学习中一种经典的卷积神经网络(CNN)架构,由微软研究院的KaimingHe等人在2015年提出。它通过引入残差连接(SkipConnection)解决了深度神经网络中的梯度消失问题,使得网络可以训练极深的模型(如上百层),并在图像分类、目标检测、语义分割等任务中取得了突破性成果。以下是ResNet的详细介绍:一、核心思想ResNet的核心创新是
- DAY 43 复习日 CNN训练与Grad-CAM可视化(模块化实现)
沐兮兮兮
cnn人工智能神经网络
目录Kaggle图像分类项目:项目结构一、数据准备模块1.config/paths.py2.data/preprocessing.py3.data/dataset.py二、模型定义模块1.models/cnn_model.py2.models/grad_cam.py三、训练脚本train.py四、可视化模块1.utils/visualization.py2.visualize.py五、实用工具ut
- Python 人工智能Ai视觉模型 YOLOv8
GHY云端大师
pythonAI大模型视觉训练人工智能YOLO
YOLOv8简介:Python中的高效AI视觉模型YOLOv8是Ultralytics公司开发的最新目标检测模型,属于YOLO(YouOnlyLookOnce)系列的最新版本,以其高效和准确著称。核心特点高性能:在速度和精度之间取得了更好的平衡多功能:支持目标检测、实例分割和图像分类用户友好:简化了API设计,更易于使用可扩展性:支持从移动端到云端的多种部署场景主要改进更高的检测精度更快的推理速度
- js动画html标签(持续更新中)
843977358
htmljs动画mediaopacity
1.jQuery 效果 - animate() 方法 改变 "div" 元素的高度: $(".btn1").click(function(){ $("#box").animate({height:"300px
- springMVC学习笔记
caoyong
springMVC
1、搭建开发环境
a>、添加jar文件,在ioc所需jar包的基础上添加spring-web.jar,spring-webmvc.jar
b>、在web.xml中配置前端控制器
<servlet>
&nbs
- POI中设置Excel单元格格式
107x
poistyle列宽合并单元格自动换行
引用:http://apps.hi.baidu.com/share/detail/17249059
POI中可能会用到一些需要设置EXCEL单元格格式的操作小结:
先获取工作薄对象:
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet();
HSSFCellStyle setBorder = wb.
- jquery 获取A href 触发js方法的this参数 无效的情况
一炮送你回车库
jquery
html如下:
<td class=\"bord-r-n bord-l-n c-333\">
<a class=\"table-icon edit\" onclick=\"editTrValues(this);\">修改</a>
</td>"
j
- md5
3213213333332132
MD5
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
public class MDFive {
public static void main(String[] args) {
String md5Str = "cq
- 完全卸载干净Oracle11g
sophia天雪
orale数据库卸载干净清理注册表
完全卸载干净Oracle11g
A、存在OUI卸载工具的情况下:
第一步:停用所有Oracle相关的已启动的服务;
第二步:找到OUI卸载工具:在“开始”菜单中找到“oracle_OraDb11g_home”文件夹中
&
- apache 的access.log 日志文件太大如何解决
darkranger
apache
CustomLog logs/access.log common 此写法导致日志数据一致自增变大。
直接注释上面的语法
#CustomLog logs/access.log common
增加:
CustomLog "|bin/rotatelogs.exe -l logs/access-%Y-%m-d.log
- Hadoop单机模式环境搭建关键步骤
aijuans
分布式
Hadoop环境需要sshd服务一直开启,故,在服务器上需要按照ssh服务,以Ubuntu Linux为例,按照ssh服务如下:
sudo apt-get install ssh
sudo apt-get install rsync
编辑HADOOP_HOME/conf/hadoop-env.sh文件,将JAVA_HOME设置为Java
- PL/SQL DEVELOPER 使用的一些技巧
atongyeye
javasql
1 记住密码
这是个有争议的功能,因为记住密码会给带来数据安全的问题。 但假如是开发用的库,密码甚至可以和用户名相同,每次输入密码实在没什么意义,可以考虑让PLSQL Developer记住密码。 位置:Tools菜单--Preferences--Oracle--Logon HIstory--Store with password
2 特殊Copy
在SQL Window
- PHP:在对象上动态添加一个新的方法
bardo
方法动态添加闭包
有关在一个对象上动态添加方法,如果你来自Ruby语言或您熟悉这门语言,你已经知道它是什么...... Ruby提供给你一种方式来获得一个instancied对象,并给这个对象添加一个额外的方法。
好!不说Ruby了,让我们来谈谈PHP
PHP未提供一个“标准的方式”做这样的事情,这也是没有核心的一部分...
但无论如何,它并没有说我们不能做这样
- ThreadLocal与线程安全
bijian1013
javajava多线程threadLocal
首先来看一下线程安全问题产生的两个前提条件:
1.数据共享,多个线程访问同样的数据。
2.共享数据是可变的,多个线程对访问的共享数据作出了修改。
实例:
定义一个共享数据:
public static int a = 0;
- Tomcat 架包冲突解决
征客丶
tomcatWeb
环境:
Tomcat 7.0.6
win7 x64
错误表象:【我的冲突的架包是:catalina.jar 与 tomcat-catalina-7.0.61.jar 冲突,不知道其他架包冲突时是不是也报这个错误】
严重: End event threw exception
java.lang.NoSuchMethodException: org.apache.catalina.dep
- 【Scala三】分析Spark源代码总结的Scala语法一
bit1129
scala
Scala语法 1. classOf运算符
Scala中的classOf[T]是一个class对象,等价于Java的T.class,比如classOf[TextInputFormat]等价于TextInputFormat.class
2. 方法默认值
defaultMinPartitions就是一个默认值,类似C++的方法默认值
- java 线程池管理机制
BlueSkator
java线程池管理机制
编辑
Add
Tools
jdk线程池
一、引言
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
- 关于hql中使用本地sql函数的问题(问-答)
BreakingBad
HQL存储函数
转自于:http://www.iteye.com/problems/23775
问:
我在开发过程中,使用hql进行查询(mysql5)使用到了mysql自带的函数find_in_set()这个函数作为匹配字符串的来讲效率非常好,但是我直接把它写在hql语句里面(from ForumMemberInfo fm,ForumArea fa where find_in_set(fm.userId,f
- 读《研磨设计模式》-代码笔记-迭代器模式-Iterator
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.Arrays;
import java.util.List;
/**
* Iterator模式提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象内部表示
*
* 个人觉得,为了不暴露该
- 常用SQL
chenjunt3
oraclesqlC++cC#
--NC建库
CREATE TABLESPACE NNC_DATA01 DATAFILE 'E:\oracle\product\10.2.0\oradata\orcl\nnc_data01.dbf' SIZE 500M AUTOEXTEND ON NEXT 50M EXTENT MANAGEMENT LOCAL UNIFORM SIZE 256K ;
CREATE TABLESPA
- 数学是科学技术的语言
comsci
工作活动领域模型
从小学到大学都在学习数学,从小学开始了解数字的概念和背诵九九表到大学学习复变函数和离散数学,看起来好像掌握了这些数学知识,但是在工作中却很少真正用到这些知识,为什么?
最近在研究一种开源软件-CARROT2的源代码的时候,又一次感觉到数学在计算机技术中的不可动摇的基础作用,CARROT2是一种用于自动语言分类(聚类)的工具性软件,用JAVA语言编写,它
- Linux系统手动安装rzsz 软件包
daizj
linuxszrz
1、下载软件 rzsz-3.34.tar.gz。登录linux,用命令
wget http://freeware.sgi.com/source/rzsz/rzsz-3.48.tar.gz下载。
2、解压 tar zxvf rzsz-3.34.tar.gz
3、安装 cd rzsz-3.34 ; make posix 。注意:这个软件安装与常规的GNU软件不
- 读源码之:ArrayBlockingQueue
dieslrae
java
ArrayBlockingQueue是concurrent包提供的一个线程安全的队列,由一个数组来保存队列元素.通过
takeIndex和
putIndex来分别记录出队列和入队列的下标,以保证在出队列时
不进行元素移动.
//在出队列或者入队列的时候对takeIndex或者putIndex进行累加,如果已经到了数组末尾就又从0开始,保证数
- C语言学习九枚举的定义和应用
dcj3sjt126com
c
枚举的定义
# include <stdio.h>
enum WeekDay
{
MonDay, TuesDay, WednesDay, ThursDay, FriDay, SaturDay, SunDay
};
int main(void)
{
//int day; //day定义成int类型不合适
enum WeekDay day = Wedne
- Vagrant 三种网络配置详解
dcj3sjt126com
vagrant
Forwarded port
Private network
Public network
Vagrant 中一共有三种网络配置,下面我们将会详解三种网络配置各自优缺点。
端口映射(Forwarded port),顾名思义是指把宿主计算机的端口映射到虚拟机的某一个端口上,访问宿主计算机端口时,请求实际是被转发到虚拟机上指定端口的。Vagrantfile中设定语法为:
c
- 16.性能优化-完结
frank1234
性能优化
性能调优是一个宏大的工程,需要从宏观架构(比如拆分,冗余,读写分离,集群,缓存等), 软件设计(比如多线程并行化,选择合适的数据结构), 数据库设计层面(合理的表设计,汇总表,索引,分区,拆分,冗余等) 以及微观(软件的配置,SQL语句的编写,操作系统配置等)根据软件的应用场景做综合的考虑和权衡,并经验实际测试验证才能达到最优。
性能水很深, 笔者经验尚浅 ,赶脚也就了解了点皮毛而已,我觉得
- Word Search
hcx2013
search
Given a 2D board and a word, find if the word exists in the grid.
The word can be constructed from letters of sequentially adjacent cell, where "adjacent" cells are those horizontally or ve
- Spring4新特性——Web开发的增强
jinnianshilongnian
springspring mvcspring4
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- CentOS安装配置tengine并设置开机启动
liuxingguome
centos
yum install gcc-c++
yum install pcre pcre-devel
yum install zlib zlib-devel
yum install openssl openssl-devel
Ubuntu上可以这样安装
sudo aptitude install libdmalloc-dev libcurl4-opens
- 第14章 工具函数(上)
onestopweb
函数
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- Xelsius 2008 and SAP BW at a glance
blueoxygen
BOXelsius
Xelsius提供了丰富多样的数据连接方式,其中为SAP BW专属提供的是BICS。那么Xelsius的各种连接的优缺点比较以及Xelsius是如何直接连接到BEx Query的呢? 以下Wiki文章应该提供了全面的概览。
http://wiki.sdn.sap.com/wiki/display/BOBJ/Xcelsius+2008+and+SAP+NetWeaver+BW+Co
- oracle表空间相关
tongsh6
oracle
在oracle数据库中,一个用户对应一个表空间,当表空间不足时,可以采用增加表空间的数据文件容量,也可以增加数据文件,方法有如下几种:
1.给表空间增加数据文件
ALTER TABLESPACE "表空间的名字" ADD DATAFILE
'表空间的数据文件路径' SIZE 50M;
&nb
- .Net framework4.0安装失败
yangjuanjava
.netwindows
上午的.net framework 4.0,各种失败,查了好多答案,各种不靠谱,最后终于找到答案了
和Windows Update有关系,给目录名重命名一下再次安装,即安装成功了!
下载地址:http://www.microsoft.com/en-us/download/details.aspx?id=17113
方法:
1.运行cmd,输入net stop WuAuServ
2.点击开