李沐精读论文:ViT 《An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale》
视频:ViT论文逐段精读【论文精读】_哔哩哔哩_bilibili
代码:论文源码
使用pytorch搭建Vision Transformer(vit)模型
vision_transforme · WZMIAOMIAO/deep-learning-for-image-processing · GitHub
Pytorch官方源码
VisionTransformer — Torchvision API
参考博文:ViT论文逐段精读【论文精读】 - 哔哩哔哩
李沐论文精读系列二:Vision Transformer神洛华的博客
目录
1 引言
1.1 Vision Transformer的一些有趣特性
1.2 标题
1.3 摘要
1.4 引言
Transformer在NLP领域的应用
将transformer运用到视觉领域的难处
将自注意力用到机器视觉的相关工作
vision transformer如何解决序列长度的问题
有监督的训练
前人最相关的工作
ViT和CNN网络使用效果的比较
2、结论
3、相关工作
transformer在NLP领域的应用
自注意力在视觉中的应用
4 ViT 模型
4.1 整体结构和前向传播
4.2 图片预处理
4.3 Transformer Encoder
4.4 MLP Head和ViT-B/16模型结构图
4.5数学公式描述
5 消融实验(附录)
5.1 class token
5.2 位置编码
6 模型探讨
归纳偏置
Hybrid混合模型试验
更大尺寸上的微调
7 实验部分
7.1 ViT模型变体
7.2 ViT模型以及和CNN对比结果
7.3 ViT预训练需要多大的数据规模?(重要论证)
7.4 结论
8 ViT可视化
patch embedding可视化
position embedding可视化
自注意力是否起作用了
out token输出
9 自监督训练
10 总结
这篇文章挑战了自从2012年AlexNet提出以来卷积神经网络在计算机视觉里绝对统治的地位。结论是如果在足够多的数据上做预训练,也可以不需要卷积神经网路,直接使用标准的transformer也能够把视觉问题解决的很好。它打破了CV和NLP在模型上的壁垒,开启了CV的一个新时代,推进了多模态领域的发展。
paperswithcode可以查询现在某个领域或者说某个数据集表现最好的一些方法有哪些。图像分类在ImageNet数据集上排名靠前的全是基于Vision Transformer The latest in Machine Learning | Papers With Code

ImageNet Benchmark (Image Classification) | Papers With Code
对于目标检测任务在COCO数据集上,排名靠前都都是基于Swin Transformer。Swin Transformer是ICCV 21的最佳论文,可以把它想象成一个多尺度的Vit(Vision Transformer)

COCO test-dev Benchmark (Object Detection) | Papers With Code
在其他领域(语义分割、实例分割、视频、医疗、遥感),基本上可以说Vision Transformer将整个视觉领域中所有的任务都刷了个遍。
1 引言
1.1 Vision Transformer的一些有趣特性
作者的另一篇论文:
《Intriguing Properties of Vision Transformer》
如下图所示:

图a表示的是遮挡,在这么严重的遮挡情况下,不管是卷积神经网络,人眼也很难观察出图中所示的是一只鸟
图b表示数据分布上有所偏移,这里对图片做了一次纹理去除的操作,所以图片看起来比较魔幻
图c表示在鸟头的位置加了一个对抗性的patch
图d表示将图片打散了之后做排列组合
上述例子中,卷积神经网络很难判断到底是一个什么物体,但是对于所有的这些例子Vision Transformer都能够处理的很好。
1.2 标题
一张图片等价于很多16*16大小的单词。为什么是16*16的单词?把图片分割成很多方格patch的形式,每一个方格的大小都是16*16,那么这张图片就相当于是很多16*16的patch组成的整体

1.3 摘要
在VIT之前,self-attention在CV领域的应用很有限,要么和卷积一起使用,要么就是把CNN里面的某些模块替换成self-attention,但是整体架构不变。
这篇文章证明了,在图片分类任务中,只使用纯的Vision Transformer结构直接作用于一系列图像块,也可以取的很好的效果(最佳模型在ImageNet1K上能够达到88.55%的准确率)。尤其是当在大规模的数据上面做预训练然后迁移到中小型数据集(ImageNet、CIFAR-100、VATB)上面使用的时候,Vision Transformer能够获得跟最好的卷积神经网络相媲美的结果。Transformer的另外一个好处:它只需要更少的训练资源,而且表现还特别好。
作者这里指的少的训练资源是指2500天TPUv3的天数。这里的少只是跟更耗卡的模型去做对比。
1.4 引言
Transformer在NLP领域的应用
基于self-attention的模型架构,特别是Transformer,在NLP领域几乎成了必选架构。现在比较主流的方式,就是先去一个大规模的数据集上去做预训练,然后再在一些特定领域的小数据集上面做微调。多亏了Transformer的高效性和可扩展性,现在已经可以训练超过1000亿参数的大模型(GPT3)。随着模型和数据集的增长,还没有看到性能饱和的现象。
- 很多时候不是一味地扩大数据集或者说扩大模型就能够获得更好的效果的,尤其是当扩大模型的时候很容易碰到过拟合的问题,但是对于transformer来说目前还没有观测到这个瓶颈
- 微软和英伟达联合推出了一个超级大的语言生成模型Megatron-Turing,它已经有5300亿参数了,还能在各个任务上继续大幅度提升性能,没有任何性能饱和的现象
将transformer运用到视觉领域的难处
Transformer在做自注意力的时候是两两互相的,这个计算复杂度是跟序列的长度呈平方倍的。目前一般在自然语言处理中,硬件能支持的序列长度一般也就是几百或者是上千(比如说BERT的序列长度也就是512)。
首先要解决的是如何把一个2D的图片变成一个1D的序列(或者说变成一个集合)。最直观的方式就是把每个像素点当成元素,将图片拉直放进transformer里,看起来比较简单,但是实现起来复杂度较高。
一般来说在视觉中训练分类任务的时候图片的输入大小大概是224*224,如果将图片中的每一个像素点都直接当成元素来看待的话,序列长度就是224*224=50176个像素点,这个大小就相当于是BERT序列长度的100倍。这还仅仅是分类任务,对于检测和分割,现在很多模型的输入都已经变成600*600或者800*800或者更大,计算复杂度更高,所以在视觉领域,卷积神经网络还是占主导地位的,比如AlexNet或者是ResNet。
将自注意力用到机器视觉的相关工作
受NLP启发,很多工作研究如何将自注意力用到机器视觉中。一些工作是说把卷积神经网络和自注意力混到一起用;另外一些工作就是整个将卷积神经网络换掉,全部用自注意力。这些方法其实都是在干一个事情:因为序列长度太长,所以导致没有办法将transformer用到视觉中,所以就想办法降低序列长度
Non-local Neural Networks(CVRP,2018):将网络中间层输出的特征图作为transformer输入序列,降低序列的长度。比如ResNet50在最后一个Stage的特征图size=14×14,把它拉平,序列元素就只有196了,这就在一个可以接受的范围内了。
《Stand-Alone & Self-Attention in Vision Models》(NeurIPS,2019):使用孤立注意力Stand-Alone和 Axial-Attention来处理。具体的说,不是输入整张图,而是在一个local window(局部的小窗口)中计算attention。窗口的大小可以控制,复杂度也就大大降低。(类似卷积的操作)
《Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation》(ECCV,2020a):
- 孤立自注意力:不使用整张图,就用一个local window(局部的小窗口),通过控制这个窗口的大小,来让计算复杂度在可接受的范围之内。这就类似于卷积操作(卷积也是在一个局部的窗口中操作的)
- 轴自注意力:之所以视觉计算的复杂度高是因为序列长度N=H*W,是一个2D的矩阵,将图片的这个2D的矩阵想办法拆成2个1D的向量,所以先在高度的维度上做一次self-attention(自注意力),然后再在宽度的维度上再去做一次自注意力,相当于把一个在2D矩阵上进行的自注意力操作变成了两个1D的顺序的操作,这样大幅度降低了计算的复杂度
这些模型虽然理论上是非常高效的,但事实上这个自注意力操作都是一些比较特殊的自注意力操作,无法在现在的硬件上进行加速,所以就导致很难训练出一个大模型。因此在大规模的图像识别上,传统的残差网络还是效果最好的。
所以,自注意力早已经在计算机视觉里有所应用,而且已经有完全用自注意力去取代卷积操作的工作了。本文是被transformer在NLP领域的可扩展性所启发,直接应用一个标准的transformer作用于图片,尽量做少的修改。
vision transformer如何解决序列长度的问题
To do so, we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer. Image patches are treated the same way as tokens (words) in an NLP application. We train the model on image classification in supervised fashion.
- vision transformer将一张图片打成了很多的patch,每一个patch是16*16
- 假如图片的大小是224*224,则sequence lenth(序列长度)就是N=224*224=50176,如果换成patch,一个patch相当于一个元素的话,有效的长宽就变成了224/16=14,所以最后的序列长度就变成了N=14*14=196,对于普通的transformer来说是可以接受的
- 将每一个patch当作一个元素,通过一个全连接层就会得到一个linear embedding,这些就会当作输入传给transformer。这时候一张图片就变成了一个一个的图片块了,可以将这些图片块当成是NLP中的单词,一个句子中有多少单词就相当于是一张图片中有多少个patch,这就是题目中所提到的一张图片等价于很多16*16的单词
有监督的训练
本文训练vision transformer使用的是有监督的训练。为什么要突出有监督?因为对于NLP来说,transformer基本上都是用无监督的方式训练的,要么是用language modeling,要么是用mask language modeling,都是用的无监督的训练方式。但是对于视觉来说,大部分的基线(baseline)网络还都是用的有监督的训练方式去训练的
前人最相关的工作
本文把视觉当成自然语言处理的任务去做的,尤其是中间的模型就是使用的transformer encoder,跟BERT完全一样。这么简单的想法,之前其实也有人想到过去做,跟本文的工作最像的是一篇ICLR 2020的paper
- 这篇论文是从输入图片中抽取2*2的图片patch
- 为什么是2*2?因为这篇论文的作者只在CIFAR-10数据集上做了实验,而CIFAR-10这个数据集上的图片都是32*32的,所以只需要抽取2*2的patch就足够了,16*16的patch太大了
- 在抽取好patch之后,就在上面做self-attention
从技术上而言这就是Vision Transformer,但是本文的作者认为二者的区别在于,本文的工作证明了如果在大规模的数据集上做预训练的话,那么就能让一个标准的Transformer,不用在视觉上做任何的更改或者特殊的改动,取得比现在最好的卷积神经网络差不多或者还好的结果。
This model is very similar to ViT, but our work goes further to demonstrate that large scale pre-training makes vanilla transformers competitive with (or even better than) state-of-the-art CNNs.
这篇文章的主要目的就是说,Transformer在Vision领域能够扩展的有多好,就是在超级大数据集和超级大模型两方的加持下,transformer也能在视觉中起到很好的效果
ViT和CNN网络使用效果的比较
在中型大小的数据集上(比如说ImageNet)上训练的时候,如果不加比较强的约束,ViT的模型其实跟同等大小的残差网络相比要弱一点。
作者对此的解释是:transformer跟CNN相比,缺少了一些CNN所带有的归纳偏置(inductive bias,是指一种先验知识或者说是一种提前做好的假设)。
CNN的归纳偏置一般来说有两种:
- locality:CNN是以滑动窗口的形式一点一点地在图片上进行卷积的,所以假设图片上相邻的区域会有相邻的特征,靠得越近的东西相关性越强;
- translation equivariance(平移等变性):写成公式就是f(g(x))=g(f(x)),不论是先做 g 这个函数,还是先做 f 这个函数,最后的结果是不变的;其中f代表卷积操作,g代表平移操作。因为在卷积神经网络中,卷积核就相当于是一个模板,不论图片中同样的物体移动到哪里,只要是同样的输入进来,然后遇到同样的卷积核,那么输出永远是一样的
一旦神经网络有了这两个归纳偏置之后,他就拥有了很多的先验信息,所以只需要相对较少的数据就可以学习一个相对比较好的模型。但是对于transformer来说,它没有这些先验信息,所以它对视觉的感知全部需要从这些数据中自己学习。
为了验证这个假设, 作者在更大的数据集(ImageNet 22k数据集, 14M个样本&JFT 300M数据集, 300M个样本)上做了预训练,然后发现在有足够的数据做预训练的情况下,Vit能够获得跟现在最好的残差神经网络相近或者说更好的结果
Our Vision Transformer (ViT) attains excellent results when pre-trained at sufficient scale and transferred to tasks with fewer datapoints. When pre-trained on the public ImageNet-21k dataset or the in-house JFT-300M dataset, ViT approaches or beats state of the art on multiple image recognition benchmarks. In particular, the best model reaches the accuracy of 88.55% on ImageNet, 90.72% on ImageNet-ReaL, 94.55% on CIFAR-100, and 77.63% on the VTAB suite of 19 tasks
上面VTAB也是作者团队所提出来的一个数据集,融合了19个数据集,主要是用来检测模型的稳健性,从侧面也反映出了VisionTransformer的稳健性也是相当不错的。
2、结论
这篇论文的工作是直接拿NLP领域中标准的Transformer来做计算机视觉的问题,跟之前用自注意力的那些工作的区别在于,除了在刚开始抽图像块的时候,还有位置编码用了一些图像特有的归纳偏置,除此之外就再也没有引入任何图像特有的归纳偏置了。这样的好处就是可以直接把图片当做NLP中的token,拿NLP中一个标准的Transformer就可以做图像分类了。
当这个简单而且扩展性很好的策略和大规模预训练结合起来的时候效果出奇的好:Vision Transformer在很多图像分类的benchmark上超过了之前最好的方法,而且训练起来还相对便宜
作者对未来的展望:
- Vit不只做分类,还有检测和分割
- DETR:目标检测的一个力作,相当于是改变了整个目标检测之前的框架
- 在Vit出现短短的一个半月之后,2020年12月出来了一个叫Vit-FRCNN的工作,将Vit用到检测上面了
- 2020年12月有一篇SETR的paper将Vit用到分割里了
- 3个月之后Swin Transformer横空出世,它将多尺度的设计融合到了Transformer中,更加适合做视觉的问题,真正证明了Transformer是能够当成一个视觉领域的通用骨干网络
- 探索一下自监督的预训练方案
因为在NLP领域,所有大的transformer全都是用自监督的方式训练的,Vit这篇paper也做了一些初始实验,证明了用这种自监督的训练方式也是可行的,但是跟有监督的训练比起来还是有不小的差距的
- 将Vision Transformer变得更大,有可能会带来更好的结果
过了半年,同样的作者团队又出了一篇paper叫做Scaling Vision Transformer,就是将Transformer变得很大,提出了一个Vit-G,将ImageNet图像分类的准确率提高到了90以上了
3、相关工作
transformer在NLP领域的应用
自从2017年transformer提出做机器翻译以后,基本上transformer就是很多NLP任务中表现最好的方法。现在大规模的transformer模型一般都是先在一个大规模的语料库上做预训练,然后再在目标任务上做一些细小的微调,这当中有两系列比较出名的工作:BERT和GPT。BERT是用一个denoising的自监督方式(其实就是完形填空,将一个句子中某些词划掉,再将这些词预测出来);GPT用的是language modeling(已经有一个句子,然后去预测下一个词是什么,也就是next word prediction)做自监督。这两个人物其实都是人为定的,语料是固定的,句子也是完整的,只是人为划掉其中的某些部分或者把最后的词拿掉,然后去做完形填空或者是预测下一个词,所以这叫自监督的训练方式
自注意力在视觉中的应用
视觉中如果想简单地在图片上使用自注意力,最简单的方式就是将每一个像素点当成是一个元素,让他们两两做自注意力就好了,但是这个是平方复杂度,所以很难应用到真实的图片输入尺寸上。像现在分类任务的224*224,一个transformer都很难处理,更不用提人眼看的比较清晰的图片了,一般是1k或者4k的画质,序列长度都是上百万,直接在像素层面使用transformer的话不太现实,所以如果想用transformer就一定得做一些近似
- 复杂度高是因为用了整张图,所以序列长度长,那么可以不用整张图,就用local neighborhood(一个小窗口)来做自注意力,那么序列长度就大大降低了,最后的计算复杂度也就降低了
- 使用Sparse Transformer,就是只对一些稀疏的点去做自注意力,所以只是一个全局注意力的近似
- 将自注意力用到大小不同的block上,或者说在极端的情况下使用轴注意力(先在横轴上做自注意力,然后再在纵轴上做自注意力),序列长度也是大大减小的
这些特制的自注意力结构其实在计算机视觉上的结果都不错,表现都是没问题的,但是它们需要很复杂的工程去加速算子,虽然在CPU或者GPU上跑得很快或者说让训练一个大模型成为可能
跟本文工作最相似的是一篇ICLR2020的论文,区别在于Vision Transformer使用了更大的patch,更大的数据集
在计算机视觉领域还有很多工作是把卷积神经网络和自注意力结合起来的,这类工作相当多,而且基本涵盖了视觉里的很多任务(检测、分类、视频、多模态等)
还有一个工作和本文的工作很相近,叫image GPT
- GPT是用在NLP中的,是一个生成性的模型。image GPT也是一个生成性模型,也是用无监督的方式去训练的,和Vit相近的地方在于它也用了transformer
- image GPT最终所能达到的效果:如果将训练好的模型做微调或者就把它当成一个特征提取器,它在ImageNet上的最高的分类准确率也只能到72,Vit最终的结果已经有88.5了,远高于72
- 但是这个结果也是最近一篇paper叫做MAE爆火的原因。因为在BEiT和MAE这类工作之前,生成式网络在视觉领域很多任务上是没有办法跟判别式网络相比的,判别式网络往往要比生成式网络的结果高很多,但是MAE做到了,它在ImageNet-1k数据集上训练,用一个生成式的模型,比之前判别式的模型效果好很多,而且不光是在分类任务上,最近发现在目标检测上的迁移学习的效果也非常好
Vit其实还跟另外一系列工作是有关系的,用比ImageNet更大的数据集去做预训练,这种使用额外数据的方式,一般有助于达到特别好的效果
- 2017年介绍JFT 300数据集的paper研究了卷积神经网络的效果是怎么随着数据集的增大而提高的
- 一些论文是研究了在更大的数据集(比如说ImageNet-21k和JFT 300M)上做预训练的时候,迁移到ImageNet或者CIFAR-100上的效果如何
这篇论文也是聚焦于ImageNet-21k和JFT 300M,但是训练的并不是一个残差网络,而是训练transformer
4 ViT 模型
4.1 整体结构和前向传播
在模型的设计上尽可能按照最原始的transformer来做的,这样做的好处是transformer在NLP领域已经火了很久了,它有一些非常高效的实现,可以直接拿来使用

简单而言,模型由三个模块组成:
- Embedding层(线性投射层Linear Projection of Flattened Patches)
- Transformer Encoder(图右侧有给出更加详细的结构)
- MLP Head(最终用于分类的层结构)
前向传播过程:
- 一张图片先分割成n个patchs,然后这些patchs变成序列,每个patch输入线性投射层,得到Pacth embedding。比如ViT-L/16表示每个patchs大小是16×16。
- position embedding:self-attention本身没有考虑输入的位置信息,无法对序列建模。而图片切成的patches也是有顺序的,打乱之后就不是原来的图片了。于是和transformer一样,引入position embedding。
- class token:在所有tokens前面加一个新的class token作为这些patchs全局输出,相当于transformer中的CLS(这里的加是concat拼接)。而且它也是有position embedding,位置信息永远是0
- Pacth embedding+position embedding+class token一起输入Transformer Encoder,得到输出。
- 因为所有的token都在跟其它token做交互信息,所以class embedding能够从别的embedding中学到有用的信息,class token的输出当做整个图片的特征,经过MLP Head得到分类结果(VIT只做分类任务)。最后用交叉熵函数进行模型的训练
模型中的Transformer encoder是一个标准的Transformer。整体上来看Vision Transformer的架构还是相当简洁的,它的特殊之处就在于如何把一个图片变成一系列的token
4.2 图片预处理
标准的Transformer模块要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim]。对于图像数据而言,其数据为[H, W, C]格式的三维矩阵,所以需要先通过一个Embedding层来对数据做变换。

首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch尺寸进行划分,划分后会得到196个Patches,每一个图像块的维度就是16*16*3=768。
在代码实现中,直接通过一个卷积层来实现。卷积核大小为16x16,步距为16,卷积核个数为768。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
接着通过线性映射E将每个Patch映射到一维向量中。这个全连接层的维度是768*768,第二个768就是文章中的D。
现在得到了patch embedding,它是一个196*768的矩阵,即现在有196个token,每个token向量的维度是768,到目前为止就已经成功地将一个vision的问题变成了一个NLP的问题了,输入就是一系列1d的token,而不再是一张2d的图片了
额外的cls token维度也是768,这样可以方便和后面图像的信息直接进行拼接。所以最后整体进入Transformer的序列的长度是197*768
Position Embedding是可以学习的,每一个向量代表一个位置信息(向量的维度是768),将这些位置信息加到所有的token中,序列还是197*768。
注:对于位置编码信息,本文用的是标准的可以学习的1d position embedding,它也是BERT使用的位置编码。作者也尝试了了别的编码形式,比如说2d-aware(它是一个能处理2d信息的位置编码),但是最后发现结果其实都差不多,没有什么区别
4.3 Transformer Encoder
Transformer Encoder其实就是重复堆叠Encoder Block L次。经过预处理,包括特殊的字符cls和位置编码信息,transformer输入的embedded patches就是一个197*768的tensor。
- Layer Norm层标准化:tensor先过一个layer norm,出来之后还是197*768。
- Multi-Head Attention:假设使用的是ViT的base版本,即使用了12个头,那么k、q、v的维度变成了197*64(768/12=64),进行12组k、q、v自注意力操作,最后再将12个头的输出拼接起来,输出还是197*768
- Dropout/DropPath:在原论文的代码中是直接使用的Dropout层,在但rwightman实现的代码中使用的是DropPath(stochastic depth),可能后者会更好一点。
- 再过一层layer norm,还是197*768
- MLP Block,全连接+GELU激活函数+Dropout组成。把维度放大到4倍[197, 768] -> [197, 3072],再还原回原节点个数[197, 3072] -> [197, 768]。
进去Transformer block之前是197*768,出来还是197*768,这个序列的长度和每个token对应的维度大小都是一样的,所以就可以在一个Transformer block上不停地往上叠加Transformer block,最后有L层Transformer block的模型就构成了Transformer encoder
Transformer从头到尾都是使用D当作向量的长度的,都是768,同一个模型里这个维度是不变的。如果transformer变得更大了,D也可以相应的变得更大。
The Transformer uses constant latent vector size D through all of its layers, so we flatten the patches and map to D dimensions with a trainable linear projection. We refer to the output of this projection as the patch embeddings.
4.4 MLP Head和ViT-B/16模型结构图
对于分类,只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768],通过MLP Head得到最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成,但是迁移到ImageNet1K上或者你自己的数据上时,只定义一个Linear即可。注意,在Transformer Encoder后其实还有一个Layer Norm,
下面是小绿豆绘制的ViT-B/16模型结构图Vision Transformer详解:(Pre-Logits就是Linear+tanh,一般迁移学习是可以不用的。)

4.5数学公式描述

(1)Xp表示图像块的patch,一共有N个patch,E表示线性投影的全连接层,得到一些patch embedding。在它前面拼接一个class embedding(Xclass)。得到所有的tokens后,将位置编码信息Epos也加进去。
Z0就是整个transformer的输入。
(2)-(3)循环
对于每个transformer block来说,里面都有两个操作:一个是多头自注意力,一个是MLP。在做这两个操作之前,都要先经过layer norm,每一层出来的结果都要再去用一个残差连接
- ZL’就是每一个多头自注意力出来的结果
- ZL就是每一个transformer block整体做完之后出来的结果
(4)L层循环结束之后将ZL(最后一层的输出)的第一个位置上的ZL0,也就是class token所对应的输出当作整体图像的特征,去做最后的分类任务
5 消融实验(附录)
针对特殊的class token还有位置编码,作者还做了详细的消融实验,因为对于Vision Transformer来说,怎么对图片进行预处理以及怎样对图片最后的输出进行后处理是很关键的,因为毕竟中间的模型就是一个标准的Transformer
5.1 class token
对于Transformer来说,如果有一个Transformer模型,进去有n个元素,出来也有n个元素,为什么不能直接在n个输出上做全局平均池化得到一个最后的特征,而非要在前面加上一个class token,最后用class token的输出做分类?
要跟原始的Transformer尽可能地保持一致,所以也使用了class token,因为class token在NLP的分类任务中也有用到(也是当作一个全局的对句子的理解的特征)。本文中的class token是将它当作一个图像的整体特征,将这个token的输出送入MLP(MLP中是用tanh当作非线性的激活函数来做分类的预测)
之前在视觉领域是不需要class token的,比如说有一个残差网络Res50,在最后一个stage出来的是一个14*14的feature map,然后在这个feature map之上其实是做了一个叫做global average pooling全局平均池化的操作,池化以后的特征其实就已经拉直了,就是一个向量了,这个时候就可以把这个向量理解成一个全局的图片特征,然后再拿这个特征去做分类。
通过实验,作者最后的结论是:这两种方式都可以,就是说可以通过全局平均池化得到一个全局特征然后去做分类,也可以用一个class token去做。本文所有的实验都是用class token去做的,主要的目的是跟原始的Transformer尽可能地保持一致(stay as close as possible),作者不想让人觉得某些效果好可能是因为某些trick或者某些针对cv的改动而带来的,就是想证明,一个标准的Transformer照样可以做视觉
两种方法的效果对比如下图所示
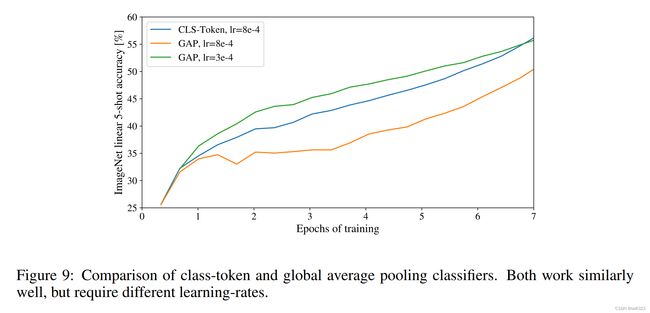
绿线表示全局平均池化,蓝线表示class token。可以发现到最后绿线和蓝线的效果是差不多的,但是作者指出绿线和蓝线所使用的学习率是不一样的,如果直接将蓝线的学习率拿过来使用得到的效果可能如橙线所示,也就是说需要进行好好调参
5.2 位置编码
作者也做了很多的消融实验,主要是三种
- 1d:就是NLP中常用的位置编码,也就是本文从头到尾都在使用的位置编码
- 2d:1d中是把一个图片打成九宫格,用的是1到9的数来表示图像块;2d就是使用11、12、13、21等来表示图像块,这样就跟视觉问题更加贴近,因为它有了整体的结构信息。具体的做法就是,原有的1d的位置编码的维度是d,现在因为横坐标、纵坐标都需要去表示,横坐标有D/2的维度,纵坐标也有D/2的维度,就是说分别有一个D/2的向量去表述横坐标和纵坐标,最后将这两个D/2的向量拼接到一起就得到了一个长度为D的向量,把这个向量叫做2d的位置编码
- relative positional embedding(相对位置编码):在1d的位置编码中,两个patch之间的距离既可以用绝对的距离来表示,又可以用它们之间的相对距离来表示(文中所提到的offset),这样也可以认为是一种表示图像块之间位置信息的方式
但是这个消融实验最后的结果也是:三种表示方法的效果差不多,如下图所示
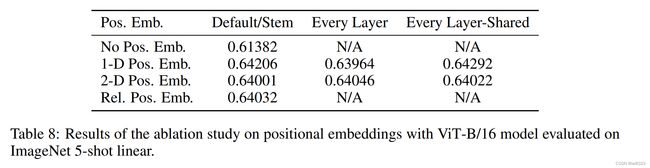
- No Pos表示不加任何的位置编码,效果不太好,但也不算特别差,还能够达到61的效果其实已经相当不错了
- 对比以上三种位置编码的形式发现,所有的performance都是64,没有任何区别
- 对此作者给出了他认为合理的解释,他所做的Vision Transformer是直接在图像块上做的,而不是在原来的像素块上做的,因为图像块很小,14*14,而不是全局的那种224*224,所以在排列组合这种小块或者想要知道这些小块之间相对位置信息的时候还是相对比较容易的,所以使用任意的位置编码都无所谓
通过以上的消融实验可以看出,class token也可以使用全局平均池化替换,最后1d的位置信息编码方式也可以用2d或者相对位置编码去替换,但是为了尽可能对标准的transformer不做太多改动,所以本文中的vision transformer还是使用的是class token和1d的位置信息编码方式
6 模型探讨
归纳偏置
vision transformer相比于CNN而言要少很多图像特有的归纳偏置。
在CNN中,locality(局部性)和translate equivariance(平移等变性)是在模型的每一层中都有体现的,这个先验知识贯穿整个模型的始终。
但是对于ViT来说,只有MLP层是局部而且平移等变性的,但是自注意力层是全局的,这种图片的2d信息ViT基本上没怎么使用。只有刚开始将图片切成patch的时候和加位置编码的时候用到了,除此之外,就再也没有用任何针对视觉问题的归纳偏置了,而且位置编码也是随机初始化的1-D信息,并没有携带任何2d的信息,所有关于图像块之间的距离信息、场景信息等,都需要从头开始学习。这里也是对后面的结果做了一个铺垫:vision transformer没有用太多的归纳偏置,所以说在中小数据集上做预训练的时候效果不如卷积神经网络是可以理解的
Hybrid混合模型试验
作者对此做了实验:不将图片打成patch了,将一整张图输入一个CNN,比如说Res50,最后出来一个14*14的特征图,这个特征图拉直了以后恰好也是196个元素,然后用新的到的196个元素去和全连接层做操作得到新的patch embedding
ViT和混合模型得到的序列的长度都是196,所以后续的操作都是一样的,都是直接输入一个transformer,最后再做分类
更大尺寸上的微调
之前的工作有表明,在微调的时候,使用更大的图片输入尺寸往往模型效果会更好。但是使用一个预训练好的vision transformer,其实是不太好去调整输入尺寸的。如果还是将patch size保持一致,但是图片扩大了,那么序列长度就增加了,提前预训练好的位置编码有可能就没用了。
这个时候位置编码该如何使用?作者发现其实做一个简单的2d的插值就可以了(使用torch官方自带的interpolate函数就完成)。但这只是一个临时的解决方案,如果需要从一个很短的序列变成一个很长的序列时(比如256→512),简单的插值操作会导致最终的效果下降。这也算是vision transformer在微调的时候的一个局限性。
因为使用了图片的位置信息进行插值,所以这块的尺寸改变和抽图像块是vision transformer里唯一用到2d信息的归纳偏置的地方。
7 实验部分
主要是对比了残差网络、vit和它们混合模型的表征学习能力。
为了了解训练好每个模型到底需要多少数据,在不同大小的数据集上做预训练,然后在很多的数据集上做测试。数据集的使用方面主要是用了
- ImageNet的数据集:ImageNet-1k(最常用的有1000个类别、130万张图片)、ImageNet-21k(有21000个类别、1400万张图片)
- JFT数据集:Google自己的数据集(有3亿张图片)
下游任务全部是做的分类,用的也是比较常用的数据集
- CIFAR
- Oxford Pets
- Oxford Flowers
结论:当考虑到预训练的时间代价(预训练的时间长短)的时候,vision transformer表现得非常好,能在大多数数据集上取得最好的结果,同时需要更少的时间进行训练
作者还做了一个自监督的实验,自监督实验的结果虽然没有最好,但是还是可以,还是比较有潜力
- 时隔一年之后,MAE就证明了自监督的方式去训练ViT确实效果很好
7.1 ViT模型变体
三个模型(Base/ Large/ Huge,对应BERT)的参数。其中:
- Layers:Transformer Encoder中重复堆叠Encoder Block的次数
- Hidden Size:对应通过Embedding层后每个token的向量的长度
- MLP size:Hidden Size的四倍
- Heads:多头注意力有几个头。
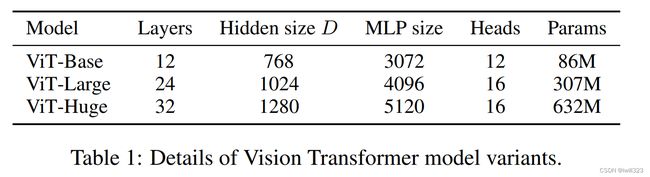
ViTa不光跟transformer本身有关系,还和输入有关系。当patch size大小变化的时候,模型的位置编码就不一样,所以patch size也要考虑在模型的命名里面,vit-l 16表示用的是一个vit large的模型,输入的patch size是16*16。transformer的序列长度是跟patch size成反比的,当模型用了更小的patch size的时候计算起来就会更贵,因为序列长度增加了
7.2 ViT模型以及和CNN对比结果
结果如下。下表是说当它已经在大规模的数据上进行过预训练之后,在左边这一列的数据集上去做fine-tune(微调)的时候得到的表现

上表对比了几个vit的变体和卷积神经网络(bit和noisy student)。和bit做对比的原因是因为bit确实是之前卷积神经网络里做得比较大的,而且也是因为他是作者团队自己本身的工作,所以正好可以拿来对比。和noisy student做对比是因为它是ImageNet之前表现最好的方法,它所采用的方法是用pseudo-label(伪标签)去进行self training,也取得了很好的效果
从上表中可以看出,vit huge用比较小的patch 14*14能取得所有数据集上最好的结果。
但是这些数值都太接近了,仅仅相差零点几个点或者一点几个点,所以作者就得从另外一个角度来体现vit的优点:因为训练起来更便宜
作者所说的更便宜是指最大的vit huge这个模型也只需要训练2500天tpuv3天数,而bit用了9900天,noisy student用了一万多天,所以从这个角度上来说,vit不仅比之前bit和noisy student要训练的快,而且效果要好,所以通过这两点可以得出vit真的是比卷积神经网络要好的结论
7.3 ViT预训练需要多大的数据规模?(重要论证)
下图展示了在不同大小的数据集(x轴,ImageNet是1.2M,而ImageNet-21k是14M,JFT是300M)上预训练后,BiTt和VIT在ImageNet的微调效果如何。
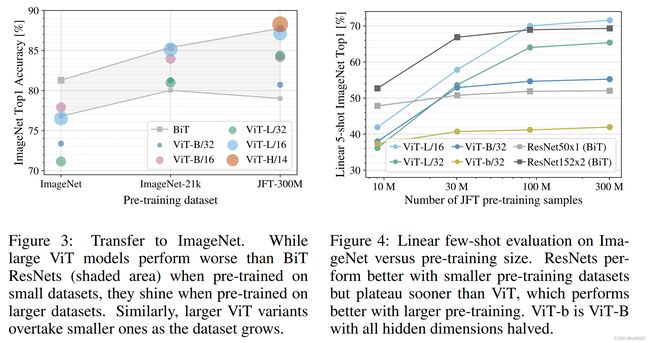
图中灰色区域表示BiT,上下两条界线分别表示使用ResNet50和ResNet152结构;五个彩色的点就是不同配置的ViT。
- 在最小的ImageNet上做预训练时,vision transformer基本上所有的点都在灰色区域的下面,这说明vision transformer在中小型数据集上做预训练的时候的效果是远不如残差网络的,原因就是因为vision transformer没有使用先验知识(归纳偏置),所以它需要更大的数据去让网络学得更好
- 在ImageNet-21k上做预训练的时候,vision transformer基本上所有的点都落在灰色区域内,说明vision transformer和resnet已经是差不多了
- 只有当用特别大的数据集JFT-300M时,vision transformer是比bit对应的res152还要高的
结论:如果想用ViT,那么得至少是在ImageNet-21k这种规模的数据集上预训练(数据量14M),否则还不如用CNN。当已经拥有了比ImageNet-21k更大的数据集的时候,用vision transformer就能得到更好的结果
右图是在JFT数据集上分别采样不同规模子集的实验结果,这里ViT用作特征提取器而不是微调。(去除了训练时的强约束,比如说dropout、weight decay、label smoothing;而且不同规模的数据集来自同一分布,更能看出模型本身的特性)
作者在图三中要用vision transformer跟resnet做比较,所以在训练的时候用了一些强约束(比如说dropout、weight decay、label smoothing),所以就不太好分析vision transformer模型本身的特性,所以在图四中做了linear few-shot evaluation,在拿到预训练的模型之后,直接把它当成一个特征提取器,不去fine-tune,而是直接拿这些特征做logistic regression。图示中标出了5-shot,就是在ImageNet上做linear evaluation的时候,每一类随机选取了5个sample,所以这个evaluation做起来是很快的,作者用这种方式做了大量的消融实验
- 图四中横轴表示预训练数据集的大小,在JFT数据集上分别采样不同规模子集,因为所有的数据都是从一个数据集里面得来的,就没有那么大的distribution gap,这样比较起来模型的效果就更加能体现出模型本身的特质
- 图四中的结果其实跟图三差不多,当用很小的预训练的数据集的时候vision transformer是完全比不过resnet的。本文的解释是因为缺少归纳偏置和约束方法(weight decay、label smoothing等),所以就导致在10M数据集的情况下vision transformer容易过拟合,导致最后学到的特征不适合做其他任务
- 随着预训练数据集的增大,vision transformer的稳健性就提升上来了。但是这里的提升也不是很明显,作者在最后一段写了如何用vision transformer去做这种小样本的学习,是一个非常有前途的方向
下图再次论证作者观点——VIT训练更便宜:
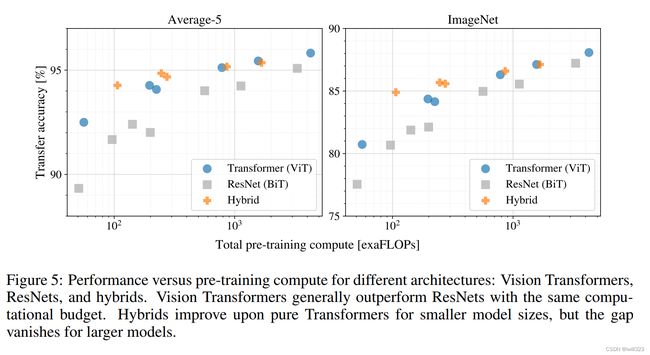
左图的Average-5就是他在五个数据集(ImageNet real、 pets、 flowers、 CIFAR-10、 CIFAR-100)上做了验证后的平均结果。右图是ImageNet 上的验证结果。
图中大大小小的点就是各种配置下大小不一样的vision transformer的变体,或者说是resnet的变体。所有模型都是在JFT-300M上预训练好的模型。作者这样训练的目的不想让模型的能力受限于数据集的大小,所以说所有的模型都在最大的数据集上做预训练
7.4 结论
- 同等复杂度下(沿着竖直方向看), ViT比BiT效果要好,这也说明ViT训练比CNN更便宜
- 小规模的模型上,Hybrid混合模型比其它两者效果都要好。按道理来讲,混合模型都应该是吸收了双方的优点:既不需要太多的数据去做预训练,同时又能达到跟vision transformer一样的效果
- 随着模型规模增大,Hybrid精度慢慢的跟ViT差不多了,甚至还不如在同等计算条件下的ViT。为什么卷积神经网络抽出来的特征没有帮助ViT更好的去学习?这里作者对此也没有做过多的解释。
- 随着规模的增大,ViT和BiT都没有性能饱和的迹象。但是从这个图中来看的话,其实卷积神经网络的效果也没有饱和
8 ViT可视化
作者也做了一些可视化,希望通过这些可视化能够分析一下vit内部的表征。
patch embedding可视化

上图展示了E(第一层linear projection layer)是如何对图片像素进行embedding。只展示了开头28个token的可视化结果,可以看到结果类似CNN,都是提取的一些颜色和纹理这样的底层特征,可以用来描述每一个图像块的底层的结构。
position embedding可视化

上图中间部分展示了不同patch之间,位置编码的cos相似性,越接近1 表示越相似。如果是同一个坐标,自己和自己相比,相似性肯定是最高的。可以看到黄色(最相似)出现位置和patch本身所处位置对应,并且越靠近“主角”的点越黄,说明学到的位置编码是可以表示一些距离信息的。同时它还学习到了一些行和列的规则,每一个图像块都是同行同列的相似性更高,也就意味着虽然它是一个1d的位置编码,但是它已经学到了2d图像的距离概念,这也可以解释为什么在换成2d的位置编码以后,并没有得到效果上的提升,是因为1d已经够用了
自注意力是否起作用了
为了了解ViT如何利用self-attention来整合图像中的信息,我们分析了不同层的Mean attention distance

上图展示的是vit large 16这个模型,有24层,所以横坐标所表示的网络深度就是从0到24,图中五颜六色的点就是每一层的transformer block中多头自注意力的头,对于vit large来说一共有16个头,所以每一列其实有16个点。纵轴所表示的是mean attention distance平均注意力的距离。图上两个点是平均注意力距离是整两个点像素之间的距离乘以他们之间的attention weights,反映了模型能不能注意到两个很远的像素。
规律:头几层中,有的头的距离还是挺近的,能达到20个像素,但是有的能达到120个像素,证明了在网络最底层,自注意力注意到全局上的信息,而不是像卷神经网络一样,刚开始第一层的receptive field(感受野)非常小,只能看到附近的一些像素。随着网络越来越深,网络学到的特征也会变得越来越高级,越来越具有语义信息。在网络的后半部分,模型的自注意力的距离已经非常远了,也就是说已经学到了带有语义性的概念,而不是靠邻近的像素点去进行判断
We find that some heads attend to most of the image already in the lowest layers, showing that the ability to integrate information globally is indeed used by the model. Other attention heads have consistently small attention distances in the low layers. This highly localized attention is less pronounced in hybrid models that apply a ResNet before the Transformer (Figure 7, right), suggesting that it may serve a similar function as early convolutional layers in CNNs. Further, the attention distance increases with network depth.
out token输出

上图对上面attention的结果又进行了一次验证,用网络中最后一层的out token所作的图。从图中可以发现,如果用输出的token的自注意力折射回原来的输入图片,可以发现模型确实是学习到了这些概念。因为输出的token是融合了所有的信息(全局的特征),模型已经可以关注到与最后分类有关的图像区域
Globally, we find that the model attends to image regions that are semantically relevant for classification (Figure 6).
9 自监督训练
这部分放在正文而不是附录中,是因为作者认为,在NLP领域Transformer模型确实起到了很大的推动作用,但另外一个真正让Transformer火起来的原因其实是大规模的自监督训练,二者缺一不可。
NLP中自监督方式是MLM任务或者Next word prediction。本文模仿的是BERT,所以作者考虑构造专属于ViT的目标函数Mask patch prediction。具体来说,给定一张图片,将它打成很多patch,然后将某些patch随机抹掉,然后通过这个模型将这些patch重建出来。
但是最后ViT-Base/16在ImageNet只能达到80的左右的准确率,虽然相对于从头来训练vision transformer已经提高了两个点,但是和最好的有监督方式训练相比,还是差了四个点。所以作者将跟对比学习的结果当作是未来的工作。
对比学习是所有自监督学习中表现最好的,紧接着出现的ViT MoCo v3和DINO就是在ViT的基础上使用了对比学习。
10 总结
从内容上来说,可以从各个角度来进行分析、提高或者推广vision transformer
- 如果从任务角度来说,vision transformer只是做了分类,所以还可以拿他去做检测、分割甚至别的领域的任务
- 如果从改变结构的角度来讲,可以去改变刚开始的tokenization,也可以改中间的transformer block,后来就已经有人将自注意力换成了MLP,而且还是可以工作得很好(比如mataformer,将自注意力直接换成了池化操作,也能在视觉领域取得很好的效果),所以在模型的改进上也大有可为
- 如果从目标函数来讲,可以继续采用有监督,也可以尝试很多不同的自监督训练的方式
最重要的是vit打破了NLP和CV之间的鸿沟,可以用它去做视频、音频,甚至还可以去做一些基于touch的信号,也就是说各种modality的信号都可以拿来使用