【20210914】【机器/深度学习】详解鸢尾花卉数据集,并以此为例介绍决策树模型的保存与调用
一、鸢尾花卉数据集(Iris数据集)
1. 数据集介绍
Iris数据集是一种多重变量分析的数据集,数据集包含150个数据样本,分为3类,每类有50个数据,每个数据包含4个属性/特征,分别是:花萼长度、花萼宽度、花瓣长度、花瓣宽度,标签有3个,分别是:Setosa, Versicolour, Virginca。
(参考:IRIS (IRIS数据集))
2. 数据集调用和可视化
from sklearn.datasets import load_iris
from matplotlib import pyplot as plt
''' 导入数据集 '''
iris = load_iris()
fea_names = iris.feature_names # 数据集特征名称
label_names = iris.target_names # 数据集标签名称
''' 数据及可视化 '''
x_sepal = x[:, :2] # 萼片长、宽特征
plt.scatter(x_sepal[:, 0], x_sepal[:, 1], c=y, cmap=plt.cm.gnuplot)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('Sepals Samples')
plt.show()
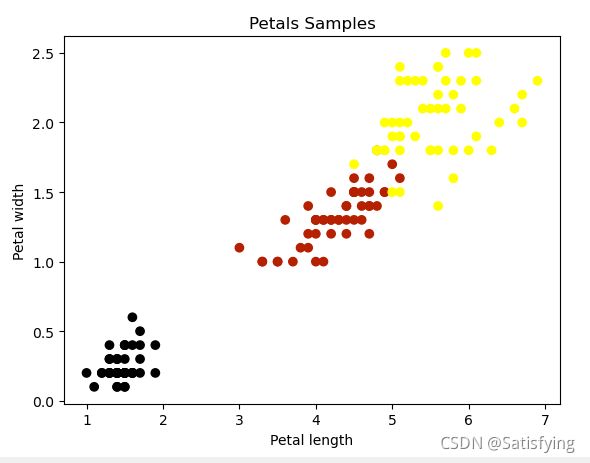
x_petal = x[:, 2:4] # 花瓣长、宽特征
plt.scatter(x_petal[:, 0], x_petal[:, 1], c=y, cmap=plt.cm.gnuplot)
plt.xlabel('Petal length')
plt.ylabel('Petal width')
plt.title('Petals Samples')
plt.show()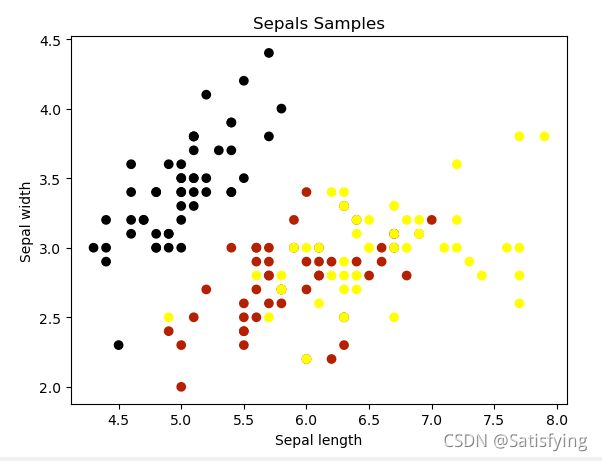
二、几种分类算法
1. K-NN(K-近邻算法)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(x, y)
y_pre_knn = knn.predict(x)2. LR(逻辑回归)
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
logreg.fit(x, y)
y_pre_lr = logreg.predict(x)3. CART决策树
from sklearn import tree
import pydotplus
model = tree.DecisionTreeClassifier(criterion='gini') # 选择模型并设置参数
model.fit(x, y) # 训练数据
y_pre_cart = model.predict(x)4. lightGBM
''' x_train, y_train, x_test, y_test 分别为训练集特征、标签和测试集特征、标签 '''
import lightgbm as lgb
dataset_train = lgb.Dataset(x_train, y_train)
dataset_test = lgb.Dataset(x_test, y_test)
params = {
'learning rate': 0.1,
'lambda_l1': 0,
'lambda_l2': 0,
'max_depth': 4,
'objective': 'multiclass',
'num_class': 3,
'min_data_in_leaf': 4
} # 设置模型参数
gbm = lgb.train(params, dataset_train, valid_sets=dataset_test) # 模型训练
y_pre_lgb = gbm.predict(x) # 模型预测三、Cart决策树模型的保存与调用
from sklearn import tree
import pydotplus
with open(r'D:\Program Files (x86)\PyCharm\PyCharm Community Edition 2021.1.1\My project/test/tree.dot', 'w') as f:
f = tree.export_graphviz(model, out_file=f) # 将训练的模型保存
# 将模型可视化并保存
dot_data = tree.export_graphviz(model, out_file=None, feature_names=fea_names, class_names=labels_names, filled=True, rounded=True, special_characters=True) # 设置图像参数
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf(r'D:\Program Files (x86)\PyCharm\PyCharm Community Edition 2021.1.1\My project/test/tree.pdf')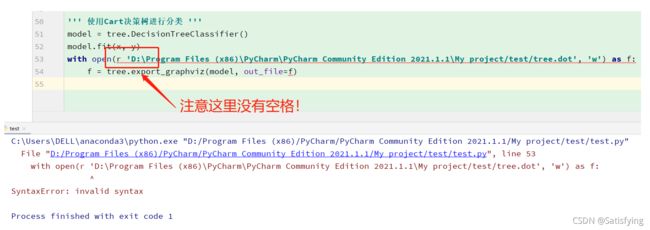
(参考:scikit-learn库 决策树模型结果运用)
四、补充Tips
1. 使用 scikit-learn 进行模型匹配一般有四个步骤:(以 KNN 算法为例)
第一步:载入要使用的模型类
from sklearn.neighbors import KNeighborsClassifier第二步:实例化分类器
knn = KNeighborsClassifier(n_neighbors=2)第三步:用数据来拟合模型(进行模型训练)
knn.fit(x, y)第四步:对新的观测值进行预测
y_pre = knn.predict(x)(参考:从iris数据集入门scikit-learn)
2. 评估 CART 决策树特征重要性
''' 基于 CART 决策树模型 model 输出特征重要性 '''
print(model.feature_importances_)3. 评估 lightGBM 模型特征重要性 并 保存
''' 1. 基于 lightGBM 模型 gbm 输出特征重要性 '''
import matplotlib.pyplot as plt
plt.figure()
lgb.plot_importance(gbm, max_num_features=4)
plt.title('Feature Importances')
plt.show()
''' 2. 基于 lightGBM 模型 gbm 输出特征重要性 '''
booster = gbm.booster_
importance = booster.feature_importance(importance_type='split')
feature_name = booster.feature_name()
feature_importance = pd.DataFrame({'feature_name': feature_name, 'importance':importance})
feature_importance.to_csv('feature_importance.csv', index=False)(参考:【机器学习笔记】使用lightgbm画并保存Feature Importance)