【PaddleNLP 基于深度学习的自然语言处理】第三次作业--必修|快递单信息识别
基本情况
1.数据 train_ds, test_ds = paddlenlp.datasets.load_dataset(“msra_ner”, splits=[“train”, “test”])
2.模型 bert-base-multilingual-uncased
model = BertForTokenClassification.from_pretrained( 'bert-base-multilingual-uncased', num_classes=label_num)
if paddle.distributed.get_world_size() > 1:
model = paddle.DataParallel(model)
作业
更换数据集MSRA和ERNIE-Gram或BERT等预训练模型。
- 数据集:
train_ds, test_ds = load_dataset("msra_ner", splits=["train", "test"]) - 模型:
将from paddlenlp.transformers import ErnieTokenizer, ErnieForTokenClassification换成相应的模型。
使用PaddleNLP语义预训练模型ERNIE完成快递单信息抽取
注意
本项目代码需要使用GPU环境来运行:

命名实体识别是NLP中一项非常基础的任务,是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具。命名实体识别的准确度,决定了下游任务的效果,是NLP中的一个基础问题。在NER任务提供了两种解决方案,一类LSTM/GRU + CRF,通过RNN类的模型来抽取底层文本的信息,而CRF(条件随机场)模型来学习底层Token之间的联系;另外一类是通过预训练模型,例如ERNIE,BERT模型,直接来预测Token的标签信息。
本项目将演示如何使用PaddleNLP语义预训练模型ERNIE完成从快递单中抽取姓名、电话、省、市、区、详细地址等内容,形成结构化信息。辅助物流行业从业者进行有效信息的提取,从而降低客户填单的成本。
在2017年之前,工业界和学术界对文本处理依赖于序列模型Recurrent Neural Network (RNN).
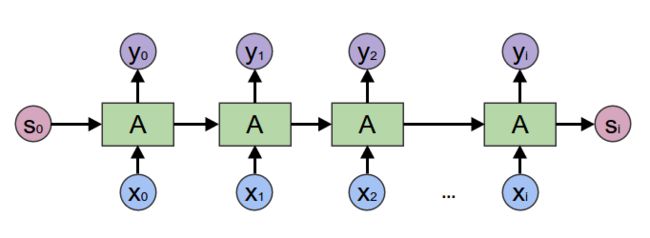
基于BiGRU+CRF的快递单信息抽取项目介绍了如何使用序列模型完成快递单信息抽取任务。
近年来随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。
近年来,大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的不断提高,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。

本示例展示了以ERNIE(Enhanced Representation through Knowledge Integration)为代表的预训练模型如何Finetune完成序列标注任务。
记得给PaddleNLP点个小小的Star⭐
开源不易,希望大家多多支持~
GitHub地址:https://github.com/PaddlePaddle/PaddleNLP
![]()
AI Studio平台后续会默认安装PaddleNLP,在此之前可使用如下命令安装。
!pip install --upgrade paddlenlp
Looking in indexes: https://mirror.baidu.com/pypi/simple/
Requirement already up-to-date: paddlenlp in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (2.0.2)
Requirement already satisfied, skipping upgrade: visualdl in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.1.1)
Requirement already satisfied, skipping upgrade: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (4.1.0)
Requirement already satisfied, skipping upgrade: h5py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.9.0)
Requirement already satisfied, skipping upgrade: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.4.4)
Requirement already satisfied, skipping upgrade: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (1.2.2)
Requirement already satisfied, skipping upgrade: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.42.1)
Requirement already satisfied, skipping upgrade: multiprocess in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.70.11.1)
Requirement already satisfied, skipping upgrade: numpy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.20.3)
Requirement already satisfied, skipping upgrade: shellcheck-py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (0.7.1.1)
Requirement already satisfied, skipping upgrade: Pillow>=7.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (7.1.2)
Requirement already satisfied, skipping upgrade: bce-python-sdk in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (0.8.53)
Requirement already satisfied, skipping upgrade: requests in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (2.22.0)
Requirement already satisfied, skipping upgrade: six>=1.14.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.15.0)
Requirement already satisfied, skipping upgrade: flake8>=3.7.9 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (3.8.2)
Requirement already satisfied, skipping upgrade: protobuf>=3.11.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (3.14.0)
Requirement already satisfied, skipping upgrade: Flask-Babel>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.0.0)
Requirement already satisfied, skipping upgrade: pre-commit in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.21.0)
Requirement already satisfied, skipping upgrade: flask>=1.1.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.1.1)
Requirement already satisfied, skipping upgrade: scikit-learn>=0.21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp) (0.24.2)
Requirement already satisfied, skipping upgrade: dill>=0.3.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from multiprocess->paddlenlp) (0.3.3)
Requirement already satisfied, skipping upgrade: pycryptodome>=3.8.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl->paddlenlp) (3.9.9)
Requirement already satisfied, skipping upgrade: future>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl->paddlenlp) (0.18.0)
Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (2.8)
Requirement already satisfied, skipping upgrade: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (1.25.6)
Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (2019.9.11)
Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (3.0.4)
Requirement already satisfied, skipping upgrade: importlib-metadata; python_version < "3.8" in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (0.23)
Requirement already satisfied, skipping upgrade: pyflakes<2.3.0,>=2.2.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (2.2.0)
Requirement already satisfied, skipping upgrade: pycodestyle<2.7.0,>=2.6.0a1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (2.6.0)
Requirement already satisfied, skipping upgrade: mccabe<0.7.0,>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (0.6.1)
Requirement already satisfied, skipping upgrade: Babel>=2.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2.8.0)
Requirement already satisfied, skipping upgrade: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2019.3)
Requirement already satisfied, skipping upgrade: Jinja2>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2.10.1)
Requirement already satisfied, skipping upgrade: identify>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.4.10)
Requirement already satisfied, skipping upgrade: cfgv>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (2.0.1)
Requirement already satisfied, skipping upgrade: pyyaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (5.1.2)
Requirement already satisfied, skipping upgrade: nodeenv>=0.11.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.3.4)
Requirement already satisfied, skipping upgrade: aspy.yaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.3.0)
Requirement already satisfied, skipping upgrade: virtualenv>=15.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (16.7.9)
Requirement already satisfied, skipping upgrade: toml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (0.10.0)
Requirement already satisfied, skipping upgrade: click>=5.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (7.0)
Requirement already satisfied, skipping upgrade: Werkzeug>=0.15 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (0.16.0)
Requirement already satisfied, skipping upgrade: itsdangerous>=0.24 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (1.1.0)
Requirement already satisfied, skipping upgrade: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (2.1.0)
Requirement already satisfied, skipping upgrade: scipy>=0.19.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (1.6.3)
Requirement already satisfied, skipping upgrade: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (0.14.1)
Requirement already satisfied, skipping upgrade: zipp>=0.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from importlib-metadata; python_version < "3.8"->flake8>=3.7.9->visualdl->paddlenlp) (0.6.0)
Requirement already satisfied, skipping upgrade: MarkupSafe>=0.23 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Jinja2>=2.5->Flask-Babel>=1.0.0->visualdl->paddlenlp) (1.1.1)
Requirement already satisfied, skipping upgrade: more-itertools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from zipp>=0.5->importlib-metadata; python_version < "3.8"->flake8>=3.7.9->visualdl->paddlenlp) (7.2.0)
from functools import partial
import paddle
from paddlenlp.datasets import MapDataset
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.transformers import ErnieTokenizer, ErnieForTokenClassification
from paddlenlp.metrics import ChunkEvaluator
from utils import convert_example, evaluate, predict, load_dict
import paddlenlp
MSRA-NER 数据集由微软亚研院发布,其目标是识别文本中具有特定意义的实体,主要包括人名、地名、机构名等。
加载自定义数据集
推荐使用MapDataset()自定义数据集。
# Create dataset, tokenizer and dataloader.
train_ds, test_ds = paddlenlp.datasets.load_dataset("msra_ner", splits=["train", "test"])
from paddlenlp.transformers import BertForTokenClassification, BertTokenizer
from paddlenlp.data import Stack, Tuple, Pad, Dict
from paddle.io import DataLoader
def tokenize_and_align_labels(example, tokenizer, no_entity_id,
max_seq_len=512):
labels = example['labels']
example = example['tokens']
tokenized_input = tokenizer(
example,
return_length=True,
is_split_into_words=True,
max_seq_len=max_seq_len)
# -2 for [CLS] and [SEP]
if len(tokenized_input['input_ids']) - 2 < len(labels):
labels = labels[:len(tokenized_input['input_ids']) - 2]
tokenized_input['labels'] = [no_entity_id] + labels + [no_entity_id]
tokenized_input['labels'] += [no_entity_id] * (
len(tokenized_input['input_ids']) - len(tokenized_input['labels']))
return tokenized_input
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-uncased')
label_list = train_ds.label_list
label_num = len(label_list)
no_entity_id = label_num - 1
trans_func = partial(
tokenize_and_align_labels,
tokenizer=tokenizer,
no_entity_id=no_entity_id,
max_seq_len=128)
train_ds = train_ds.map(trans_func)
[2021-06-11 01:25:22,321] [ INFO] - Found /home/aistudio/.paddlenlp/models/bert-base-multilingual-uncased/bert-base-multilingual-uncased-vocab.txt
每条数据包含一句文本和这个文本中每个汉字以及数字对应的label标签。
之后,还需要对输入句子进行数据处理,如切词,映射词表id等。
数据处理
预训练模型ERNIE对中文数据的处理是以字为单位。PaddleNLP对于各种预训练模型已经内置了相应的tokenizer。指定想要使用的模型名字即可加载对应的tokenizer。
tokenizer作用为将原始输入文本转化成模型model可以接受的输入数据形式。


数据读入
使用paddle.io.DataLoader接口多线程异步加载数据。
ignore_label = -100
batchify_fn = lambda samples, fn=Dict({
'input_ids': Pad(axis=0, pad_val=tokenizer.pad_token_id, dtype='int32'), # input
'token_type_ids': Pad(axis=0, pad_val=tokenizer.pad_token_type_id, dtype='int32'), # segment
'seq_len': Stack(dtype='int64'), # seq_len
'labels': Pad(axis=0, pad_val=ignore_label, dtype='int64') # label
}): fn(samples)
train_batch_sampler = paddle.io.DistributedBatchSampler(
train_ds, batch_size=32, shuffle=True, drop_last=True)
train_data_loader = DataLoader(
dataset=train_ds,
collate_fn=batchify_fn,
num_workers=0,
batch_sampler=train_batch_sampler,
return_list=True)
test_ds = test_ds.map(trans_func)
test_data_loader = DataLoader(
dataset=test_ds,
collate_fn=batchify_fn,
num_workers=0,
batch_size=32,
return_list=True)
PaddleNLP一键加载预训练模型
快递单信息抽取本质是一个序列标注任务,PaddleNLP对于各种预训练模型已经内置了对于下游任务文本分类Fine-tune网络。以下教程以ERNIE为预训练模型完成序列标注任务。
paddlenlp.transformers.ErnieForTokenClassification()一行代码即可加载预训练模型ERNIE用于序列标注任务的fine-tune网络。其在ERNIE模型后拼接上一个全连接网络进行分类。
paddlenlp.transformers.ErnieForTokenClassification.from_pretrained()方法只需指定想要使用的模型名称和文本分类的类别数即可完成定义模型网络。
# Define the model netword and its loss
# model = ErnieForTokenClassification.from_pretrained("ernie-1.0", num_classes=len(label_vocab))
model = BertForTokenClassification.from_pretrained( 'bert-base-multilingual-uncased', num_classes=label_num)
if paddle.distributed.get_world_size() > 1:
model = paddle.DataParallel(model)
[2021-06-11 01:25:22,432] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/bert-base-multilingual-uncased/bert-base-multilingual-uncased.pdparams
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
PaddleNLP不仅支持ERNIE预训练模型,还支持BERT、RoBERTa、Electra等预训练模型。
下表汇总了目前PaddleNLP支持的各类预训练模型。您可以使用PaddleNLP提供的模型,完成文本分类、序列标注、问答等任务。同时我们提供了众多预训练模型的参数权重供用户使用,其中包含了二十多种中文语言模型的预训练权重。中文的预训练模型有bert-base-chinese, bert-wwm-chinese, bert-wwm-ext-chinese, ernie-1.0, ernie-tiny, gpt2-base-cn, roberta-wwm-ext, roberta-wwm-ext-large, rbt3, rbtl3, chinese-electra-base, chinese-electra-small, chinese-xlnet-base, chinese-xlnet-mid, chinese-xlnet-large, unified_transformer-12L-cn, unified_transformer-12L-cn-luge等。
更多预训练模型参考:PaddleNLP Transformer API。
更多预训练模型fine-tune下游任务使用方法,请参考:examples。
设置Fine-Tune优化策略,模型配置
适用于ERNIE/BERT这类Transformer模型的迁移优化学习率策略为warmup的动态学习率。

模型训练与评估
模型训练的过程通常有以下步骤:
- 从dataloader中取出一个batch data
- 将batch data喂给model,做前向计算
- 将前向计算结果传给损失函数,计算loss。将前向计算结果传给评价方法,计算评价指标。
- loss反向回传,更新梯度。重复以上步骤。
每训练一个epoch时,程序将会评估一次,评估当前模型训练的效果。
metric = ChunkEvaluator(label_list=label_list)
loss_fn = paddle.nn.loss.CrossEntropyLoss(ignore_index=ignore_label)
optimizer = paddle.optimizer.AdamW(learning_rate=2e-5, parameters=model.parameters())
step = 0
for epoch in range(1):
for idx, (input_ids, token_type_ids, length, labels) in enumerate(train_data_loader):
logits = model(input_ids, token_type_ids)
loss = paddle.mean(loss_fn(logits, labels))
loss.backward()
optimizer.step()
optimizer.clear_grad()
step += 1
print("epoch:%d - step:%d - loss: %f" % (epoch, step, loss))
# evaluate(model, metric, dev_data_loader)
paddle.save(model.state_dict(),
'./ernie_result/model_%d.pdparams' % step)
# model.save_pretrained('./checkpoint')
# tokenizer.save_pretrained('./checkpoint')
epoch:0 - step:1406 - loss: 0.010329
模型预测
训练保存好的模型,即可用于预测。如以下示例代码自定义预测数据,调用predict()函数即可一键预测。
进一步使用CRF
PaddleNLP提供了CRF Layer,它能够学习label之间的关系,能够帮助模型更好地学习、预测序列标注任务。
我们在PaddleNLP仓库中提供了示例,您可以参照示例代码使用Ernie-CRF结构完成快递单信息抽取任务。
加入交流群,一起学习吧
现在就加入课程QQ交流群,一起交流NLP技术吧!
