从jieba分词到BERT-wwm——中文自然语言处理(NLP)基础分享系列(8)
优化代码 & 谈谈『词向量』
让代码更好看一些
在看torchtext 参考手册文档的时候,发现之前代码里手工编写的功能(如根据空格的分词、索引序列的截断和补齐等)已有封装函数实现,引用它的成品函数会让代码简洁一些。
另外将读取文件、构造语料库等前续步骤,也合并到myDataset 类的**init** 方法里。
优化后新的代码如下:
import numpy as np
import pandas as pd
import pickle
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchtext.vocab import build_vocab_from_iterator # 从语料迭代器构建词典
from torchtext.data.functional import simple_space_split # 语料库文本按空格分词,返回一个迭代器
from torchtext.data.functional import numericalize_tokens_from_iterator # 从文本序列迭代器中返回数字索引序列
from torchtext.functional import truncate # 索引序列按最大定长截断
from torchtext.functional import to_tensor # 索引序列按最大定长补齐(padding),并转为张量(tensor)
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
MAX_LEN = 20
只保留唯一1个自定义函数,用来处理训练数据中的label字段。
label_to_index = { 'unrelated' : 0 , 'agreed' : 1 , 'disagreed' : 2 }
label_pipeline = lambda x : label_to_index [ x ]
# 自定义一个DataSet 对输入数据进行预处理
class myDataset(Dataset):
def __init__(self, picked_file , max_len=20, transform=None):
super().__init__()
pkl_file_rb = open(picked_file, 'rb')
train =pickle.load(pkl_file_rb)
corpus = pd.concat([train.title1_tokenized, train.title2_tokenized])
corpus = [c for c in corpus]
vocab = build_vocab_from_iterator(simple_space_split(corpus), min_freq=2, specials=["" ])
# 在语料库中出现2次及以上的词汇才纳入词典,减小词典规模
vocab.set_default_index(-1) # 对于词典外的生词,改用-1作为index
self.vocab_size = vocab.__len__() # 词典大小规模
y_train = train.label.apply(label_pipeline)
tensor_x = {}
for i in range(2):
x = train.title1_tokenized if i==0 else train.title2_tokenized
tmp_x = []
ids_iter_x = numericalize_tokens_from_iterator(vocab,simple_space_split([c for c in x]))
for ids in ids_iter_x:
tmp_x.append( truncate([num for num in ids],MAX_LEN ))
tensor_x[i] = to_tensor(tmp_x, padding_value=0)
tensor_x = torch.stack([tensor_x[0], tensor_x[1]], 1)
self.x = tensor_x
self.y = torch.from_numpy(np.asarray(y_train.values))
self.transform = transform
def __len__(self):
return len(self.y) # 数据集长度
def __getitem__(self, index):
x = self.x[index] # tensor类型
y = self.y[index]
if self.transform is not None:
x = self.transform(x) # 对输入进行某些变换
return x, y
def get_vocab_size(self):
return self.vocab_size # 词典规模
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_data = myDataset(r'./save_file',max_len=MAX_LEN)
vocab_size = train_data.get_vocab_size()
dataloader = DataLoader(train_data, batch_size=8, shuffle=False)
for x,y in dataloader:
print(x,y)
print("*"*80)
print(x.shape,y.shape)
break
tensor([[[ 218, 1269, 32, 1178, 5971, 24, 488, 2875, 116, 5568,
4, 1847, 2, 13, 0, 0, 0, 0, 0, 0],
[ 150, 8, 12895, 6168, 6345, 529, 44, 64, 740, 12,
488, 286, 13213, 0, 0, 0, 0, 0, 0, 0]],
[[ 4, 10, 47, 677, 2561, 4, 165, 34, 17, 47,
5153, 62, 15, 677, 4509, 3208, 23, 284, 1185, 0],
[ 677, 3208, 1141, 284, 1185, 677, 23975, 8, 784, 4515,
16, 12858, 0, 0, 0, 0, 0, 0, 0, 0]],
[[ 4, 10, 47, 677, 2561, 4, 165, 34, 17, 47,
5153, 62, 15, 677, 4509, 3208, 23, 284, 1185, 0],
[ 3208, 1141, 284, 1185, 677, 390, 22, 953, 9816, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
[[ 4, 10, 47, 677, 2561, 4, 165, 34, 17, 47,
5153, 62, 15, 677, 4509, 3208, 23, 284, 1185, 0],
[ 3299, 677, 3208, 1141, 284, 1185, 677, 23975, 8, 22,
953, 45212, 120, 0, 0, 0, 0, 0, 0, 0]],
[[ 31, 319, 3373, 3057, 1, 94, 97, 3373, 3057, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 7, 2, 208, 15, 14291, 174, 50, 1627, 319, 122,
3373, 3057, 0, 0, 0, 0, 0, 0, 0, 0]],
[[ 4, 10, 47, 677, 2561, 4, 165, 34, 17, 47,
5153, 62, 15, 677, 4509, 3208, 23, 284, 1185, 0],
[ 677, 3208, 1141, 284, 1185, 23975, 8, 381, 284, 242,
4515, 1670, 12858, 0, 0, 0, 0, 0, 0, 0]],
[[ 7, 2220, 1, 2071, 7, 18165, 2188, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 2220, 78, 20, 101, 125, 7, 46, 1552, 641, 7,
3055, 4705, 0, 0, 0, 0, 0, 0, 0, 0]],
[[ 4, 10, 47, 677, 2561, 4, 165, 34, 17, 47,
5153, 62, 15, 677, 4509, 3208, 23, 284, 1185, 0],
[ 677, 3208, 1141, 284, 1185, 8, 381, 284, 242, 4515,
1670, 12858, 0, 0, 0, 0, 0, 0, 0, 0]]]) tensor([0, 0, 0, 0, 1, 0, 0, 0])
********************************************************************************
torch.Size([8, 2, 20]) torch.Size([8])
我们得到了与上回同样的数据预处理结果。
上面显示的torch.Size([8, 2, 20]) 是目前一批(8条数据)新闻标题A和B 经过数字化转换后的张量(tensor)结构。对于tensor 这个概念,在之后的深度学习建模中会经常提及,可以理解为多维数组。
这里的**[8, 2, 20]** 中,8是分批batch的大小,2代表A和B两个文档,20是每个文档中包含的词汇个数(经过截断和补齐后,已经变成等长度的)。
而这个多维数组中最里面存储的数据,则是每个词汇在词典中的index顺序号。
我们设想一下,直接把这个数据扔给模型去学习,是不是好呢?
显然不行,因为index 仅代表词典序,数字的大小不代表词之间语义的差别。
那么,如何才能表征出词所具有的语义差别呢?这便引出了「词向量」的概念。
谈谈『词向量』
要让深度学习模型能够更好的「理解」标题序列内的词汇,我们要将它们表示成向量的形式,而不是一个单纯数字。
所以现在的问题变成:
「要怎么将一个词汇表示成一个N 维向量?」
为了便于演示和理解,我们把N设定为2,这样可以在平面图中示例:
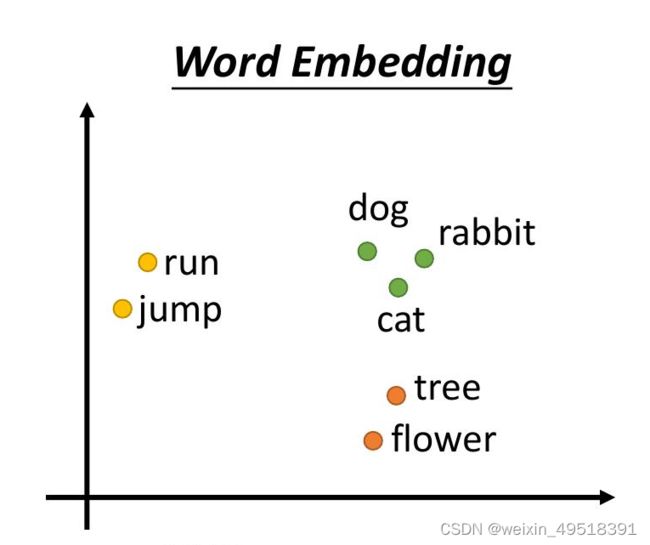
在这个2 维空间里头,我们可以发现一个好的词向量表示有2 个特性:
• 距离有意义:「dog」与意思相近的词汇「cat」距离接近,而与较不相关的「flower」距离较远
• 维度有意义:仔细观察,我们发现横轴可以解释为不同的词性(动词 VS 名词);纵轴可以解释为与运动相关程度
如果我们能把语料库里头的每个词汇都表示成像这样有意义的词向量,模型就能帮我们找到潜藏在大量词汇中的语义关系,并进一步改善NLP 任务的精准度。
大部分的情况我们并不需要自己手动设定每个词汇的词向量。我们可以随机初始化所有词向量,并利用平常训练模型的反向传播算法(Backpropagation),自动学到一组适合当前NLP 任务的理想的词向量。这种技术也被称之为词嵌入(Word Embedding)。
在PyTorch 中,可以使用torch.nn.Embedding 层来帮我们做到这件事情:
for x,y in dataloader:
embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=4,\
padding_idx=0, max_norm=True)
print(embedding(x))
print("*"*80)
print(embedding(x).shape)
break
tensor([[[[ 0.3216, -0.0349, -0.8415, 0.4328],
[-0.2446, -0.7660, -0.1314, 0.5798],
[-0.5807, -0.4590, -0.2667, 0.2735],
...,
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000]],
[[-0.0856, 0.6362, -0.1089, -0.7590],
[ 0.2191, -0.3605, 0.6859, 0.5929],
[ 0.1359, 0.4224, 0.8961, 0.0097],
...,
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000]]],
[[[-0.9065, 0.0611, 0.3347, 0.2499],
[-0.5257, -0.4218, 0.0394, 0.7377],
[-0.1322, 0.6302, 0.7646, -0.0280],
...,
[ 0.6432, 0.6028, 0.1835, -0.4351],
[-0.4235, -0.7525, 0.2486, 0.4388],
[ 0.0000, 0.0000, 0.0000, 0.0000]],
[[-0.0733, 0.8526, 0.3267, -0.0788],
[ 0.8529, 0.3061, 0.4096, -0.1053],
[ 0.6355, 0.4800, -0.6012, -0.0656],
...,
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000]]],
[[[-0.9065, 0.0611, 0.3347, 0.2499],
[-0.5257, -0.4218, 0.0394, 0.7377],
[-0.1322, 0.6302, 0.7646, -0.0280],
...,
[ 0.6432, 0.6028, 0.1835, -0.4351],
[-0.4235, -0.7525, 0.2486, 0.4388],
[ 0.0000, 0.0000, 0.0000, 0.0000]],
[[ 0.8529, 0.3061, 0.4096, -0.1053],
[ 0.6355, 0.4800, -0.6012, -0.0656],
[ 0.6432, 0.6028, 0.1835, -0.4351],
...,
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000]]],
...,
[[[-0.9065, 0.0611, 0.3347, 0.2499],
[-0.5257, -0.4218, 0.0394, 0.7377],
[-0.1322, 0.6302, 0.7646, -0.0280],
...,
[ 0.6432, 0.6028, 0.1835, -0.4351],
[-0.4235, -0.7525, 0.2486, 0.4388],
[ 0.0000, 0.0000, 0.0000, 0.0000]],
[[-0.0733, 0.8526, 0.3267, -0.0788],
[ 0.8529, 0.3061, 0.4096, -0.1053],
[ 0.6355, 0.4800, -0.6012, -0.0656],
...,
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000]]],
[[[ 0.1606, -0.0126, 0.8301, -0.5338],
[-0.5255, 0.2322, -0.3078, 0.7584],
[ 0.2719, -0.0936, -0.9010, 0.3250],
...,
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000]],
[[-0.5255, 0.2322, -0.3078, 0.7584],
[ 0.6682, -0.1490, 0.5041, 0.5265],
[ 0.3344, -0.0973, -0.6929, 0.6313],
...,
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000]]],
[[[-0.9065, 0.0611, 0.3347, 0.2499],
[-0.5257, -0.4218, 0.0394, 0.7377],
[-0.1322, 0.6302, 0.7646, -0.0280],
...,
[ 0.6432, 0.6028, 0.1835, -0.4351],
[-0.4235, -0.7525, 0.2486, 0.4388],
[ 0.0000, 0.0000, 0.0000, 0.0000]],
[[-0.0733, 0.8526, 0.3267, -0.0788],
[ 0.8529, 0.3061, 0.4096, -0.1053],
[ 0.6355, 0.4800, -0.6012, -0.0656],
...,
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000]]]],
grad_fn=)
********************************************************************************
torch.Size([8, 2, 20, 4])
好了,就到这儿吧。
本系列共12期,将分6天发布。相关代码已全部分享在我的github项目(moronism189/chinese-nlp-stepbystep)下,急的可以先去那里下载。