NSL-KDD 基于随机森林的分类模型
NSL-KDD 基于随机森林的分类模型
数据集
NSL-KDD数据集是网络安全领域相对权威的入侵检测数据集,它对KDD 99的一些固有问题做了改进。
(1)NSL-KDD数据集的训练集和测试集中不包含冗余记录,使检测更加准确。
(2)训练和测试中的记录数量设置是合理的,这使得在整套实验上运行实验成本低廉而无需随机选择一小部分。因此,不同研究工作的评估结果将是一致的和可比较的。
NSL-KDD官方地址
本实验用到的文件有 KDDTrain+.txt、KDDTrain+_20Percent.txt和KDDTest+.txt
数据预处理
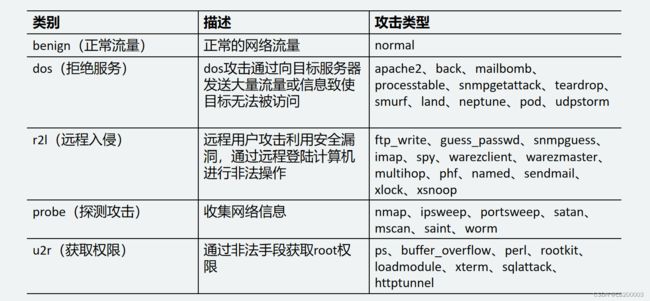
1.原始数据的攻击类型很多,我们把它划分为五大类,先建立一个映射字典
def data_handle():
dataset_root = 'data'#数据根目录
header_names = ['duration', 'protocol_type', 'service', 'flag', 'src_bytes', 'dst_bytes', 'land', 'wrong_fragment', 'urgent', 'hot', 'num_failed_logins', 'logged_in', 'num_compromised', 'root_shell', 'su_attempted', 'num_root', 'num_file_creations', 'num_shells', 'num_access_files', 'num_outbound_cmds', 'is_host_login', 'is_guest_login', 'count', 'srv_count', 'serror_rate', 'srv_serror_rate', 'rerror_rate', 'srv_rerror_rate', 'same_srv_rate', 'diff_srv_rate', 'srv_diff_host_rate', 'dst_host_count', 'dst_host_srv_count', 'dst_host_same_srv_rate', 'dst_host_diff_srv_rate', 'dst_host_same_src_port_rate', 'dst_host_srv_diff_host_rate', 'dst_host_serror_rate', 'dst_host_srv_serror_rate', 'dst_host_rerror_rate', 'dst_host_srv_rerror_rate', 'attack_type', 'success_pred']
#------------------------创建攻击类型的映射字典-----------------------
category = defaultdict(list)
category['benign'].append('normal')
with open('data/training_attack_types.txt', 'r') as f:
for line in f.readlines():
attack, cat = line.strip().split(' ')
category[cat].append(attack)
# print(category)
attack_mapping = dict((v,k) for k in category for v in category[k])
# print(attack_mapping)
training_attack_types.txt 文件内容
apache2 dos
back dos
mailbomb dos
processtable dos
snmpgetattack dos
teardrop dos
smurf dos
land dos
neptune dos
pod dos
udpstorm dos
ps u2r
buffer_overflow u2r
perl u2r
rootkit u2r
loadmodule u2r
xterm u2r
sqlattack u2r
httptunnel u2r
ftp_write r2l
guess_passwd r2l
snmpguess r2l
imap r2l
spy r2l
warezclient r2l
warezmaster r2l
multihop r2l
phf r2l
named r2l
sendmail r2l
xlock r2l
xsnoop r2l
worm r2l
nmap probe
ipsweep probe
portsweep probe
satan probe
mscan probe
saint probe
载入数据
train_file = os.path.join(dataset_root, 'KDDTrain+.txt')
test_file = os.path.join(dataset_root, 'KDDTest+.txt')
train_df = pd.read_csv(train_file, names=header_names)
print(f'初始数据规模')
print(f'X_train shape is {train_df.shape}')
print(Counter(train_df['attack_type']))
# print(f'train_label is {Counter(train_df['attack_type'])}')
print(train_df.info())
查看一下初始数据是什么样子

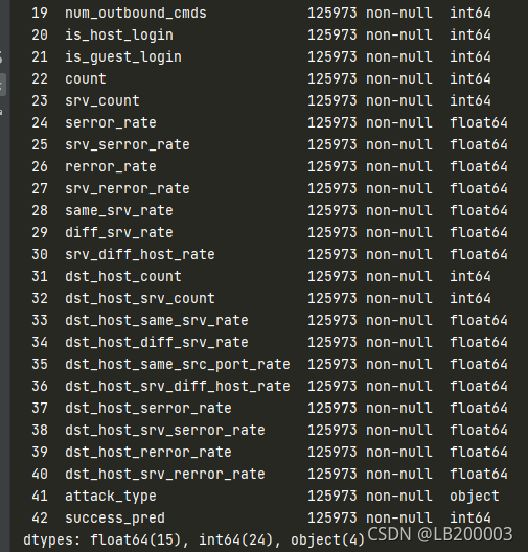
数据共43列,前41列为网络流量特征,第42列为攻击类型,43列为能够正确标注给定记录的学习者数量。第43列与流量本身无关,后面会删掉。
进行归类
train_df['label'] = train_df['attack_type'] .map(lambda x: attack_mapping[x])#把攻击类型归到五大类中
train_df.drop(['attack_type'], axis=1, inplace=True)#去掉细分攻击类型那一列
train_df.drop(['success_pred'], axis=1, inplace=True)#去掉最后一列
# print(train_df)
# print(train_df.info())
test_df = pd.read_csv(test_file, names=header_names)
print(f'X_test shape is {test_df.shape}')
print(Counter(test_df['attack_type']))
test_df['label'] = test_df['attack_type'] .map(lambda x: attack_mapping[x])
test_df.drop(['attack_type'], axis=1, inplace=True)#去掉细分攻击类型那一列
test_df.drop(['success_pred'], axis=1, inplace=True)
查看归类后的数据规模
Y_train = train_df['label'] #训练数据的标签列
Y_test = test_df['label'] #测试数据的标签列
X_train = train_df.drop('label', axis=1) #训练数据的40列特征
X_test = test_df.drop('label', axis=1) #测试数据的40列特征
# print(Y_train)
# print(X_train)
print(f'归类后数据规模')
print(f'X_train shape is {X_train.shape}')
print(f'Y_train shape is {Y_train.shape}')
print(f'train_label is {Counter(Y_train)}')
print(f'X_test shape is {X_test.shape}')
print(f'Y_test shape is {Y_train.shape}')
print(f'test_label is {Counter(Y_test)}')
 数据中存在三个字符型离散特征:‘protocol_type’, ‘service’, ‘flag’,先对它们编码,转换成数字表示。由于转换后的值会影响同一特征在样本中的权重,因此采用独热编码(用N位状态寄存器来对N个状态进行编码)
数据中存在三个字符型离散特征:‘protocol_type’, ‘service’, ‘flag’,先对它们编码,转换成数字表示。由于转换后的值会影响同一特征在样本中的权重,因此采用独热编码(用N位状态寄存器来对N个状态进行编码)
# # ---------------------分离离散特征------------------------------
def split_category(data, columns):
cat_data = data[columns] #分离出的三个离散变量
rest_data = data.drop(columns, axis=1)#剩余的特征
return rest_data, cat_data
categorical_mask = (X_train.dtypes == object)
categorical_columns = X_train.columns[categorical_mask].tolist()
# print(categorical_mask)
# print(categorical_columns)
# ----------------------把三个离散字符型特征编码,转化成数字------------------------
from sklearn.preprocessing import LabelEncoder
def label_encoder(data):
labelencoder = LabelEncoder()
for col in data.columns:
data.loc[:, col] = labelencoder.fit_transform(data[col])
return data
X_train[categorical_columns]= label_encoder(X_train[categorical_columns])
X_test[categorical_columns] = label_encoder(X_test[categorical_columns])
由于数据集极不平衡,先对训练集重采样 再进行独热编码
#---------------------------重采样-----------------------------------
from imblearn.over_sampling import SMOTE, ADASYN
oversample = ADASYN()
X_train, Y_train = oversample.fit_resample(X_train, Y_train)
print(f'重采样后的数据规模')
print(f'X_train shape is {X_train.shape}')
print(f'Y_train shape is {Y_train.shape}')
X_train, X_train_cat = split_category(X_train, categorical_columns)
# print(X)#剩余的38个特征
# print(X_cat) #分离出的三个离散变量 'protocol_type', 'service', 'flag',各自的类别数为3 70 11
X_test, X_test_cat = split_category(X_test, categorical_columns)
# ----------------------------对所有离散变量进行独热编码-------------------------------
def one_hot_cat(data):
if isinstance(data, pd.Series):
data = pd.DataFrame(data, columns=[data.name])
# print(data)
out = pd.DataFrame([])
for col in data.columns:
one_hot_cols = pd.get_dummies(data[col], prefix=col)
out = pd.concat([out, one_hot_cols], axis=1)
out.set_index(data.index)
return out
X_train_cat_one_hot = one_hot_cat(X_train_cat)
print(X_train_cat_one_hot.shape)
print(X_train_cat_one_hot.iloc[:,[0,1,2]])
X_test_cat_one_hot = one_hot_cat(X_test_cat)
print(X_test_cat_one_hot.shape)
额外的一些处理,由于测试集和训练集中存在不同的类型,所以要对齐
# 将测试集与训练集对齐
X_train_cat_one_hot, X_test_cat_one_hot = X_train_cat_one_hot.align(X_test_cat_one_hot, join='inner', axis=1)
print(X_train_cat_one_hot)
print(X_test_cat_one_hot)
X_train_cat_one_hot.fillna(0, inplace=True) #用NAN填充数据集中的空值
X_test_cat_one_hot.fillna(0, inplace=True)
X_train = pd.concat([X_train, X_train_cat_one_hot], axis=1)#数据合并
X_test = pd.concat([X_test, X_test_cat_one_hot], axis=1)
# 特征值归一化
min_max_scaler = MinMaxScaler()
X_train = min_max_scaler.fit_transform(X_train)
X_test = min_max_scaler.fit_transform(X_test)
最后把分类标签也编码一下。可以尝试采用pca降维,但我降维之后准确率变得很离谱,大家可以尝试一下。
#--------------------把分类标签编码-------------------------------
from sklearn.preprocessing import LabelEncoder
Y_train_encode = LabelEncoder().fit_transform(Y_train)
Y_test_encode = LabelEncoder().fit_transform(Y_test)
# pca = decomposition.PCA()
# pca = PCA(n_components=83)
# pca.fit(X_train)
# X_train_reduced = pca.fit_transform(X_train)
# print(X_train_reduced.shape)
#
# pca.fit(X_test)
# X_test_reduced = pca.fit_transform(X_test)
# print(X_test_reduced.shape)
return X_train,Y_train_encode,X_test,Y_test_encode
把处理好的数据存一下,后面验证的时候不用每次都处理了
KDDTrain+.txt和KDDTest+.txt
if __name__ == '__main__':
X_train,Y_train,X_test,Y_test=data_handle()
pd.DataFrame(X_train).to_csv('data/KDDTrain+vtest+_afterHandle.csv',index=False)
pd.DataFrame(Y_train).to_csv('data/KDDTrain+vtest+_label_afterHandle.csv',index=False)
pd.DataFrame(X_test).to_csv('data/KDDTest+_afterHandle.csv', index=False)
pd.DataFrame(Y_test).to_csv('data/KDDTest+_label_afterHandle.csv', index=False)
把前面注释掉,处理KDDTrain+.txt和KDDTrain+_20Percent.txt
pd.DataFrame(X_train).to_csv('data/KDDTrain+_afterHandle.csv',index=False)
pd.DataFrame(Y_train).to_csv('data/KDDTrain+_label_afterHandle.csv',index=False)
pd.DataFrame(X_test).to_csv('data/data/KDDTrain20+_afterHandle.csv', index=False)
pd.DataFrame(Y_test).to_csv('data/KDDTrain20+_label_afterHandle.csv', index=False)
模型建立
随机森林是一种集成学习方法,它是对决策树的集成。每棵决策树都是一个分类器,那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,是一种最简单的 Bagging 思想。
构建过程:
(1) 从N个训练样本中以有放回抽样的方式,取样N次,形成一个训练集,并用未抽到的用例(样本)作预测,评估其误差。
(2)对于每一个节点,随机选择m个特征,m远小于总特征数。从这m个属性中采用某种策略(比如说信息增益或Gini)来选择1个属性作为该节点的分裂属性。
(3)决策树形成过程中每个节点都要按照步骤(2)来分裂,直到不能再分裂。
(4)按照步骤(1)-(3)建立大量的决策树,构成随机森林。
随机森林具有较好的准确率;能够有效地运行在大数据集上;能够处理具有高维特征的输入样本。
模型建立
对下面的参数进行调优

将n_estimators设置在0-200之间,设置步长为10,得到最优参数为131
# 优化n_estimators树的棵数
scorel = []
for i in range(0, 200, 10):
RFC = RandomForestClassifier(n_estimators=i + 1,
n_jobs=-1,
random_state=0)
score = cross_val_score(RFC, X_train, Y_train, cv=10).mean()
scorel.append(score)
print(max(scorel), (scorel.index(max(scorel)) * 10) + 1) # 作图反映出准确度随着估计器数量的变化,131的附近最好
plt.figure(figsize=[20, 5])
plt.plot(range(1, 201, 10), scorel)
plt.show()
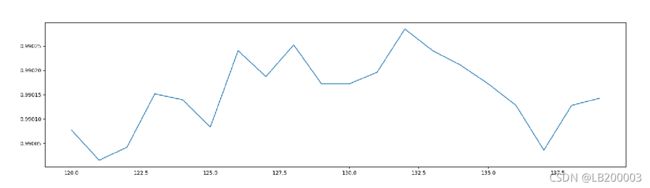
缩小步长为1,在120-140内继续调优,最终得到最优参数为
# 根据上面的显示最优点在131附近,进一步细化学习曲线
scorel = []
for i in range(120, 140):
RFC = RandomForestClassifier(n_estimators=i,
n_jobs=-1,
random_state=0)
score = cross_val_score(RFC, X_train, Y_train, cv=10).mean()
scorel.append(score)
print(max(scorel), ([*range(120, 140)][scorel.index(max(scorel))])) # 132是最优的估计器数量 #最优得分是0.990285
plt.figure(figsize=[20, 5])
plt.plot(range(120, 140), scorel)
plt.show()
## 调整max_features
param_grid = {'max_features': ['auto', 'sqrt', 'log2']}
RFC = RandomForestClassifier(n_estimators=132
, random_state=0
)
GS = GridSearchCV(RFC, param_grid, cv=10)
GS.fit(X_train, Y_train)
print(GS.best_params_) # 最佳最大特征方法为auto 不用更改默认
## 调整criterion
param_grid = {'criterion': ['gini', 'entropy']}
RFC = RandomForestClassifier(n_estimators=132
, random_state=0
)
GS = GridSearchCV(RFC, param_grid, cv=10)
GS.fit(X_train, Y_train)
print(GS.best_params_) # 在这种情况下,最佳判别标准为gini
## 优化max_depth
from sklearn.model_selection import GridSearchCV
param_grid = {'max_depth': np.arange(1, 20, 1)} # 一般根据数据的大小来进行一个1~20这样的试探,更应该画出学习曲线,来观察深度对模型的影响
RFC = RandomForestClassifier(n_estimators=132
, random_state=0
)
GS = GridSearchCV(RFC, param_grid, cv=10)
GS.fit(X_train, Y_train)
print(GS.best_params_) # 最佳深度为19
调优结果

模型测试
用默认参数分类
if __name__ == '__main__':
#------------------测试1 训练集KDDTrain+.txt 测试集KDDTrain+_20Percent.txt------------------------
X_train = pd.read_csv("data/KDDTrain+_afterHandle.csv")
X_train=X_train.values
print(X_train.shape)
Y_train=pd.read_csv("data/KDDTrain+_label_afterHandle.csv")
Y_train=Y_train.values
print(Y_train.shape)
X_test=pd.read_csv("data/KDDTrain20+_afterHandle.csv")
X_test=X_test.values
Y_test=pd.read_csv("data/KDDTrain20+_label_afterHandle.csv")
Y_test=Y_test.values
# ------------------测试2 训练集KDDTrain+.txt 测试集KDDTest+_.txt------------------------
# X_train = pd.read_csv("data/KDDTrain+vtest_afterHandle.csv")
# X_train = X_train.values
# # print(X_train.shape)
# Y_train = pd.read_csv("data/KDDTrain+vtest_label_afterHandle.csv")
# Y_train = Y_train.values
# # print(Y_train.shape)
# X_test = pd.read_csv("data/KDDTest+_afterHandle.csv")
# X_test = X_test.values
# Y_test = pd.read_csv("data/KDDTest+_label_afterHandle.csv")
# Y_test = Y_test.values
#------------------模型评估--------------------
def assess_model(model_pred):
target_names = ['benign', 'dos', 'probe', 'r2l', 'u2r']
print(f'准确率: {accuracy_score(Y_test, model_pred)}')
print(f'混淆矩阵:')
print(confusion_matrix(Y_test, model_pred))
print(f'分类报告:')
print(classification_report(Y_test, model_pred, target_names=target_names, digits=3))
f1 = f1_score(model_pred, Y_test, average='macro')
print(f'f1_score is {f1}')
# 默认
RFC = RandomForestClassifier()
# RFC.fit(X_train, Y_train)
RFC.fit(X_train, Y_train)
RFC_pred = RFC.predict(X_test)
print(f'随机森林')
assess_model(RFC_pred)
测试1 训练集KDDTrain+.txt 测试集KDDTrain+20Percent.txt

测试2 训练集KDDTrain+.txt 测试集KDDTest+.txt
这个报错可以忽略 或者把RFC.fit(X_train, Y_train)改成RFC.fit(X_train, pd.DataFrame(Y_train).values.ravel())就ok了
C:/Users/LB/Desktop/2021研究生课程资料/2021研一上/数据仓库及数据挖掘/作业2_数据挖掘/AnomalyDetection/test.py:112: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().
RFC.fit(X_train, Y_train)

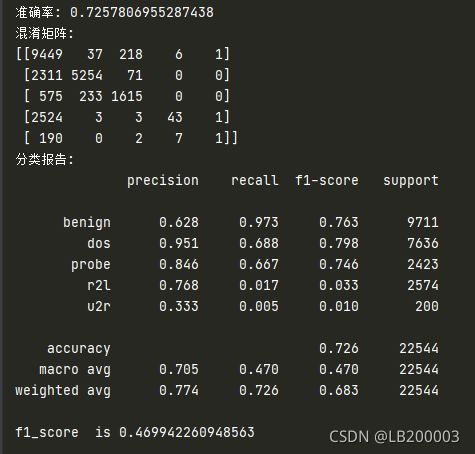
用调优后的参数分类
# 调参后
RFC = RandomForestClassifier(n_estimators=132 , random_state=0,max_depth=19)
# RFC.fit(X_train, Y_train)
RFC.fit(X_train, Y_train)
RFC_pred = RFC.predict(X_test)
print(f'随机森林')
assess_model(RFC_pred)
测试1 训练集KDDTrain+.txt 测试集KDDTrain+_20Percent.txt

测试2 训练集KDDTrain+.txt 测试集KDDTest+_.txt

max_depth调整可能会导致过拟合,我们验证一下,用调优后的其他参数,但不使用max_depth=19 ,训练集20%的准确率升高了,但测试集的准确率下降了,明显过拟合了
RFC = RandomForestClassifier(n_estimators=132 , random_state=0)
# RFC.fit(X_train, Y_train)
RFC.fit(X_train, Y_train)
RFC_pred = RFC.predict(X_test)
print(f'随机森林')
assess_model(RFC_pred)
测试1 训练集KDDTrain+.txt 测试集KDDTrain+_20Percent.txt

测试2 训练集KDDTrain+.txt 测试集KDDTest+_.txt
因此我们还是采用调优后的整套参数
总结
以上建立了NSL-KDD的一个简单分类模型。本实验是我作为数据挖掘的一个课堂汇报,老师问了一个问题我没答上来。这个问题是 随机森林是二分类算法,怎么用于多分类呢
我下来想了一下 ,应该是因为随机森林里的很多棵决策树,它们最后分成的两类结果不一定是一样的,这样每种类别都会有对应的决策树。因此对每个类别进行分类时,用的是与之相关的决策树,所以随机森林可以实现多分类。
参考
参考1
参考2