推荐系统(Recommender System)笔记 04:推荐系统工程实现
推荐系统(Recommender System)04:推荐系统工程实现
- 推荐系统的数据流
-
- 批处理大数据架构(Batch Processing)
- 流计算大数据架构 (Streaming Processing)
- Lambda 架构
- Kappa 架构
- 大数据平台与推荐系统的结合
- 推荐模型的离线训练
-
- Spark MLlib
- Parameter Server
- TensorFlow
- 推荐模型的上线部署
-
- 预存 推荐/Embedding 结果
- 自研模型线上服务平台
- 训练 Embedding + 轻量级线上模型
- 利用 PMML 转换并部署模型
- TensorFlow Serving
从具体的工程实现角度来看,推荐系统有 2 个不可或缺的组成部分:数据部分 (Data) 和模型部分 (Model)。这和其他绝大多数的 ML 以及 DL 任务都一致:
- 数据部分 (Data):推荐系统所需要的数据流的相关工程实现。
- 模型部分 (Model):推荐模型的工程实现,包括离线训练和在线训练
结合推荐系统的架构,我们可以把推荐系统的工程结构细分为 3 个部分:
- 推荐系统的数据流: 借助大数据平台去处理实时流 (stream) 以及离线数据 (local)
- 推荐模型的离线训练: 借助深度学习平台,训练推荐系统的深度学习模型
- 推荐模型的上线部署: 将训练好的推荐模型部署上线,正式提供服务
推荐系统的数据流
本节主要讲目光放在使用什么大数据平台去处理数据流以及如何处理数据流。下面将按照发展的顺序进行介绍
批处理大数据架构(Batch Processing)
在之前的 Big Data Mangement 系列笔记中,我们实际上已经对这个部分进行了相当细致的了解,因此在这里我们只进行大概的介绍: Big Data Management Framework_MYJace的博客-CSDN博客
所谓的批处理 (Batch Processing) 就是对已经落盘的全量静态数据进行处理。 由于数据量级的关系,甚至难以将数据存储到本地,更别说如此大量的计算。因此,“分布式存储 + Map Reduce” 的架构应运而生,这就是我们很熟悉的 Apache Hadoop,它主要由分布式存储系统 HDFS 以及分布式计算框架 MapReduce 组成。

但是这一架构的缺点很明显,他只能处理已经落盘的数据,因此基本不具备实时性,越来越难以满足当下对实时性要求越来越高的数据计算。
流计算大数据架构 (Streaming Processing)
与批处理相对,流计算框架就是在数据流产生以及传递过程中流式地消费并处理数据。 流数据计算框架中,“滑动窗口 (Sliding Window) ” 会显得十分重要,这是一个时间窗口,流计算的延迟和它直接相关。一般来说,这个时间窗口应该在分钟级,比如 3 分钟。那么在这个窗口内,数据会被短暂缓存并使用,只有当前窗口内的数据都被处理之后,窗口才会滑动到下一个时间段。
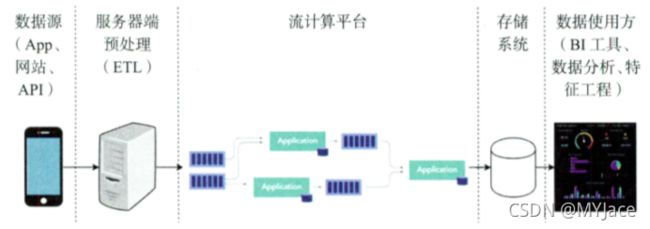
需要注意,流计算不只是针对一个数据流进行的,它可以将两个数据流进行 Join,然后在同一个时间窗口内进行统一处理。最典型的流计算大数据框架就是 Flink,Spark Streaming 等。其中 Flink 是近些年的主流,它将所有数据全部看作 “流 (Stram)” 来处理,也就是说,在 Flink 眼中,批处理也只是流计算的一种特殊情况。
很明显,流计算的优点就是在于大大降低了延迟,增强了数据流的灵活性。但是由于抛弃了批量处理,流计算在全量分析、数据回放方面会显得力不从心;另外,当时间窗口变得很小时,日志乱序、Join 操作造成的数据遗漏而导致的数据误差会不断累积。
Lambda 架构
Lambda 架构在一开始的数据收集阶段就被分为两条分支:实时流以及离线处理。 和之前一样,实时流更注重保障数据的实时性;离线处理即批处理,则力求保证数据最终的一致性。
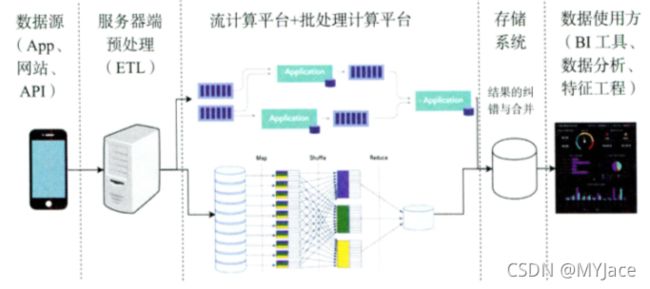
在将统计数据存入最终的数据库之前,Lambda 有一个很关键的步骤。它会将实时流数据和离线层数据进行合并,并且使用离线数据对实时流进行纠错和校验。
总的来说,Lambda 同时保留了实时流处理和批处理两条数据处理流程。力求保证实时性的同时,也能够保障全面性。但是实时流处理和批处理可能会有大量冗余的重复逻辑,进行重复的编码工作,造成资源的浪费。
Kappa 架构
Kappa 就是为了处理 Lambda 中的冗余计算而诞生的。Kappa 的核心思想就是 “Everything is streaming”,也就是说,无论是真实的实时流,还是离线批处理都以流计算的形式执行。在这个层面 Kappa 和 Lambda 无疑是一脉相承的。那么,Kappa 到底是如何使用流计算框架来实现批处理的呢?
我们之前说过,实时流计算中 “时间窗口” 是一个很重要的概念,一般时间窗口都是分钟级的。那么,对于批处理,我们也可以将其看作是处理一个 “时间窗口” 的数据,只不过 “时间窗口” 的跨度从 “分钟” 级变为 “天” 级。 但是这样就会有一个疑问,如果时间窗口变为 “天” 级,那还怎么进行线上计算?(会造成大量的数据积压,堵塞住数据通路)答案是不进行在线计算,转而在离线环境利用流处理框架进行数据批处理。
这就需要在原有的流计算框架上添加两个通路:“原始数据存储” 和 “数据重播”:
- 原始数据存储: 将未经过流处理的数据/日志原封不动存入分布式文件系统
- 数据重播:将分布式存储系统中存入的原始数据按照时间进行排序,进行重播,让其通过流处理框架,从而完成离线状态的批处理
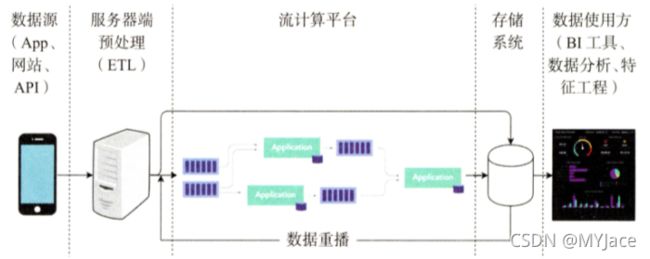
但是,这 Kappa 中,数据重播的效率问题以及实时流处理以及批处理能否完全共享会成为一个问题
大数据平台与推荐系统的结合
大数据平台与推荐系统的结合体现在 2 个方面:
- 训练数据的处理
- 特征的预计算
根据业务场景的差异,处理完的数据会流向两个不同的方向:
- 以 HDFS 为代表的离线海量数据存储平台。主要存储离线训练使用的训练数据
- 以 Redis 为代表的在线实时特征数据库。主要为模型的在线训练提供实时特征

大数据框架的选择与推荐模型的训练方式密切相关。而新一代的 Unified 大数据框架更是通过为 Kappa 和 Lambda 添加机器学习层来将机器学习和数据处理进行了有机结合。
推荐模型的离线训练
在上一个环节,我们已经借助大数据平台对海量的数据流进行了处理,这种量级的数据量直接决定了机器学习模型完全无法在单机上完成训练,所以很自然的,对于机器学习模型,我们也必须采用分布式训练方式。下面将陆续介绍 3 种主流的解决分布式训练的方案
Spark MLlib
Saprk 最为当前最为主流的数据处理平台之一,为了保证数据处理与模型训练的一致性,其原生的机器学习平台 Spark MLlib 自然也会受到不小的青睐。Spark MLlib 为并行训练提供了一种最朴素经典的方案。
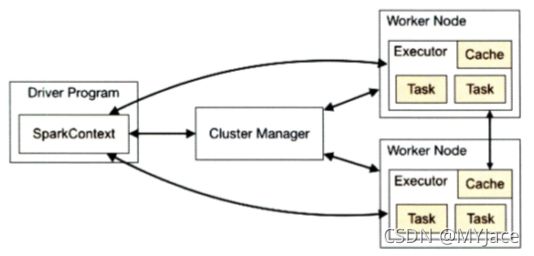
对于 Spark 我们同样在之前的 Big Data Management 系列笔记中进行了比较详细的介绍,因此这里也只对其关键的部分进行一个大致的梳理。Spark 和 MapReduce 一样是分布式计算框架,其主体架构如下所示:
其中 Cluster Manager (集群管理节点) 进行资源调度,具体的计算任务分发给 Worker Node (工作节点) 完成,最终的结果都被返回到 Driver Program (驱动程序) 。而在 Worker Node 中,数据还会进一步被分为 Partitions。
在执行任务时,Spark 会使用 DAG 将工作流程先拆分为多个 stages。划分 stages 的依据在于:
- Narrow Transformation 会被归纳为 1 个 stage
- Wide Transaformation 定义 2 个 stages 的边界
Narrow Transformation 和 Wide Transformation 的区别在于同一个 partition 在进行了 Transformation 之后是否仍会在同一个 Partition 中。而只有 Wide Transformation 会进行 Shuffling
在上面这个 DAG 中,groupByKey 和 Join 就是典型的 2 个 Wide Transformation。因此 stages 的划分如上所示。这就直观体现了 Spark 运算的过程:在 stage 内高效并行计算,stage 边界处进行资源消耗较高的 shuffling 或 reduce 操作。
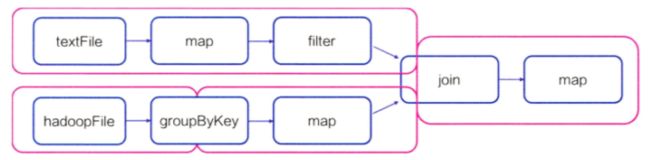
在了解 Saprk 分布式计算的基础上,就能去理解 Spark MLlib 模型并行训练的原理。而在机器学习模型的训练中,梯度下降法一直是我们无法绕开的方法。这一方法在模型训练中占据了绝对的主流,同时在分布式模型训练中,梯度下降的并行程度直接决定了深度学习模型的训练速度。
我们可以通过 Spark MLlib 的源码来看它是如何进行 mini Batch 梯度下降的。这里贴出简化版的源码:

从上面的代码来看,mini Batch 主要做了三件事:
- 把当前模型的参数 (Parameters) 广播到所有的 Partitions
- 各计算节点进行数据抽样 (Sampling),得到 mini Batch 的数据,各自计算梯度。然后用 treeAggregate() 汇总这些梯度,得到最终的梯度 gradientSum
- 利用这个最终梯度 gradientSum 去更新模型
*所谓的 treeAggregate 就是进行类似树结构的逐层汇总,整个过程就是一个 reduce 的过程,没有任何 shuffle
我们结合之前用 DAG 分出的 stages 来看。在 stage 内的并行计算就是各节点各自进行采样并计算梯度,stage 的边界部分就是汇总(求和)各节点的梯度。和一般的机器学习训练一样,最后当迭代次数达到某个阈值或者误差小于某个阈值时,训练停止。
可以看到,Spark MLlib 的并行训练过程,实际上是 “数据并行” 的过程,没有涉及复杂的梯度更新策略。但如此一来,就会有一些缺陷:
- 每轮迭代前需要全局广播模型所有参数,让每个节点都知道当前模型使用的参数是怎样的。 这种操作非常消耗带宽资源
- 阻断式的梯度下降机制,每轮更新的时长由最慢的节点决定。 这很好理解,因为当前这一轮迭代中,模型的梯度是由所有节点的梯度汇总才能得到,在得到这个最终梯度之前,无法更新模型,这时候,如果某个节点计算其梯度的速度很慢,那么,就会大大拖慢更新速度。(这是很有可能发生的,尤其是存在数据倾斜的问题时)
- Saprk MLlib 不支持结构复杂的深度学习模型的训练,只支持标准的 MLP (多层感知机) 训练。
Parameter Server
为了解决 Spark MLlib 中存在的广播消耗问题以及阻断式梯度下降带来的弊端,Parameter Server 诞生了。
回顾一下最基本的机器学习模型训练过程:
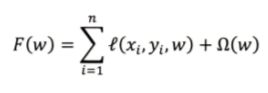
上式就是一个带有正则化项的损失函数,n 就是样本总量,l(x, y, w) 就是单个样本的损失函数,其中 x 表示特征向量,y 是样本标签,w 就是模型参数。这里的正则化项 Ω(w) 需要汇总所有模型参数才能正确计算,因此 Parameter Server 在进行并行训练时,也和 Spark MLlib 一样需要先计算局部梯度在汇总为整体梯度以更新参数权重。Parameter Server 主要由两个部分组成:
- Server:Server 节点用以保存模型参数、接受 Worker 节点计算出的局部梯度、汇总计算全局梯度并更新模型参数
- Worker:Worker 节点会保存部分训练数据并从 Server 节点拉取最新的模型参数,使用训练数据计算局部梯度,上传给 Server

根据上面的架构图我们可以看到,Server Group 和 Worker Group 分别包含了大量的 Server 节点以及 Worker 节点。其中,每个 Server 几点会维护一部分参数,服务器管理中心 (Server Manager) 主要负责维护和分配 Server 资源。而每个 Worker Group 就对应一个模型训练任务,Worker Group 之间以及 Worker Group 内部的任务节点之间都不会有任何交流,任务节点只会和 Server 通信。 而具体的训练流程如下图所示:
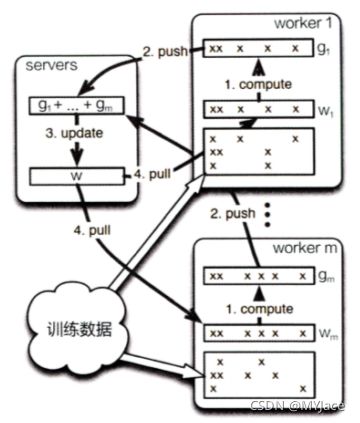
Parameter Server 并行训练过程的梯度下降流程中,最关键的两个操作就是 Push 和 Pull:
- Push:Worker 节点利用本地的训练数据,计算出梯度,上传给 Server 节点
- Pull:Worker 节点从 Server 节点获取最新的模型参数以进行下一轮计算
因此,我们可以将整个训练流程梳理出来:
- 每个 Worker 节点存入一部分训练数据
- Worker 节点从 Server 节点获取最新的模型参数 (Pull)
- Worker 节点使用本地数据计算梯度
- Wroker 节点将计算好的梯度上传至 Server 节点
- Server 节点汇总梯度并且更新模型
- 重复步骤 2 (直到训练结束)
我们已经直到,Spark MLlib 中,采用 “同步阻断式” 的并行梯度下降策略,这导致了训练速度降低,但是却有效保证了 “一致性”,因为所有计算节点都会使用到最新的模型参数去进行下一轮计算,所以计算的结果和串行梯度下降的计算结果严格一致。但是在 Parameter Server 中,采用了完全不同的 “异步非阻断式” 的梯度下降,这是什么意思呢?
我们用一个例子就能很好地理解:
可以看到,由于第 10 次迭代的 push&pull 操作还没有完全结束,而第 11 次迭代已经开始,此时最新的模型参数还没能被拉取到本地,因此,仍在使用第 10 次迭代时使用的模型参数来计算梯度。换言之,所有的节点始终都在进行并行工作,不会被其他节点任务的进度影响。
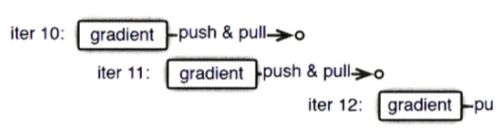
当然,这样的策略是建立在牺牲了 “一致性” 的基础上的,也就是说,并行训练的结果与原来的单点串行训练的结果是不一致的,这样的不一致会对模型收敛的速度造成一定影响。所以最终选择哪种策略需要根据不同模型对于一致性的敏感程度来决定。但是整体来说,“异步非阻断式” 策略无论从计算效率还是收敛速度来说,都比同步策略更好。
那么,到此为止,Parameter Server 已经解决了 Spark MLlib 的第一个缺点:“同步阻断式更新策略会降低运算效率”。接下来,就来看看 Parameter Server 如何解决另一个问题:“多节点协同的效率问题”
Saprk MLlib 由于每次都需要将模型的全部参数广播给所有计算节点,受限于有限的带宽资源,这会使得 Master 节点的效率低下。根据之前的架构图,我们知道 Server Group 中会有多个 Server 节点,每个 Server 节点负责部分模型参数。模型参数以 key-value 形式表示,因此,每个 Server 节点只需要负责一定 Key Range 内的参数即可。 此时,就需要考虑以下几个问题:每个 Server 几点如何确定自己该负责的参数范围?如果有新的 Server 节点加入,该怎么半?
这些问题就需要借助一致性哈希 (Consistent Hashing) 来解决。我们先来看由 Parameter Server 节点组成的哈希环 (Hashing Cycle):

在 Server Group 中,使用一致性哈希来进行参数管理的流程如下:
- 将模型参数的 Key 映射到一个环形的哈希空间。这很简答,比如一个 Hash Function 会将 Key 映射到 0 ~ 9,那么只需要保证 10 的下一个 Bucket 为 0 对应的 Bucket 即可
- 根据 Server 节点的数量 n,把环形空间等分为 nm 个范围,即每个 Server 节点负责 m 个哈希范围。 这样可以保证一定的负载均衡性
- 一个新的 Server 节点加入时,让这个新加入的 Server 节点找到哈希环上的插入位置。 如此,新的 Server 节点负责插入点与下一个插入点之间的哈希范围即可。相当于将原有的某一段哈希范围分为两部分,原有的 Server 几点负责前半部分,新加入的 Server 节点负责后半部分。
- 删除某个 Server 节点时,移除该节点相关的插入点,让相邻节点接手其负责的范围。
只要遵循上面的这一系列流程,某个 Worker 拉取 (Pull) 模型参数时,只需要发送不同的 “范围拉取请求 (Range Pull)” 到不同的节点,之后各节点并行发送自己负责的权值参数给 Worker 节点即可。在进行 Push 时,也可进行同样的操作,即利用范围推送 (Range Push) 将梯度发送给一部分相关的 Server 节点即可。
大致总结一下 Parameter Serving 的特点:
- 使用 “异步非阻断式” 梯度更新策略替代 Spark MLlib 中的 “同步阻断式” 策略
- 实现多 Server 节点的架构,避免单 Master 节点带来的低效问题
- 使用一致性哈希、Range Pull 和 Range Push 等工程手段减少信息的全局传递总量
TensorFlow
TensorFlow 作为当下使用最多的 ML/DL 学习框架,对于所有人来说应该都不陌生。其核心思想就是任何复杂的深度学习模型,都能够使用张量流动图 (Tensor Flow Chart) (操作有向图)来进行表示,下图就是一个例子:
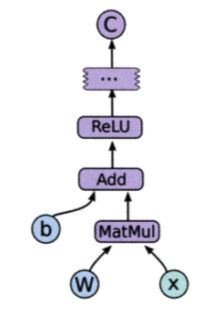
这样一张任务关系图就能够帮助 TensorFlow 进行灵活的资源调度以利用 GPU 或是分布式计算节点来提升并行计算的效率。其调度的主要原则是 “存在依赖关系的任务节点或者子 图 (subgraph) 之间需要串行执行,不存在依赖关系的任务节点或者子图之间可以井行执行”
下面就用一个 TensorFlow 官方给出的任务关系图来理解一下:
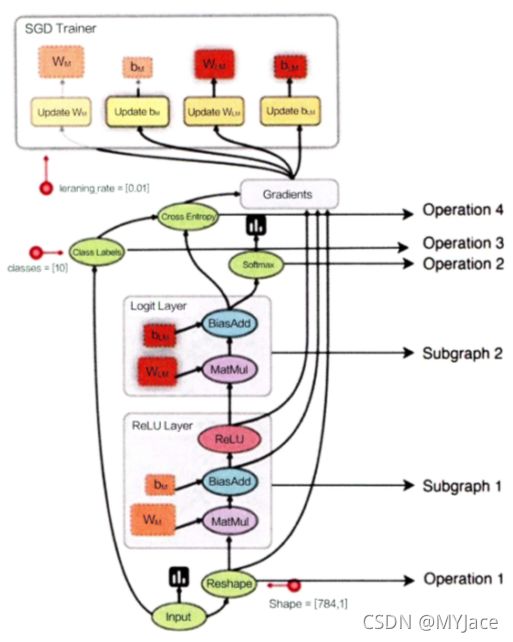
可以看到,这张图和之前那张任务简图稍显不同,最明显的区别在于它由操作节点 (Operation Node) 和任务子图 (Subgraph) 组成。所谓的子图就是由一组串行的操作节点组成,由于是串行,所以认为它们不可进行再分割。现在具体来看 TensorFlow 如何进行任务调度,实际上很好理解,TensorFlow 为所有的操作维护一个任务队列 (Queue):
- 当某个任务的所有前置任务都被完成,该任务就会被加入队尾
- 当由空闲的计算节点,根据队列 (Queue) 先进先出的特性,计算节点从队首取一个任务进行计算
在上面这张任务图中,由于 Operation 1 和 Operation 3 会被同时加入任务队列,此时若有 2 个空闲计算节点,会拉取出 Operation1 和 Operation 3 并行执行。Operation 1 执行结束后,以此向任务队列依次加入 Subgraph 1 和 Subgraph 2 并串行执行,当 Subgraph 2 执行结束,Operation 2 所有前置任务完成,加入队列。Operation 4 的前置任务是 Subgraph 2 和 Operation 3 ,只有当它们全部执行完才会被推送到任务队列中。所有计算节点上的任务都被执行完毕并且任务队列中已经 没有待处理的任务时,整个训练过程结束
TensorFlow 同时支持单机训练和多机分布式训练。所谓的单机训练也会使用 CPU 和 GPU 的并行计算,但仍是共享内存 (Memory) 的环境;而多机分布式训练,则是真正使用多台不共享内存的独立计算节点组成的集群环境下的训练方法,计算节点间需要依靠网络通信。
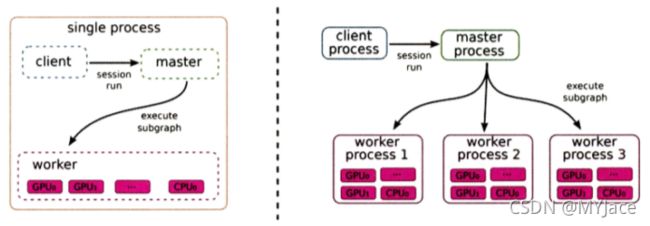
可以看到,单机训练场景下,仅有一个 Worker Node,此时按照任务关系图,在不同的 GPU 和 CPU 节点之间并行计算;分布式场景下,会有多个 Worker Node,每个 Worker Node 中则和单机场景下的训练过程一致。若采用 TensorFlow 的 Parameter Server 策略,此时每个 Worker Node 会使用各自不同的数据,根据相同的任务图来进行训练,然后进行梯度汇总。(此时就是一个 2 层并行计算的结构)
*这里刚好也即使一下为何平时我们在进行模型训练时,会选择使用 tensorflow_gpu,即借助 GPU 来加速训练。因为 GPU 拥有多核优势,因此在处理矩阵加、向量乘等张量运算时,相比 CPU 更加强大。举例来说,在处理两个向量的元素乘操作时, CPU 会居中调度,把两个向量 对应范围的元素发送给 GPU 处理,再收集处理结果,最终生成处理好的结果向量
推荐模型的上线部署
离线训练完成的模型,最终还是要将其部署上线,提供正式的服务,让模型进行实时的推荐,以此来创造营收。
部署推荐模型的方法也会有多种不同选择
预存 推荐/Embedding 结果
这是最简单粗暴的一种方法,即在离线环境下就生成好每个用户的推荐结果,将这些结果存在 Redis 等线上数据库中。等用户上线后,在线上直接把结果推送给用户即可。
| 优点 | 缺点 |
|---|---|
| 无须考虑实现模型线上推断,将线上服务和线下训练完全独立 | 需要存储用户 x 物品 x 应用场景的组合推荐结果,数据规模过大时,容易发生组合爆炸的情况,线上数据库根本无力支撑如此大规模结果的存储 |
| 线上服务不需要进行复杂的计算,线上延迟很低 | 无法引人线上场景类特征,推荐系统的灵活性和效果受限 |
因此,预存推荐结果只适合用户规模较小,或一些冷启动问题场景。
预存 Embedding 则是这种方式的一种进阶版。此时在线上数据库存储的不是海量的推荐结果,而是用户和物品的 Embedding,这样大大减少了存储需求。但同时线上服务需要进行一些计算,比如计算 Embedding 之间的内积/余弦相似度来得出最终的推荐结果。
但是这两种方法都无法引入线上场景特征,并且无法进行复杂模型结构的 线上推断,表达能力受限
自研模型线上服务平台
由于 TensorFlow 等通用平台为了灵活性和通用性的要求,需要支持大量冗余的功能,导致平台过重,难以修改和定制。 而自研平台的好处是可以根据公司业务和需求进行定制化的实现,并兼顾模型服务的效率。
另一个原因是当模型的需求比较特殊时,大部分深度学习框架无法支持。 例如,某些推荐系统召回模型、“探索与利用” 模型、与推荐系统具体业务结合得非常紧密的冷启动等算法,它们的线上服务方法一般也需要自研
自研平台的弊端显而易见。 由于实现模型的时间成本较高,自研一到两种模 型是可行的,做到数十种模型的实现、比较和调优则很难
训练 Embedding + 轻量级线上模型
这是一种结合通用平台的灵活性、 功能的多样性,以及自研模型线上推断高效性的方法。这一方法的逻辑为:“复杂网络离线训练、生成 Embedding 存入内存数据 库、线上实现逻辑回归或浅层神经网络等轻量级模型拟合优化目标”
比如之前介绍过的双塔模型,它分别用复杂网络对 “用户特征” 和 “物品特征” 进行了 Embedding 化,在最后的交叉层之前,用户特征和物品特征之间没有任何交互,这就形成了两个独立的 “塔”。将这前半部分生成的 Embedding 都存入线上数据库。
至于模型最后的输出层逻辑则部署上线,作为线上推断的逻辑。这里的输出层一般就是逻辑回归、softmax 或是浅层神经网络,这样相对简单的结果,部署上线非常合适。
如此一来,从内存数据库中取出用户 Embedding 和物品 Embedding 之后,通过输出层的线上计算即可得到最终的预估结果
利用 PMML 转换并部署模型
Embedding + 轻量级线上模型这一方法确实很不错,但本质上是分割了原本完整的模型,一部分放在线下,一部分放在线上。我们希望能够将训练好的模型,完整部署到线上,这就需要使用一种脱离平台的通用的模型部署方式 一 PMML。
PMML 全称 “预测模型标记语言 (Predictive Model Markup Language)”,是一种以 XML 的形式表示不同模型结构参数的标记语言,用以连接离线训练平台和线上部署平台。下面以 Spark MLlib 作为离线训练平台为例子:

这个例子中使用 JPMML 作为序列化和解析 PMML 文件的库 (Library)。整个项目分为使用 Spark 进行离线训练的部分以及使用 Java Server 进行线上部署的部分。在 Saprk 平台完成模型训练之后,将模型结构的参数进行序列化 (Serialize) 生成 PMML 文件并保存到线上服务器能够触达的数据库或 文件系统中;Java Server 部分则完成 PMML 模型的解析,并生成预估模型,完成与业务逻辑的整合。JPMML 在 Java Server 部分只进行推断,不考虑模型训练、分布式部署等一 系列问题,因此 library 比较轻,能够高效地完成推断过程。
但是 PMML 对于 TensorFlow 中比较复杂的模型表达能力不足,因此上线 TensorFlow 模型时,就需要它的原生支持 TensorFlow Serving
TensorFlow Serving
TensorFlow Serving 的工作流程和 PMML 类工具的流程是一致的。不同之处在于,TensorFlow 定义了自己的模型序列化标准。 利用 TensorFlow 自带的模型序列化函数可将训练好的模型参数和结构保存至某文件路径。
