Python Spark 机器学习(二)
Python Spark 机器学习(二)
主要是MLlib包(基于RDD)和ml包(基于DataFrame)的使用
上篇文章中我们使用了MLlib,这次我们使用ml包。
Python Spark ML 决策树二元分类
通过Kaggle上一个题目来实践: StumbleUpon Evergreen Classification Challenge
该题目内容是判断一个网页内容是暂时性的(ephemeral)还是长青的(evergreen),具体内容可以在Kaggle网站上查看。
查看并下载数据(需注册)
在data页面查看train数据的大致情况,有27列,其中26列特征列,1列标签列。查看数据描述,其中0-2字段是网址、网址ID、样板文字,跟网页是否长青关系不大,我们可以直接忽略。

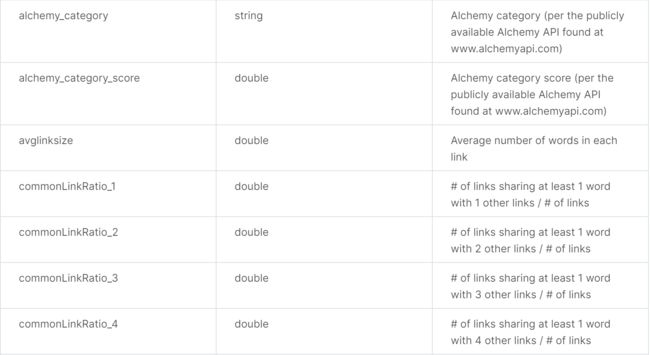
后面的字段都是特征字段,第三个是string,后面的都是数值型(太多,就不一一展示,可以在网页上查看)。这些大致判断是跟结果有关的(至于到底有多大相关,如果是数值型可以求相关系数表,如果是字符型可以做方差分析)。
test数据有26列,全是特征列,没有标签列(废话)。
下载train和test数据,解压。
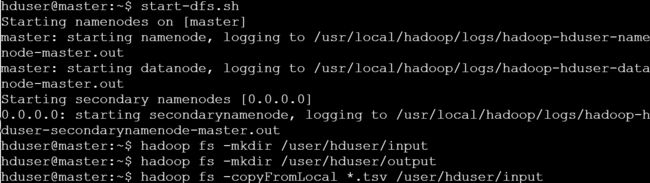
上传文件到HDFS
# 启动hdfs
start-dfs.sh
# 先创建两个文件用来存储输入和输出文件(可自行指定)
hadoop fs -mkdir /user/hduser/input
hadoop fs -mkdir /user/hduser/output
# 上传下载的两个文件到hdfs
hadoop fs -copyFromLocal *.tsv /user/hduser/input
Spark ML Pipeline 机器学习简单介绍
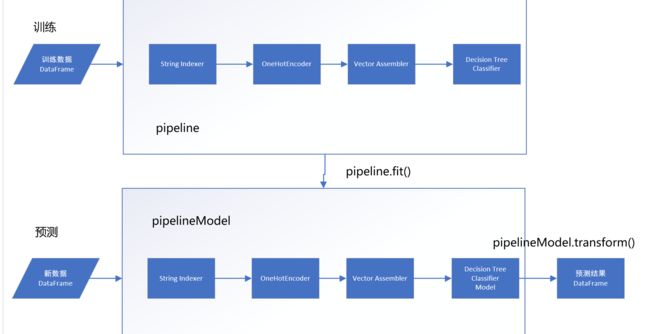
Spark 机器学习工作流程(ML Pipeline)的原理就是将机器学习的每一个阶段形成机器学习工作流程。流程示意图如下。(跟sklearn的pipeline相似)
说明如下:
(1)建立机器学习流程pipeline:包含4个阶段(stages),前三个阶段是数据处理阶段,第四个阶段是DecisionTreeClassifier 机器学习分类算法阶段。
- StringIndexer: 将文字的分类特征字段转换为数值。
- OneHotEncoder: 将一个数字的分类特征字段转换为多个字段。
- VectorAssembler: 将所有的特征字段整合成一个Vector字段。
- DecisionTreeClassifier: 进行训练并产生模型。
(2)训练:“训练数据 DataFrame” 使用pipeline.fit() 进行训练。系统会按照顺序执行每一个阶段,最后产生pipelineModel模型。pipelineModel和pipeline类似,只是多了训练后建立的模型Model。
(3)预测:“新数据 DataFrame” 使用 pipelineModel.transform() 进行预测。系统会按照顺序执行每一个阶段,并使用DecisionTreeClassifier 进行预测。预测完成后,会产生“预测结果DataFrame”。
名词说明:
- DataFrame: Spark ML 机器学习API处理的数据格式必须是DataFrame(跟Python的DataFrame基本类似)。
- Transformer: 是训练好的模型,可以用transform方法将一个DataFrame转换为另一个DataFrame。
- Estimator: 是一个算法,可以使用fit方法传入一个DataFrame进行训练,产生模型Transformer。
- Pipeline: 可以串联多个Transformers 和 Estimators 建立ML机器学习的workflow工作流程。
数据准备
new一个新的notebook
# 配置文件读取路径
global Path
if sc.master[0:5]=='local':
'''如果是现在本地运行则读取本地文件'''
Path = 'file:/home/hduser/'
else:
'''否则读取hdfs文件'''
Path = 'hdfs://master:9000/user/hduser/input/'

读取文件并查看数据项集
# 使用sqlContext.read() 导入文本文件,并创建row_df DataFrame
row_df = sqlContext.read.format("csv").option("header", "true").option("delimiter", "\t").load(Path + "train.tsv")
print(row_df.count())
# 指定格式是 'csv',是否有 'header'为'true',指定分隔符'delimiter'是'\t'
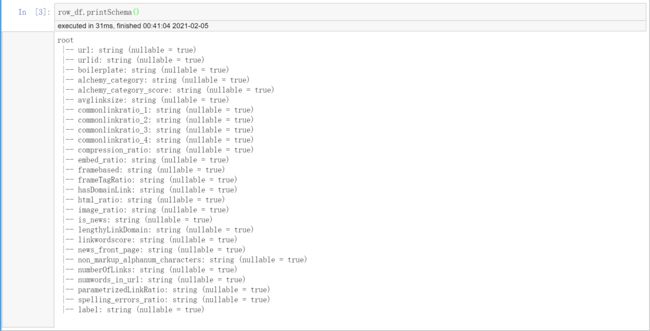
# 查看导入数据的Schema
row_df.printSchema()

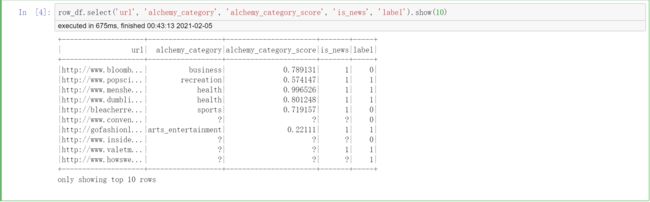
# 查看前十项数据
row_df.select('url', 'alchemy_category', 'alchemy_category_score', 'is_news', 'label').show(10)
# 由下图可以看到其中缺失值较多,所以我们接下来进行缺失值填充,用0填充。(你也可以采用其他方法)
# 编写UDF用户自定义函数,将?转换为0
from pyspark.sql.functions import udf
def replace_question(x):
return ('0' if x=='?' else x)
replace_question = udf(replace_question)
# 再导入相关模块
from pyspark.sql.functions import col
import pyspark.sql.types

# 进行转换
df = row_df.select(['url', 'alchemy_category'] + [replace_question(col(column)).cast('double').alias(column) for column in row_df.columns[4:]])
# 前两个字段不需要转换,然后对每一列用函数进行转换
# 查看转换后的Schema
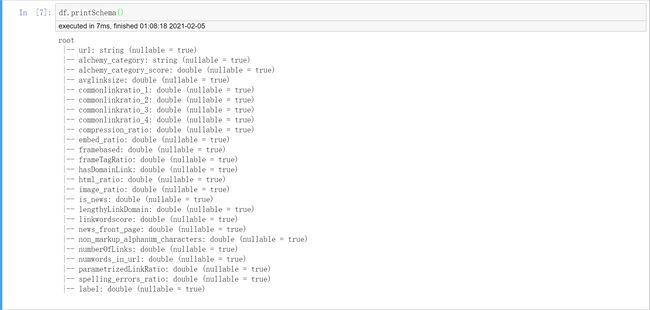
df.printSchema()
# 可以看到数值型数据都转换为double了
![]()
数据分割
# 将数据分成训练集和测试集,并持久化
train_df, test_df = df.randomSplit([0.7, 0.3])
train_df.cache()
test_df.cache()

机器学习pipeline流程组件
StringIndexer
# StringIndexer的功能类似于上篇文章说的categoriesMap,用于将字符串分类特征字段转换为数值。StringIndexer是一# 个'Estimator',所以使用上必须分为两个步骤:(1)使用fit方法传入参数DataFrame,产生一个'Transformer' (2)# 针对生成的'Transformer',使用transform方法将DataFrame转换成另一个DataFrame
# 导入模块
from pyspark.ml.feature import StringIndexer
# inputCol:要转换的字段名
# outputCol:转换后生成的字段名
categoryIndexer = StringIndexer(
inputCol='alchemy_category',
outputCol='alchemy_category_Index'
)
# 用df进行fit,就生成了类似categoariesMap字典的东西
categoryTransformer = categoryIndexer.fit(df)
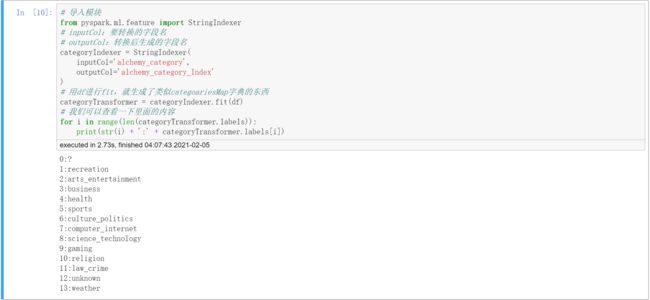
# 我们可以查看一下里面的内容
for i in range(len(categoryTransformer.labels)):
print(str(i) + ':' + categoryTransformer.labels[i])
# 接下来就可以利用categoaryTransformer将train_df转换成df1
df1 = categoryTransformer.transform(train_df)
# 打印出来看看
print(df1.columns)
# 可以看到最后多出一列是我们转换的输出
# 再把结果打印出来看看
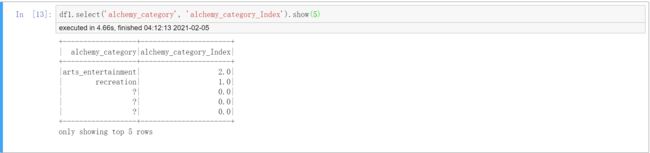
df1.select('alchemy_category', 'alchemy_category_Index').show(5)
# 可以看到字符都转换成了对应的数字

OneHotEncoding
# OneHotEncoding 类似sklearn和pandas的dummy,就是将一个数值的字段转换为多个字段的Vector。
# 导入模块
from pyspark.ml.feature import OneHotEncoder
encoder = OneHotEncoder(dropLast=False, inputCol='alchemy_category_Index', outputCol='alchemy_category_IndexVec')
df2 = encoder.transform(df1)
print(df2.columns)
# 可以看到最后多了输出一列
# 再把结果打印出来
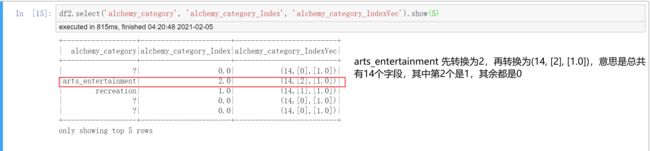
df2.select('alchemy_category', 'alchemy_category_Index', 'alchemy_category_IndexVec').show(5)
# 如图所示

VectorAssembler
# VectorAssembler 可以将多个特征字段整合成一个特征Vector
from pyspark.ml.feature import VectorAssembler
# 这里将所有要输入的特征字段全部集合到一起,即由字符字段刚刚生成的14个特征字段加上原来的全部数值型字段
assemblerInputs = ['alchemy_category_IndexVec'] + row_df.columns[4:-1]
print(assemblerInputs)
# 注意这里只是字段名集合在一起,数据并没有

# 将刚刚集合的特征字段作为输入列
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol='feature')
# 把数据代入进行转换
df3 = assembler.transform(df2)
print(df3.columns)
# 看到最后增加了新的一列

# 我们再来查看一下刚生成的feature字段
df3.select('feature').take(1)
# 如图,意思是,总共有36个字段,第0个字段是1.0,第15个字段是2.1446,第16个字段是0.7969等等,其余全是0。

Decision Tree Classifier
from pyspark.ml.classification import DecisionTreeClassifier
# labelCol参数指定标签列,featuresCol指定特征列(就是刚刚生成的特征Vector)
dt = DecisionTreeClassifier(labelCol='label', featuresCol='feature', impurity='gini', maxDepth=10, maxBins=14)
dt_model = dt.fit(df3)
print(dt_model)
# 有了model之后就可以transform
df4 = dt_model.transform(df3)

建立机器学习Pipeline流程
# 导入需要的模块
from pyspark.ml import Pipeline
from pyspark.ml.feature import StringIndexer, OneHotEncoder, VectorAssembler
from pyspark.ml.classification import DecisionTreeClassifier
# 建立Pipeline,将之前的组件集合起来
stringIndexer = StringIndexer(inputCol='alchemy_category', outputCol='alchemy_category_Index')
encoder = OneHotEncoder(dropLast=False, inputCol='alchemy_category_Index', outputCol='alchemy_category_IndexVec')
assemblerInputs = ['alchemy_category_IndexVec'] + row_df.columns[4:-1]
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol='feature')
dt = DecisionTreeClassifier(labelCol='label', featuresCol='feature', impurity='gini', maxDepth=10, maxBins=14)
# 创建pipeline,注意这里只是建立算法,还没有代入数据
pipeline = Pipeline(stages=(stringIndexer, encoder, assembler, dt))
# 我们可以查看管道的每一个阶段
pipeline.getStages()

# 代入数据进行训练生成模型
pipelineModel = pipeline.fit(train_df)
# 各个阶段以列表的形式存储在pipelineModel中,查看第3个
pipelineModel.stages[3]

# 还可以进一步查看决策树规则
print(pipelineModel.stages[3].toDebugString)
# 太多了,显示不全

使用pipelineModel进行预测
predicted = pipelineModel.transform(test_df)
print(predicted.columns)
# 最后三个字段是预测后生成的

# 仔细查看
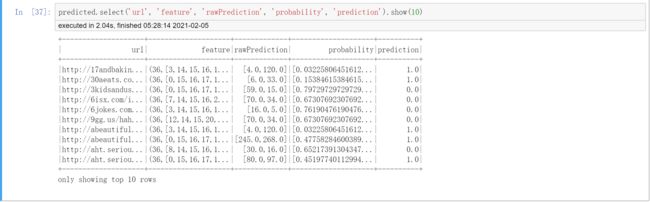
predicted.select('url', 'feature', 'rawPrediction', 'probability', 'prediction').show(10)
# rawPrediction在我们后续评估模型准确率时使用
# probability是预测结果是0和1的概率
# prediction是最后预测的结果
模型评估
# 导入模块
from pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluator = BinaryClassificationEvaluator(rawPredictionCol='rawPrediction', labelCol='label', metricName='areaUnderROC')
auc = evaluator.evaluate(predicted)
auc

使用crossValidation交叉验证找出最佳模型
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
# 建立参数列表
paramGrid = ParamGridBuilder().addGrid(dt.impurity, ['gini', 'entropy']).addGrid(dt.maxDepth, [5, 10, 15]).addGrid(dt.maxBins, [10, 15, 20]).build()
# 建立交叉验证器
# estimator 就是之前的Decision Tree Classifier
# evaluator 就是之前的模型评估方法
# estimatorParamMaps是参数列表
# numFolds 表示5折验证
cv = CrossValidator(estimator=dt, evaluator=evaluator, estimatorParamMaps=paramGrid, numFolds=5)
# 建立管道
cv_pipeline = Pipeline(stages=[stringIndexer, encoder, assembler, cv])
# 代入数据进行训练
cv_pipelineModel = cv_pipeline.fit(train_df)
# 找出最佳模型
bestModel = cv_pipelineModel.stages[3].bestModel
print(bestModel)
# 计算最佳模型的AUC
predictions = cv_pipelineModel.transform(test_df)
auc = evaluator.evaluate(predictions)
auc
