kaggle-员工离职预测
模型建立
1、逻辑回归
a、写法
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score,recall_score,precision_score,\
f1_score,roc_curve,auc,confusion_matrix
df = pd.read_csv(r'HR_comma_sep1.csv')
x=df.drop(['left'],axis=1)
y=df['left']
X_tt, X_test, Y_tt, Y_test = train_test_split(x,y , random_state=0, test_size=0.2)
#设定测试集为2/10
X_train, X_validation, Y_train, Y_validation = train_test_split(X_tt, Y_tt, random_state=1, test_size=0.25)
#设定训练集:验证集 = 3:1
print(len(X_train),len(X_validation), len(X_test))
best_auc = 0.0
for penalty in ['l1', 'l2']:
# for penalty in ['l2']:
for C in [0.1, 1, 10, 100]:
clf = LogisticRegression(penalty=penalty, C=C,solver='liblinear')
clf.fit(X_train, Y_train) #训练集训练
Y_pred_val = clf.predict(X_validation) #验证集调参
fpr,tpr,threshold = roc_curve(Y_validation, Y_pred_val)
if auc(fpr,tpr) > best_auc:
best_auc = auc(fpr,tpr)
best_parameters = {'penalty':penalty, 'C':C}
clf = LogisticRegression(**best_parameters) #使用最佳参数,构建新的模型
clf.fit(X_train, Y_train) #使用训练集训练调参后的模型
Y_pred = clf.predict(X_test) #测试集评估泛化能力
fpr_lr,tpr_lr,threshold = roc_curve(Y_test, Y_pred)
print("在验证集上AUC为: {:.3f}".format(best_auc))
print("所选参数: {}".format(best_parameters))
print("在测试集上AUC为: {:.3f}".format(auc(fpr_lr,tpr_lr)))
print('\n测试集的其他指标: ')
print('Accuracy rate : ' + str(accuracy_score(Y_test,Y_pred)))
print('Recall rate : ' + str(recall_score(Y_test,Y_pred)))
print('F1 score : ' + str(f1_score(Y_test,Y_pred)))
#混淆矩阵
print('Confusion Matrix : \n' + str(confusion_matrix(Y_test,Y_pred)))b、写法
from sklearn.linear_model import LogisticRegression
df = pd.read_csv(r'HR_comma_sep1.csv')
x=df.drop(['left'],axis=1)
y=df['left']
X_tt, X_test, Y_tt, Y_test = train_test_split(x,y , random_state=0, test_size=0.2)
#设定测试集为2/10
X_train, X_validation, Y_train, Y_validation = train_test_split(X_tt, Y_tt, random_state=1, test_size=0.25)
#设定训练集:验证集 = 3:1
print(len(X_train),len(X_validation), len(X_test))
lg = LogisticRegression()
lg.fit(X_train, Y_train)
# print("训练集准确率: ", lg.score(X_train, Y_train))
# print("测试集准确率: ", lg.score(X_test, Y_test))
lg=LogisticRegression(solver='saga')
lg.fit(X_train,Y_train)
y_predict=lg.predict(X_test)
print("训练集准确率",lg.score(X_train,Y_train))
print("测试集准确率",lg.score(X_test,Y_test))采用10折交叉验证 确定c的最优值
Cs = 10**np.linspace(-10, 10, 400)
lr_cv = LogisticRegressionCV(Cs=Cs, cv=10, penalty='l2', solver='saga', max_iter=10000, scoring='accuracy')
lr_cv.fit(X_train, Y_train)
print(lr_cv.C_)用最优值在验证集上进行预测
LR = LogisticRegression(solver='saga', penalty='l2', C=25.52908068)
print(LR.fit(X_train, Y_train))
print("训练集准确率: ", LR.score(X_train, Y_train))
print("验证集准确率: ", LR.score(X_validation, Y_validation))模型的准确率和召回率
from sklearn.metrics import classification_report
y_predict=LR.predict(X_test)
print("准确率",lg.score(X_train,Y_train))
print("召回率:",classification_report(Y_test,y_predict,target_names=["a","b"]))
2、朴素贝叶斯
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import classification_report
df = pd.read_csv(r'HR_comma_sep1.csv')
x=df.drop(['left'],axis=1)
y=df['left']
X_tt, X_test, Y_tt, Y_test = train_test_split(x,y , random_state=0, test_size=0.2)
#设定测试集为2/10
X_train, X_validation, Y_train, Y_validation = train_test_split(X_tt, Y_tt, random_state=1, test_size=0.25)
#设定训练集:验证集 = 3:1
print(len(X_train),len(X_validation), len(X_test))
gnb = GaussianNB()
gnb.fit(X_train, Y_train)
predict_gnb=gnb.predict(X_test)
print("朴素贝叶斯训练集准确率: ", gnb.score(X_train, Y_train))
print("测试集准确率: ", gnb.score(X_test, Y_test))
print('测试集召回率:',classification_report(Y_test,predict_gnb))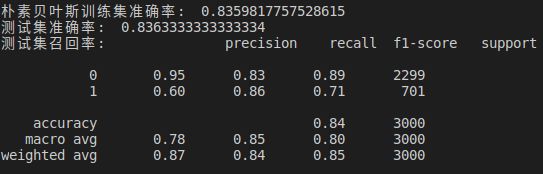
3、随机森林
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score,recall_score,precision_score,\
f1_score,roc_curve,auc,confusion_matrix
from sklearn.metrics import classification_report
df = pd.read_csv(r'HR_comma_sep1.csv')
x=df.drop(['left'],axis=1)
y=df['left']
X_tt, X_test, Y_tt, Y_test = train_test_split(x,y , random_state=0, test_size=0.2)
#设定测试集为2/10
X_train, X_validation, Y_train, Y_validation = train_test_split(X_tt, Y_tt, random_state=1, test_size=0.25)
#设定训练集:验证集 = 3:1
print(len(X_train),len(X_validation), len(X_test))
rf_true = RandomForestClassifier(n_estimators=100,max_depth=10,random_state=10,min_samples_split=10)
rf_true.fit(X_train,Y_train)
predict_final = rf_true.predict(X_validation)
print("随机森林训练集上的准确率:",rf_true.score(X_train,Y_train))
print("测试集准确率: ", rf_true.score(X_test, Y_test))
print("验证集准确率: ", rf_true.score(X_validation, Y_validation))
print('验证集召回率:',classification_report(Y_validation,predict_final))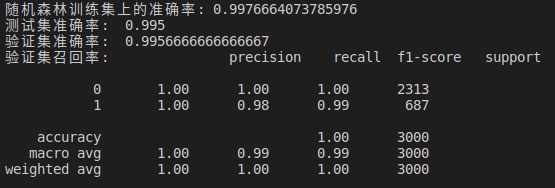
4、SVM
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn.svm import SVC
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score,recall_score,precision_score,\
f1_score,roc_curve,auc,confusion_matrix
df = pd.read_csv(r'HR_comma_sep1.csv')
x=df.drop(['left'],axis=1)
y=df['left']
X_tt, X_test, Y_tt, Y_test = train_test_split(x,y , random_state=0, test_size=0.2)
#设定测试集为2/10
X_train, X_validation, Y_train, Y_validation = train_test_split(X_tt, Y_tt, random_state=1, test_size=0.25)
#设定训练集:验证集 = 3:1
print(len(X_train),len(X_validation), len(X_test))
clf = SVC(kernel='rbf',gamma = 0.001, C=10)
clf.fit(X_train, Y_train) #使用训练集训练调参后的模型
Y_pred = clf.predict(X_test) #使用测试集评估泛化能力
# fpr_svm,tpr_svm,threshold = roc_curve(Y_test, Y_pred)
predict_final = clf.predict(X_test)
print("随机森林训练集上的准确率:",clf.score(X_train,Y_train))
print("测试集准确率: ", clf.score(X_test, Y_test))
print("验证集准确率: ", clf.score(X_validation, Y_validation))
print('验证集召回率:',classification_report(Y_validation,predict_final))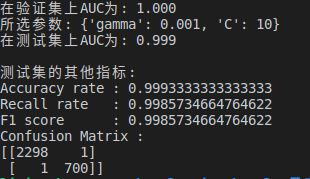
5、ROC曲线
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn.naive_bayes import GaussianNB
# from sklearn.metrics import classification_report
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score,recall_score,precision_score,\
f1_score,roc_curve,auc,confusion_matrix
df = pd.read_csv(r'HR_comma_sep1.csv')
x=df.drop(['left'],axis=1)
y=df['left']
X_tt, X_test, Y_tt, Y_test = train_test_split(x,y , random_state=0, test_size=0.2)
#设定测试集为2/10
X_train, X_validation, Y_train, Y_validation = train_test_split(X_tt, Y_tt, random_state=1, test_size=0.25)
#设定训练集:验证集 = 3:1
print(len(X_train),len(X_validation), len(X_test))
LR = LogisticRegression(solver='saga', penalty='l2', C=25.52908068)
LR.fit(X_train, Y_train)
print('LR')
gnb = GaussianNB()
gnb.fit(X_train, Y_train)
print('GNB')
rf_true = RandomForestClassifier(n_estimators=100,max_depth=10,random_state=10,min_samples_split=10)
rf_true.fit(X_train,Y_train)
print('RFtree')
best_auc = 0.0
for gamma in [0.001,0.01,0.1,1,10,100]:
for C in [0.001,0.01,0.1,1,10,100]:
clf = SVC(gamma=gamma, C=C)
clf.fit(X_train, Y_train) #训练集训练
Y_pred_val = clf.predict(X_validation) #验证集调参
fpr,tpr,threshold = roc_curve(Y_validation, Y_pred_val)
if auc(fpr,tpr) > best_auc:
best_auc = auc(fpr,tpr)
best_parameters = {'gamma':gamma, 'C':C}
clf = SVC(**best_parameters) #使用最佳参数,构建新的模型
clf.fit(X_train, Y_train)
print('SVM')
fpr_lg,tpr_lg,thresholds_lg = roc_curve(Y_test,LR.predict_proba(X_test)[:,1])
roc_auc_lg = auc(fpr_lg,tpr_lg)
print('1OK')
fpr_gnb,tpr_gnb,thresholds_gnb = roc_curve(Y_test,gnb.predict_proba(X_test)[:,1])
roc_auc_gnb = auc(fpr_gnb,tpr_gnb)
print('2OK')
fpr_svm , tpr_svm , thresholds_svm = roc_curve(Y_test , clf.predict_proba(X_test)[:,1])
roc_auc_svm = auc(fpr_svm , tpr_svm)
print('3OK')
fpr_tre_rf,tpr_tre_rf,thresholds_tre_rf = roc_curve(Y_test,rf_true.predict_proba(X_test)[:,1])
roc_auc_tre_rf = auc(fpr_tre_rf,tpr_tre_rf)
print('4OK')
## 绘制roc曲线图
plt.subplots(figsize=(7,5.5));
plt.plot(fpr_lg, tpr_lg, lw=2, label='LogisticRegression(area = %0.2f)' % roc_auc_lg);
plt.plot(fpr_gnb, tpr_gnb, lw=2, label='GaussianNB(area = %0.2f)' % roc_auc_gnb);
plt.plot(fpr_svm , tpr_svm , lw=2, label='SVM(area = %0.2f)' % roc_auc_svm);
plt.plot(fpr_tre_rf, tpr_tre_rf, lw=2, label='RFTree(area = %0.2f)' % roc_auc_tre_rf);
plt.plot([0, 1], [0, 1], color='navy',linestyle='--');
plt.xlim([0.0, 1.0]);
plt.ylim([0.0, 1.05]);
plt.xlabel('False Positive Rate');
plt.ylabel('True Positive Rate');
plt.title('ROC Curve');
plt.legend(loc="lower right");
plt.show()得到的ROC曲线
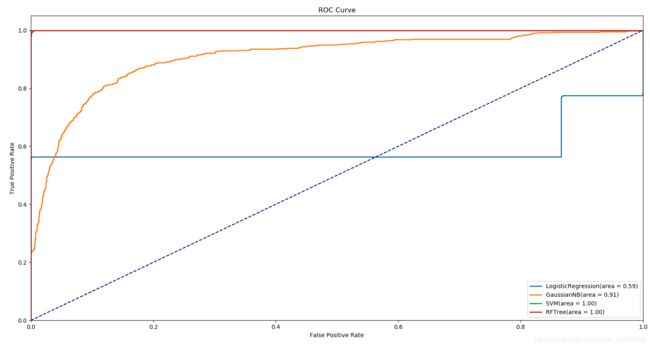
随机森林和SVM对比
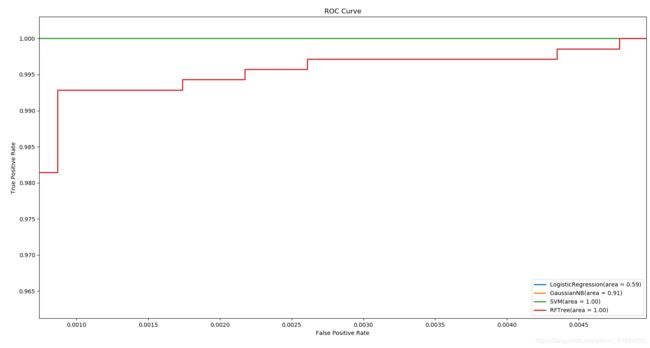
通过ROC曲线,SVM > 随机森林模型 > 朴素贝叶斯 > 逻辑回归 。
缺陷:该模型中决策树没有进行剪枝操作,可能会出现过拟合