【编译原理】第四章部分课后题答案
T 4.1
根据表4.1的语法制导定义,为输入表达式 5 ∗ ( 4 ∗ 3 + 2 ) 5*(4*3+2) 5∗(4∗3+2)构造注释分析树。
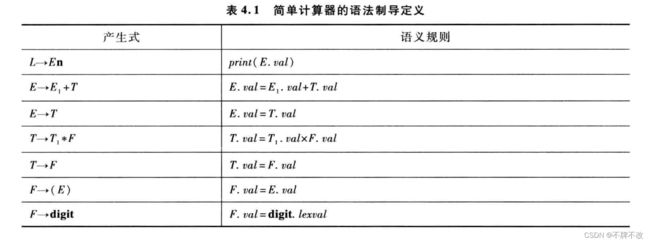
T 4.2
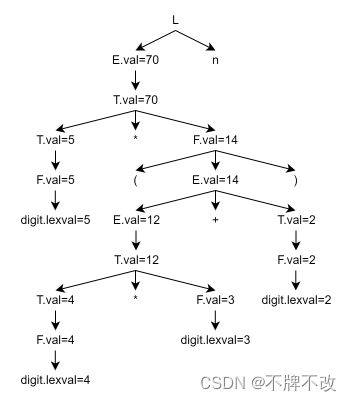
构造表达式 ( ( a ∗ b ) + ( c ) ) ((a*b)+(c)) ((a∗b)+(c))的分析树和语法树:
(a)根据表4.3的语法制导定义。

(b)根据图4.9的翻译方案。

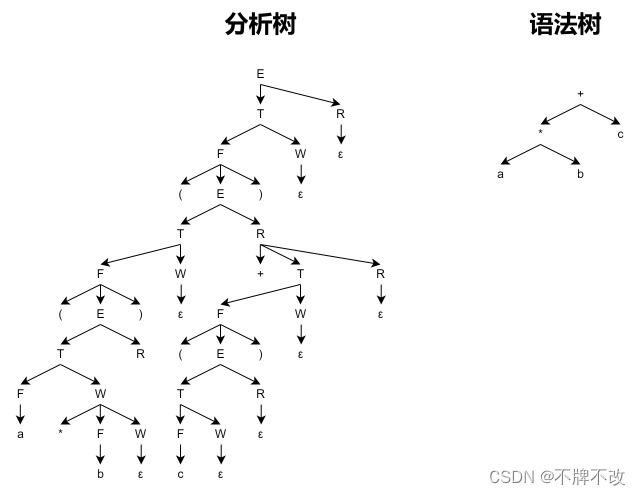
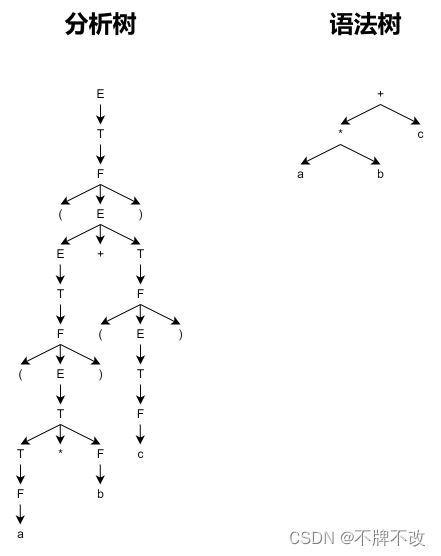
有关“分析树”和“语法树”:
语法分析树和语法树不是一种东西。习惯上,我们把前者叫做“具体语法树”,其能够体现推导的过程;后者叫做“抽象语法树”,其不体现过程,只关心最后的结果。
语法分析树的定义:
对于 CFG G 的句型,分析树被定义为具有下述性质的一棵树:
- 根由开始符号所标记;
- 每个叶子由一个终结符、非终结符或 ε 标记;
- 每个内部节点都是非终结符;
- 若 A A A 是某节点的内部标记,且 X 1 X_1 X1、 X 2 X_2 X2、…、 X n X_n Xn 是该节点从左到右的所有孩子的标记。则: A → X 1 X 2 . . . X n A\rightarrow X_1X_2...X_n A→X1X2...Xn 是一个产生式。若 A→ε,则标记为 A A A 的节点可以仅有一个标记为 ε ε ε 的孩子。若 A → ε A\rightarrow ε A→ε ,则标记为 A A A 的节点可以仅有一个标记为 ε ε ε 的孩子。
简而言之,利用产生式推导出句型G的过程以树的形式表现。
语法树的定义:
对于 CFG G 的句型,语法树被定义为具有下述性质的一棵树:
- 根与内部节点由表达式中的操作符标记;
- 叶子由表达式中的操作数标记;
- 用于改变运算优先级和结合性的括号,被隐含在语法树的结构中。
简而言之,叶子全是操作数,内部全是操作符,树里没有非终结符也不能有括号。
T 4.3
为文法
S → ( L ) ∣ a L → L , S ∣ S S\rightarrow(L)\space |\space a \\ L\rightarrow L,S\space|\space S S→(L) ∣ aL→L,S ∣ S
(a)写一个语法制导定义,它输出括号的对数。
S ′ → S n p r i n t ( S . v a l ) S → ( L ) S . v a l = L . v a l + 1 S → a S . v a l = 0 S → L , S 1 L . v a l = L . v a l + S 1 . v a l L → S L . v a l = S . v a l \left. \begin{array}{l} % 左对齐 S'\rightarrow S\textbf{n} && print(S.val) \\ S\rightarrow (L) && S.val = L.val + 1 \\ S\rightarrow a && S.val = 0 \\ S\rightarrow L,\space S_1 && \textcolor{red}{L.val = L.val + S_1.val} \\ L\rightarrow S && L.val = S.val \\ \end{array} \right. S′→SnS→(L)S→aS→L, S1L→Sprint(S.val)S.val=L.val+1S.val=0L.val=L.val+S1.valL.val=S.val
(b)写一个语法制导定义,它输出括号嵌套的最大深度。
S ′ → S n p r i n t ( S . v a l ) S → ( L ) S . v a l = L . v a l + 1 S → a S . v a l = 0 S → L , S 1 L . v a l = m a x ( L . v a l , S 1 . v a l ) L → S L . v a l = S . v a l \left. \begin{array}{l} % 左对齐 S'\rightarrow S\textbf{n} && print(S.val) \\ S\rightarrow (L) && S.val = L.val + 1 \\ S\rightarrow a && S.val = 0 \\ S\rightarrow L,\space S_1 && \textcolor{red}{L.val = max(L.val,S_1.val)} \\ L\rightarrow S && L.val = S.val \\ \end{array} \right. S′→SnS→(L)S→aS→L, S1L→Sprint(S.val)S.val=L.val+1S.val=0L.val=max(L.val,S1.val)L.val=S.val
红色部分为二者的不同之处。
T 4.4
下面的文法定义语言 L = { a n b n c m ∣ m , n ≥ 1 } L= \{a^n b^n c^m| m,n ≥1\} L={anbncm∣m,n≥1}。写一个语法制导定义,其语义规则的作用是:对不属于语言 L L L的子集 L 1 = { a n b n c n ∣ n ≥ 1 } L_1= \{a^n b^n c^n| n ≥1\} L1={anbncn∣n≥1}的句子,打印出错信息。
S → D C D → a D b ∣ a b C → C c ∣ c S\rightarrow DC\\ D\rightarrow aDb\space | \space ab \\ C\rightarrow Cc\space |\space c \\ S→DCD→aDb ∣ abC→Cc ∣ c
语法制导定义如下:
S → D C i f D . l e n g t h ≠ C . l e n g t h t h e n p r i n t ( ‘ ‘ e r r o r ” ) D → a b D . l e n g t h = 1 D → a D 1 b D . l e n g t h = D 1 . l e n g t h + 1 C → c D . l e n g t h = 1 C → C 1 c C . l e n g t h = C 1 . l e n g t h + 1 \left. \begin{array}{l} % 左对齐 S\rightarrow DC && if \space D.length ≠ C.length \space then \space print(``error”)\\ D\rightarrow ab && D.length = 1\\ D\rightarrow aD_1b && D.length = D_1.length + 1\\ C\rightarrow c && D.length = 1\\ C\rightarrow C_1c && C.length = C_1.length + 1\\ \end{array} \right. S→DCD→abD→aD1bC→cC→C1cif D.length=C.length then print(‘‘error”)D.length=1D.length=D1.length+1D.length=1C.length=C1.length+1
T 4.5
为下面文法写一个语法制导的定义,它完成一个句子的 w h i l e − d o while-do while−do最大嵌套层次的计算并输出这个计算结果。
S → E E → while E do E ∣ id : = E ∣ E + E ∣ id ∣ ( E ) S\rightarrow E \\ E\rightarrow \textbf{while}\space E \space \textbf{do} \space E \space |\space \textbf{id}:=E\space|\space E + E\space|\space \textbf{id} \space|\space(E) S→EE→while E do E ∣ id:=E ∣ E+E ∣ id ∣ (E)
语法制导定义如下:
S → E p r i n t ( S . l o o p ) E → while E 1 do E 2 E . l o o p = m a x ( E 1 . l o o p , E 2 . l o o p ) + 1 E → id : = E E . l o o p = E 1 . l o o p E → E 1 + E 2 E . l o o p = m a x ( E 1 . l o o p , E 2 . l o o p ) E → id E . l o o p = 0 E → ( E 1 ) E . l o o p : = E 1 . l o o p \left. \begin{array}{l} % 左对齐 S→E && print(S.loop) \\ E→ \textbf{while} E_1 \textbf{do} E_2 && E.loop = max(E_1.loop, E_2.loop)+1 \\ E→ \textbf{id}:=E && E.loop = E_1.loop \\ E→E_1+ E2 && E.loop = max(E_1.loop, E_2.loop) \\ E→ \textbf{id} && E.loop = 0\\ E→(E_1) && E.loop := E_1.loop \\ \end{array} % 左对齐 \right. S→EE→whileE1doE2E→id:=EE→E1+E2E→idE→(E1)print(S.loop)E.loop=max(E1.loop,E2.loop)+1E.loop=E1.loopE.loop=max(E1.loop,E2.loop)E.loop=0E.loop:=E1.loop
T 4.6
下列文法产生由 + + +作用于整常数或实常数的表达式。两个整数相加时,结果是整型,否则是实型。
E → E + T ∣ T T → num . num ∣ num E\rightarrow E+T\space | \space T \\ T\rightarrow\textbf{num}.\textbf{num}\space|\space\textbf{num} E→E+T ∣ TT→num.num ∣ num
( a)给出决定每个子表达式类型的语法制导定义。
E → E 1 + T i f ( E 1 . t y p e = = i n t e g e r ) a n d ( T . t y p e = = i n t e g e r ) t h e n E . t y p e = i n t e g e r e l s e E . t y p e = r e a l E → T E . t y p e = T . t y p e T → num . num T . t y p e = r e a l T → num T . t y p e = i n t e g e r \left. \begin{array}{l} % 左对齐 E\rightarrow E_1+T && if \space (E_1.type==integer)\space and\space(T.type==integer)\space then\\ && \space\space\space\space E.type=integer \\ &&else\\&& \space\space\space\space E.type = real \\ E\rightarrow T && E.type = T.type \\ T\rightarrow \textbf{num} . \textbf{num} && T.type = real \\ T\rightarrow \textbf{num} && T.type = integer \\ \end{array} \right. E→E1+TE→TT→num.numT→numif (E1.type==integer) and (T.type==integer) then E.type=integerelse E.type=realE.type=T.typeT.type=realT.type=integer
( b)扩充(a)的语法制导定义,既决定类型,又把表达式翻译成后缀表示。使用一元算符 i n t t o r e a l inttoreal inttoreal把整数变成等价的实数,使得后缀式中 + + +的两个对象有同样的类型。
E → E 1 + T i f ( E 1 . t y p e = = i n t e g e r ) a n d ( T . t y p e = = i n t e g e r ) t h e n E . t y p e = i n t e g e r p r i n t ( ′ + ′ , E 1 . v a l , T . v a l ) e l s e E . t y p e = r e a l i f E 1 . t y p e = i n t e g e r t h e n E 1 . t y p e = r e a l E 1 . v a l = i n t t o r e a l ( E 1 . v a l ) i f T . t y p e = i n t e g e r t h e n T . t y p e = r e a l T . v a l = i n t t o r e a l ( T . v a l ) p r i n t ( ′ + ′ , E 1 . v a l , T . v a l ) E → T E . t y p e = T . t y p e E . v a l = T . v a l T → num . num T . t y p e = r e a l T . v a l = num . num . l e x v a l T → num T . t y p e = i n t e g e r T . v a l = num . l e x v a l \left. \begin{array}{l} % 左对齐 E\rightarrow E_1+T && if \space (E_1.type==integer)\space and \space (T.type==integer)\space then \\ && \space\space\space\space E.type = integer \\ && \space\space\space\space print('+', E_1.val, T.val) \\ && else \\ && \space\space\space\space E.type=real \\ && \space\space\space\space if \space E_1.type = integer \space then \\ && \space\space\space\space\space\space\space\space E_1.type = real \\ && \space\space\space\space\space\space\space\space E_1.val = inttoreal(E_1.val) \\ && \space\space\space\space if \space T.type = integer \space then \\ && \space\space\space\space\space\space\space\space T.type = real \\ && \space\space\space\space\space\space\space\space T.val = inttoreal(T.val) \\ && \space\space\space\space print('+',E_1.val, T.val) \\ E\rightarrow T && E.type = T.type \\ && E.val = T.val \\ T\rightarrow \textbf{num}.\textbf{num} && T.type=real \\ && T.val = \textbf{num}.\textbf{num}.lexval \\ T\rightarrow \textbf{num} && T.type = integer \\ && T.val = \textbf{num}.lexval \\ \end{array} \right. E→E1+TE→TT→num.numT→numif (E1.type==integer) and (T.type==integer) then E.type=integer print(′+′,E1.val,T.val)else E.type=real if E1.type=integer then E1.type=real E1.val=inttoreal(E1.val) if T.type=integer then T.type=real T.val=inttoreal(T.val) print(′+′,E1.val,T.val)E.type=T.typeE.val=T.valT.type=realT.val=num.num.lexvalT.type=integerT.val=num.lexval
T 4.7
给出对表达式求导数的语法制导定义,表达式由 + + +和 ∗ * ∗作用于变量x和常数组成,如 x ∗ ( 3 ∗ x + x ∗ x ) x * (3 * x+ x *x) x∗(3∗x+x∗x),并假定没有任何化简,例如将 3 ∗ x 3*x 3∗x翻译成 3 ∗ 1 + 0 ∗ x 3*1+0*x 3∗1+0∗x。
经分析可知对每个文法符号需要有两个属性
- . e x p .exp .exp 用来记录原表达式
- . s .s .s 用来记录该表达式求导的结果
- ∣ ∣ || ∣∣ 用来表示串拼接
E ′ → E n p r i n t ( E . s ) E → E 1 + T E . e x p = E 1 . e x p ∣ ∣ ′ + ′ ∣ ∣ T . e x p E . s = E 1 . s ∣ ∣ ′ + ′ T . s E → T E . e x p = T . e x p E . s = T . s T → T 1 ∗ F T . e x p = T 1 . e x p ∣ ∣ ′ ∗ ′ F . e x p T . s = ′ ( ′ ∣ ∣ T 1 . s ∣ ∣ ′ ) ′ ∣ ∣ ′ ∗ ′ ∣ ∣ F . e x p ∣ ∣ ′ + ′ ∣ ∣ T . e x p ∣ ∣ ′ ∗ ′ ∣ ∣ F . s T → F T . e x p = F . e x p T . s = F . s F → ( E ) F . e x p = ′ ( ′ ∣ ∣ E . e x p ∣ ∣ ′ ) ′ F . s = ′ ( ′ ∣ ∣ E . s ∣ ∣ ′ ) ′ F → num F . e x p = num . l e x m e F . s = ′ 0 ′ F → x F . e x p = ′ x ′ F . s = ′ 1 ′ \left. \begin{array}{l} % 左对齐 E'\rightarrow E\textbf{n} && print(E.s) \\ E\rightarrow E_1+T && E.exp = E_1.exp\space||\space '+' \space || \space T.exp \\ && E.s = E_1.s\space ||\space '+'\space T.s \\ E\rightarrow T && E.exp = T.exp \\ && E.s = T.s \\ T\rightarrow T_1*F && T.exp = T_1.exp\space || \space '*' \space F.exp \\ && T.s = '('\space||\space T_1.s\space || \space ')'\space || \space '*' \space || \space F.exp\space ||\space '+' \space || \space T.exp \space ||\space '*' \space || \space F.s \\ T\rightarrow F && T.exp = F.exp \\ && T.s = F.s \\ F\rightarrow (E) && F.exp='('\space ||\space E.exp\space || \space ')' \\ && F.s = '('\space ||\space E.s\space|| \space ')' \\ F\rightarrow \textbf{num} && F.exp = \textbf{num}.lexme \\ && F.s = '0' \\ F\rightarrow\textbf{x}&& F.exp = '\textbf{x}' \\ && F.s = '\textbf{1}'\\ \end{array} \right. E′→EnE→E1+TE→TT→T1∗FT→FF→(E)F→numF→xprint(E.s)E.exp=E1.exp ∣∣ ′+′ ∣∣ T.expE.s=E1.s ∣∣ ′+′ T.sE.exp=T.expE.s=T.sT.exp=T1.exp ∣∣ ′∗′ F.expT.s=′(′ ∣∣ T1.s ∣∣ ′)′ ∣∣ ′∗′ ∣∣ F.exp ∣∣ ′+′ ∣∣ T.exp ∣∣ ′∗′ ∣∣ F.sT.exp=F.expT.s=F.sF.exp=′(′ ∣∣ E.exp ∣∣ ′)′F.s=′(′ ∣∣ E.s ∣∣ ′)′F.exp=num.lexmeF.s=′0′F.exp=′x′F.s=′1′
T 4.8
给出把中缀表达式翻译成没有冗余括号的中缀表达式的语法制导定义。例如,因为 + + +和 ∗ * ∗是左结合, ( ( a ∗ ( b + c ) ) ∗ ( d ) ) ((a * (b+c))*(d)) ((a∗(b+c))∗(d))可以重写成 a ∗ ( b + c ) ∗ d a* (b+c) * d a∗(b+c)∗d。
两种方法:
- 先把表达式的括号都去掉,然后在必要的地方再加括号
- 去掉表达式中的冗余括号,保留必要的括号
第一种方法:
- . e x p .exp .exp 用来记录表达式
- ∣ ∣ || ∣∣ 用来表示串拼接
S → E p r i n t ( E . e x p ) E → E 1 + T i f T . o p = = ′ + ′ t h e n E . e x p = E 1 . e x p ∣ ∣ ′ + ′ ∣ ∣ ′ ( ′ ∣ ∣ T . e x p ∣ ∣ ′ ) ′ e l s e E . e x p = E 1 . e x p ∣ ∣ ′ + ′ ∣ ∣ T . e x p E . o p = T . o p E → T E . e x p = T . e x p E . o p = T . o p T → T 1 ∗ F i f ( F . o p = = ′ + ′ ) o r ( F . o p = = ′ ∗ ′ ) t h e n i f T 1 . o p = = ′ + ′ t h e n T . e x p = ′ ( ′ ∣ ∣ T 1 . c o d e ∣ ∣ ′ ) ′ ∣ ∣ ′ ∗ ′ ∣ ∣ ′ ( ′ ∣ ∣ F . e x p ∣ ∣ ′ ) ′ e l s e T . e x p = T 1 . e x p ∣ ∣ ′ ∗ ′ ∣ ∣ ′ ( ′ ∣ ∣ F . e x p ∣ ∣ ′ ) ′ e l s e i f T 1 . o p = = ′ + ′ t h e n T . e x p = ′ ( ′ ∣ ∣ T 1 . e x p ∣ ∣ ′ ) ′ ∣ ∣ ′ ∗ ′ ∣ ∣ F . e x p e l s e T . e x p = T 1 . e x p ∣ ∣ ′ ∗ ′ ∣ ∣ F . e x p T . o p = ′ ∗ ′ T → F T . e x p = F . e x p T . o p = F . o p F → id F . e x p = id . l e x m e F . o p = id F → ( E ) F . e x p = E . e x p F . o p = E . o p \left. \begin{array}{l} % 左对齐 S\rightarrow E && print(E.exp) \\ E\rightarrow E_1+T && if \space T.op == '+' \space then \\ && \space\space\space\space E.exp = E_1.exp \space || \space '+'\space ||\space '(' \space || \space T.exp \space || \space ')' \\ && else \\ && \space\space\space\space E.exp = E_1.exp \space || \space '+'\space || \space T.exp \\ && E.op = T.op \\ E\rightarrow T && E.exp = T.exp \\ && E.op = T.op \\ T\rightarrow T_1*F && if \space (F.op == '+')\space or\space (F.op == '*')\space then \\ && \space\space\space\space if \space T_1.op == '+' \space then \\ && \space\space\space\space\space\space\space\space T.exp = '(' \space || \space T_1.code \space || \space ')'\space || \space '*' \space || \space '(' \space || \space F.exp \space || \space ')' \\ && \space\space\space\space else \\ && \space\space\space\space\space\space\space\space T.exp = T_1.exp \space || \space '*'\space || \space '(' \space || \space F.exp \space ||\space ')' \\ && else\space if\space T_1.op == '+' \space then \\ && \space\space\space\space T.exp = '(' \space || \space T_1.exp \space ||\space ')'\space || \space'*'\space || \space F.exp \\ && else \\ && \space\space\space\space T.exp = T_1.exp \space ||\space '*'\space || \space F.exp \\ && T.op = '*' \\ T\rightarrow F && T.exp = F.exp \\ && T.op = F.op \\ F\rightarrow \textbf{id} && F.exp = \textbf{id}.lexme \\ && F.op = \textbf{id} \\ F\rightarrow (E) && F.exp = E.exp \\ && F.op = E.op \\ \end{array} % 左对齐 \right. S→EE→E1+TE→TT→T1∗FT→FF→idF→(E)print(E.exp)if T.op==′+′ then E.exp=E1.exp ∣∣ ′+′ ∣∣ ′(′ ∣∣ T.exp ∣∣ ′)′else E.exp=E1.exp ∣∣ ′+′ ∣∣ T.expE.op=T.opE.exp=T.expE.op=T.opif (F.op==′+′) or (F.op==′∗′) then if T1.op==′+′ then T.exp=′(′ ∣∣ T1.code ∣∣ ′)′ ∣∣ ′∗′ ∣∣ ′(′ ∣∣ F.exp ∣∣ ′)′ else T.exp=T1.exp ∣∣ ′∗′ ∣∣ ′(′ ∣∣ F.exp ∣∣ ′)′else if T1.op==′+′ then T.exp=′(′ ∣∣ T1.exp ∣∣ ′)′ ∣∣ ′∗′ ∣∣ F.expelse T.exp=T1.exp ∣∣ ′∗′ ∣∣ F.expT.op=′∗′T.exp=F.expT.op=F.opF.exp=id.lexmeF.op=idF.exp=E.expF.op=E.op
第二种方法:
- 给 E E E、 T T T和 F F F两个继承属性 l e f t o p left_op leftop和 r i g h t o p right_op rightop分别表示左右两侧算符的优先级
- 给它们一个综合属性 s e l f o p self_op selfop表示自身主算符的优先级
- 再给一个综合属性 c o d e code code表示没有冗余括号的表达式
- 分别用1和2表示加和乘的优先级,用3表示 i d id id和 ( E ) (E) (E)的优先级,用0表示左侧或右侧没有运算对象的情况
S → E E . l e f t _ o p = 0 E . r i g h t _ o p = 0 p r i n t ( E . e x p ) E → E 1 + T E 1 . l e f t _ o p = E . l e f t _ o p E 1 . r i g h t _ o p = 1 T . l e f t _ o p = 1 T . r i g h t _ o p = E . r i g h t _ o p E . e x p = E 1 . e x p ∣ ∣ ′ + ′ ∣ ∣ T . e x p E . s e l f _ o p = 1 E → T T . l e f t _ o p = E . l e f t _ o p T . r i g h t _ o p = E . r i g h t _ o p E . e x p = T . e x p E . s e l f _ o p = T . s e l f _ o p T → T 1 ∗ F i f ( F . o p = = ′ + ′ ) o r ( F . o p = = ′ ∗ ′ ) t h e n i f T 1 . o p = = ′ + ′ t h e n T . e x p = ′ ( ′ ∣ ∣ T 1 . c o d e ∣ ∣ ′ ) ′ ∣ ∣ ′ ∗ ′ ∣ ∣ ′ ( ′ ∣ ∣ F . e x p ∣ ∣ ′ ) ′ e l s e T . e x p = T 1 . e x p ∣ ∣ ′ ∗ ′ ∣ ∣ ′ ( ′ ∣ ∣ F . e x p ∣ ∣ ′ ) ′ e l s e i f T 1 . o p = = ′ + ′ t h e n T . e x p = ′ ( ′ ∣ ∣ T 1 . e x p ∣ ∣ ′ ) ′ ∣ ∣ ′ ∗ ′ ∣ ∣ F . e x p e l s e T . e x p = T 1 . e x p ∣ ∣ ′ ∗ ′ ∣ ∣ F . e x p T . o p = ′ ∗ ′ T → F T . e x p = F . e x p T . o p = F . o p F → id F . e x p = id . l e x m e F . s e l f _ o p = 3 F → ( E ) E . l e f t _ o p = 0 E . r i g h t _ o p = 0 F . s e l f _ o p = i f ( F . l e f t _ o p < E . s e l f _ o p ) a n d ( E . s e l f _ o p > = F . r i g h t _ o p ) t h e n E . s e l f _ o p e l s e 3 F . e x p = i f ( F . l e f t _ o p < E . s e l f _ o p ) a n d ( E . s e l f _ o p > = F . r i g h t _ o p ) t h e n E . e x p e l s e ′ ( ′ ∣ ∣ E . e x p ∣ ∣ ′ ) ′ \left. \begin{array}{l} % 左对齐 S\rightarrow E && E.left\_op = 0 \\ && E.right\_op = 0 \\ && print(E.exp) \\ E\rightarrow E_1+T && E_1.left\_op=E.left\_op \\ && E_1.right\_op=1 \\ && T.left\_op = 1 \\ && T.right\_op = E.right\_op \\ && E.exp = E_1.exp \space || \space '+'\space || \space T.exp \\ && E.self\_op = 1 \\ E\rightarrow T && T.left\_op = E.left\_op \\ && T.right\_op = E.right\_op \\ && E.exp = T.exp \\ && E.self\_op = T.self\_op \\ T\rightarrow T_1*F && if \space (F.op == '+')\space or\space (F.op == '*')\space then \\ && \space\space\space\space if \space T_1.op == '+' \space then \\ && \space\space\space\space\space\space\space\space T.exp = '(' \space || \space T_1.code \space || \space ')'\space || \space '*' \space || \space '(' \space || \space F.exp \space || \space ')' \\ && \space\space\space\space else \\ && \space\space\space\space\space\space\space\space T.exp = T_1.exp \space || \space '*'\space || \space '(' \space || \space F.exp \space ||\space ')' \\ && else\space if\space T_1.op == '+' \space then \\ && \space\space\space\space T.exp = '(' \space || \space T_1.exp \space ||\space ')'\space || \space'*'\space || \space F.exp \\ && else \\ && \space\space\space\space T.exp = T_1.exp \space ||\space '*'\space || \space F.exp \\ && T.op = '*' \\ T\rightarrow F && T.exp = F.exp \\ && T.op = F.op \\ F\rightarrow \textbf{id} && F.exp = \textbf{id}.lexme \\ && F.self\_op=3 \\ F\rightarrow (E) && E.left\_op =0 \\ && E.right\_op = 0 \\ && F.self\_op = \\ && \space\space\space\space if \space (F.left\_op < E.self\_op) \space and \space (E.self\_op >= F.right\_op) \space then \\ && \space\space\space\space\space\space\space\space E.self\_op \\ && \space\space\space\space else \\ && \space\space\space\space\space\space\space\space 3 \\ && F.exp = \\ && \space\space\space\space if \space (F.left\_op < E.self\_op) \space and \space (E.self\_op >= F.right\_op) \space then \\ && \space\space\space\space\space\space\space\space E.exp \\ && \space\space\space\space else \\ && \space\space\space\space\space\space\space\space '('\space || \space E.exp \space || \space ')' \\ \end{array} % 左对齐 \right. S→EE→E1+TE→TT→T1∗FT→FF→idF→(E)E.left_op=0E.right_op=0print(E.exp)E1.left_op=E.left_opE1.right_op=1T.left_op=1T.right_op=E.right_opE.exp=E1.exp ∣∣ ′+′ ∣∣ T.expE.self_op=1T.left_op=E.left_opT.right_op=E.right_opE.exp=T.expE.self_op=T.self_opif (F.op==′+′) or (F.op==′∗′) then if T1.op==′+′ then T.exp=′(′ ∣∣ T1.code ∣∣ ′)′ ∣∣ ′∗′ ∣∣ ′(′ ∣∣ F.exp ∣∣ ′)′ else T.exp=T1.exp ∣∣ ′∗′ ∣∣ ′(′ ∣∣ F.exp ∣∣ ′)′else if T1.op==′+′ then T.exp=′(′ ∣∣ T1.exp ∣∣ ′)′ ∣∣ ′∗′ ∣∣ F.expelse T.exp=T1.exp ∣∣ ′∗′ ∣∣ F.expT.op=′∗′T.exp=F.expT.op=F.opF.exp=id.lexmeF.self_op=3E.left_op=0E.right_op=0F.self_op= if (F.left_op<E.self_op) and (E.self_op>=F.right_op) then E.self_op else 3F.exp= if (F.left_op<E.self_op) and (E.self_op>=F.right_op) then E.exp else ′(′ ∣∣ E.exp ∣∣ ′)′
T 4.9
用 S S S的综合属性 v a l val val给出下面文法中 S S S产生的二进制数的值。例如,输入 101.101 101.101 101.101时, S . v a l = 5.625 S. val=5.625 S.val=5.625。
S → L . L ∣ L L → L B ∣ B B → 0 ∣ 1 S\rightarrow L.L\space | \space L \\ L\rightarrow LB\space | \space B \\ B \rightarrow 0 \space | \space 1 \\ S→L.L ∣ LL→LB ∣ BB→0 ∣ 1
(a)仅用综合属性决定 S . v a l S. val S.val。
S → L 1 . L 2 S . v a l = L 1 . v a l + L 2 . v a l / p o w e r ( 2 , L 2 . l e n g t h ) S → L S . v a l = L . v a l L → L 1 B L . v a l = L 1. v a l ∗ 2 + B . v a l L . l e n g t h = L 1 . l e n g t h + 1 L → B L . v a l = B . v a l L . l e n g t h = 1 B → 0 B . v a l = 0 B → 1 B . v a l = 1 \left. \begin{array}{l} % 左对齐 S\rightarrow L_1.L_2 && S.val = L_1.val + L_2.val / power(2, L_2.length) \\ S\rightarrow L && S.val = L.val \\ L\rightarrow L_1B && L.val = L1.val * 2 + B.val \\ && L.length = L_1.length + 1 \\ L\rightarrow B && L.val = B.val \\ && L.length = 1 \\ B\rightarrow 0 && B.val = 0 \\ B\rightarrow 1 && B.val = 1 \\ \end{array} \right. S→L1.L2S→LL→L1BL→BB→0B→1S.val=L1.val+L2.val/power(2,L2.length)S.val=L.valL.val=L1.val∗2+B.valL.length=L1.length+1L.val=B.valL.length=1B.val=0B.val=1
(b)用 L L L属性定义决定 S . v a l S.val S.val。在该定义中, B B B的唯一综合属性是 c c c(还需要继承属性),它给出由 B B B产生的位对最终值的贡献。例如, 101.101 101.101 101.101的最前一位和最后一位对值 5.625 5.625 5.625的贡献分别是 4 4 4和 0.125 0.125 0.125。
先将文法改写为:
S → L . R ∣ L L → B L ∣ B R → R B ∣ B B → 0 ∣ 1 S\rightarrow L.R\space | \space L \\ L\rightarrow BL \space | \space B \\ R\rightarrow RB \space | \space B \\ B \rightarrow 0 \space | \space 1 \\ S→L.R ∣ LL→BL ∣ BR→RB ∣ BB→0 ∣ 1
所求语法制导定义如下,其中 i i i是 B B B的继承属性, v a l val val和 c c c是综合属性。
S → L . R S . v a l = L . v a l + R . v a l S → L S . v a l = L . v a l L → B L 1 B . i = L 1 . c ∗ 2 L . c = L 1 . c ∗ 2 L . v a l = L 1 . v a l + B . c L → B B . i = 1 L . c = 1 L . v a l = B . c R → R 1 B B . i = R 1 . c / 2 R . c = R 1 . c / 2 R . v a l = R 1 . v a l + B . c R → B B . i = 0.5 R . c = 0.5 R . v a l = B . c B → 0 B . c = 0 B → 1 B . c = B . i \left. \begin{array}{l} % 左对齐 S\rightarrow L.R && S.val=L.val + R.val \\ S\rightarrow L && S.val=L.val \\ L\rightarrow BL_1 && B.i = L_1.c*2 \\ && L.c = L_1.c*2 \\ && L.val = L_1.val+B.c \\ L\rightarrow B && B.i = 1 \\ && L.c = 1 \\ && L.val = B.c \\ R\rightarrow R_1B && B.i = R_1.c/2 \\ && R.c = R_1.c/2 \\ && R.val = R_1.val + B.c \\ R\rightarrow B B.i = 0.5 \\ && R.c = 0.5 \\ && R.val = B.c \\ B\rightarrow 0 && B.c = 0 \\ B\rightarrow 1 && B.c = B.i \\ \end{array} \right. S→L.RS→LL→BL1L→BR→R1BR→BB.i=0.5B→0B→1S.val=L.val+R.valS.val=L.valB.i=L1.c∗2L.c=L1.c∗2L.val=L1.val+B.cB.i=1L.c=1L.val=B.cB.i=R1.c/2R.c=R1.c/2R.val=R1.val+B.cR.c=0.5R.val=B.cB.c=0B.c=B.i
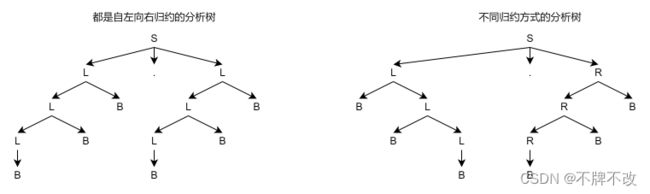
分析:首先,从 B B B推出的串是不可能知道这个 B B B在串中的具体位置的,因此也不可能计算它的贡献。这样 B B B必须有继承属性,它被用来计算 B B B的贡献。对于一个二进制数,如 101.101 101.101 101.101,对于小数点前的 1 1 1,我们需要知道它处在从右向左数的第几位上;而对于小数点后的 1 1 1,我们需要知道它处在从左向右数的第几位上。考察原来的文法,从下面左图的分析树可以看出,不管是小数点前还是后,它都是一种自左向右的归约,适合于自左向右地计数。这样,小数点左边就需要用继承属性来计数,这就增加了难度。而且,由于小数点左右都是用非终结符 L L L,那么, L L L就即要有综合属性来用于从自左向右地计数,又要有继承属性来用于自右向左地计数,显然语法制导定义的难度会大大增加。所以我们采用改写文法的办法,让分析树是右图的形式。这样,小数点两边的归约方式不一样,适合于不同方向的计数,使我们的语法制导定义能简洁得多。
T 4.10
重写例4.3语法制导定义的基础文法,然后重新设计语法制导定义,使得仅用综合属性就能把类型信息填入符号表。

改写后文法和语法制导定义为:
L → T id L . t y p e = T . t y p e a d d t y p e ( id . e n t r y , L . t y p e ) L → L 1 , id L . t y p e = L 1. t y p e a d d t y p e ( id . e n t r y , L . t y p e ) T → int T . t y p e = i n t e g e r T → real T . t y p e = real \left. \begin{array}{l} % 左对齐 L→T \textbf{id} && L.type = T.type \\ && addtype\space(\textbf{id}.entry, L.type) \\ L→L_1,\textbf{id} && L.type = L1.type\\ && addtype\space(\textbf{id}.entry, L.type) \\ T→\textbf{int} && T.type = integer \\ T→\textbf{real} && T.type = \textbf{real} \\ \end{array} \right. L→TidL→L1,idT→intT→realL.type=T.typeaddtype (id.entry,L.type)L.type=L1.typeaddtype (id.entry,L.type)T.type=integerT.type=real
T 4.12
文法如下:
S → ( L ) ∣ a L → L , S ∣ S S\rightarrow (L)\space | \space a \\ L\rightarrow L, S\space | \space S \\ S→(L) ∣ aL→L,S ∣ S
(a)写一个翻译方案,它输出每个 a a a的嵌套深度。例如,对于句子 ( a , ( a , a ) ) (a, (a,a)) (a,(a,a)),输出的结果是 1 2 2 1\space2\space2 1 2 2。
S ′ → { S . d e p t h = 0 } S S → { L . d e p t h = S . d e p t h + 1 } ( L ) S → a { p r i n t ( S . d e p t h ) } L → { L 1 . d e p t h = L . d e p t h } L 1 , { S . d e p t h = L . d e p t h } S L → { S . d e p t h = L . d e p t h } S \left. \begin{array}{l} % 左对齐 S'\rightarrow &&& \{S.depth=0\} \\ & S \\ S\rightarrow &&& \{L.depth = S.depth + 1\} \\ & (L) \\ S\rightarrow a &&& \{print(S.depth)\} \\ L\rightarrow &&& \{L_1.depth=L.depth\} \\ & L_1, && \{S.depth = L.depth\} \\ & S \\ L\rightarrow &&& \{S.depth = L.depth\} \\ & S \\ \end{array} \right. S′→S→S→aL→L→S(L)L1,SS{S.depth=0}{L.depth=S.depth+1}{print(S.depth)}{L1.depth=L.depth}{S.depth=L.depth}{S.depth=L.depth}
(b)写一个翻译方案,它打印出每个 a a a在句子中是第几个字符。例如,当句子是 ( a , ( a , ( a , a ) , ( a ) ) ) (a,(a,(a,a),(a))) (a,(a,(a,a),(a)))时,打印的结果是 2 5 8 10 14 2\space5\space8\space10\space14 2 5 8 10 14。
S ′ → { S . i n = 0 } S S → { L . i n = S . i n + 1 } ( L ) { S . o u t = L . o u t + 1 } S → a { S . o u t = S . i n + 1 ; p r i n t ( S . o u t ) } L → { L 1 . i n = L . i n } L 1 , { S . i n = L 1 . o u t + 1 } S { L . o u t = S . o u t } L → { S . i n = L . i n } S { L . o u t = S . o u t } \left. \begin{array}{l} % 左对齐 S'\rightarrow &&&\{S.in=0\} \\ & S \\ S\rightarrow &&& \{L.in=S.in+1\} \\ & (L) && \{S.out = L.out + 1\} \\ S\rightarrow & a && \{S.out = S.in+1;print(S.out)\} \\ L\rightarrow &&& \{L_1.in=L.in\} \\ & L_1, && \{S.in = L_1.out+1\} \\ & S && \{L.out= S.out\} \\ L\rightarrow &&& \{S.in = L.in\} \\ & S && \{L.out = S.out\} \\ \end{array} \right. S′→S→S→L→L→S(L)aL1,SS{S.in=0}{L.in=S.in+1}{S.out=L.out+1}{S.out=S.in+1;print(S.out)}{L1.in=L.in}{S.in=L1.out+1}{L.out=S.out}{S.in=L.in}{L.out=S.out}
T 4.13
语句的文法如下:
S → id : = E ∣ if E then S ∣ while E do S ∣ begin S ; S end ∣ break S →\textbf{id}:=E\space |\space \textbf{if}\space E \space \textbf{then}\space S \space |\space \textbf{while} \space E\space \textbf{do}\space S \space |\space \textbf{begin}\space S;S\space \textbf{end} \space |\space \textbf{break} S→id:=E ∣ if E then S ∣ while E do S ∣ begin S;S end ∣ break
写一个翻译方案,其语义动作的作用是:若发现break不是出现在循环语句中,及时报告错误。
S ′ → { S . l o o p = f a l s e } S S → id : = E S → if E then { S 1 . l o o p = S . l o o p } S 1 S → while E do { S 1 . l o o p = t r u e } S 1 S → begin { S 1 . l o o p = S . l o o p } S 1 ; { S 2 . l o o p = S . l o o p } S 2 end S → break { i f n o t S . l o o p t h e n p r i n t ( ′ e r r o r ′ ) } \left. \begin{array}{l} % 左对齐 S'\rightarrow &&& \{S.loop=false\} \\ &S \\ S\rightarrow & \textbf{id}:=E \\ S\rightarrow & \textbf{if}\space E \space \textbf{then} && \{S_1.loop = S.loop\} \\ & S_1 \\ S\rightarrow &\textbf{while} \space E\space \textbf{do} && \{S_1.loop=true\} \\ & S_1 \\ S\rightarrow & \textbf{begin} && \{S_1.loop = S.loop\}\\ & S_1; && \{S_2.loop=S.loop\}\\ & S_2\space \textbf{end} \\ S\rightarrow &\textbf{break} && \{if \space not \space S.loop \space then \space print('error')\} \end{array} \right. S′→S→S→S→S→S→Sid:=Eif E thenS1while E doS1beginS1;S2 endbreak{S.loop=false}{S1.loop=S.loop}{S1.loop=true}{S1.loop=S.loop}{S2.loop=S.loop}{if not S.loop then print(′error′)}
T 4.14
程序的文法如下:
P → D D → D ; D ∣ id : T ∣ proc id ; D ; S P→D \\ D→D;D \space | \space \textbf{id}:T \space | \space \textbf{proc} \space \textbf{id};D;S P→DD→D;D ∣ id:T ∣ proc id;D;S
(a)写一个语法制导定义,打印该程序一共声明了多少个 id \textbf{id} id。
s s s是 D D D的综合属性,用于 D D D中 id \textbf{id} id 的个数。
P → D p r i n t ( D . s ) D → D 1 ; D 2 p r i n t ( D . s = D 1 . s + D 2 . s ) D → id : T D . s = 1 D → proc id ; D 1 ; S D . s = D 1 . s + 1 \left. \begin{array}{l} % 左对齐 P\rightarrow D && print(D.s) \\ D\rightarrow D_1;D_2 && print(D.s = D_1.s+D_2.s) \\ D\rightarrow \textbf{id} : T && D.s = 1 \\ D\rightarrow \textbf{proc} \space \textbf{id};D_1;S && D.s = D_1.s + 1 \\ \end{array} \right. P→DD→D1;D2D→id:TD→proc id;D1;Sprint(D.s)print(D.s=D1.s+D2.s)D.s=1D.s=D1.s+1
(b)写一个翻译方案,打印该程序每个变量 id \textbf{id} id的嵌套深度。
i i i为 D D D的继承属性,用于计算 D D D所在的程序嵌套深度。
P → { D . i = 1 } D D → { D 1 . i = D . i } D 1 ; { D 2 . i = D . i } D 2 D → id : T { p r i n t ( D . i ) } D → proc id ; { D 1 . i = D . i + 1 } D 1 ; S \left. \begin{array}{l} % 左对齐 P\rightarrow &&& \{D.i = 1\} \\ & D \\ D\rightarrow &&& \{D_1.i = D.i\} \\ & D_1; && \{D_2.i = D.i\} \\ & D_2 \\ D\rightarrow & \textbf{id} : T && \{print(D.i)\} \\ D\rightarrow & \textbf{proc} \space \textbf{id}; && \{D_1.i = D.i + 1\} \\ & D_1;S\\ \end{array} \right. P→D→D→D→DD1;D2id:Tproc id;D1;S{D.i=1}{D1.i=D.i}{D2.i=D.i}{print(D.i)}{D1.i=D.i+1}