深度学习进行领域适应(Domain Adaptation)开山之作
来自:SimpleAI
论文标题:Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach
会议/期刊:ICML-2011
团队:Bengio那一伙儿
Domain adaptation的定义: 训练和测试在不一样的分布上的问题,就是领域适应问题。
常见场景: 在一个source domain上训练,但是需要部署到另一个domain上。
本文主要思想: 使用非监督式的深度学习方法,提取文本的高层次特征,然后使用这些特征进行分类。
一段话概括全文:
情感分类任务适用于多个领域,比如对图书的评论,对电影的评论,对电子产品的评论等等,针对不同的领域,都可以使用“积极”或“消极”来作为评论的标签。现在的场景是在一个领域上训练了一个情感分类模型,能否很好地在另一个领域进行预测?本文的主要想法是,先通过多层自编码器(Stacked Auto-encoder)对评论文本(各个领域的无标签数据)进行非监督训练,得到的编码器可以提取出评论文本的高层次特征(即可以用来转化原始文本),然后使用SVM进行分类。实验表明这种方法相比于传统的方法,使用auto-encoder转化后的特征可以训练出更好的模型,迁移到另一个领域的损失大大降低。
论文要点一览:
1. 数据集
本文使用了一个Amazon的商品评论数据集,分为大小两个版本,大的分布不均衡,小的人为构造的类别均衡。同时还有很多的无标签数据,可用于进行非监督训练。
2. 使用多层降噪自编码器来训练特征提取器
Stacked Denoising Auto-encoder(SDA)这个玩意儿,主要就是“压缩-解压”网络,训练的过程就是要让解压后的重构损失最小。简单地可以表示为r(x) = g(h(x)),然后最小化loss(x, r(x))。因此,auto-encoder的训练完全可以是无监督的,自己训练自己,挺有意思的。

训练完后的auto-encoder,可以单独拿其encoder的部分,作为一个特征提取器(或者降维工具),提取样本的重要特征。
3. 本文提出的是一个two-step的方法
第一步是通过SDA来对数据特征进行转化;
第二步是对转化后的特征,使用常用的模型(比如本文中的SVM)进行分类。
4. in-domain error,transfer error和transfer loss
这些都是为了评价各种方法/模型在domain adaptation上的效果。
in-domain error :在target领域上训练和测试的test error. 然后使用baseline模型的test error,记为
transfer error :在source S上训练,然后在target domain上进行测试的test error
transfer loss : ,就是transfer error减去本身在target上就有的一个误差。这样就消去了target domain本身的影响。
下图展示了实验结果,其中SDA就是文本的方法。可以看出其transfer loss基本都是最低的。有几个甚至是负值,说明了在那些任务上,transfer的error,比原本的in-domain的error都要低。(虽然这种做法我并不认为这能说明什么,因为 是使用原始的特征进行测试的,而SDA是使用转化后的特征)
5. 通过SDA的转化,两个domain之间的A-distance反而拉大了。所以按照一些理论,transfer的效果应该更差,但是论文的实验结果表明transfer的预测效果是更好的。
这是一个值得探究的地方,差点让这个论文自相矛盾。
所谓的A-distance是一个衡量两个分布之间相似度的一个指标。如下图所示:横坐标是经过转化后的A-dist,纵坐标是原始的A-dist,各个点就是各种不同的迁移任务。这些点都在对角线的右下方,说明A-dist在经过SDA转化后变大了。

针对这种尴尬的状况,作者的解释是,是不是因为SDA把原本特征中,领域相关的特征(domain-specific info)与情感极性的特征(sentiment polarity info)给解耦了,也就是把“通用的”特征和“个性化”的特征给分开了,相当于把那些的个性的、特殊的特征更加突出了,因此不同domain的特征就更不相似了(解释的好牵强???)。
为了验证作者的这个猜想,他们继续做了一些实验,即想办法挑出情感分类任务和领域识别任务中的那些重要特征,看看这些特征在两种不同的任务上的重叠程度。提取重要特征则是通过使用L1正则项的SVM来完成(L1范数常用于训练一个稀疏的模型,从而得到最重要的那些特征)。实验结果见下面这个热力图:
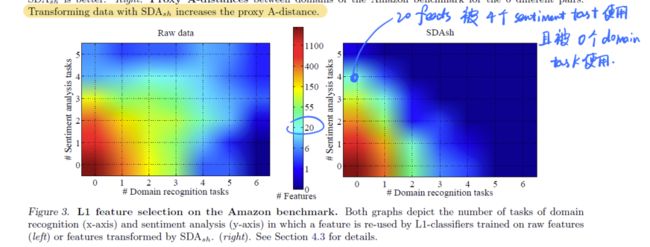
这个图上的每个点代表,有多少的特征,被m个domain recognition任何和n个sentiment classification任务同时使用。同时使用的越多,说明特征越耦合在一块儿。图中左下方亮度越高,就代表耦合程度越低。因此经过SDA转化之后的特征,确实降低了特征耦合的程度。
后记:
这个文章,毕竟是2011的工作,不能拿2021的视角来看,否则看完之后一定会问,这里用SDA进行特征提取有啥好的?用一个预训练好的bert难道不是更好吗?而且这个还是无监督的,分两步的,所以无论从精确程度还是方便程度,都其实一般般。但这个工作,在2011年这个深度学习还没有被广泛应用的年代,依然是开创性的,让人看到了深度学习模型的种种可能,比如强大的特征提取能力,这一点在文章最后探究特征解耦的这一块尤其让人感到惊讶。在这篇文章之后,诞生了许许多多使用深度学习方法进行domain adaptation的工作,所以,也是开启了一扇重要的门了。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心![]() 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
点击上面卡片,关注我呀,每天推送AI技术干货~
整理不易,还望给个在看!