卷积-池化-激活
文章目录
- 01 实现卷积-池化-激活
-
- 1.1 python实现
- 1.2 Torch 实现
- 1.3 实验结果
- 02 图像可视化
-
- 2.1 原图像
- 2.2 卷积核
- 2.3 特征图
- 2.4 卷积+relu后的特征图
- 2.5 实验源码
- 03 总结
- Reference
01 实现卷积-池化-激活
CNN 会比较图片里的各个局部信息。在相似的位置上进行特征特征比对,会更好地分辨两张图片是否相同。
- 卷积
CNN提取局部信息的方式是通过卷积来实现的。具体的操作流程为- 对于位置做乘法,得到 9 个值
- 9 个值进行相加
- 得到的值在除以 9
eg:
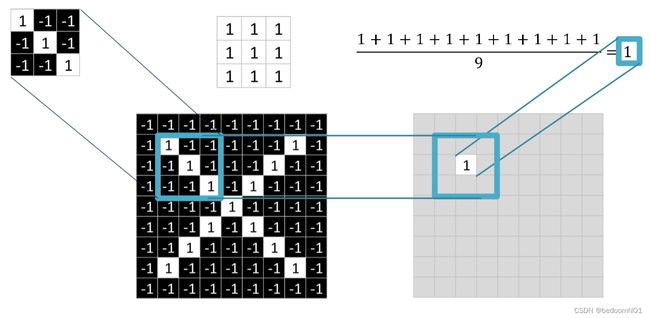
-
池化
池化层的主要作用是压缩特征,或者说是降低维度。当数据的维度比较高时,计算难度会急剧上升,可以通过降低维度的方法来降低所需算力。
步骤:- 选择窗口大小 (usually 2 or 3).
- 选择间隔 (usually 2).
- 使用窗口遍历特征图.
- 每个窗口取最大值.
此时大图就变小了。
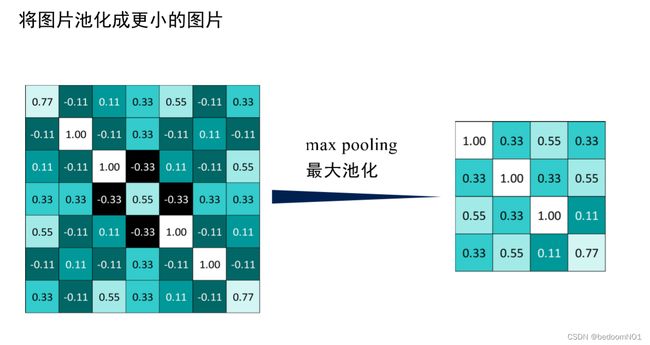
-
激活
激活层的作用是微调数据,避免梯度消失。
eg: ReLU()

1.1 python实现
import numpy as np
x = np.array([[-1, -1, -1, -1, -1, -1, -1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, -1, -1, 1, -1, -1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, -1, -1, -1, -1, -1, -1, -1]])
print("x=\n", x)
# 初始化卷积核
Kernel = [[0 for i in range(0, 3)] for j in range(0, 3)]
Kernel[0] = np.array([[1, -1, -1], [-1, 1, -1], [-1, -1, 1]])
Kernel[1] = np.array([[1, -1, 1], [-1, 1, -1], [1, -1, 1]])
Kernel[2] = np.array([[-1, -1, 1], [-1, 1, -1], [1, -1, -1]])
print(Kernel)
# -----------卷积-----------
stride = 1
feature_map_h = 7
feature_map_w = 7
feature_map = [0 for i in range(0, 3)]
for i in range(0, 3):
feature_map[i] = np.zeros((feature_map_h, feature_map_w))
for h in range(feature_map_h):
for w in range(feature_map_w):
v_start = h * stride
v_end = v_start + 3
h_start = w * stride
h_end = h_start + 3
window = x[v_start:v_end, h_start:h_end]
for i in range(0, 3):
feature_map[i][h, w] = np.divide(np.sum(np.multiply(window, Kernel[i])), 9)
print(np.around(feature_map, decimals=2))
# -------------池化--------------
pooling_stride = 2
pooling_h = 4
pooling_w = 4
feature_map_pad_0 = [0 for j in range(0, 3)]
for i in range(0, 3):
feature_map_pad_0[i] = np.pad(feature_map[i], ((0, 1), (0, 1)), 'constant',\
constant_values = (0, 0))
print("feature_map_pad_0 0:\n", np.around(feature_map_pad_0[0], decimals=2))
pooling = [0 for i in range(0, 3)]
for i in range(0, 3):
pooling[i] = np.zeros((pooling_h, pooling_w)) # 初始化特征图
for h in range(pooling_h): # 向下滑动,得到卷积后的固定行
for w in range(pooling_w): # 向右滑动,得到卷积后的固定行的列
v_start = h * pooling_stride # 滑动窗口的起始行(高)
v_end = v_start + 2 # 滑动窗口的结束行(高)
h_start = w * pooling_stride # 滑动窗口的起始列(宽)
h_end = h_start + 2 # 滑动窗口的结束列(宽)
for i in range(0, 3):
pooling[i][h, w] = np.max(feature_map_pad_0[i][v_start:v_end, h_start:h_end])
print("pooling[0]:\n", np.around(pooling[0], decimals=2))
print("pooling[1]:\n", np.around(pooling[1], decimals=2))
print("pooling[2]:\n", np.around(pooling[2], decimals=2))
1.2 Torch 实现
import numpy as np
import torch
import torch.nn as nn
x = torch.tensor([[[[-1, -1, -1, -1, -1, -1, -1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, -1, -1, 1, -1, -1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, -1, -1, -1, -1, -1, -1, -1]]]], dtype=torch.float)
print(x.shape)
print(x)
print("--------------- 卷积 ---------------")
conv1 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv1.weight.data = torch.Tensor([[[[1, -1, -1],
[-1, 1, -1],
[-1, -1, 1]]
]])
conv2 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv2.weight.data = torch.Tensor([[[[1, -1, 1],
[-1, 1, -1],
[1, -1, 1]]
]])
conv3 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv3.weight.data = torch.Tensor([[[[-1, -1, 1],
[-1, 1, -1],
[1, -1, -1]]
]])
feature_map1 = conv1(x)
feature_map2 = conv2(x)
feature_map3 = conv3(x)
print(feature_map1 / 9)
print(feature_map2 / 9)
print(feature_map3 / 9)
print("--------------- 池化 ---------------")
max_pool = nn.MaxPool2d(2, padding=0, stride=2) # Pooling
zeroPad = nn.ZeroPad2d(padding=(0, 1, 0, 1)) # pad 0 , Left Right Up Down
feature_map_pad_0_1 = zeroPad(feature_map1)
feature_pool_1 = max_pool(feature_map_pad_0_1)
feature_map_pad_0_2 = zeroPad(feature_map2)
feature_pool_2 = max_pool(feature_map_pad_0_2)
feature_map_pad_0_3 = zeroPad(feature_map3)
feature_pool_3 = max_pool(feature_map_pad_0_3)
print(feature_pool_1.size())
print(feature_pool_1 / 9)
print(feature_pool_2 / 9)
print(feature_pool_3 / 9)
print("--------------- 激活 ---------------")
activation_function = nn.ReLU()
feature_relu1 = activation_function(feature_map1)
feature_relu2 = activation_function(feature_map2)
feature_relu3 = activation_function(feature_map3)
print(feature_relu1 / 9)
print(feature_relu2 / 9)
print(feature_relu3 / 9)
1.3 实验结果
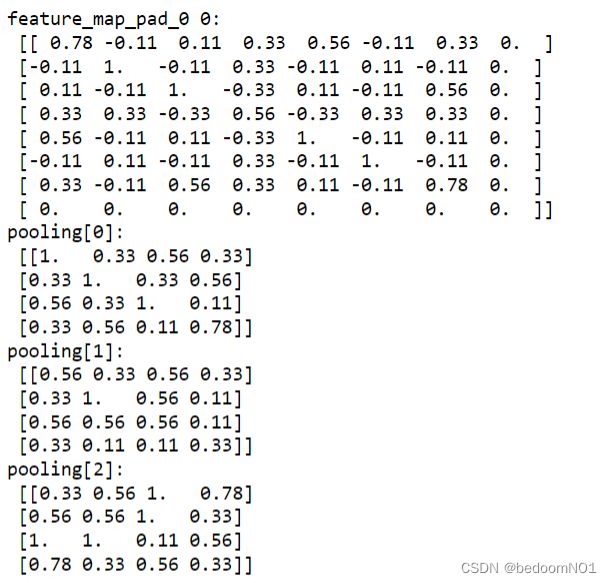
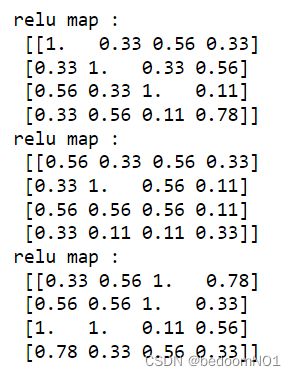
02 图像可视化
2.1 原图像
[-1., -1., -1., -1., -1., -1., -1., -1., -1.],
[-1., 1., -1., -1., -1., -1., -1., 1., -1.],
[-1., -1., 1., -1., -1., -1., 1., -1., -1.],
[-1., -1., -1., 1., -1., 1., -1., -1., -1.],
[-1., -1., -1., -1., 1., -1., -1., -1., -1.],
[-1., -1., -1., 1., -1., 1., -1., -1., -1.],
[-1., -1., 1., -1., -1., -1., 1., -1., -1.],
[-1., 1., -1., -1., -1., -1., -1., 1., -1.],
[-1., -1., -1., -1., -1., -1., -1., -1., -1.]

2.2 卷积核
# 卷积核 1
[[ 1, -1, -1],
[-1, 1, -1],
[-1, -1, 1]]
# 卷积核 2
[[ 1, -1, 1],
[-1, 1, -1],
[ 1, -1, 1]]
# 卷积核 3
[[-1, -1, 1],
[-1, 1, -1],
[ 1, -1, -1]]
| 图像 | |
|---|---|
| 卷积核 1 |  |
| 卷积核 2 |  |
| 卷积核 3 |  |
2.3 特征图
# 1
[[ 0.78 -0.11 0.11 0.33 0.56 -0.11 0.33]
[-0.11 1. -0.11 0.33 -0.11 0.11 -0.11]
[ 0.11 -0.11 1. -0.33 0.11 -0.11 0.56]
[ 0.33 0.33 -0.33 0.56 -0.33 0.33 0.33]
[ 0.56 -0.11 0.11 -0.33 1. -0.11 0.11]
[-0.11 0.11 -0.11 0.33 -0.11 1. -0.11]
[ 0.33 -0.11 0.56 0.33 0.11 -0.11 0.78]]
# 2
[[ 0.78 -0.11 0.11 0.33 0.56 -0.11 0.33]
[-0.11 1. -0.11 0.33 -0.11 0.11 -0.11]
[ 0.11 -0.11 1. -0.33 0.11 -0.11 0.56]
[ 0.33 0.33 -0.33 0.56 -0.33 0.33 0.33]
[ 0.56 -0.11 0.11 -0.33 1. -0.11 0.11]
[-0.11 0.11 -0.11 0.33 -0.11 1. -0.11]
[ 0.33 -0.11 0.56 0.33 0.11 -0.11 0.78]]
# 3
[[ 0.33 -0.11 0.56 0.33 0.11 -0.11 0.78]
[-0.11 0.11 -0.11 0.33 -0.11 1. -0.11]
[ 0.56 -0.11 0.11 -0.33 1. -0.11 0.11]
[ 0.33 0.33 -0.33 0.56 -0.33 0.33 0.33]
[ 0.11 -0.11 1. -0.33 0.11 -0.11 0.56]
[-0.11 1. -0.11 0.33 -0.11 0.11 -0.11]
[ 0.78 -0.11 0.11 0.33 0.56 -0.11 0.33]]
| 图像 | |
|---|---|
| 特征图 1 |  |
| 特征图 2 |  |
| 特征图 3 |  |
2.4 卷积+relu后的特征图
#relu map[0]:
[[1. 0.33 0.56 0.33]
[0.33 1. 0.33 0.56]
[0.56 0.33 1. 0.11]
[0.33 0.56 0.11 0.78]]
# relu map[1]:
[[0.56 0.33 0.56 0.33]
[0.33 1. 0.56 0.11]
[0.56 0.56 0.56 0.11]
[0.33 0.11 0.11 0.33]]
# relu map[2]:
[[0.33 0.56 1. 0.78]
[0.56 0.56 1. 0.33]
[1. 1. 0.11 0.56]
[0.78 0.33 0.56 0.33]]
| 图像 | |
|---|---|
| 卷积+relu后图 1 |  |
| 卷积+relu后图 2 |  |
| 卷积+relu后图 3 |  |
2.5 实验源码
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 #有中文出现的情况,需要u'内容
x = torch.tensor([[[[-1, -1, -1, -1, -1, -1, -1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, -1, -1, 1, -1, -1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, -1, -1, -1, -1, -1, -1, -1]]]], dtype=torch.float)
print(x.shape)
print(x)
img = x.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('原图')
plt.show()
print("--------------- 卷积 ---------------")
conv1 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv1.weight.data = torch.Tensor([[[[1, -1, -1],
[-1, 1, -1],
[-1, -1, 1]]
]])
img = conv1.weight.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('Kernel 1')
plt.show()
conv2 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv2.weight.data = torch.Tensor([[[[1, -1, 1],
[-1, 1, -1],
[1, -1, 1]]
]])
img = conv2.weight.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('Kernel 2')
plt.show()
conv3 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv3.weight.data = torch.Tensor([[[[-1, -1, 1],
[-1, 1, -1],
[1, -1, -1]]
]])
img = conv3.weight.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('Kernel 3')
plt.show()
feature_map1 = conv1(x)
feature_map2 = conv2(x)
feature_map3 = conv3(x)
print(feature_map1 / 9)
print(feature_map2 / 9)
print(feature_map3 / 9)
img = feature_map1.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('卷积后的特征图1')
plt.show()
print("--------------- 池化 ---------------")
max_pool = nn.MaxPool2d(2, padding=0, stride=2) # Pooling
zeroPad = nn.ZeroPad2d(padding=(0, 1, 0, 1)) # pad 0 , Left Right Up Down
feature_map_pad_0_1 = zeroPad(feature_map1)
feature_pool_1 = max_pool(feature_map_pad_0_1)
feature_map_pad_0_2 = zeroPad(feature_map2)
feature_pool_2 = max_pool(feature_map_pad_0_2)
feature_map_pad_0_3 = zeroPad(feature_map3)
feature_pool_3 = max_pool(feature_map_pad_0_3)
print(feature_pool_1.size())
print(feature_pool_1 / 9)
print(feature_pool_2 / 9)
print(feature_pool_3 / 9)
img = feature_pool_1.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('卷积池化后的特征图1')
plt.show()
print("--------------- 激活 ---------------")
activation_function = nn.ReLU()
feature_relu1 = activation_function(feature_map1)
feature_relu2 = activation_function(feature_map2)
feature_relu3 = activation_function(feature_map3)
print(feature_relu1 / 9)
print(feature_relu2 / 9)
print(feature_relu3 / 9)
img = feature_relu1.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('卷积 + relu 后的特征图1')
plt.show()
03 总结
如果直接将图像数据做成一个向量,然后作为输入数据,会丢失掉图像本身所包含的空间信息,效果不好。CNN采用的是局部匹配的思想,来尽可能多的保留图像所蕴含的空间信息,CNN在图像识别上比之前的神经网络会效果更好。
Reference
【2021-2022 春学期】人工智能-作业5:卷积-池化-激活 - HBU_DAVID - CSDN