详解何恺明团队最新作品:源于Facebook AI的RegNet
2020-06-18 14:50:24
机器之心转载
来源:计算机视觉研究院
作者:Edison_G
前段时间,何恺明组的研究者提出了一种新的网络设计范式。与以往研究不同,他们没有专注于设计单个网络实例,而是设计出了参数化网络群的网络设计空间。这种新的网络设计范式综合了手工设计网络和神经架构搜索(NAS)的优点。在类似的条件下,他们设计出的网络超越了当前表现最佳的 EfficientNet 模型,在 GPU 上实现了 5 倍的加速。本文是对这一论文的详细解读。

论文链接:
https://arxiv.org/pdf/2003.13678.pdf
在之前的介绍中,我们说到了 AnyNet 的设计空间,先回顾下:AnyNet 设计空间。我们的重点是探索假定标准的固定网络块 (例如,剩余瓶颈块) 的神经网络结构。在我们的术语中,网络的结构包括一些元素,如块的数量 (即网络深度)、块的宽度(即通道的数量) 和其他块的参数(如瓶颈比率或组的宽度)。网络的结构决定了计算、参数和内存在整个网络计算图中的分布,是决定其准确性和效率的关键。
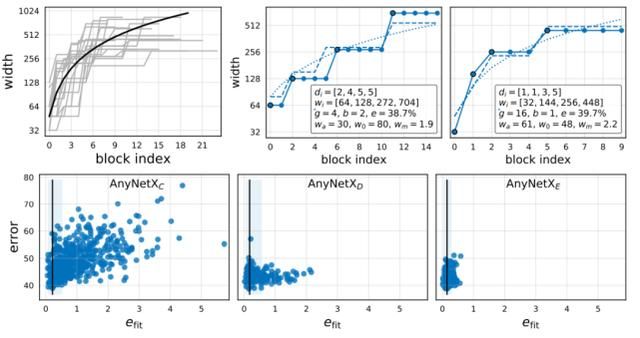
我们现在将这种方法应用于 AnyNetX 设计空间。
AnyNetXA
为了清晰起见,我们将最初的、不受约束的 AnyNetX 设计空间称为 AnyNetXA。
AnyNetXB
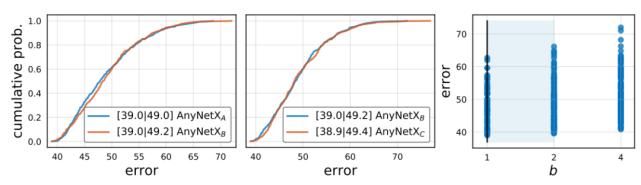
我们首先测试 AnyNetXA 设计空间的所有阶段 i 的共享瓶颈比 bi = b,并将得到的设计空间称为 AnyNetXB。与之前一样,我们在相同的设置下从 AnyNetXB 取样和培训了 500 个模型。如下图 (左) 所示,AnyNetXA 和 AnyNetXB 的 edf 在平均情况和最佳情况下实际上是相同的。这表示在耦合 bi 时没有精度损失。除了更简单之外,AnyNetXB 更易于分析,参见下图(右侧)。
AnyNetXC
我们的第二个细化步骤紧跟着第一个步骤。从 AnyNetXB 开始,我们还为所有阶段使用共享的组宽度 gi = g 来获得 AnyNetXC。与前面一样,EDFs 几乎没有变化,请参见上图(中间)。
总的来说,AnyNetXC 比 AnyNetXA 少了 6 个自由度,并且减少了近 4 个数量级的设计空间大小。有趣的是,我们发现 g > 1 是最好的(没有显示); 我们将在后面对此进行更详细的分析。
AnyNetXD
接下来,我们将研究下图中 AnyNetXC 中好的和坏的网络的典型网络结构。

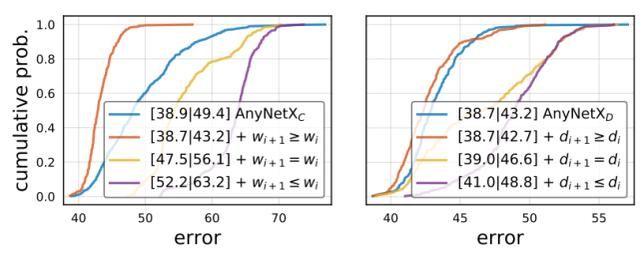
一种模式出现了: 良好的网络具有不断增长的宽度。我们测试了 wi+1≥wi 的设计原则,并将此约束下的设计空间称为 AnyNetXD。在下图 (左) 中,我们看到这极大地改进了 EDF。稍后我们将讨论控制宽度的其他选项。
AnyNetXE
在进一步检查许多模型 (未显示) 后,我们观察到另一个有趣的趋势。除了阶段宽度 wi 随 i 增加外,对于最佳模型,阶段深度 di 也同样趋向于增加,尽管不一定是在最后阶段。尽管如此,在上图 (右) 中,我们测试了一个设计空间变体 AnyNetXE,其中 di+1≥di,并看到它也改善了结果。最后,我们注意到对 wi 和 di 的约束使设计空间减少了 4!,与 AnyNetXA 相比 O(107)的累积减少。
RegNet 设计空间
为了进一步了解模型结构,我们在一个图中显示了来自 AnyNetXE 的最好的 20 个模型,见下图(左上)。对于每个模型,我们绘制每个块 j 的每块宽度 wj,直到网络深度 d(我们分别使用 i 和 j 来索引阶段和块)。
虽然在个别模型 (灰色曲线) 中存在显著的差异,但在总体上出现了一种模式。特别地,在相同的图中,我们显示了 0≤j≤20 时的 wj = 48·(j+1)(实心黑色曲线,请注意 y 轴是对数的)。值得注意的是,这种琐碎的线性拟合似乎可以解释顶级模型网络宽度增长的总体趋势。然而,请注意,这个线性拟合为每个块分配了不同的宽度 wj,而单个模型具有量化的宽度(分段常数函数):
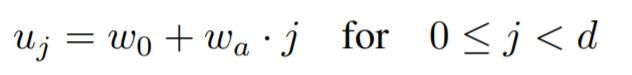
要查看类似的模式是否适用于单个模型,我们需要一种策略来将一条线量化为分段常数函数。受 AnyNetXD 和 AnyNetXE 的启发,我们提出了以下方法。首先,我们引入一个块宽的线性参数化:
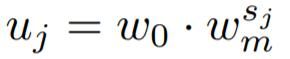
该参数化有三个参数: 深度 d、初始宽度 w0 >和斜率 wa > 0,并为每个区块 j < d 生成不同的区块宽度 uj。为了量化 uj,
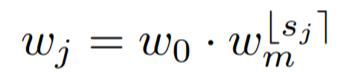
我们可以将每个块的 wj 转换为我们的每个阶段的格式,只需计算具有恒定宽度的块的数量,即每个阶段 i 的块宽度 wi = w0·w im,块数量 di = P j 1[bsj e = i]。当只考虑四个阶段网络时,我们忽略了引起不同阶段数的参数组合。
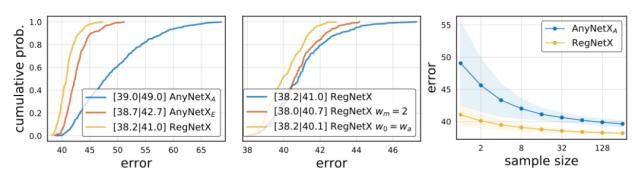
上图就是 RegNetX 设计空间。
我们通过拟合来自 AnyNetX 的模型来测试这个参数化。特别地,在给定的模型中,我们通过设置网络深度 d 并在 w0、wa 和 wm 上执行网格搜索来计算拟合,从而最小化每个块宽度的预测与观察的平均日志比 (用 efit 表示)。来自 AnyNetXE 的两个顶级网络的结果下图所示(右上角)。量化的线性拟合(虚线) 是这些最佳模型 (实线) 的良好拟合。
接下来,我们通过 AnyNetXE 绘制 AnyNetXC 中每个网络的拟合错误 efit 与网络错误,如上图 (底部) 所示。首先,我们注意到每个设计空间中最好的模型都具有良好的线性拟合。实际上,经验引导法给出了一个接近于 0 的 efit 窄频带,它可能包含每个设计空间中最好的模型。其次,我们注意到 efit 从 AnyNetXC 到 AnyNetXE 的平均性能得到了改善,这表明线性参数化自然地对 wi 和 di 的增加施加了相关的约束。
为了进一步检验线性参数化,我们设计了一个只包含线性结构模型的设计空间。特别地,我们通过 6 个参数来指定网络结构: d, w0, wa, wm(以及 b, g),给定这些参数,我们通过 Eqn 来生成块的宽度和深度。我们将最终的设计空间称为 RegNet,因为它只包含简单的、常规的模型。我们对 d < 64、w0、wa < 256、1.5≤wm≤3 和 b、g 进行采样(根据 AnyNetXE 上的 efit 设置范围)。
我们通过拟合来自 AnyNetX 的模型来测试这个参数化。特别地, 在给定的模型中, 我们通过设置网络深度 d 并在 w0, 佤邦和 wm 上执行网格搜索来计算拟合, 从而最小化每个块宽度的预测与观察的平均日志比 (用 efit 表示)。来自 AnyNetXE 的两个顶级网络的结果如上图所示(右上角)。量化的线性拟合(虚线) 是这些最佳模型 (实线) 的良好拟合。
上图 (左) 显示了 RegNetX 的 EDF 错误。在维护最佳模型的同时,RegNetX 中的模型具有比 AnyNetX 更好的平均错误。在上图 (中间) 中,我们测试了两个进一步的简化。首先,使用 wm = 2(两个阶段之间的宽度加倍)稍微提高了 EDF,但是我们注意到使用 wm≥2 性能更好 (稍后将展示)。其次,我们测试设置 w0 = wa,进一步将线性参数化简化为 uj = wa·(j + 1),有趣的是,这样做的效果更好。然而,为了保持模型的多样性,我们不施加任何限制。最后,在上图(右) 中,我们展示了 RegNetX 的随机搜索效率要高得多; 只对∼32 随机模型进行搜索可能会得到好的模型。
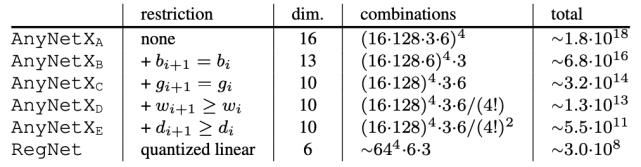
上表显示了设计空间大小的摘要(对于 RegNet,我们通过量化其连续参数来估计大小)。在设计 RegNetX 时,我们将原始 AnyNetX 设计空间的维度从 16 个维度缩减为 6 个维度,大小接近 10 个数量级。但是,我们注意到,RegNet 仍然包含各种各样的模型,可以针对各种设置进行调优。
设计空间泛化
我们在只有一个块类型的低计算、低历元训练机制中设计了 RegNet 设计空间。然而,我们的目标不是为单一的设置设计一个设计空间,而是发现可以推广到新设置的网络设计的一般原则。
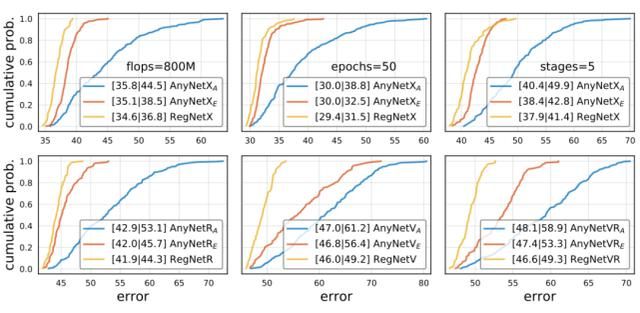
在上图中,我们将 RegNetX 设计空间与 AnyNetXA 和 AnyNetXE 在更高的 flops、更高的 epoch、5 级网络和各种块类型 (在附录中进行了描述) 下进行了比较。在所有情况下,设计空间的顺序是一致的,使用 RegNetX > AnyNetXE > AnyNetXA。换句话说,我们没有看到过度拟合的迹象。这些结果很有希望,因为它们表明 RegNet 可以泛化到新的设置。5 阶段的结果表明,正则 RegNet 结构可以推广到更多的阶段,其中 AnyNetXA 具有更多的自由度。
分析 RegNetX 设计空间
接下来,我们将进一步分析 RegNetX 设计空间,并回顾常见的深度网络设计选择。我们的分析产生了与流行实践不匹配的惊人见解,这使我们能够用简单的模型获得良好的结果。
由于 RegNetX 设计空间拥有高度集中的优秀模型,对于以下结果,我们将转换为抽样较少的模型(100 个),但对它们进行更长时间的培训(25 个 epoch),学习率为 0.1(参见附录)。我们这样做是为了观察网络行为中更细微的趋势。
RegNet 趋势
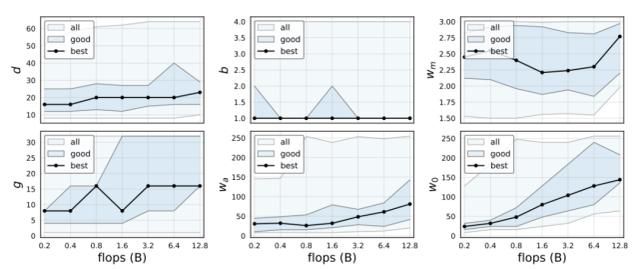
我们在下图中展示了在整个触发器中 RegNetX 参数的变化趋势。值得注意的是,最佳模型的深度在不同区域 (左上) 是稳定的,最优深度为∼20 块 (60 层)。这与在更高的翻背越高的体制中使用更深的模式的惯例形成了对比。我们还观察到,最佳模型使用的瓶颈比 b 为 1.0(上 - 中),这有效地消除了瓶颈(在实践中经常使用)。接下来,我们观察到好模型的宽度倍增器 wm 为∼2.5(右上角),这与流行的跨阶段加倍宽度的方法相似,但并不完全相同。其余参数(g、wa、w0) 随复杂度增加而增加(底部)。
复杂性分析
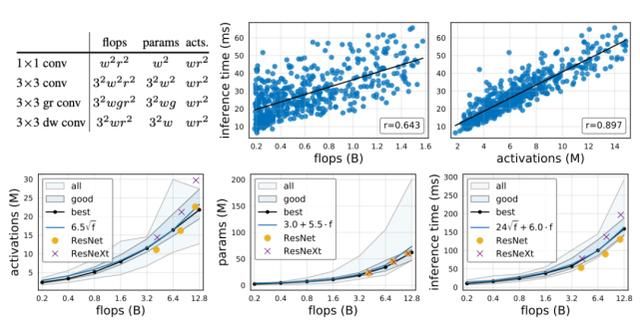
除了 flops 和参数之外,我们还分析了网络激活,我们将其定义为所有 conv 层的输出张量的大小 (我们在下图(左上角) 中列出了常见 conv 操作符的复杂性度量)。虽然激活不是测量网络复杂性的常用方法,但它会严重影响内存限制硬件加速器 (例如,gpu、TPUs) 上的运行时,参见下图 (顶部)。在下图(底部) 中,我们观察到,对于总体中的最佳模型,激活随 flops 的平方根增加而增加,参数线性增加,由于运行时对 flops 和激活的依赖性,最好同时使用线性和平方根项进行建模。
RegNetX 受限
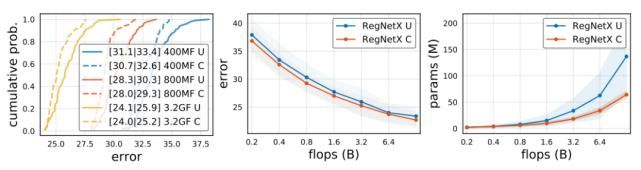
利用这些发现,我们改进了 RegNetX 设计空间。首先,根据上上张图 (top),我们令 b = 1, d≤40,wm≥2。其次,我们限制参数和激活,如上图 (底部) 所示。这将生成快速、低参数、低内存的模型,而不会影响准确性。在下图中,我们使用这些约束对 RegNetX 进行了测试,并观察到约束的版本在所有的触发器状态下都是优越的。
替代设计选择
现代移动网络通常采用倒置瓶颈 (b < 1) 提出了 [M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C.Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In CVPR, 2018] 随着切除 conv(g = 1)。在下图 (左), 我们观察到倒置瓶颈略有降低了 EDF, 切除 conv 执行更糟糕的是相对于 b = 1, g≥1 进一步分析(见文章的附录)。接下来,在[M. Tan and Q. V. Le. Efficientnet: Rethinking model scalingfor convolutional neural networks. ICML, 2019] 的启发下,我们测试了下图 (中间) 中变化的分辨率,[M. Tan and Q. V. Le. Efficientnet: Rethinking model scalingfor convolutional neural networks. ICML, 2019]发现缩放输入图像分辨率是有帮助的。与 [M. Tan and Q. V. Le. Efficientnet: Rethinking model scalingfor convolutional neural networks. ICML, 2019] 相反,我们发现对于 RegNetX,固定的 224×224 分辨率是最好的,即使在更高的 flops。
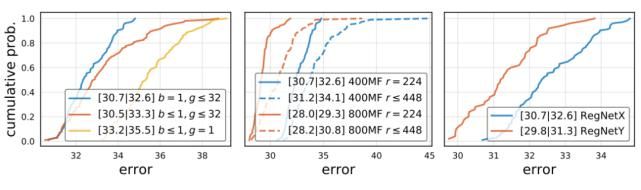
最后,我们使用流行的挤压 - 激励 (SE) op 来评估 RegNetX(我们将 X+SE 缩写为 Y,并将最终的设计空间称为 RegNetY)。在上图(右) 中,我们看到 RegNetY 产生了良好的收益。
与现有网络的比较
我们现在比较的顶级模型从 RegNetX 和 RegNetY 设计空间在各种复杂的状态,对 ImageNet 的艺术状态。我们使用小的大写字母来表示单个的模型,例如 REGNETX。我们还在模型后面加上了触发器机制,例如 400MF。对于每个触发器机制,我们从 RegNet 参数的 25 个随机设置 (d、g、wm、wa、w0) 中选出最佳模型,并在 100 个 epoch 时对 top 模型进行 5 次再训练,以获得可靠的误差估计。
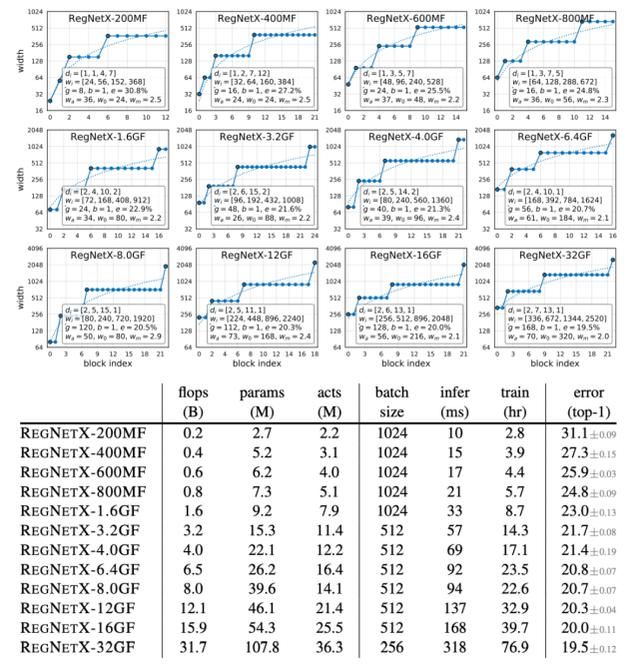
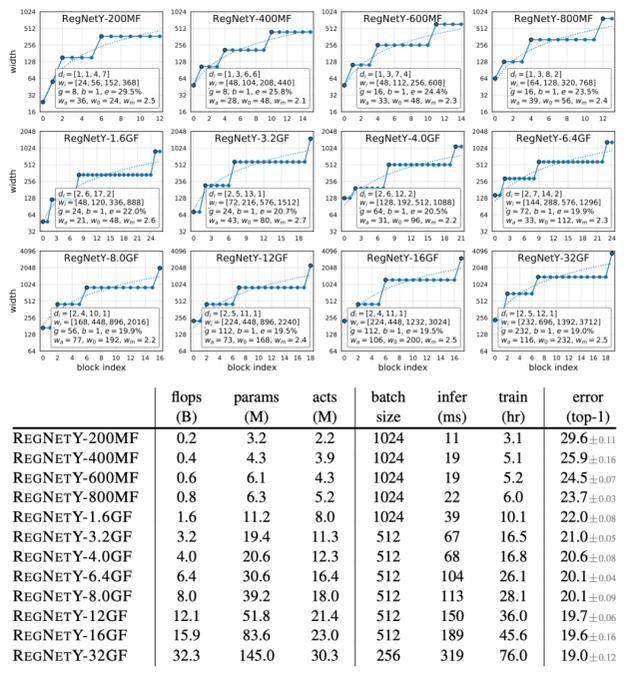
上图分别显示了每种翻牌制度的最高 REGNETX 和 REGNETY 模型。除了上面分析的简单线性结构和趋势外,我们还观察到一个有趣的模式。即高阶触发器模型在第三阶段积木数量较多,在最后阶段积木数量较少。这与标准 RESNET 模型的设计类似。此外,我们观察到群宽度 g 随着复杂度的增加而增加,但是深度 d 对于大型模型来说是饱和的。
我们的目标是执行公平的比较,并提供简单且易于复制的基线。我们注意, 以及更好的架构, 最近的报道在网络性能是基于增强培训设置和正规化方案(见下表)。我们的重点是评估网络架构, 我们表现的小心控制的实验设置在同样的培训。特别是,为了与经典作品进行公平的比较,我们没有使用任何培训时间的增强。

计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!