怎样用python爬虫付费文档_python爬文档
 广告关闭
广告关闭
腾讯云11.11云上盛惠 ,精选热门产品助力上云,云服务器首年88元起,买的越多返的越多,最高返5000元!
最近项目需要将批量链接中的pdf文档爬下来处理,根据以下步骤完成了任务:将批量下载链接copy到text中,每行1个链接; 再读txt文档构造url_list列表,利用readlines返回以行为单位的列表; 利用str的rstrip方法,删除 string 字符串末尾的指定字符(默认为空格); 调用getfile函数:通过指定分隔符‘’对字符串进行...
封面图片:《python程序设计实验指导书》(isbn:9787302525790),董付国,清华大学出版社图书详情:https:item.jd.com12592638.html=====问题描述:爬取微信公众号“python小屋”所有文章,每篇文章生成一个独立的word文档,包含该文中的文字、图片、表格、超链接。 技术要点:扩展库requests、beautifulsoup4...

这里可以外部导入a=# 打开保存位置csv_obj = open(.python爬取地理坐标data.csv, w,newline=,encoding=utf-8)#写入titlecsv.writer(csv_obj).writerow()# ...address=北京市海淀区上地十街10号&output=json&ak=您的ak&callback=showlocationget请求注意:当前为v3.0版本接口文档,v2.0及以前版本自2019...
前言 考虑到现在大部分小伙伴使用 python 主要因为爬虫,那么为了更好地帮助大家巩固爬虫知识,加深对爬虫的理解,选择了爬取百度文库作为我们的目标。 废话不多说,我们开始。 本文详细讲解,5000+字,觉得太长的读者可以划到文末拿走源码先用着,然后收藏就等于学会了? 爬取txt、docx 在爬取任何东西之前,我们都要...

pythonrequests 库 爬取网页数据的第一步就是下载网页。 我们可以利用requests 库向web服务器发送 get 请求下载网页内容。 使用requests时有几种不同的...还可以添加一些属性到html文档中来改变其行为: heres a paragraph of text! learn data science online heres a second paragraph of text! python 页面...
这次爬虫并没有遇到什么难题,甚至没有加header和data就直接弄到了盗版网站上的小说,真是大大的幸运。 所用模块:urllib,re主要分三个步骤:(1)分析小说网址构成; (2)获取网页,并分离出小说章节名和章节内容; (3)写入txt文档。 #-*-coding:gbk-*-#author:zwg爬取某小说网站的免费小说import urllibimport ...
usrbinenvpython#coding=utf-8针对51cto首页进行爬取importrequestsfrombs4importbeautifulsoupimportreimportjsonimportsysreload(sys)sys.setdefaultencoding(utf-8) classhtmldownload(object):定义页面爬取类:接收url,返回页面内容为了防止页面中文乱码,我们针对不同页面的编码选择utf-8或者gbkdef__init...
掌握基本的爬虫后,你再去学习python数据分析、web开发甚至机器学习,都会更得心应手。 因为这个过程中,python基本语法、库的使用,以及如何查找文档你都...python爬虫可以爬取的东西有很多,python爬虫怎么学? 简单的分析下:如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以...
www.crummy.comsoftwarebeautifulsoupbs4doc没有python基础的新人,我建议可以学习以下资料:1、官方最新的英文文档(https:docs.python.org3)2、python...献给想学爬虫的零基础新人们,欢迎各位大佬们的指点。 本文适用人群1、零基础的新人; 2、python刚刚懂基础语法的新人; 输入标题学习定向爬虫前需要的...
由上图我们可以看到,对于http客户端python官方文档也推荐我们使用requests库,实际工作中requests库也是使用的比较多的库。 所以今天我们来看看requests...requests库来登录豆瓣然后爬取影评为例子,用代码讲解下cookie的会话状态管理(登录)功能。 此教程仅用于学习,不得商业获利! 如有侵害任何公司利益,请...
beautifulsoup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。 它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单...知识点补充:关于爬虫中的headers:在使用python爬虫爬取数据的时候,经常会遇到一些网站的反爬虫措施,一般就是针对于headers中的user-agent...
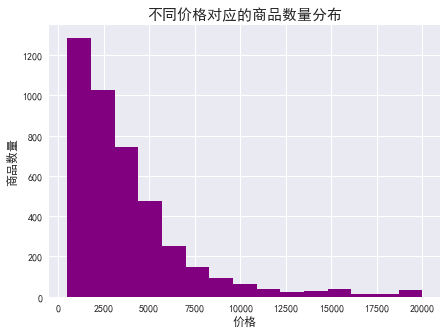
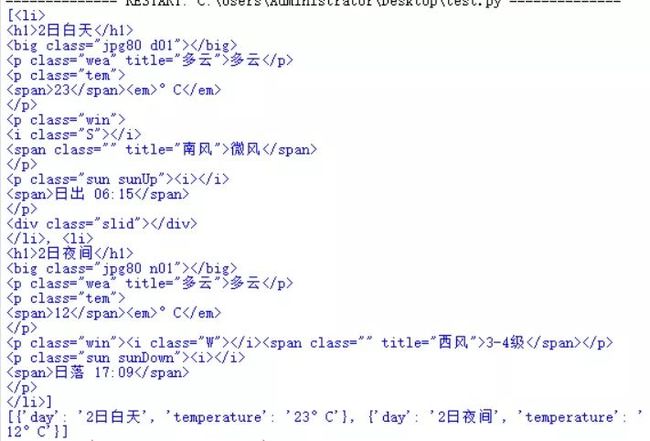
数据采集:python爬取淘宝网商品数据2. 对数据进行清洗和处理3. 文本分析:jieba分词、wordcloud可视化4. 数据柱形图可视化 barh5. 数据直方图可视化 hist...原代码和相关文档后台回复“淘宝”下载一、爬取数据因淘宝网是反爬虫的,虽然使用多线程、修改headers参数,但仍然不能保证每次100%爬取,所以 我增加了...

首先执行:pip install pipenv这里安装的,是一个优秀的 python 软件包管理工具 pipenv 。 安装后,请执行:pipenv install看到演示目录下两个pipfile开头的文件了吗? 它们就是 pipenv 的设置文档。 pipenv 工具会依照它们,自动为我们安装所需要的全部依赖软件包。? 上图里面有个绿色的进度条,提示所需安装软件...

正好一直在学习python爬虫,所以今天就心血来潮来写了个爬虫,抓取该网站上所有美剧链接,并保存在文本文档中,想要哪部剧就直接打开复制链接到迅雷就可以下载啦。? 其实一开始打算写那种发现一个url,使用requests打开抓取下载链接,从主页开始爬完全站。 但是,好多重复链接,还有其网站的url不是我想的那么规则...

正好一直在学习python爬虫,所以今天就心血来潮来写了个爬虫,抓取该网站上所有美剧链接,并保存在文本文档中,想要哪部剧就直接打开复制链接到迅雷就可以下载啦。? 其实一开始打算写那种发现一个url,使用requests打开抓取下载链接,从主页开始爬完全站。 但是,好多重复链接,还有其网站的url不是我想的那么规则...
正好一直在学习python爬虫,所以今天就心血来潮来写了个爬虫,抓取该网站上所有美剧链接,并保存在文本文档中,想要哪部剧就直接打开复制链接到迅雷就可以下载啦。? 其实一开始打算写那种发现一个url,使用requests打开抓取下载链接,从主页开始爬完全站。 但是,好多重复链接,还有其网站的url不是我想的那么规则...

这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库requests与beautifulsoup。 python 版本:python3.6 ,ide :pycharm。 其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行。 第三方库首先安装 我是用的pycharm所以另为的脚本安装我...

1 环境说明win10 系统下 python3,编译器是 pycharm,需要安装 wechatsogou 这个库这里只介绍 pycharm 安装第三方包的方法。? 一? 二2 相关代码2.1 搜索...?3 相关说明wechatsogou 的说明文档:https: github.comchyrocwechatsogou(点击原文链接也可以访问) 题图:photo by sunrise on unsplash...
实现思路阿拉丁产品分开放平台和统计平台两个产品线,目前开放平台有api及配套的文档。 统计平台api需要收费,而且贼贵。 既然没有现成的api可以获取数据,那么我们尝试一下用python抓取页面上的数据,毕竟python擅长干这种事情。 获取数据流程 1、首先登陆阿拉丁的统计平台,如下图? 发现实际需要获取的关键数据主要...

然而python的urlliburllib2默认都不支持压缩,要返回压缩格式,必须在request的header里面写明’accept-encoding’,然后读取response后更要检查header...每次写twisted的程序整个人都扭曲了,累得不得了,文档等于没有,必须得看源码才知道怎么整,唉不提了。 如果要支持gzipdeflate,甚至做一些登陆的扩展...