【YOLOX关键模块记录与解读】YOLOX: Exceeding YOLO Series in 2021
目录
- 前言
- 一、主干部分的Focus网络结构
- 二、解耦头
- 三、Mosaic数据增强
- 四、Anchor Free
- 五、SimOTA标签匹配策略
- 六、参考资料
前言
论文地址:https://arxiv.org/abs/2107.08430
源码地址:https://github.com/Megvii-BaseDetection/YOLOX
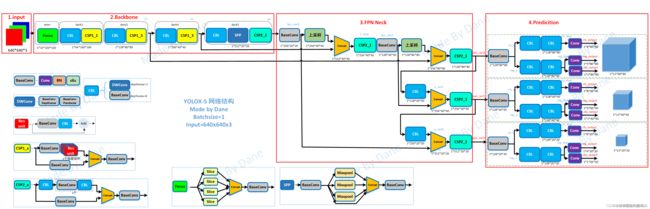
关于YOLOX有以下值得关注的部分:
1、主干部分的Focus网络结构:在一张图片的行和列上间隔取像素,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,通道数扩充了四倍。
2、解耦头:Decoupled Head。在YoloX中,Yolo Head被分为了两部分分别实现,把检测和分类问题分开处理(解耦头收敛更快且效果更好),最后预测的时候才整合在一起。
3、Mosaic数据增强:利用四张图片进行拼接实现数据中增强,这可以丰富检测物体的背景。
4、Anchor Free:不使用先验框。
5、SimOTA标签匹配策略 :为目标动态匹配正样本。
下图为网络主体结构图:
一、主干部分的Focus网络结构
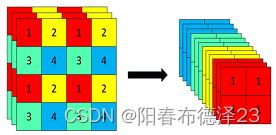
Focus结构是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,通道数扩充了四倍。拼接起来的特征层相对于原先的三通道变成了十二个通道,如下图所示:
代码如下:
class Focus(nn.Module):
"""Focus width and height information into channel space."""
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu"):
super().__init__()
self.conv = BaseConv(in_channels * 4, out_channels, ksize, stride, act=act)
def forward(self, x):
# shape of x (b,c,w,h) -> y(b,4c,w/2,h/2)
patch_top_left = x[..., ::2, ::2]
patch_top_right = x[..., ::2, 1::2]
patch_bot_left = x[..., 1::2, ::2]
patch_bot_right = x[..., 1::2, 1::2]
x = torch.cat(
(
patch_top_left,
patch_bot_left,
patch_top_right,
patch_bot_right,
),
dim=1,
)
return self.conv(x)
二、解耦头
在YoloX中,Yolo Head被分为了两部分分别实现,最后预测的时候才整合在一起。
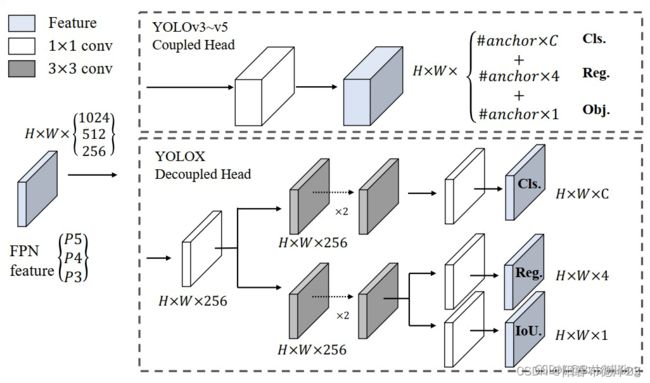
如图所示,将三个预测结果进行堆叠,每个特征层获得的结果为:
output(batch_size,xywh(回归参数)+1+num_classses,h,w),其中在第一维度,前四个参数用于判断每一个网格的回归参数,回归参数调整后可以获得预测框;第五个参数用于判断每一个网格的预测框是否包含物体;最后num_classes个参数用于判断每一个网格的预测框所包含的物体种类。
三、Mosaic数据增强
Mosaic数据增强方法是YOLOV4论文中提出来的,主要思想是将四张图片进行随机裁剪,再拼接到一张图上作为训练数据。这样做的好处是丰富了图片的背景,并且四张图片拼接在一起变相地提高了batch_size。

Pytorch实现:
def load_mosaic(self, index):
"""
将四张图片拼接在一张马赛克图像中
:param self:
:param index: 需要获取的图像索引
:return:
"""
# loads images in a mosaic
labels4 = [] # 拼接图像的label信息
s = self.img_size
# 随机初始化拼接图像的中心点坐标
xc, yc = [int(random.uniform(s * 0.5, s * 1.5)) for _ in range(2)] # mosaic center x, y
# 从dataset中随机寻找三张图像进行拼接
indices = [index] + [random.randint(0, len(self.labels) - 1) for _ in range(3)] # 3 additional image indices
# 遍历四张图像进行拼接 4张不同大小的图像 => 1张[1472, 1472, 3]的图像
for i, index in enumerate(indices):
# load image
img, _, (h, w) = load_image(self, index)
# place img in img4
if i == 0: # top left
# 创建马赛克图像 [1472, 1472, 3]
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
# 计算截取的图像区域信息(以xc,yc为第一张图像的右下角坐标填充到马赛克图像中,丢弃越界的区域)
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
# 计算截取的图像区域信息(以xc,yc为第二张图像的左下角坐标填充到马赛克图像中,丢弃越界的区域)
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
# 计算截取的图像区域信息(以xc,yc为第三张图像的右上角坐标填充到马赛克图像中,丢弃越界的区域)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, max(xc, w), min(y2a - y1a, h)
elif i == 3: # bottom right
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
# 计算截取的图像区域信息(以xc,yc为第四张图像的左上角坐标填充到马赛克图像中,丢弃越界的区域)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
# 将截取的图像区域填充到马赛克图像的相应位置
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
# 计算pad(图像边界与马赛克边界的距离,越界的情况为负值)
padw = x1a - x1b
padh = y1a - y1b
# Labels 获取对应拼接图像的labels信息
x = self.labels[index]
labels = x.copy() # 深拷贝,防止修改原数据
if x.size > 0: # Normalized xywh to pixel xyxy format
# 计算标注数据在马赛克图像中的
labels[:, 1] = w * (x[:, 1] - x[:, 3] / 2) + padw
labels[:, 2] = h * (x[:, 2] - x[:, 4] / 2) + padh
labels[:, 3] = w * (x[:, 1] + x[:, 3] / 2) + padw
labels[:, 4] = h * (x[:, 2] + x[:, 4] / 2) + padh
labels4.append(labels)
# Concat/clip labels 把labels4([(3, 5), (3, 5), (1, 5), (1, 5)] => (8, 5))压缩到一起
if len(labels4):
labels4 = np.concatenate(labels4, 0)
# np.clip(labels4[:, 1:] - s / 2, 0, s, out=labels4[:, 1:]) # use with center crop
np.clip(labels4[:, 1:], 0, 2 * s, out=labels4[:, 1:]) # use with random_affine 防止越界
# affine Augment 随机仿射变换 [1472, 1472, 3] => [736, 736, 3]
# img4 = img4[s // 2: int(s * 1.5), s // 2:int(s * 1.5)] # center crop (WARNING, requires box pruning)
img4, labels4 = random_affine(img4, labels4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
border=-s // 2) # border to remove
return img4, labels4
四、Anchor Free
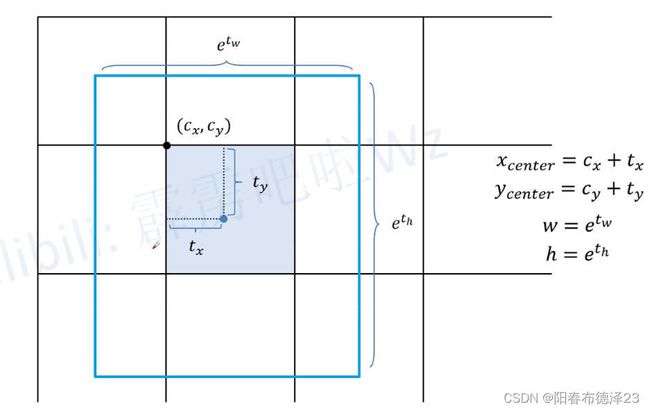
针对每个grid cell都会预测4个参数:相对网格左上方的x偏移量、y偏移量、w回归参数、h回归参数,再带入公式,得到最终的相对当前特征图的边界框(xywh)。注意这里和其他的YOLO系列的区别是,在根据wh回归参数计算wh坐标的时候,是不需要预先设置的anchor的w和h的,是和anchor无关的。
五、SimOTA标签匹配策略
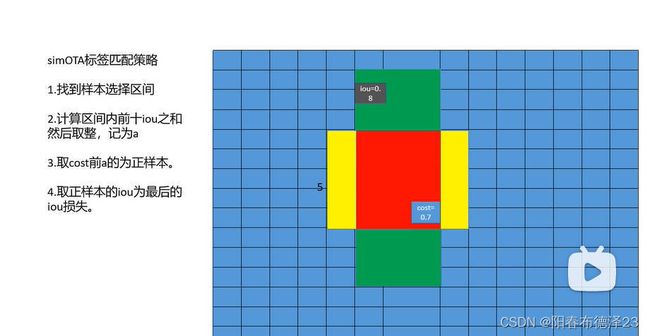
上图中纵向的绿色区域为标签框,横向的黄色区域为某一尺度“中心区域”示例,红色区域为二者交集
“中心区域”——(5xstride) * (5xstride),stride表示下采样率。yolox用到了类FPN金字塔结构,有三个输出尺度,不同尺度的中心区域是不同的(stride不同)
基本步骤:
- 确定正样本候选区域(“中心区域”和标签框的并集区域和交集区域)【调用get_in_boxes_info函数】;
- 计算每个候选框和每个gt的iou矩阵;
- 计算每个候选框和每个gt的cost矩阵,其中cost = cls loss + 3 * iou loss + 100000.0 * (~is_in_boxes_and_center), is_in_boxes_and_center表示标签框和“中心区域”交集的区域 取反就是并集-交集的区域,给这些区域的cost取一个非常大的数字 那么在后续的dynamic_k_matching,根据最小化cost原则会优先选取这些交集的区域 如果交集区域还不够才回去选取并集-交集的区域;
- 使用iou矩阵,确定每个gt的dynamic_k(正样本) 【调用dynamic_k_matching函数】;
a. 获取与当前gt的iou最大的前10个样本;
b. 将这top10样本的iou求和取整,就是当前gt的dynamic_k,而且dynamic_k大于等于1;
c. 为每个gt取cost排名最小的前dynamic_k个网格(anchor point)作为正样本,其他作为负样本;
d. 最后再人工去除同一个样本被分配到多个gt作为正样本的情况(最小化cost原则)
主要函数代码如下(详细注释):
get_assignments函数:正负样本匹配
#==================================get_assignments函数:正负样本匹配===========================#
#
# 1.确定正样本候选区域(“中心区域”和标签框的并集区域和交集区域)【调用get_in_boxes_info函数】;
# 2.计算每个候选框和每个gt的iou矩阵;
# 3.计算每个候选框和每个gt的cost矩阵,其中cost = cls loss + 3 * iou loss + 100000.0 * (~is_in_boxes_and_center)
# is_in_boxes_and_center表示标签框和“中心区域”交集的区域 取反就是并集-交集的区域
# 给这些区域的cost取一个非常大的数字 那么在后续的dynamic_k_matching,根据最小化cost原则
# 会优先选取这些交集的区域 如果交集区域还不够才回去选取并集-交集的区域
# 4.使用iou矩阵,确定每个gt的dynamic_k 【调用dynamic_k_matching函数】;
# a、获取与当前gt的iou最大的前10个样本;
# b、将这TOP10样本的iou求和取整,就是当前gt的dynamic_k,而且dynamic_k大于等于1;
# c、为每个gt取cost排名最小的前dynamic_k个网格(anchor point)作为正样本,其他作为负样本;
# d、最后再人工去除同一个样本被分配到多个gt作为正样本的情况(最小化cost原则)
# e、返回:最终的正样本个数、每个正样本所匹配到的真实框所属的类别、
# 每个正样本与所属的真实框的iou、每个正样本所匹配的真实框idx
#
#=============================================================================================#
@torch.no_grad()
def get_assignments(
self,
batch_idx,
num_gt,
total_num_anchors,
gt_bboxes_per_image,
gt_classes,
bboxes_preds_per_image,
expanded_strides,
x_shifts,
y_shifts,
cls_preds,
bbox_preds,
obj_preds,
labels,
imgs,
mode="gpu",
):
"""正负样本匹配
:param batch_idx: 第几张图片
:param num_gt: 当前图片的gt个数
:param total_num_anchors: 当前图片总的anchor point个数 640x640 -> 80x80+40x40+20x20 = 8400
:param gt_bboxes_per_image: [num_gt, 4(xywh相对原图)] 当前图片的gt box
:param gt_classes: [num_gt,] 当前图片的gt box所属类别
:param bboxes_preds_per_image: [total_num_anchors, xywh(相对原图)] 当前图片的每个anchor point相对原图的预测box坐标
:param expanded_strides: [1, total_num_anchors] 当前图片每个anchor point的下采样倍率
:param x_shifts: [1, total_num_anchors] 当前图片每个anchor point的网格左上角x坐标
:param y_shifts: [1, total_num_anchors] 当前图片每个anchor point的网格左上角y坐标
:param cls_preds: [bs, total_num_anchors, num_classes] bs张图片每个anchor point的预测类别
:param bbox_preds: [bs, total_num_anchors, 4(xywh相对原图)] bs张图片每个anchor point相对原图的预测box坐标
:param obj_preds: [bs, total_num_anchors, 1] bs张图片每个anchor point相对原图的预测置信度
:param labels: [bs, 200, class+xywh] batch张图片的原始gt信息 每张图片最多200个gt 不足的全是0
:param imgs: [bs, 3, 640, 640] 输入batch张图片
:param mode: 'gpu'
:return gt_matched_classes: 每个正样本所匹配到的真实框所属的类别 [num_fg,]
:return fg_mask: 记录哪些anchor是正样本 哪些是负样本 [total_num_anchors,] True/False
:return pred_ious_this_matching: 每个正样本与所属的真实框的iou [num_fg,]
:return matched_gt_inds: 每个正样本所匹配的真实框idx [num_fg,]
:return num_fg: 最终这张图片的正样本个数
"""
if mode == "cpu":
print("------------CPU Mode for This Batch-------------")
gt_bboxes_per_image = gt_bboxes_per_image.cpu().float()
bboxes_preds_per_image = bboxes_preds_per_image.cpu().float()
gt_classes = gt_classes.cpu().float()
expanded_strides = expanded_strides.cpu().float()
x_shifts = x_shifts.cpu()
y_shifts = y_shifts.cpu()
img_size = imgs.shape[2:]
# 1、确定正样本候选区域(使用中心先验)
# fg_mask: [total_num_anchors] gt内部和中心区域内部的所有anchor point都是候选框 所以是两者的并集
# True/False 假设所有True的个数为num_candidate
# is_in_boxes_and_center: [num_gt, num_candidate] 对应这张图像每个gt的候选框anchor point True/False
# 而且这些候选框anchor point是既在gt框内部也在fixed center area区域内的
fg_mask, is_in_boxes_and_center = self.get_in_boxes_info(
gt_bboxes_per_image,
expanded_strides,
x_shifts,
y_shifts,
total_num_anchors,
num_gt,
img_size
)
bboxes_preds_per_image = bboxes_preds_per_image[fg_mask] # 得到当前图片所有候选框的预测box [num_candidate, xywh(相对原图)]
cls_preds_ = cls_preds[batch_idx][fg_mask] # 得到当前图片所有候选框的预测cls [num_candidate, num_classes]
obj_preds_ = obj_preds[batch_idx][fg_mask] # 得到当前图片所有候选框的预测obj [num_candidate, 1]
num_in_boxes_anchor = bboxes_preds_per_image.shape[0] # 候选框个数
if mode == "cpu":
gt_bboxes_per_image = gt_bboxes_per_image.cpu()
bboxes_preds_per_image = bboxes_preds_per_image.cpu()
# 2、计算每个候选框anchor point和每个gt的iou矩阵
# [num_gt, 4(xywh相对原图)] [num_candidate, 4(xywh相对原图)] -> [num_gt, num_candidate]
pair_wise_ious = bboxes_iou(gt_bboxes_per_image, bboxes_preds_per_image, False)
# 3、计算每个候选框和每个gt的cost矩阵
# gt cls转为独热编码 方便后面计算cls loss
# [num_gt] -> [num_gt, num_classes] -> [num_gt, 1, num_classes] -> [num_gt, num_candidate, num_classes]
gt_cls_per_image = (
F.one_hot(gt_classes.to(torch.int64), self.num_classes)
.float()
.unsqueeze(1)
.repeat(1, num_in_boxes_anchor, 1)
)
# 计算每个候选框和每个gt的iou loss = -log(iou)
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8)
if mode == "cpu":
cls_preds_, obj_preds_ = cls_preds_.cpu(), obj_preds_.cpu()
# 计算每个候选框和每个gt的分类损失pair_wise_cls_loss
with torch.cuda.amp.autocast(enabled=False):
cls_preds_ = (
cls_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
* obj_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
)
pair_wise_cls_loss = F.binary_cross_entropy(
cls_preds_.sqrt_(), gt_cls_per_image, reduction="none"
).sum(-1)
del cls_preds_
# 计算每个候选框和每个gt的cost矩阵 [num_gt, num_candidate]
# 其中cost = cls loss + 3 * iou loss + 100000.0 * (~is_in_boxes_and_center)
# is_in_boxes_and_center表示gt box和fixed center area交集的区域 取反就是并集-交集的区域
# 给这些区域的cost取一个非常大的数字 那么在后续的dynamic_k_matching根据最小化cost原则
# 我们会优先选取这些交集的区域 如果交集区域还不够才回去选取并集-交集的区域
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_ious_loss
+ 100000.0 * (~is_in_boxes_and_center)
)
# 4、使用iou矩阵,确定每个gt的dynamic_k
# num_fg: 最终的正样本个数
# gt_matched_classes: 每个正样本所匹配到的真实框所属的类别 [num_fg,]
# pred_ious_this_matching: 每个正样本与所属的真实框的iou [num_fg,]
# matched_gt_inds: 每个正样本所匹配的真实框idx [num_fg,]
(
num_fg,
gt_matched_classes,
pred_ious_this_matching,
matched_gt_inds,
) = self.dynamic_k_matching(cost, pair_wise_ious, gt_classes, num_gt, fg_mask)
del pair_wise_cls_loss, cost, pair_wise_ious, pair_wise_ious_loss
if mode == "cpu":
gt_matched_classes = gt_matched_classes.cuda()
fg_mask = fg_mask.cuda()
pred_ious_this_matching = pred_ious_this_matching.cuda()
matched_gt_inds = matched_gt_inds.cuda()
return (
gt_matched_classes,
fg_mask,
pred_ious_this_matching,
matched_gt_inds,
num_fg,
)
get_in_boxes_info函数:确定正样本候选框
#========================get_in_boxes_info函数:确定正样本候选框=======================#
#
# 1.计算哪些网格的中心点是在gt内部的;
# 2.计算哪些网格是在“中心区域” (5xstride) * (5xstride)内;注意:不同尺度的中心区域是不同的(stride不同)
# 3.得到最终的候选框(预测候选框的网格),确定所有的候选框(在gt内部 和 在“中心区域”的交集),但是在最终会倾向于选取两者的并集区域
#
#=====================================================================================#
def get_in_boxes_info(
self,
gt_bboxes_per_image,
expanded_strides,
x_shifts,
y_shifts,
total_num_anchors,
num_gt,
img_size
):
"""确定正样本候选区域
:param gt_bboxes_per_image: [num_gt, 4(xywh相对原图的)] 当前图片的gt box
:param expanded_strides: [1, total_num_anchors] 当前图片每个anchor point的下采样倍率
:param x_shifts: [1, total_num_anchors] 当前图片每个anchor point的网格左上角x坐标
:param y_shifts: [1, total_num_anchors] 当前图片每个anchor point的网格左上角y坐标
:param total_num_anchors: 当前图片总的anchor point个数 640x640 -> 80x80+40x40+20x20 = 8400
:param num_gt: 当前图片的gt个数
:return is_in_boxes_anchor: [total_num_anchors] gt内部和中心区域内部的所有anchor point都是候选框 所以是两者的并集
True/False 假设所有True的个数为num_candidate
:return is_in_boxes_and_center: [num_gt, num_candidate] 对应这张图像每个gt的候选框anchor point True/False
而且这些候选框anchor point是既在gt框内部也在fixed center area区域内的
"""
# 一、计算哪些网格的中心点是在gt内部的
# 计算每个网格的中心点坐标
# [total_num_anchors,] 当前图片的3个特征图中每个grid cell的缩放比
expanded_strides_per_image = expanded_strides[0]
# [total_num_anchors,] 当前图片3个特征图中每个grid cell左上角在原图上的x坐标
x_shifts_per_image = x_shifts[0] * expanded_strides_per_image
# [total_num_anchors,] 当前图片3个特征图中每个grid cell左上角在原图上的y坐标
y_shifts_per_image = y_shifts[0] * expanded_strides_per_image
# 得到每个网格中心点的x坐标(相对原图) [total_num_anchors,] -> [1, total_num_anchors] -> [num_gt, total_num_anchors]
x_centers_per_image = (
(x_shifts_per_image + 0.5 * expanded_strides_per_image)
.unsqueeze(0)
.repeat(num_gt, 1)
) # [n_anchor] -> [n_gt, n_anchor]
# 得到每个网格中心点的y坐标(相对原图) [total_num_anchors,] -> [1, total_num_anchors] -> [num_gt, total_num_anchors]
y_centers_per_image = (
(y_shifts_per_image + 0.5 * expanded_strides_per_image)
.unsqueeze(0)
.repeat(num_gt, 1)
)
# 计算所有gt框相对原图的左上角和右下角坐标 gt: [num_gt, 4(xywh)] xy为中心点坐标 wh为宽高
# 计算每个gt左上角的x坐标 x - 0.5 * w [num_gt, ] -> [num_gt, 1] -> [num_gt, total_num_anchors]
gt_bboxes_per_image_l = (
(gt_bboxes_per_image[:, 0] - 0.5 * gt_bboxes_per_image[:, 2])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
# 计算每个gt右下角的x坐标 x + 0.5 * w [num_gt, ] -> [num_gt, 1] -> [num_gt, total_num_anchors]
gt_bboxes_per_image_r = (
(gt_bboxes_per_image[:, 0] + 0.5 * gt_bboxes_per_image[:, 2])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
# 计算每个gt左上角的y坐标 y - 0.5 * h [num_gt, ] -> [num_gt, 1] -> [num_gt, total_num_anchors]
gt_bboxes_per_image_t = (
(gt_bboxes_per_image[:, 1] - 0.5 * gt_bboxes_per_image[:, 3])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
# 计算每个gt右下角的y坐标 y + 0.5 * h [num_gt, ] -> [num_gt, 1] -> [num_gt, total_num_anchors]
gt_bboxes_per_image_b = (
(gt_bboxes_per_image[:, 1] + 0.5 * gt_bboxes_per_image[:, 3])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
# 计算哪些网格的中心点是在gt内部的
# 每个网格中心点x坐标 - 每个gt左上角的x坐标
b_l = x_centers_per_image - gt_bboxes_per_image_l # [num_gt, total_num_anchors]
# 每个gt右下角的x坐标 - 每个网格中心点x坐标
b_r = gt_bboxes_per_image_r - x_centers_per_image # [num_gt, total_num_anchors]
# 每个网格中心点的y坐标 - 每个gt左上角的y坐标
b_t = y_centers_per_image - gt_bboxes_per_image_t # [num_gt, total_num_anchors]
# 每个gt右下角的y坐标 - 每个网格中心点的y坐标
b_b = gt_bboxes_per_image_b - y_centers_per_image # [num_gt, total_num_anchors]
bbox_deltas = torch.stack([b_l, b_t, b_r, b_b], 2) # 4x[num_gt, total_num_anchors] -> [num_gt, total_num_anchors, 4]
# b_l, b_t, b_r, b_b中最小的一个>0.0 则为True 也就是说要保证b_l, b_t, b_r, b_b四个都大于0 此时说明这个网格中心点位于这个gt的内部(可以画个图理解下)
# [num_gt, total_num_anchors] True表示当前这个网格是落在这个gt内部的
is_in_boxes = bbox_deltas.min(dim=-1).values > 0.0
# [total_num_anchors] 某个网格只要落在一个gt内部就是True 否则False
is_in_boxes_all = is_in_boxes.sum(dim=0) > 0
# in fixed center
# 二、计算哪些网格是在fixed center area区域内 计算步骤和一是一样的 就不赘述了
# fixed center area 中心区域大小是 (5xstride) x (5xstride) 中心点是每个gt的中心点 注意中心区域对于不同尺度的输出特征图大小是不同的
# 在原图尺度上,每个gt有三个中心区域,因为stride有三个尺度,考查的是哪些网格在对应尺度的中心区域里
center_radius = 2.5
# clip center inside image
# 计算所有中心区域相对原图的左上角和右下角坐标 [num_gt, total_num_anchors]
gt_bboxes_per_image_clip = gt_bboxes_per_image[:, 0:2].clone()
gt_bboxes_per_image_clip[:, 0] = torch.clamp(gt_bboxes_per_image_clip[:, 0], min=0, max=img_size[1])
gt_bboxes_per_image_clip[:, 1] = torch.clamp(gt_bboxes_per_image_clip[:, 1], min=0, max=img_size[0])
gt_bboxes_per_image_l = (gt_bboxes_per_image_clip[:, 0]).unsqueeze(1).repeat(
1, total_num_anchors
) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_r = (gt_bboxes_per_image_clip[:, 0]).unsqueeze(1).repeat(
1, total_num_anchors
) + center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_t = (gt_bboxes_per_image_clip[:, 1]).unsqueeze(1).repeat(
1, total_num_anchors
) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_b = (gt_bboxes_per_image_clip[:, 1]).unsqueeze(1).repeat(
1, total_num_anchors
) + center_radius * expanded_strides_per_image.unsqueeze(0)
# 计算哪些网格的中心点是在fixed center area区域内的
c_l = x_centers_per_image - gt_bboxes_per_image_l
c_r = gt_bboxes_per_image_r - x_centers_per_image
c_t = y_centers_per_image - gt_bboxes_per_image_t
c_b = gt_bboxes_per_image_b - y_centers_per_image
center_deltas = torch.stack([c_l, c_t, c_r, c_b], 2)
is_in_centers = center_deltas.min(dim=-1).values > 0.0
is_in_centers_all = is_in_centers.sum(dim=0) > 0
# in boxes and in centers
# 三、得到最终的所有的c
# is_in_boxes_anchor: [total_num_anchors] gt内部和中心区域内部的所有anchor point都是候选框 所以是两者的并集
# True/False 假设所有True的个数为num_candidate True表示在gt内部或中心区域内部的网格
is_in_boxes_anchor = is_in_boxes_all | is_in_centers_all
# is_in_boxes_and_center: [num_gt, num_candidate] 对应这张图像每个gt的候选框anchor point True/False
# &: 表示这些候选框anchor point是既在gt框内部也在fixed center area区域内的
is_in_boxes_and_center = (
is_in_boxes[:, is_in_boxes_anchor] & is_in_centers[:, is_in_boxes_anchor] # [:, is_in_boxes_anchor] 只留下True的部分,表示在gt内部或中心区域内部的网格
)
del gt_bboxes_per_image_clip
return is_in_boxes_anchor, is_in_boxes_and_center
dynamic_k_matching函数
def dynamic_k_matching(self, cost, pair_wise_ious, gt_classes, num_gt, fg_mask):
"""确定每个gt的dynamic_k
正样本筛选过程:8400 -> num_candidate -> num_fg
:param cost: 每个候选框和每个gt的cost矩阵 [num_gt, num_candidate]
:param pair_wise_ious: 每个候选框和每个gt的iou矩阵 [num_gt, num_candidate]
:param gt_classes: 当前图片的gt box所属类别 [num_gt,]
:param num_gt: 当前图片的gt个数
:param fg_mask: [total_num_anchors,] gt内部和中心区域内部的所有anchor point都是候选框 所以是两者的并集
True/False 假设所有True的个数为num_candidate
:return num_fg: 最终的正样本个数
:return gt_matched_classes: 每个正样本所匹配到的真实框所属的类别 [num_fg,]
:return pred_ious_this_matching: 每个正样本与所属的真实框的iou [num_fg,]
:return matched_gt_inds: 每个正样本所匹配的真实框idx [num_fg,]
"""
# Dynamic K
# ---------------------------------------------------------------
# 初始化匹配矩阵 [num_gt, num_candidate]
matching_matrix = torch.zeros_like(cost)
ious_in_boxes_matrix = pair_wise_ious
# 每个gt选取前topk个iou
n_candidate_k = min(10, ious_in_boxes_matrix.size(1))
# [num_gt, num_candidate] -> [num_gt, 10]
topk_ious, _ = torch.topk(ious_in_boxes_matrix, n_candidate_k, dim=1)
# 对于每个gt,将其对应的n_candidate_k个iou相加,并取整作为每个gt的正样本数量(>=1) [num_gt,]
dynamic_ks = torch.clamp(topk_ious.sum(1).int(), min=1)
# 遍历每个gt, 选取前dynamic_ks个最小的cost对应的anchor point作为最终的正样本
for gt_idx in range(num_gt):
_, pos_idx = torch.topk( # pos_idx: 正样本对应的idx
cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False
)
# 把匹配矩阵的gt和anchor point对应位置置为1 意为这个anchor point是这个gt的正样本
matching_matrix[gt_idx][pos_idx] = 1.0
del topk_ious, dynamic_ks, pos_idx
# 消除重复匹配: 如果有1个anchor point是多个gt的正样本,那么还是最小化原则,它是cost最小的那个gt的正样本,其他gt的负样本
# 计算每个候选anchor point匹配的gt个数 [num_candidate,]
anchor_matching_gt = matching_matrix.sum(0)
# 如果大于1 说明有1个anchor分配给了多个gt 那么要重新分配这个anchor:把这个anchor分配给cost小的那个gt
if (anchor_matching_gt > 1).sum() > 0:
cost_min, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0) # 取cost小的位置idx
matching_matrix[:, anchor_matching_gt > 1] *= 0.0 # 重复匹配的区域(大于1)全为0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0 # cost小的改为1
# fg_mask_inboxes: [num_candidate] True/False 最终的正样本区域为True 负样本为False
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
# 最终的正样本总个数
num_fg = fg_mask_inboxes.sum().item()
# fg_mask: [total_num_anchors] True/False fg_mask重新赋值,True的数量为num_fg
fg_mask[fg_mask.clone()] = fg_mask_inboxes
# 每个正样本所匹配的真实框idx [num_fg,] 注意每个真实框可能会有多个正样本,但是每个正样本只能是一个真实框的正样本
# [num_gt, num_candidate] -> [num_gt, num_fg] -> [num_fg,]
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
# 每个正样本所匹配到的真实框所属的类别 [num_fg,]
gt_matched_classes = gt_classes[matched_gt_inds]
# 每个正样本与所属的真实框的iou [num_fg,]
pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[
fg_mask_inboxes
]
return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds
六、参考资料
- https://hukai.blog.csdn.net/article/details/128160734?spm=1001.2014.3001.5502
- https://blog.csdn.net/weixin_44791964/article/details/120476949
- https://hukai.blog.csdn.net/article/details/116465458
- https://www.bilibili.com/video/BV11R4y177zJ/?spm_id_from=333.788&vd_source=0ce9ee4a0d88fcc1691c6cb5aa773a8d