机器学习汇总(支持向量机、随机森林、BP神经网络)包含实战附代码及结果
第一次发表博客,记录学习过程为主,自己的理解,如果有疑问,欢迎纠正!!!
在这一篇文章中,主要带大家了解一下机器学习是什么,它在实际中怎样使用,具体解决什么问题,同时还有丰富的例子哦!!!
1、引子
首先,机器学习这个名词大家或多或少都听说过,那么它具体是什么呢?我们可以这样理解,通过对生活中的某些事物,都具有不同的类型,每一种类型的事务都有自己特有的特征,我们通过这些特征可以判断出每一种事物的类别,当然我们人也可以轻松的判断出,但是我们人同样是通过不断的学习才逐渐的知道这个事物它具体是什么。这里我们可以联想,我们可不可以将人做的这些工作用计算机完成呢?如果计算机完成,由于计算机超级快的计算速度,是不是在某种程度上比我们人类达到更好的效果呢?这就是机器学习!!!
下面我们通过一个简单的例子深入的理解机器学习的本质,我们看下面四张图片




我们假想现在的你回到了小时候,并不知道以上四张图片中的东西是什么,那么现在你的妈妈告诉你上面的两张图片是苹果,下面两张图片是香蕉,告诉你一次,你可能过一天就忘了,那如果天天告诉你呢?你是不是很快就知道了,可能刚开始你不知道苹果分为红苹果和青苹果,但是只要你见得多了,总有一天(也就是长大了)就知道苹果这种水果了;下面的香蕉也是同样道理,有一天你拿到了左下角的水果,你不知道是什么,妈妈告诉你,“这是香蕉,吃、吃”,你开心的接了过去,剥开皮,就是右下角的图片了,这是香蕉的另一种特征,虽然没有提醒你这还是香蕉,但是你肯定知道啊!!
以上是我们人类学习具体事务分类的特征最后在生活中知道,哪个是苹果,哪个是香蕉或者其他水果也是同理,我们是根据它的颜色,形状,味道等等特征区分;但是迁移到计算机呢?就需要将这些物体(图片)转化为数字,使得计算机去计算,那么图片怎么转化为数字特征呢?
没错!!就是像素,那么下一个问题是,一张图片有多少个数字(像素)呢?3(RGB)*图像高度*图像宽度,这起码有几万个特征了吧!特征多有时候其实也不是好事(这涉及到主成分分析PCA中的内容,大家不了解的可以略过,不影响,后面有时间会专门给大家出一期讲解),我们考虑将这些特征(feature)有用的提取出来,以免误导机器学习的进度,。接着我们每一张图片都对应一个种类,我们把这个种类叫做标签(label),我们有多少张图片就有多少组特征和对应的标签。
接下来,将为大家介绍训练集和测试集的划分。
2、训练集和测试集划分
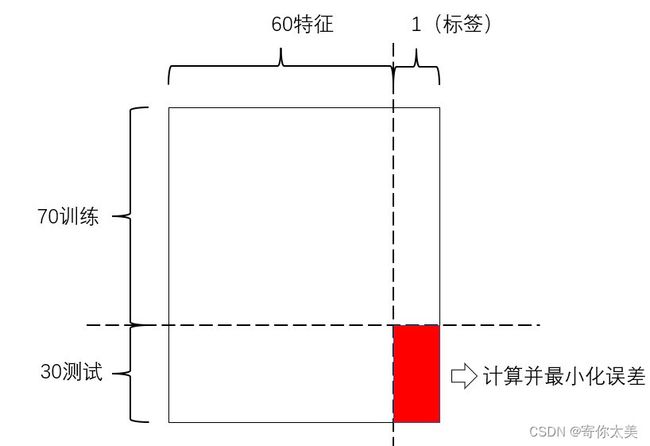
我们用一个例子介绍这一小节。假如现在你有100张图片,分为两类:香蕉和苹果(香蕉用0表示,苹果用1表示)。每张图片是3(RGB)*100*100像素,那么每一张图片的特征一共有30000个,我们通过PCA假如降维到60个特征(不知道PCA的小伙伴可以不做这一步,用30000个特征也是可以的),我们100张图片共有60个特征+1个标签,构成了一个61*100的矩阵。下图所示。

这时候我们考虑一个新的问题:如果我们100张图片都送入系统中学习的话,你怎么知道学习的效果,就想人一样,你如果妈妈一直教你“这是苹果,这是梨子……”不让你自己独立思考,就比如一直学习不能看出你的效果,需要考试吧,检验你的学习效果,机器学习也是一样,这时就出现了所谓的训练集(平时练习)和测试集(考试),当然平时训练和测试我们按7:3分配吧!那么是不是就变成了70个图片训练(61*70的矩阵),30个图片测试集(注意:60*30的矩阵,为什么不是61?因为是“考试”,肯定不会给你答案啊)。划分训练集和测试集后见下图
3、指标
我们在训练后怎么评价呢?考试后总有一个分数吧,这个分数就可以作为评价指标,在机器学习中我们同样有准确率(Accuracy)这一指标,也就是30个图片(或者其他事物),你的系统判断正确了多少,可以用下面的公式表示
Accuracy=正确个数/总个数*100%
4、实战
接下来我们就直接进入实战部分了,可能有些小伙伴对于机器学习还是一头雾水,因为我们没有介绍机器学习的一些模型(支持向量机、神经网络、随机森林等等),由于这些模型介绍起来比较复杂,我打算留到后面一一深入讲解,现在先通过具体的实战案例带大家看看实战中的效果。
4.1支持向量机(SVM)
这一小节是使用SVM解决一个简单的人脸识别问题,使用的数据集是ORL库,共有400张图片(40个人,每人10张)链接在文末。使用了libsvm工具箱,可以百度搜索下载
matlab代码如下(使用时注意修改读取图片的路径,你们电脑和我的电脑存储位置不一定相同)
clear all;clc
feature=[];
for i=1:40
path='E:\deep_learning\orl_faces (2)\';%基础路径
path=[path,'s',int2str(i)];
path_list=dir(strcat(path,'\*.pgm'));
img_len=length(path_list); %计算每一个文件夹中图片个数
for j=1:img_len
img_name=[path,'\',num2str(j),'.pgm'];%遍历读取图片
f=[reshape(imread(img_name),1,112*92),i];%112*92 ->1*10304
feature=[feature;f];%得到特征矩阵
end
end
feature=double(feature);
%pca降维
[~,score,lamda,~,~,~]=pca(feature(:,1:end-1));%调用库函数求得降维后的特征矩阵
l=cumsum(lamda)./sum(lamda);
idx=find(l>0.74);%optm=0.74 Accuracy = 99.1667% (119/120) (classification)
k=idx(1);
feature=[score(:,1:k),feature(:,end)];
count=size(feature,1);
index=randperm(count);%随机选择训练样本
% index=[1:7,11:17,21:27,31:37,41:47,51:57,61:67,8:10,18:20,28:30,38:40,48:50,58:60,68:70];%固定训练样本
train_data=feature(index(1:count*0.7),1:end-1);
train_label=feature(index(1:count*0.7),end);
test_data=feature(index(count*0.7+1:count),1:end-1);
test_label=feature(index(count*0.7+1:count),end);
%数据预处理,用matlab自带的mapminmax将训练集和测试集归一化处理[0,1]之间
%训练数据处理
[train_data,pstrain] = mapminmax(train_data');
% 将映射函数的范围参数分别置为0和1
pstrain.ymin = 0;
pstrain.ymax = 1;
% 对训练集进行[0,1]归一化
[train_data,pstrain] = mapminmax(train_data,pstrain);
% 测试数据处理
[test_data,pstest] = mapminmax(test_data');
% 将映射函数的范围参数分别置为0和1
pstest.ymin = 0;
pstest.ymax = 1;
% 对测试集进行[0,1]归一化
[test_data,pstest] = mapminmax(test_data,pstest);
% 对训练集和测试集进行转置,以符合libsvm工具箱的数据格式要求
train_data = train_data';
test_data = test_data';
%此处可以网格搜索最优参数
%训练模型
cmd= '-c 1.5 -g 1/40';%设置参数
model=svmtrain(train_label,train_data,cmd);
%save model.mat;
disp(cmd);
%测试分类
[predict_label, accuracy, dec_values]=svmpredict(test_label,test_data,model);
accuracy
%想要从外部的图片做验证,还有点问题结果如下
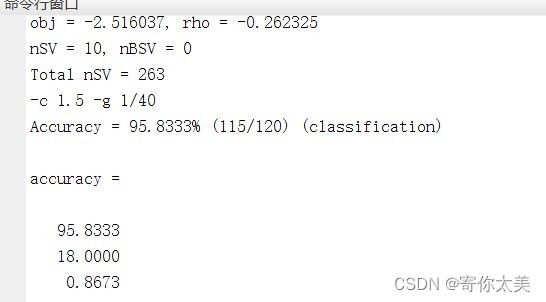
从图中我们可以看出在测试集上的准确率达到了95.83%,代表我们的SVM模型识别率还是不错的。
4.2BP神经网络
使用的数据集仍然是ORL数据集
matlab代码如下(注意更改文件夹路径)
clear all;clc
feature=[];
for i=1:7
% path='E:\图像处理实验\实验5\实验5\人脸图像\人脸图像\';
path='E:\deep_learning\orl_faces (2)\';%基础路径
% path=strcat(path,int2str(i));
path=[path,'s',int2str(i)];
path_list=dir(strcat(path,'\*.pgm'));
img_len=length(path_list); %计算每一个文件夹中图片个数
for j=1:img_len
% img_name=[path,'\s',num2str(j,'%02d'),'.bmp'];
img_name=[path,'\',num2str(j),'.pgm'];%遍历读取图片
% f=[reshape(imresize(rgb2gray(imread(img_name)),[224,224]),1,224*224),i];
f=[reshape(imread(img_name),1,112*92),i];%112*92 ->1*10304
feature=[feature;f];%得到特征矩阵
end
end
feature=double(feature);
acc=[];
[~,score,lamda,~,~,~]=pca(feature(:,1:end-1));%调用库函数求得降维后的特征矩阵
l=cumsum(lamda)./sum(lamda);
idx=find(l>0.92);
k=idx(1);
feature=[score(:,1:k),feature(:,end)];
% test_final=score(end-1:end,1:k);
count=size(feature,1);
index=randperm(count);%随机选择训练样本
% index=[1:7,11:17,21:27,31:37,41:47,51:57,61:67,8:10,18:20,28:30,38:40,48:50,58:60,68:70];%固定训练样本
% index=[1 2 3 4 5 6 7 11 12 13 14 15 16 17 21 22 23 24 25 26 27 8 9 10 18 19 20 28 29 30];
train_data=feature(index(1:count*0.7),1:end-1)';
train_label=feature(index(1:count*0.7),end)';
test_data=feature(index(count*0.7+1:count),1:end-1)';
test_label=feature(index(count*0.7+1:count),end)';
%数据预处理,用matlab自带的mapminmax将训练集和测试集归一化处理[0,1]之间
%训练数据处理
[train_data,pstrain] = mapminmax(train_data');
% 将映射函数的范围参数分别置为0和1
pstrain.ymin = 0;
pstrain.ymax = 1;
% 对训练集进行[0,1]归一化
[train_data,pstrain] = mapminmax(train_data,pstrain);
% 测试数据处理
[test_data,pstest] = mapminmax(test_data');
% 将映射函数的范围参数分别置为0和1
pstest.ymin = 0;
pstest.ymax = 1;
% 对测试集进行[0,1]归一化
[test_data,pstest] = mapminmax(test_data,pstest);
% 对训练集和测试集进行转置,以符合libsvm工具箱的数据格式要求
train_data = train_data';
test_data = test_data';
val_error=100;
%循环测试寻找最优模型
while val_error>0.3
net=newff(train_data,train_label,[8,5,2],{'tansig','purelin'});%3层隐含层(8 5 2)
net.trainParam.epochs=1000;%训练次数
net.trainParam.lr=0.01;%学习率
net.trainParam.goal=0.00001;%目标误差
net.trainParam.show=1;%训练多少次显示一次
net=train(net,train_data,train_label);
test_pre=sim(net,test_data);%结果
val_error=mean(abs(test_pre-test_label));%误差
array=round(test_pre)==test_label;
yes=length(find(array==1));%正确的个数
acc=yes/length(test_label);%验证集精度
end
acc
val_error结果展示


上面的图片展示了在测试集上的指标,达到了95.24的准确率。
4.3随机森林
这次我们可以换一个数据集,使用红酒数据集,数据集结构是1599个样本,14个特征,1个标签(10分类),详细数据来源:Red Wine Quality | Kaggle,当然我们这次使用的python的sklearn工具包中自带这个数据集,我们直接导入即可,想要知道详细的数据集结构可以百度搜索。下面给出代码。
代码如下
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
#导入红酒数据集
wine=load_wine()
#划分训练集和测试集
Xtrain,Xtest,Ytrain,Ytest=train_test_split(wine.data,wine.target,test_size=0.3)
clf=DecisionTreeClassifier()
rfc=RandomForestClassifier()
clf.fit(Xtrain,Ytrain)
rfc.fit(Xtrain,Ytrain)
#交叉验证可以代替clf.fit
#clf_s=cross_val_score(clf,wine.data,wine.target,cv=10)
'''
print(clf.score(Xtest,Ytest))
print(rfc.score(Xtest,Ytest))
'''
#随机森林的调参
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
#第一步:先找n_estimators的范围(最终确定在15-25中细化)
'''
score=[]
for i in range(0,200,10):
rfc=RandomForestClassifier(n_estimators=i+1,random_state=30)
score1=cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
score.append(score1)
print(max(score),(score.index(max(score))*10)+1)
plt.plot(range(1,201,10),score)
plt.show()
'''
#第二步:在15-25中细化
'''
#15-25间细化
score=[]
for i in range(15,25):
rfc=RandomForestClassifier(n_estimators=i,random_state=30)
score1=cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
score.append(score1)
print(max(score),([*range(15,25)][score.index(max(score))]))
plt.plot(range(15,25),score)
plt.show()
#结果0.9888888888888889 18
'''
#第三步:网格调参
param_grid={'max_depth':np.arange(1,20,1)}
rfc=RandomForestClassifier(n_estimators=18,random_state=30,)
GS=GridSearchCV(rfc,param_grid,cv=10)
GS.fit(wine.data,wine.target)
print(GS.best_params_)
print(GS.best_score_)
#结果{'max_depth': 5}
#0.9888888888888889
#总结:整个调整参数的顺序
'''
整个调整参数的顺序
n_estimators
max_depth
min_samples_leaf
min_samples_split
max_features
criterion(调一下试试吧)
'''最后经过调参我们可以发现达到了98.89%的准确率。
ORL数据集链接:
链接:https://pan.baidu.com/s/1ISgZnVQ6iTJjyrLnb53bcg
提取码:it6d