DEEPFAKE VIDEO DETECTION USING 3D-ATTENTIONAL INCEPTION
论文简读《DEEPFAKE VIDEO DETECTION USING 3D-ATTENTIONAL INCEPTION
CONVOLUTIONAL NEURAL NETWORK》
发表在CCF C 类会议 2021 IEEE International Conference on Image Processing (ICIP)
使用3D注意力的Inception卷积神经网络的deepfake视频检测
主要贡献:
1.提出了一种基于三维卷积网络的deepfake检测框架,该框架可以充分利用从虚假视频中提取的时间信息,提高检测能力。
2.我们创造性地将注意力模块应用到3D卷积网络中。此外,为了进一步提高模型的检测性能,引入了增强方法。
3.大量的实验表明,我们的方法优于大多数现有的检测方法,在数据集内和跨数据集上都达到了最先进的检测性能。
一、数据预处理
现有的方法大多是提取二维人脸,并利用人脸对齐将所有提取的人脸对齐到特定的一个或特定的位置。这个操作改变了每一帧中人脸的相对位置,这是对时间信息的破坏。为了保留原始视频的时间信息,我们使用一个固定的边界框对视频的每一帧进行不对齐的剪辑。
使用MTCNN不同大小的边界框来捕获脸区域,选择使用最小的且能覆盖整个脸的边界框。然后,我们用选定的边界框裁剪每一帧的面部区域,并通过填充零将它们调整为正方形形状后,将它们重塑为256*256的大小。裁剪好的帧将被重新组合成新的视频剪辑,每个视频剪辑包含大约100帧。这样可以保证我们的模型更多地关注人脸区域而不是无意义的背景,并且不会破坏虚假视频的时间信息。
这步我认为是很合理的,我在做的时候也是有这种疑问。
二、3D-注意力网络
采用I3D为骨架网络,是因为在时间-空间学习上有最好的表现。为了帮助网络更好地关注输入视频中有意义的部分,在每个Iception模块之后添加了一个注意模块。
三、注意力模块
借鉴的是CBAM,但这是个4维的操作,比CBAM多了一个维度。如下图,左边是时空注意力模块,右边是通道注意力模块,下面分别从这两个模块进行分析。

1.时空注意力模块
输入为:![]()
C、T、H和W分别表示通道、时间、宽度和高度。
首先沿着通道轴应用平均和最大池化操作,并将它们连接到特征描述符Fst:
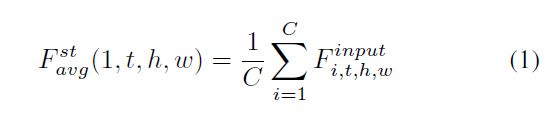
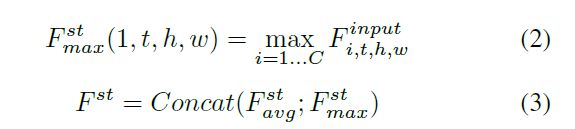
接着是一次3D卷积(5x5x5卷积核)和sigmoid函数.两次操作数学表达如下:

最后再与原输入进行对应元素相乘:

2.通道注意力模块
首先使用平均和最大池操作来压缩特征特征图的时间和空间维度:
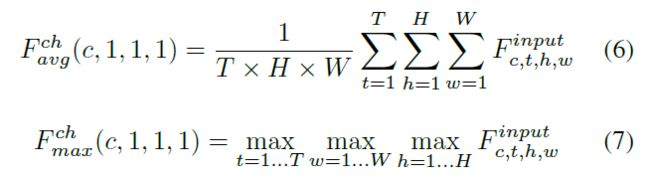
下一步是两个1x1x1卷积层,M1和M2,M1卷积之后relu激活,M2卷积之后,把结果相加,在经过sigmoid函数:

为了减少参数数量,M1卷积后通道数量变为原来的1/8,M2卷积后通道数保持不变。sigmoid之后Ach的每个值在0~1之间,代表着每个通道的重要性。
最后将原输入特征Finput与通道注意特征图Ach相乘:
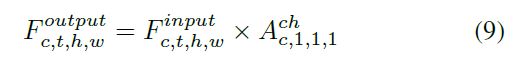
四、实验部分
在被裁剪的视频中,随机选择连续的64帧,每个帧裁剪成224*224大小作为输入。
I3D在Charades数据集上被预训练好,注意力模块随机初始化,用adma优化器,初始学习率0.001.
首先在FF++上进行了一组实验来证明时间信息的重要性,对输入的视频剪辑进行各种修改以破坏时间信息,包括帧顺序变换和数据增强。对视频的每一帧进行增强,实现视频级的数据增强。随机增加每一帧,包括添加高斯噪声、裁剪和翻转等。我们采用两种视频级数据增强策略,一种是对所有帧的增强方法统一,另一种是对每帧的增强方法随机选取。结果如下表:
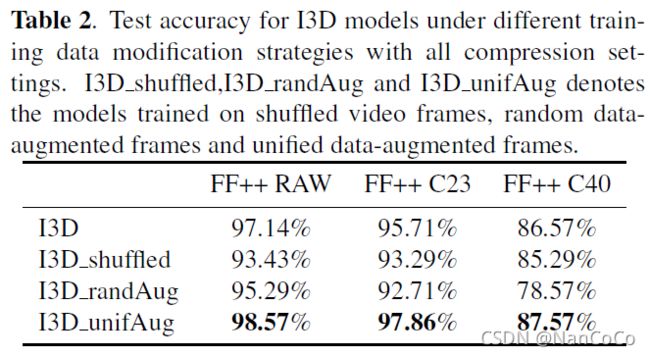
从结果中,我们可以观察到与直接在原始视频上训练的模型相比,I3D shuffle和I3D randAug有明显的下降。而I3D unifAug性能更好。这验证了视频时间信息对深度假检测模型的关键作用。统一的数据增强可以增加训练数据的多样性,进一步提高基线模型的性能。
最后是对比实验结果,下表出了该模型与几种最先进的方法的性能比较。前六列是数据集内评估的结果,模型在同一数据集的训练集上训练,在同一数据集的测试集上测试。最后一列的结果表明了不同模型的泛化能力,其中模型在FF++(c23)上训练,在Celeb-DF上测试。
